什么是IO多路復用_IO多路復用同步異步阻塞和非阻塞
一、什么是socket?
我們都知道unix(like)世界里,一切皆文件,而文件是什么呢?文件就是一串二進制流而已,不管socket,還是FIFO、管道、終端,對我們來說,一切都是文件,一切都是流。在信息 交換的過程中,我們都是對這些流進行數據的收發操作,簡稱為I/O操作(input and output),往流中讀出數據,系統調用read,寫入數據,系統調用write。不過話說回來了 ,計算機里有這么多的流,我怎么知道要操作哪個流呢?對,就是文件描述符,即通常所說的fd,一個fd就是一個整數,所以,對這個整數的操作,就是對這個文件(流)的操作。我們創建一個socket,通過系統調用會返回一個文件描述符,那么剩下對socket的操作就會轉化為對這個描述符的操作。不能不說這又是一種分層和抽象的思想。
二、阻塞?
什么是程序的阻塞呢?想象這種情形,比如你等快遞,但快遞一直沒來,你會怎么做?有兩種方式:
快遞沒來,我可以先去睡覺,然后快遞來了給我打電話叫我去取就行了。
快遞沒來,我就不停的給快遞打電話說:擦,怎么還沒來,給老子快點,直到快遞來。
很顯然,你無法忍受第二種方式,不僅耽擱自己的時間,也會讓快遞很想打你。
而在計算機世界,這兩種情形就對應阻塞和非阻塞忙輪詢。
非阻塞忙輪詢:數據沒來,進程就不停的去檢測數據,直到數據來。
阻塞:數據沒來,啥都不做,直到數據來了,才進行下一步的處理。
先說說阻塞,因為一個線程只能處理一個套接字的I/O事件,如果想同時處理多個,可以利用非阻塞忙輪詢的方式,偽代碼如下:
[cpp] view plain copywhile true
{
for i in stream[]
{
if i has data
read until unavailable
}
}
我們只要把所有流從頭到尾查詢一遍,就可以處理多個流了,但這樣做很不好,因為如果所有的流都沒有I/O事件,白白浪費CPU時間片。正如有一位科學家所說,計算機所有的問題都可以增加一個中間層來解決,同樣,為了避免這里cpu的空轉,我們不讓這個線程親自去檢查流中是否有事件,而是引進了一個代理(一開始是select,后來是poll),這個代理很牛,它可以同時觀察許多流的I/O事件,如果沒有事件,代理就阻塞,線程就不會挨個挨個去輪詢了,偽代碼如下:
[cpp] view plain copywhile true
{
select(streams[]) //這一步死在這里,知道有一個流有I/O事件時,才往下執行
for i in streams[]
{
if i has data
read until unavailable
}
}
但是依然有個問題,我們從select那里僅僅知道了,有I/O事件發生了,卻并不知道是哪那幾個流(可能有一個,多個,甚至全部),我們只能無差別輪詢所有流,找出能讀出數據,或者寫入數據的流,對他們進行操作。所以select具有O(n)的無差別輪詢復雜度,同時處理的流越多,無差別輪詢時間就越長。
epoll可以理解為event poll,不同于忙輪詢和無差別輪詢,epoll會把哪個流發生了怎樣的I/O事件通知我們。所以我們說epoll實際上是事件驅動(每個事件關聯上fd)的,此時我們對這些流的操作都是有意義的。(復雜度降低到了O(1))偽代碼如下:
[cpp] view plain copywhile true
{
