 電子發燒友App
電子發燒友App


本篇文章為大家介紹一種2D圖像和LiDAR的3D點云之間的配準方法。
不同模態之間的配準,即來自攝像機的2D圖像和LiDAR的3D點云之間的配準,是計算機視覺和機器人領域中的關鍵任務。先前的方法通過匹配神經網絡學習到的點和像素模式來估計2D-3D對應關系,并使用 Perspective-n-Points(PnP)在后處理階段估計剛性變換。然而這些方法在將點和像素魯棒地映射到共享的潛在空間方面存在困難,因為點和像素具有非常不同的特征,用不同的方式學習模式,而且它們也無法直接在變換上構建監督,因為PnP是不可微分的,導致不穩定的配準結果。為解決這些問題提出通過可微分的概率PnP求解器學習結構化的跨模態潛在空間,以表示像素特征和3D特征。
具體而言設計了一個三元網絡來學習VoxelPoint-to-Pixel匹配,其中我們使用體素和點來表示3D元素,以通過像素學習跨模態潛在空間。我們基于CNN設計了體素和像素分支,以在表示為網格的體素/像素上執行卷積,并集成了額外的點分支,以在體素化過程中丟失的信息。我們通過在概率PnP求解器上直接施加監督來端到端地訓練我們的框架。為了探索跨模態特征的獨特模式,我們設計了一種具有自適應權重優化的新型損失來描述跨模態特征。在KITTI和nuScenes數據集上的實驗結果顯示,與最先進的方法相比,我們的方法取得了顯著的改進。
主要貢獻
1. 提出了一個新穎的框架,通過學習一個結構化的跨模態潛在空間,通過自適應權重優化,通過可微的PnP求解器進行端到端訓練,從而學習圖像到點云的配準。?
2. 提出將3D元素表示為體素和點的組合,以克服點云和像素之間的模態差距,其中設計了一個三元網絡來學習體素點到像素的匹配。?
3. 通過在KITTI和nuScenes數據集上進行廣泛實驗,展示了我們在最先進技術上的卓越性能。
內容概述
首先詳細介紹了VoxelPoint-to-Pixel匹配的框架,該框架用于學習結構化的跨模態潛在空間。接著提出了一種新穎的損失函數,具有自適應加權優化,用于學習獨特的跨模態模式。最后引入了可微分的概率PnP求解器,這推動了我們的端到端學習模式。總體而言,該方法框架如圖1所示。
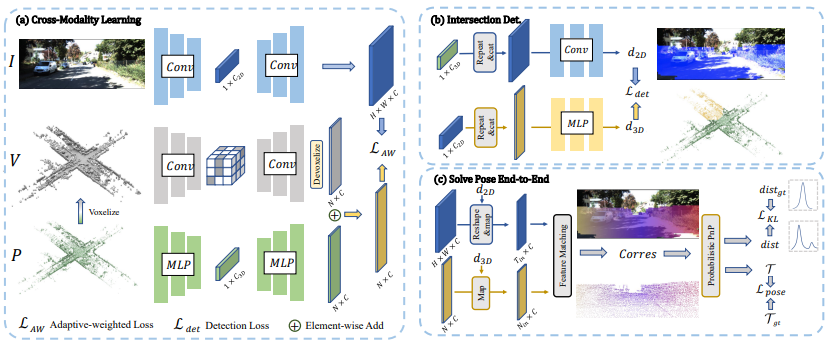
圖1:我們方法的概述。給定一對未正確配準的圖像I和點云P作為輸入,(a) 我們首先對稀疏體素進行操作以生成稀疏體素V,然后應用三元網絡從三個模態中提取模式。我們將2D模式表示為像素特征,將3D模式表示為體素和點特征的組合,分別使用自適應加權損失來學習獨特的2D-3D跨模態模式。(b) 我們使用跨模態特征融合檢測2D/3D空間中的交集區域。(c) 我們根據交集檢測的結果去除異常區域,并使用2D-3D特征匹配建立2D-3D對應關系,然后應用概率PnP來預測外參姿勢的分布,通過與真值位姿一起進行端到端的監督。
VoxelPoint-to-Pixel匹配框架
? 該框架采用三元網絡,包括Voxel、Point和Pixel分支,以獲取2D和3D特征。
? 在voxel分支中使用稀疏卷積,以有效捕捉空間模式。
? 引入point分支,受PointNet++啟發,用于恢復在voxel化期間丟失的詳細3D模式。
? pixel分支基于卷積U-Net,提取全局2D圖像特征。
2D-3D特征匹配
? 將3D元素表示為voxels和points的組合。
? 引入一種新方法,通過將它們映射到共享的潛在空間中,匹配2D和3D特征。
? VoxelPoint-to-Pixel匹配創建了一個結構化的跨模態潛在空間,提供均勻的特征分布。
用于異常處理的交叉檢測
? 由于圖像和LiDAR點云采集方式的不同,存在大量離群值區域,無法找到對應關系。
? 將交叉區域定義為LiDAR點云使用地面實況相機參數的2D投影與參考圖像之間的重疊部分。
? 通過檢測策略,預測每個2D/3D元素位于交叉區域的概率,有助于在推斷2D-3D對應關系之前去除兩個模態上的離群區域。

