 電子發燒友App
電子發燒友App


1 前言
從輸出維度的角度來看,基于視覺傳感器的感知方法可以分為2D感知和3D感知兩種。專欄之前的文章也分別對這兩種感知任務做了詳細的介紹。
從傳感器的數量上看,視覺感知系統也分為單目系統,雙目系統,以及多目系統。2D感知任務通常采用的是單目系統,這也是計算機視覺和深度學習結合最緊密的領域。但是自動駕駛感知最終需要的是3D輸出,因此我們需要將2D的信息推廣到3D。在深度學習取得成功之前,通常的做法是根據目標的先驗大小以及目標處于地平面上等假設來推斷目標的深度(距離),或者采用運動信息進行深度估計(Motion Stereo)。有了深度學習的助力之后,從大數據集中學習場景線索,并進行單目深度估計成為了可行的方案。但是這種方案非常依賴于模式識別,而且很難處理數據集之外的場景(Corner Case)。比如施工路段的特殊工程車輛,由于數據庫中很少出現或者根本沒有此類樣本,視覺傳感器無法準確檢測該目標,因而也就無法判斷其距離。
雙目系統可以自然的獲得視差,從而估計障礙物的距離。這種系統對模式識別的依賴度較小,只要能在目標上獲得穩定的關鍵點,就可以完成匹配,計算視差并估計距離。但是,雙目系統也有以下缺點。首先,如果關鍵點無法獲取,比如在自動駕駛中經常引發事故的白色大貨車,如果其橫在路中央,視覺傳感器在有限的視野中很難捕捉關鍵點,距離的測算就會失敗。其次,雙目視覺系統對攝像頭之間的標定要求非常高,一般來說都需要有非常精確的在線標定功能。最后,雙目系統的計算量較大,需要算力較高的芯片來支持,一般都會采用FPGA。雙目系統的成本介于單目和激光雷達之間,目前也有一些OEM開始采用雙目視覺來支持不同級別的自動駕駛系統,比如斯巴魯,奔馳,寶馬等。
理論上說,雙目系統已經可以解決3D信息獲取的問題,那么為什么還需要多目系統呢?原因大致有兩點:一是通過增加不同類別的傳感器,比如紅外攝像頭,來提高對各種環境條件的適應性;二是通過增加不同朝向,不同焦距的攝像頭來擴展系統的視野范圍。下面我們就來分析幾個典型的多目系統。
2 Mobileye的三目系統
對應定焦鏡頭來說,探測距離和探測視角是成反比的關系。視角越寬,探測的距離越短,精度越低;視角越窄,探測的距離越長,精度越高。車載攝像頭很難做到頻繁變焦,因此一般來說探測距離和視野都是固定的。
多目系統,可以通過不同焦距的攝像頭來覆蓋不同范圍的場景。比如Mobileye和ZF聯合推出的三目系統,三目包含一個150°的廣角攝像頭,一個52°的中距攝像頭和一個28°的遠距攝像頭。其最遠探測距離可以達到300米,同時也可以保證中近距的探測視野和精度,用于檢測車輛周邊的環境,及時發現車輛前方突然出現的物體。
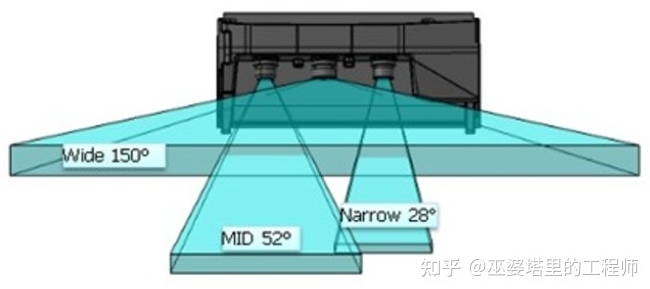