active_stream[] = epoll_wait(epollfd)
for i in active_stream[]
{
read or write till
}
}
可以看到,select和epoll最大的區別就是:select只是告訴你一定數目的流有事件了,至于哪個流有事件,還得你一個一個地去輪詢,而epoll會把發生的事件告訴你,通過發生的事件,就自然而然定位到哪個流了。不能不說epoll跟select相比,是質的飛躍,我覺得這也是一種犧牲空間,換取時間的思想,畢竟現在硬件越來越便宜了。
三、I/O多路復用
好了,我們講了這么多,再來總結一下,到底什么是I/O多路復用。
先講一下I/O模型:
首先,輸入操作一般包含兩個步驟:
等待數據準備好(waiting for data to be ready)。對于一個套接口上的操作,這一步驟關系到數據從網絡到達,并將其復制到內核的某個緩沖區。
將數據從內核緩沖區復制到進程緩沖區(copying the data from the kernel to the process)。
其次了解一下常用的3種I/O模型:
1、阻塞I/O模型
最廣泛的模型是阻塞I/O模型,默認情況下,所有套接口都是阻塞的。 進程調用recvfrom系統調用,整個過程是阻塞的,直到數據復制到進程緩沖區時才返回(當然,系統調用被中斷也會返回)。
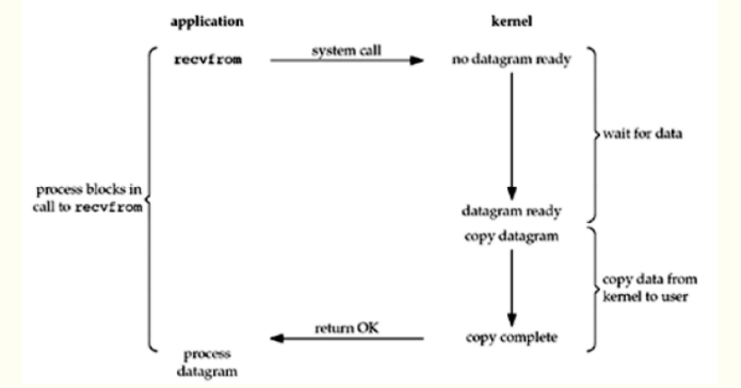
2、非阻塞I/O模型
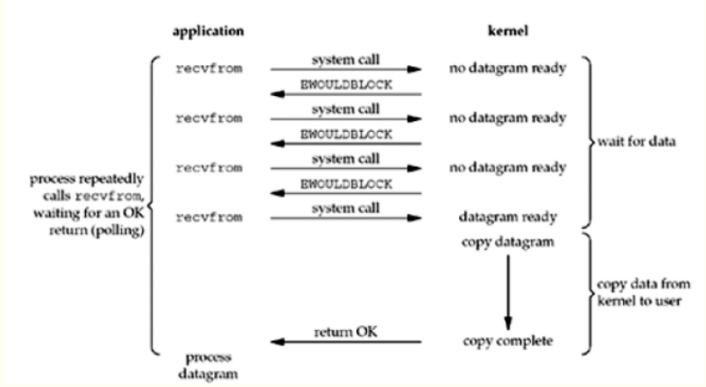
當我們把一個套接口設置為非阻塞時,就是在告訴內核,當請求的I/O操作無法完成時,不要將進程睡眠,而是返回一個錯誤。當數據沒有準備好時,內核立即返回EWOULDBLOCK錯誤,第四次調用系統調用時,數據已經存在,這時將數據復制到進程緩沖區中。這其中有一個操作時輪詢(polling)。
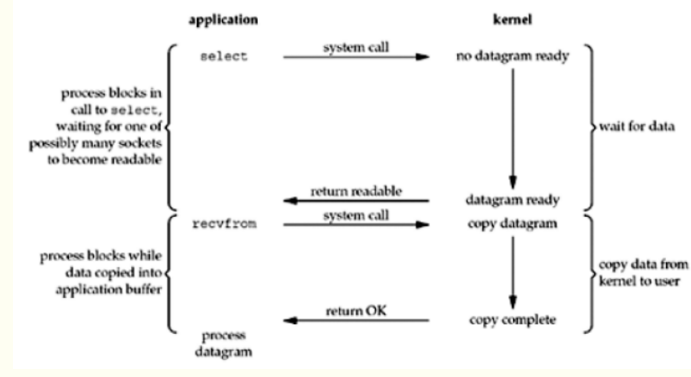
3、I/O復用模型
此模型用到select和poll函數,這兩個函數也會使進程阻塞,select先阻塞,有活動套接字才返回,但是和阻塞I/O不同的是,這兩個函數可以同時阻塞多個I/O操作,而且可以同時對多個讀操作,多個寫操作的I/O函數進行檢測,直到有數據可讀或可寫(就是監聽多個socket)。select被調用后,進程會被阻塞,內核監視所有select負責的socket,當有任何一個socket的數據準備好了,select就會返回套接字可讀,我們就可以調用recvfrom處理數據。
正因為阻塞I/O只能阻塞一個I/O操作,而I/O復用模型能夠阻塞多個I/O操作,所以才叫做多路復用。
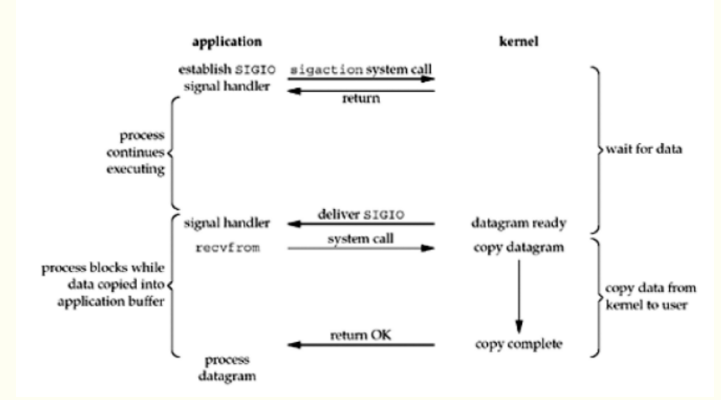
4、信號驅動I/O模型(signal driven I/O, SIGIO)
首先我們允許套接口進行信號驅動I/O,并安裝一個信號處理函數,進程繼續運行并不阻塞。當數據準備好時,進程會收到一個SIGIO信號,可以在信號處理函數中調用I/O操作函數處理數據。當數據報準備好讀取時,內核就為該進程產生一個SIGIO信號。我們隨后既可以在信號處理函數中調用recvfrom讀取數據報,并通知主循環數據已準備好待處理,也可以立即通知主循環,讓它來讀取數據報。無論如何處理SIGIO信號,這種模型的優勢在于等待數據報到達(第一階段)期間,進程可以繼續執行,不被阻塞。免去了select的阻塞與輪詢,當有活躍套接字時,由注冊的handler處理。