圖2:使用點對像素(P2P)和體素點對像素(VP2P)匹配學習的潛在空間的 t-SNE 可視化
自適應加權優化策略
自適應加權優化旨在解決2D和3D任務中的特征匹配問題。通常情況下,傳統的對比損失和三元損失等優化方法在處理2D-3D特征匹配時存在問題,提出了一種自適應加權的優化策略,該策略針對一組2D-3D配對樣本,通過自適應權重因子對正對和負對進行加權,以更靈活地進行優化。

圖3:自適應加權優化的說明
可微分 PnP
建立2D-3D的對應關系首先通過交叉區域檢測,在兩個模態中去除離群區域,然后利用交叉模態潛在空間的最近鄰原則進行2D-3D特征匹配。為了建立對應關系,使用 arg max 操作在交叉模態潛在空間中搜索具有最大相似度的點坐標。這一操作是非可微的,但通過 Gumbel 估計器獲得梯度以實現端到端訓練。概率 PnP 方法將輸出解釋為概率分布,用于解決非可微的 PnP 問題,通過計算 KL 散度損失最小化預測姿態分布與地面真實姿態分布之間的距離,進行監督。此外,通過基于 Gauss-Newton 算法的迭代 PnP 求解器求解精確的姿態,并計算姿態損失。姿態損失也參與優化,因為 GN 算法的迭代部分是可微分的。
實驗
我們在兩個廣泛使用的基準數據集KITTI和nuScenes上評估我們在圖像到點云配準任務上的性能。在兩個數據集上,圖像和點云是通過2D相機和3D激光雷達同時捕獲的。
定量與定性比較實驗
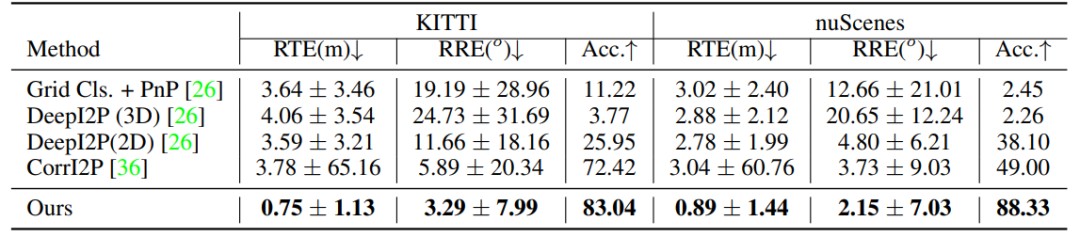
定量比較:我們的方法在KITTI和nuScenes數據集上展現出卓越性能,尤其在RTE方面比最新的CorrI2P方法提高了大約4倍。我們的方法通過端到端訓練框架,結合概率PnP求解器,能夠學習穩健的2D-3D對應關系,實現了更準確的預測,如表1。
視覺比較:圖5中的視覺比較顯示,我們的方法在不同道路情況下實現了更好的配準精度。與其他方法相比,尤其是在調校困難的情況下,如第1行和第2行,我們的方法能夠更準確地解決配準問題,而其他方法(如DeepI2P和CorrI2P)無法正確匹配樹木和汽車的投影與圖像中相應的像素。
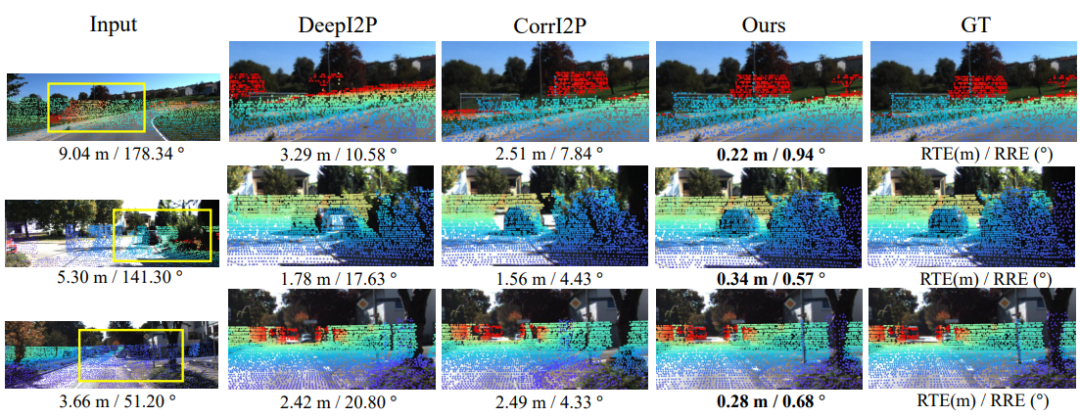
圖5:在KITTI數據集下進行的圖像到點云配準結果的可視比較
特征匹配的精度
圖6展示了特征匹配的可視化,通過計算兩個模態上的匹配距離生成雙側誤差圖。對于2D到3D的匹配,我們在交叉區域的每個2D像素上尋找相似度最大的點,計算投影匹配點與2D像素之間的歐拉距離,結果顯示我們的方法在2D到3D和3D到2D匹配中均明顯優于CorrI2P。我們的方法在大多數匹配中能夠實現小于2像素的輕微錯誤,表明我們學到的共享潛在空間能夠準確區分交叉模態模式,實現準確的特征匹配。在圖像和點云邊緣處可能存在相對較大的錯誤,因為在邊緣區域完美執行交叉區域檢測通常是困難的。
運行效率
與其他方法在NVIDIA RTX 3090 GPU和Intel(R) Xeon(R) E5-2699 CPU上進行了效率比較。在表2中,我們的方法參數更少,性能顯著更好。此外我們的方法僅需0.19秒進行網絡推斷和一個幀的姿態估計,比先前的方法快了大約50倍(或更多)。

