 電子發燒友App
電子發燒友App


在建立雷達虛擬操作系統或維修訓練系統時,顯示器的仿真效果直接影響模擬器的訓練效果。目前制約余輝實現的主要瓶頸是余輝效果帶來的龐大的計算量,使得效果較好的余輝掃描線轉速難以超過10轉/s,如果要提高轉速,則需要以犧牲顯示畫質為代價。基于光柵掃描余輝模擬的主流方法有畫線法、固定扇掃法、逐點消隱法,由于前兩者圖像易出現輻射狀花紋及掃描速率不穩定,因此后者的應用較多,效果也明顯強于前者。本文在逐點消隱法的基礎上應用CUDA技術,解決了運算量巨大的問題,在光柵顯示器上得到了余輝效果逼真、畫面流暢的余輝圖形。
1、 余輝仿真的瓶頸
傳統的雷達P顯采用示波管作為顯示終端,其內部熒光材料具有指數型衰減的余輝效應,電子束掃描線圓周掃過屏幕將留下逐漸消隱的余輝。但光柵顯示器無法自動產生熒光粉的余輝效應,因此必須人為地模擬余輝效應。
軟模擬通常采用光柵顯示器,用計算機編程實現。光柵掃描顯示器具有高亮度、高穩定度、大容量顯示的圖文處理能力、豐富的色彩及多灰度等級的優點。一般采用以下三種方法實現。
(1)畫線法較容易實現,原理是在屏幕上以畫直線的方式畫出每一角度的掃描線,形成每次畫一個扇面的灰度遞減的直線簇。但是當程序運行時,掃描線軌跡不斷地在屏幕上轉動,該方法不能無縫地覆蓋整個扇掃區域,從而產生一個輻射狀的固定花紋。
(2)固定扇掃法是在畫線法基礎上改進的一種仿真方法,控制扇形區域的圓心角,依次使不同扇形區域亮度減少。它雖然消除了輻射狀花紋,但在沒有目標到有目標信號時,由于數據量的增加會造成掃描線的轉速不同。
(3)逐點消隱法,主要原理是將每個方位像素的亮度逐次遞減,即每個點都必須被修改,這樣整個屏幕畫面亮度逐漸衰減。其產生的余輝效果比較逼真,掃描線轉速也較穩定。
模擬逼真的余輝效果,一般采用逐點消隱法,十分逼真的余輝仿真需要非常高的數據吞吐率,要求在每一顯示幀的時間內(一般為60 Hz的倒數約16 ms)對屏幕中所有像素進行一次衰減運算。以公認的高效算法,即查表法為例:對于一個像素點而言,最少需要1次讀和2次寫操作,分辨率為1 024×1 024的屏幕中會有1 024×1 024個像素點參與雷達回波的顯示,數量約為1 M。即在16 ms的時間內需要進行1 M次讀操作和2 M次寫操作,分給每個像素點的時間為16 ns。由于Windows屬于通用型操作系統,硬件操作過程極其復雜,無論如何也無法在16 ns內完成1次讀和2次寫操作。需要說明的是,現有的用PC實現的余輝仿真算法都是以犧牲畫質為前提條件的,例如有的算法降低角度分辨率,有的算法只運算部分像素。
2、 瓶頸的解決方案
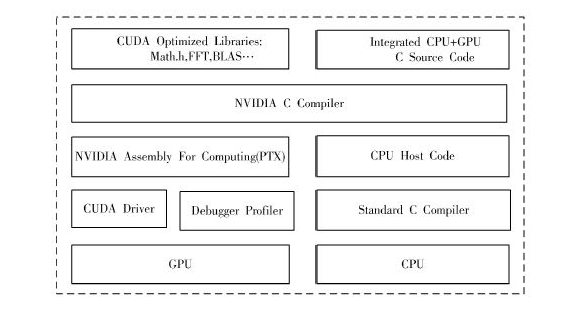
為了解決此瓶頸,本文將國外主要應用于3D游戲設計的CUDA技術移植到余輝的模擬上。CUDA(統一計算設備架構)是NVIDIA公司在2007年推出的針對GPGPU(通用計算GPU)的一個全新構想,使專注于圖像處理的GPU超高性能在數據處理和科學計算等通用計算領域發揮優勢。
GPU特別適合并行數據運算問題,同一個程序可操作許多并行數據元素,并具有高運算密度(算術運算與內存操作的比例),且在高密度運算時,GPU訪問內存的延遲可以被掩蓋。目前高端GPU計算性能已達到Teraflops(每秒萬億次浮點運算)級別,其運算速度遠遠高于CPU的速度。2008年初國內建成的首套實驗系統,其計算性能的理論峰值124 Teraflops,可用峰值82 Teraflops。