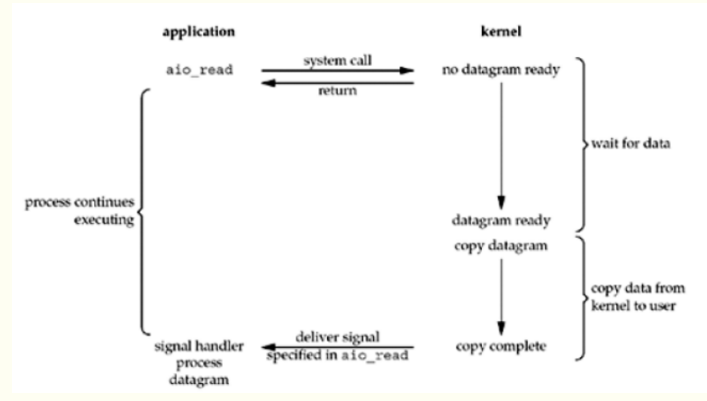
5、異步I/O模型(AIO, asynchronous I/O)
進程發起read操作之后,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之后,首先它會立刻返回,所以不會對用戶進程產生任何block。然后,kernel會等待數據準備完成,然后將數據拷貝到用戶內存,當這一切都完成之后,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
這個模型工作機制是:告訴內核啟動某個操作,并讓內核在整個操作(包括第二階段,即將數據從內核拷貝到進程緩沖區中)完成后通知我們。
這種模型和前一種模型區別在于:信號驅動I/O是由內核通知我們何時可以啟動一個I/O操作,而異步I/O模型是由內核通知我們I/O操作何時完成。
高性能IO模型淺析
服務器端編程經常需要構造高性能的IO模型,常見的IO模型有四種:
(1)同步阻塞IO(Blocking IO):即傳統的IO模型。
(2)同步非阻塞IO(Non-blocking IO):默認創建的socket都是阻塞的,非阻塞IO要求socket被設置為NONBLOCK。注意這里所說的NIO并非Java的NIO(New IO)庫。
(3)IO多路復用(IO Multiplexing):即經典的Reactor設計模式,Java中的Selector和Linux中的epoll都是這種模型。
(4)異步IO(Asynchronous IO):即經典的Proactor設計模式,也稱為異步非阻塞IO。
為了方便描述,我們統一使用IO的讀操作作為示例。
一、同步阻塞IO
同步阻塞IO模型是最簡單的IO模型,用戶線程在內核進行IO操作時被阻塞。
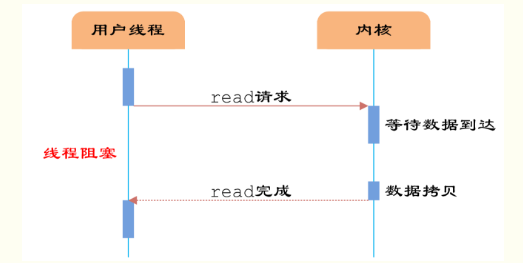
圖1 同步阻塞IO
如圖1所示,用戶線程通過系統調用read發起IO讀操作,由用戶空間轉到內核空間。內核等到數據包到達后,然后將接收的數據拷貝到用戶空間,完成read操作。
用戶線程使用同步阻塞IO模型的偽代碼描述為:
{
read(socket, buffer);
process(buffer);
}
即用戶需要等待read將socket中的數據讀取到buffer后,才繼續處理接收的數據。整個IO請求的過程中,用戶線程是被阻塞的,這導致用戶在發起IO請求時,不能做任何事情,對CPU的資源利用率不夠。
二、同步非阻塞IO
同步非阻塞IO是在同步阻塞IO的基礎上,將socket設置為NONBLOCK。這樣做用戶線程可以在發起IO請求后可以立即返回。
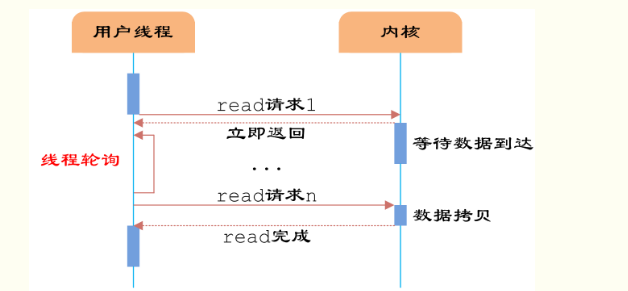
圖2 同步非阻塞IO
如圖2所示,由于socket是非阻塞的方式,因此用戶線程發起IO請求時立即返回。但并未讀取到任何數據,用戶線程需要不斷地發起IO請求,直到數據到達后,才真正讀取到數據,繼續執行。
用戶線程使用同步非阻塞IO模型的偽代碼描述為:
{
while(read(socket, buffer) != SUCCESS)
;
process(buffer);
}