這種三目系統主要的難點在于如何處理重疊區域中不一致的感知結果。不同攝像頭對于同一場景給出了不同的理解,那么就需要后面的融合算法來決定信任哪一個。不同攝像頭自身的誤差范圍也不同,很難設計一個合理的規則去定義各種不同情況下的決策,這給融合算法帶來了更大的挑戰。文章后面會介紹,多目系統其實還可以采用數據層的融合,利用深度學習和大數據集來學習融合規則。當然也不是說交給機器學習就完事大吉了,黑盒子的深度神經網絡有時也會給出難以解釋的輸出。
3 Foresight的四目感知系統
多目系統的另外一個思路是增加不同波段的傳感器,比如紅外攝像頭(其實激光雷達和毫米波雷達也是不同波段的傳感器而已)。來自以色列的Foresight公司設計并演示了一個四目感知系統(QuadSight)。在可見光雙目攝像頭的基礎上,QuadSight增加了一對長波紅外(LWIR)攝像頭,使探測范圍從可見光波段擴展到紅外波段。紅外波段的加入,一方面增加了信息量,另一方面也增強了在夜間環境以及在雨霧天氣下的適應能力,保證了系統全天候運行的能力。
QuadSight系統中攝像頭的視野范圍為45度,最遠可以探測150米的距離,可以在100米的距離內探測到35*25厘米大小的物體。運行速度方面可以達到45幀/秒,足以應對高速行駛的場景。
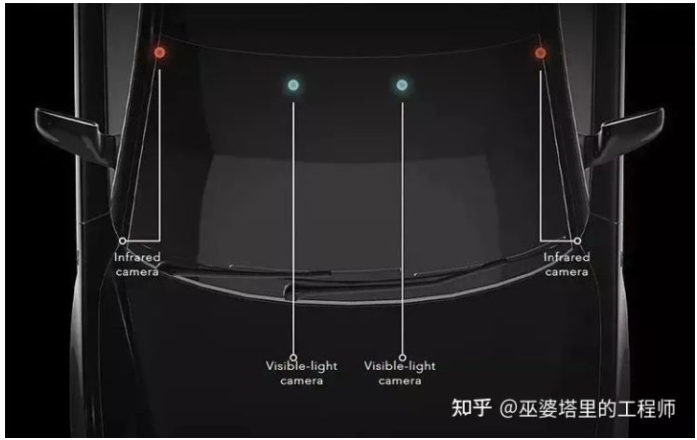
Foresight的QuadSight四目系統
QuardSight系統是由兩對雙目系統組成。從上圖中可以看到,紅外雙目攝像頭安裝在擋風玻璃的左右兩側,其基線長度要比一般的雙目系統大很多。這里稍微跑點題,討論一下雙目系統基線長度的問題。
傳統的雙目系統一般采用短基線模式,也就是說兩個攝像頭之間的距離比較短,這就限制了探測的最大距離。當一個目標距離很遠時,其在左右圖像上的視差已經小于一個像素,這時就無法估計其深度,既所謂的基線約束。這已是極限的情況,其實對于遠距離目標,即使視差大于一個像素,深度估計的誤差也是很大的。一般來說,深度估計的誤差應該與距離的平方成正比。
為了提高雙目系統的有效探測距離,一個直觀的方案就是增加基線長度,這樣可以增加視差的范圍。NODAR的公司推出的Hammerhead技術,可以實現兩個攝像頭超大距離的寬基線配置,探測距離最遠可達1000米,同時可以生成高密度的點云。這個系統可以利用整車的寬度,比如把攝像頭安裝在側視鏡、前大燈或車頂兩側。
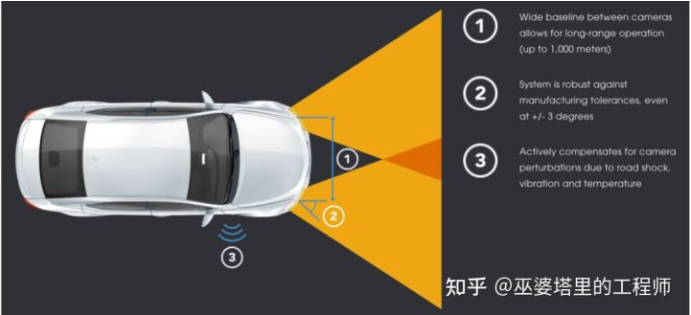
Hammerhead技術中的寬基線配置
4 Tesla的全景感知系統
分析了三目和四目的例子后,下面進入本篇文章的重點,也就是基于多目的全景感知系統。這里我們采用的例子是Tesla在2021年的AI Day上展示了一個純視覺的FSD(Full Self Driving)系統。雖然說只能算是L2級別(駕駛員必須做好隨時接管車輛的準備),但如果只是橫向對比L2級的自動駕駛系統,FSD的表現還是不錯的。此外,這個純視覺的方案集成了近年來深度學習領域的很多成功經驗,在多攝像頭融合方面很有特點,個人覺得至少在技術方面還是值得研究一下。