但是常規的GPU通用計算還存在以下問題[7]:編程過于繁雜,難以學習與使用,在非圖形領域應用很不充分;GPU編程缺乏靈活性,對GPU性能的發揮有很大的限制。
而CUDA采用GPU+CPU的方式,通過標準C語言將GPU的眾多的計算特性結合到一起,由線程來創建應用程序。程序代碼在實際執行中分為兩種,一種是運行在CPU上的主機代碼,另一種是運行在GPU上的設備代碼。它類似于CPU上的多線程程序,但與僅能有很少線程同時工作的多核CPU相比,GPU可以同時執行成千上萬個線程。CPU程序以異步的方式調用GPU核程序,GPU作為CPU的協處理器(CoProeessor)提供服務。
當前CUDA提供的主要功能如下:
(1)在GPU上提供標準C編程語言。
(2)為在支持CUDA的NVIDIA GPU的并行計算提供統一的軟硬件解決方案。
(3)支持CUDA的GPU能進行并行數據緩存和線程執行管理。
(4)經過優化的,從CPU到支持CUDA的GPU的直接上傳、下載通道。
(5)CUDA驅動與DirectX和OpenGL等圖形驅動程序兼容。
為了解決巨大計算量的問題,主要采用CPU+GPU的編程模式來模擬余輝,在GPU中為每一個像素點創建一個線程獨立進行亮度衰減處理。由于每個像素的線程并行執行,完成整個屏幕像素的數據處理幾乎不需要計算時間,真正花費時間的是畫面繪制和翻轉。因此繪制畫面在后臺表面進行,繪制完成后翻轉到前臺顯示,這樣繪制和顯示可以同時進行,既為畫面的繪制留足了時間,又能得到流暢不閃爍的畫質。
3 、采用CUDA技術來實現余輝效果
為了產生不同方位的掃描線,將方位、距離進行量化,由于掃描區域的分辨率為1 024×1 024,因此半徑為512像素。由于掃描半徑為512個像素,理論上只要角度量化數N大于3 217就不會出現顯示死地址的現象,方位上量化為4 096個等分。這樣初始生成一個4 096×512個像素的圓域。雷達P顯中采用的是極坐標系,而在光柵顯示器中采用的是直角坐標,通過坐標變換,將建立一張坐標變換表,如表1所示。

通過查表可以避免坐標變換帶來的正余弦計算,方便地在極坐標和直角坐標間轉換,從而節省大量的運算時間。考慮到近距離區域,多個角度的距離單元會對應相同的像素點,首先為每個像素點定義一個屬性的結構體:
typedef struct
{ WORD x;//屏幕直角坐標x
WORD y;//屏幕直角坐標y
WORD ScanlinePtIndex;//該點在掃描線上的
//距離索引
BYTE MapTo2Pt;//該點與同一條掃描上的
//點是否重合
BYTE RadEnd;//標記該條掃描線處理完畢
}RADIUSPOINT;
為圓域內的點分配內存空間:
RADIUSPOINT m_pRadPtToLintPtMap=new RADIUSPOINT[4 096×512]。
對于同一條掃描線上相鄰的兩點,如果直角坐標相同就把MapTo2Pt設為1,標記為相同的點;如果相鄰兩點的直角坐標不相同,則把距離索引值賦給ScanlinePtIndex,每條線最后一個點設置RadEnd為1來標記每條線處理已完畢。對于相鄰兩條線上的點,如果當前線上點與前一條線上相鄰4個點的直角坐標相等,設置為m_pPixelOverlap[i]=1,否則設為0。