即用戶需要不斷地調用read,嘗試讀取socket中的數據,直到讀取成功后,才繼續處理接收的數據。整個IO請求的過程中,雖然用戶線程每次發起IO請求后可以立即返回,但是為了等到數據,仍需要不斷地輪詢、重復請求,消耗了大量的CPU的資源。一般很少直接使用這種模型,而是在其他IO模型中使用非阻塞IO這一特性。
三、IO多路復用
IO多路復用模型是建立在內核提供的多路分離函數select基礎之上的,使用select函數可以避免同步非阻塞IO模型中輪詢等待的問題。
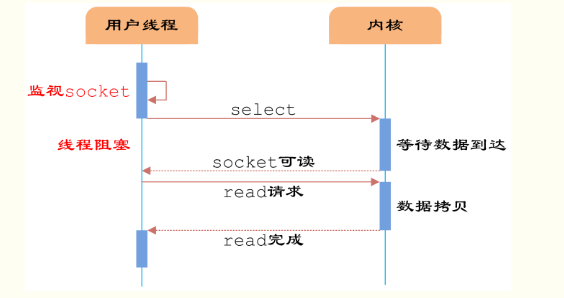
圖3 多路分離函數select
如圖3所示,用戶首先將需要進行IO操作的socket添加到select中,然后阻塞等待select系統調用返回。當數據到達時,socket被激活,select函數返回。用戶線程正式發起read請求,讀取數據并繼續執行。
從流程上來看,使用select函數進行IO請求和同步阻塞模型沒有太大的區別,甚至還多了添加監視socket,以及調用select函數的額外操作,效率更差。但是,使用select以后最大的優勢是用戶可以在一個線程內同時處理多個socket的IO請求。用戶可以注冊多個socket,然后不斷地調用select讀取被激活的socket,即可達到在同一個線程內同時處理多個IO請求的目的。而在同步阻塞模型中,必須通過多線程的方式才能達到這個目的。
用戶線程使用select函數的偽代碼描述為:
{
select(socket);
while(1) {
sockets = select();
for(socket in sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
}
其中while循環前將socket添加到select監視中,然后在while內一直調用select獲取被激活的socket,一旦socket可讀,便調用read函數將socket中的數據讀取出來。
然而,使用select函數的優點并不僅限于此。雖然上述方式允許單線程內處理多個IO請求,但是每個IO請求的過程還是阻塞的(在select函數上阻塞),平均時間甚至比同步阻塞IO模型還要長。如果用戶線程只注冊自己感興趣的socket或者IO請求,然后去做自己的事情,等到數據到來時再進行處理,則可以提高CPU的利用率。
IO多路復用模型使用了Reactor設計模式實現了這一機制。
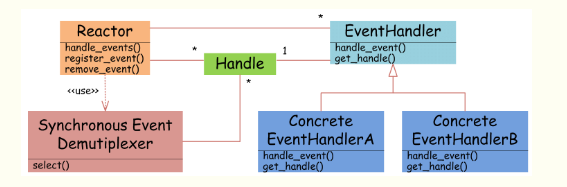
圖4 Reactor設計模式
如圖4所示,EventHandler抽象類表示IO事件處理器,它擁有IO文件句柄Handle(通過get_handle獲取),以及對Handle的操作handle_event(讀/寫等)。繼承于EventHandler的子類可以對事件處理器的行為進行定制。Reactor類用于管理EventHandler(注冊、刪除等),并使用handle_events實現事件循環,不斷調用同步事件多路分離器(一般是內核)的多路分離函數select,只要某個文件句柄被激活(可讀/寫等),select就返回(阻塞),handle_events就會調用與文件句柄關聯的事件處理器的handle_event進行相關操作。
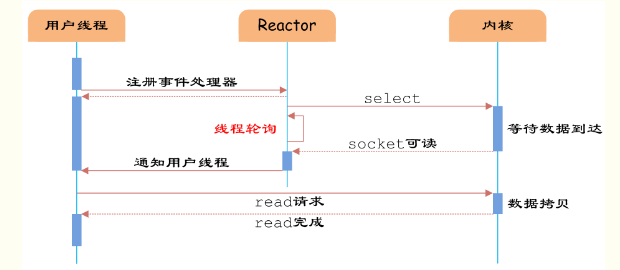
圖5 IO多路復用