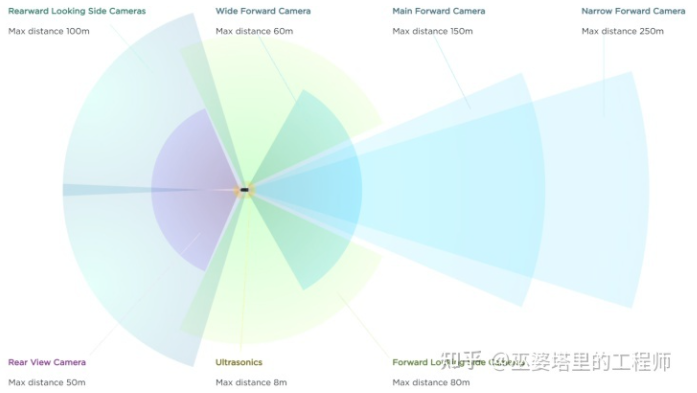
Tesla FSD系統的多攝像頭配置
這里再稍微跑個題,說一下Tesla AI和Vision方向的負責人,Andrej Karpathy。這位小哥1986年出生,2015年在斯坦福大學獲得博士學位,師從計算機視覺和機器學習界的大牛李飛飛教授,研究方向是自然語言處理和計算機視覺的交叉任務以及深度神經網絡在其中的應用。馬斯克2016年將這位青年才俊召入麾下,之后讓其負責Tesla的AI部門,是FSD這個純視覺系統在算法方面的總設計師。
Andrej在AI Day上的報告中首先提到,五年前Tesla的視覺系統是先獲得單張圖像上的檢測結果,然后將其映射到向量空間(Vector Space)。這個“向量空間”是報告中的核心概念之一,我理解其實它就是環境中的各種目標在世界坐標系中的表示空間。比如對于物體檢測任務,目標在3D空間中的位置,大小,朝向,速度等描述特性組成了一個向量,所有目標的描述向量組成的空間就是向量空間。視覺感知系統的任務就是將圖像空間中的信息轉化為向量空間中的信息。這可以通過兩種方法來實現:一是先在圖像空間中完成所有的感知任務,然后將結果映射到向量空間,最后融合多攝像頭的結果;二是先將圖像特征轉換到向量空間,然后融合來自多個攝像頭的特征,最后在向量空間中完成所有的感知任務。
Andrej舉了兩個例子,說明為什么第一種方法是不合適的。首先,由于透視投影,圖像中看起來不錯的感知結果在向量空間中精度很差,尤其是遠距離的區域。如下圖所示,車道線(藍色)和道路邊緣(紅色)在投影到向量空間后位置非常不準,無法用支持自動駕駛的應用。
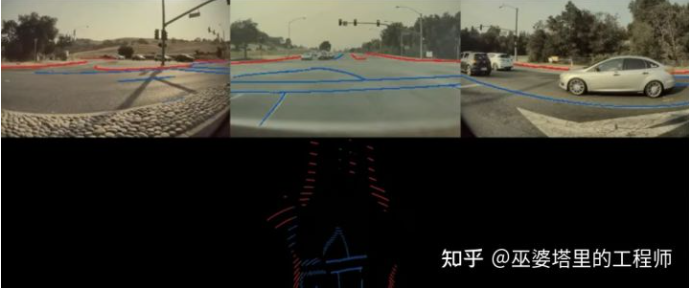
圖像空間的感知結果(上)及其在向量空間中的投影(下)
其次,在多目系統中,由于視野的限制,單個攝像頭可能無法看到完整的目標。比如在下圖的例子中,一輛大貨車出現在了一些攝像頭的視野中,但是很多攝像頭都只看到了目標的一部分,因此無法根據殘缺的信息做出正確的檢測,因此后續的融合效果也就無法保證。這其實是多傳感器決策層融合的一個一般性問題。

單攝像頭受限的視野
綜合以上分析,圖像空間感知+決策層融合并不是一個很好的方案。直接在向量空間中完成融合和感知可以有效地解決以上問題,這也是FSD感知系統的核心思路。為了實現這個思路,需要解決兩個重要的問題:一個是如何將特征從圖像空間變換到特征空間,另一個是如何得到向量空間中的標注數據。
4.1 特征的空間變換
對于特征的空間變換問題,專欄之前在3D感知的文章中也做了介紹,一般性的做法就是利用攝像頭的標定信息將圖像像素映射到世界坐標系。但這是個病態問題,需要有一定的約束,自動駕駛應用中通常采用的是地平面約束,也就是目標位于地面,而且地面是水平的。這個約束太強了,在很多場景下無法滿足。