消融實驗
進行了消融研究以驗證我們方法中每個設計的有效性以及一些重要參數的影響,報告了在KITTI數據集下RTE/RRE/Acc.的性能。
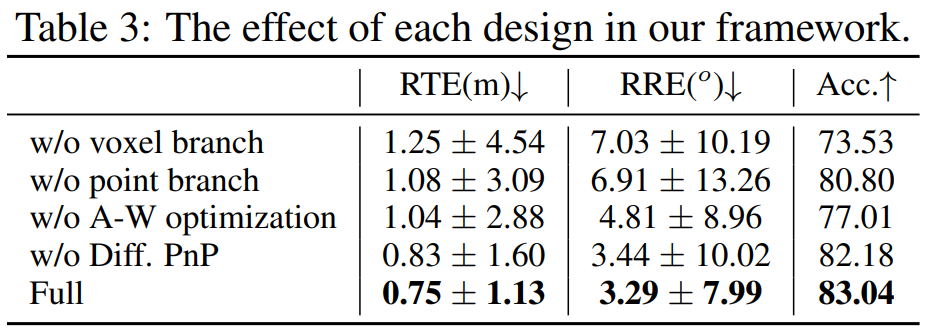
框架設計驗證:我們通過四種變體驗證了框架中每個設計的有效性,包括去除體素分支、去除點云分支、替換自適應加權優化損失以及去除可微PnP驅動的端到端監督。結果如表3,顯示了全模型在所有變體中表現最佳,證明了每個設計在框架中的有效性。特別是,相較于去掉點云分支,體素分支在框架中扮演更重要的角色,表明體素模態更適合學習圖像到點云的配準。
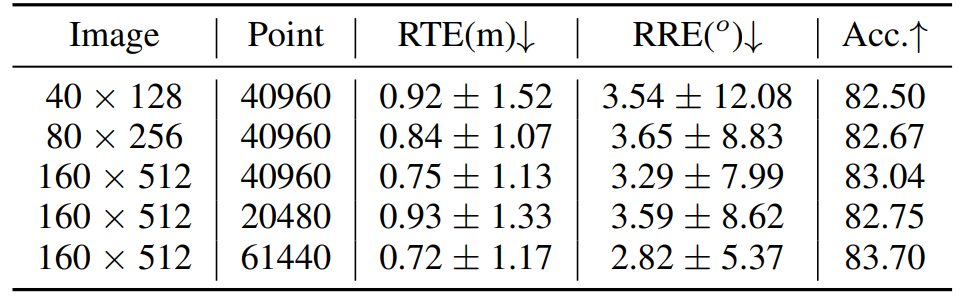
輸入分辨率影響:我們進一步研究了輸入圖像分辨率和點云密度的影響。結果如表4顯示,在兩個模態上使用更高分辨率會帶來更好的效果,因為低分辨率圖像可能丟失一些視覺信息,而低密度點云則可能失去詳細的幾何結構,我們選擇在性能和效率之間找到平衡的適當設置。
總結
這項工作提出了一個新穎的框架,通過VoxelPoint-to-Pixel匹配學習圖像到點云的配準,其中我們使用一種新穎的自適應加權損失學習結構化的跨模態潛在空間。將3D元素表示為體素和點的組合,以克服點云和像素之間的域差異。此外通過在可微的PnP求解器上直接對預測的姿態分布進行監督,端到端地訓練我們的框架,在KITTI和nuScenes數據集上進行的廣泛實驗證明了我們的卓越性能。
審核編輯:黃飛
?













 工商網監
工商網監
評論