如圖5所示,通過Reactor的方式,可以將用戶線程輪詢IO操作狀態的工作統一交給handle_events事件循環進行處理。用戶線程注冊事件處理器之后可以繼續執行做其他的工作(異步),而Reactor線程負責調用內核的select函數檢查socket狀態。當有socket被激活時,則通知相應的用戶線程(或執行用戶線程的回調函數),執行handle_event進行數據讀取、處理的工作。由于select函數是阻塞的,因此多路IO復用模型也被稱為異步阻塞IO模型。注意,這里的所說的阻塞是指select函數執行時線程被阻塞,而不是指socket。一般在使用IO多路復用模型時,socket都是設置為NONBLOCK的,不過這并不會產生影響,因為用戶發起IO請求時,數據已經到達了,用戶線程一定不會被阻塞。
用戶線程使用IO多路復用模型的偽代碼描述為:
void UserEventHandler::handle_event() {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
{
Reactor.register(new UserEventHandler(socket));
}
用戶需要重寫EventHandler的handle_event函數進行讀取數據、處理數據的工作,用戶線程只需要將自己的EventHandler注冊到Reactor即可。Reactor中handle_events事件循環的偽代碼大致如下。
Reactor::handle_events() {
while(1) {
sockets = select();
for(socket in sockets) {
get_event_handler(socket).handle_event();
}
}
}
事件循環不斷地調用select獲取被激活的socket,然后根據獲取socket對應的EventHandler,執行器handle_event函數即可。
IO多路復用是最常使用的IO模型,但是其異步程度還不夠“徹底”,因為它使用了會阻塞線程的select系統調用。因此IO多路復用只能稱為異步阻塞IO,而非真正的異步IO。
四、異步IO
“真正”的異步IO需要操作系統更強的支持。在IO多路復用模型中,事件循環將文件句柄的狀態事件通知給用戶線程,由用戶線程自行讀取數據、處理數據。而在異步IO模型中,當用戶線程收到通知時,數據已經被內核讀取完畢,并放在了用戶線程指定的緩沖區內,內核在IO完成后通知用戶線程直接使用即可。
異步IO模型使用了Proactor設計模式實現了這一機制。
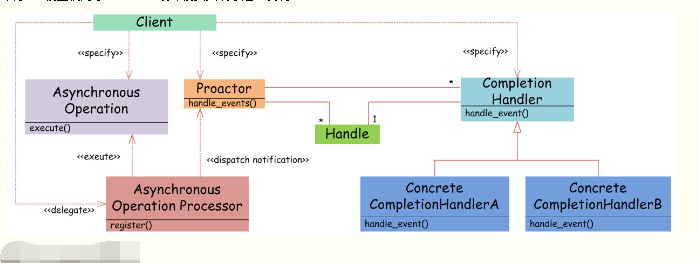
圖6 Proactor設計模式
如圖6,Proactor模式和Reactor模式在結構上比較相似,不過在用戶(Client)使用方式上差別較大。Reactor模式中,用戶線程通過向Reactor對象注冊感興趣的事件監聽,然后事件觸發時調用事件處理函數。而Proactor模式中,用戶線程將AsynchronousOperation(讀/寫等)、Proactor以及操作完成時的CompletionHandler注冊到AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式提供了一組異步操作API(讀/寫等)供用戶使用,當用戶線程調用異步API后,便繼續執行自己的任務。AsynchronousOperationProcessor 會開啟獨立的內核線程執行異步操作,實現真正的異步。