Tesla的解決方案中核心的有三點。首先,通過Transformer和Self-Attention的方式建立圖像空間到向量空間的對應關系,這里向量空間的位置編碼起到了很重要的作用。具體實現細節這里就不展開說了,以后有時間再單開一篇文章詳細的介紹。簡單來理解的話,向量空間中每一個位置的特征都可以看作圖像所有位置特征的加權組合,當然對應位置的權重肯定大一些。但是這個加權組合的過程通過Self-Attention和空間編碼來自動的實現,不需要手工設計,完全根據需要完成的任務來進行端對端的學習。
其次,在量產應用中,每一輛車上攝像頭的標定信息都不盡相同,導致輸入數據與預訓練的模型不一致。因此這些標定信息需要作為額外的輸入提供給神經網絡。簡單的做法可以將每個攝像頭的標定信息拼接起來,通過MLP編碼后再輸入給神經網絡。但是,一個更好的做法是將來自不同攝像頭的圖像通過標定信息進行校正,使不同車輛上對應的攝像頭都輸出一致的圖像。
最后,視頻(多幀)輸入被用來提取時序信息,以增加輸出結果的穩定性,更好的處理遮擋場景,并且預測目標的運動。這部分還有一個額外的輸入就是車輛自身的運動信息(可以通過IMU獲得),以支持神經網絡對齊不同時間點的特征圖。時序信息的處理可以采用3D卷積,Transformer或者RNN。FSD的方案中采用的是RNN,以我個人的經驗來看,這確實也是目前在準確度和計算量之間平衡度最好的方案。
通過以上這些算法上的改進,FSD在向量空間中的輸出質量有了很大的提升。在下面的對比圖中,下方左側是來自圖像空間感知+決策層融合方案的輸出,而下方右側上述特征空間變換+向量空間感知融合的方案。

圖像空間感知(左下) vs. 向量空間感知(右下)
4.2 向量空間中的標注
既然是深度學習算法,那么數據和標注自然就是關鍵環節。圖像空間中的標注非常直觀,但是系統最終需要的是在向量空間中的標注。Tesla的做法是利用來自多個攝像頭的圖像重建3D場景,并在3D場景下進行標注。標注者只需要在3D場景中進行一次標注,就可以實時的看到標注結果在各個圖像中的映射,從而進行相應的調整。

3D空間中的標注
人工標注只是整個標注系統的一部分,為了更快更好的獲得標注,還需要借助自動標注和模擬器。自動標注系統首先基于單攝像頭的圖像生成標注結果,然后通過各種空間和時間的線索將這些結果整合起來。形象來說就是各個攝像頭湊在一起討論出一個一致的標注結果。除了多個攝像頭的配合,在路上行駛的多臺Tesla車輛也可以對同一個場景的標注進行融合改進。當然這里還需要GPS和IMU傳感器來獲得車輛的位置和姿態,從而將不同車輛的輸出結果進行空間對齊。自動標注可以解決標注的效率問題,但是對于一些罕見的場景,比如報告中所演示的在高速公路上奔跑的行人,還需要借助模擬器來生成虛擬數據。以上所有這些技術組合起來,才構成了Tesla完整的數據收集和標注系統。關于數據的問題,這里只是稍微涉及了一點,完整的工作鏈還是相當復雜的,之后專欄中會有專門的文章進行這方面的探討。
編輯:黃飛
?












 工商網監
工商網監
評論