考慮到余輝呈指數型衰減,而指數運算需要花費大量的時間,對于計算機,其最快的操作是取值和賦值,為了提高光柵掃描雷達顯示系統的實時性,需要提高單位時間內能夠處理的像素點個數。于是對指數運算采用查表法以提高速度,維護一張按角度劃分的指數型衰減因子表m_wAttenuation[4 096]以進行數值的取值和賦值操作。
同時還要建立一個Brightness[4 096×512]的亮度表,來存儲每個像素對應的RGB顏色值。
以上這些工作在程序的初始化中即完成,一經完成即可在后續的程序中直接調用。
通過CUDA編程時,GPU可看作為可以并行執行非常多個線程的計算設備,執行并行計算的線程被組織成線程塊(Block),每個線程塊可以包含多達512個線程,而線程塊又組成了柵格(Grid)。GPU可以支持成百上千萬個并行線程,于是可以為每個像素點開一個線程,這樣每個像素點可以并行處理,能極大地提高對整個屏幕像素的處理速度,為CPU留出足夠多的時間去處理其他相關的任務。
定義線程塊Block包含的線程維數:
dim3 threads(BLOCK_SIZE,BLOCK_SIZE);
定義柵格Grid包含的線程塊數:
dim3 grid(Width/threads.x,Height/ threads.y);
每個像素點對應的線程處理工作如下:
由于某型雷達轉速為10轉/min,相當于每次更新的掃描線數應為4 096×10/60/1 000=0.683條/ms,像素處理在GPU中并行進行,對CPU的占用率幾乎為零,所消耗的時間主要是Direct3D紋理的繪制和表面的翻轉,大約為16 ms,因此每次更新的掃描線數目約為16×0.683=10.928,即每次更新11條。將當前要更新的掃描線上的像素點設為初始亮度,其后的每條掃描線上的像素點的亮度按與當前掃描線角度差m_anglediff取m_wAttenuation[m_anglediff]的亮度進行衰減。由于近距離區域多個角度的距離單元對應相同的像素點,因此中心部位被消隱的次數明顯要比其他部位多,導致效果有些失真。于是需要對這些坐標相同的點進行處理,對于屬性MapTo2Pt為1的點,比較坐標相同的點處于不同距離時的亮度,取其大者賦值給亮度表Brightness[4 096×512]。對于屬性m_pPixelOverlap為1的點,比較處于各個角度時的亮度,取其大者賦值給亮度表。這樣對于同一個點只顯示一次且取其最亮者顯示,較好地避免了中心部位被消隱次數過多的情況。
對于實現余輝等級的情況,只需要調制m_wAttenuation的大小就可以方便地調節余輝等級。如果需要提高轉速,只需增大每次更新的掃描線數目即可,且基本不會影響程序運行速度。
通過CPU+GPU組合的方式模擬不同等級余輝效果如圖1、圖2所示,此時對應的CPU占用率幾乎為零,如圖3所示。該方法得到的余輝效果逼真、畫面流暢、掃描速度達到了預定的10轉/s的要求,且CPU占用率極低,并不妨礙CPU處理其他數據。
當把每次需要更新的掃描線數目增多時,由于GPU能并行高速處理每個像素點,掃描的速度能迅速提升而不影響顯示畫質,在程序調試時,可以驗證當掃描速度到45轉/min時,畫面依然流暢且占用的系統資源少。
余輝實現的逼真程度很大程度上決定了雷達模擬器的效果,本文就當前余輝模擬存在的瓶頸提出了一種基于CUDA的解決方案,采用“CPU+DPU”編程的方法,很好地解決了數據吞吐量巨大的問題。此方法模擬的余輝易于與雷達回波信號疊加,便于程序的擴展,可以應用于模擬器的設計及雷達技術的研發。
責任編輯:gt





















 工商網監
工商網監
評論