當異步IO操作完成時,AsynchronousOperationProcessor將用戶線程與AsynchronousOperation一起注冊的Proactor和CompletionHandler取出,然后將CompletionHandler與IO操作的結果數據一起轉發給Proactor,Proactor負責回調每一個異步操作的事件完成處理函數handle_event。雖然Proactor模式中每個異步操作都可以綁定一個Proactor對象,但是一般在操作系統中,Proactor被實現為Singleton模式,以便于集中化分發操作完成事件。
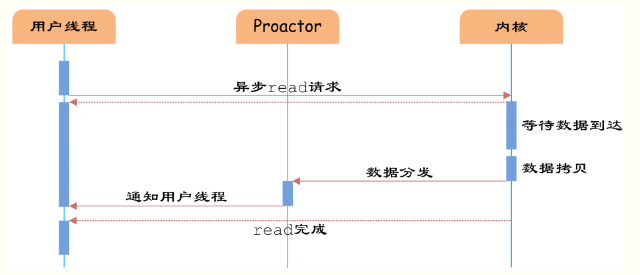
圖7 異步IO
如圖7所示,異步IO模型中,用戶線程直接使用內核提供的異步IO API發起read請求,且發起后立即返回,繼續執行用戶線程代碼。不過此時用戶線程已經將調用的AsynchronousOperation和CompletionHandler注冊到內核,然后操作系統開啟獨立的內核線程去處理IO操作。當read請求的數據到達時,由內核負責讀取socket中的數據,并寫入用戶指定的緩沖區中。最后內核將read的數據和用戶線程注冊的CompletionHandler分發給內部Proactor,Proactor將IO完成的信息通知給用戶線程(一般通過調用用戶線程注冊的完成事件處理函數),完成異步IO。
用戶線程使用異步IO模型的偽代碼描述為:
void UserCompletionHandler::handle_event(buffer) {
process(buffer);
}
{
aio_read(socket, new UserCompletionHandler);
}
用戶需要重寫CompletionHandler的handle_event函數進行處理數據的工作,參數buffer表示Proactor已經準備好的數據,用戶線程直接調用內核提供的異步IO API,并將重寫的CompletionHandler注冊即可。
相比于IO多路復用模型,異步IO并不十分常用,不少高性能并發服務程序使用IO多路復用模型+多線程任務處理的架構基本可以滿足需求。況且目前操作系統對異步IO的支持并非特別完善,更多的是采用IO多路復用模型模擬異步IO的方式(IO事件觸發時不直接通知用戶線程,而是將數據讀寫完畢后放到用戶指定的緩沖區中)。Java7之后已經支持了異步IO,感興趣的讀者可以嘗試使用。
非常好我支持^.^
(101) 97.1%
不好我反對
(3) 2.9%
相關閱讀:
- [電子說] NB-IOT無線傾角傳感器用于伊利智能貨架安全監測的具體案例 2023-10-24
- [電子說] iOS17.1可能明天發布,iOS17.1主要修復哪些問題? 2023-10-24
- [電子說] 設備互聯(IOT數據采集)平臺有什么功能 2023-10-24
- [電子說] 學習STM32F103的ADC功能 2023-10-24
- [物聯網] 介紹保護物聯網設備安全的11種方法 2023-10-24
- [電子說] 學習STM32F103的DAC功能 2023-10-24
- [電子說] STM32基礎知識:GPIO(通用輸入輸出接口) 2023-10-24
- [電子說] 遠程IO模塊物聯網應用提高工業自動化生產效率 2023-10-24
( 發表人:龔婷 )