 電子發燒友App
電子發燒友App


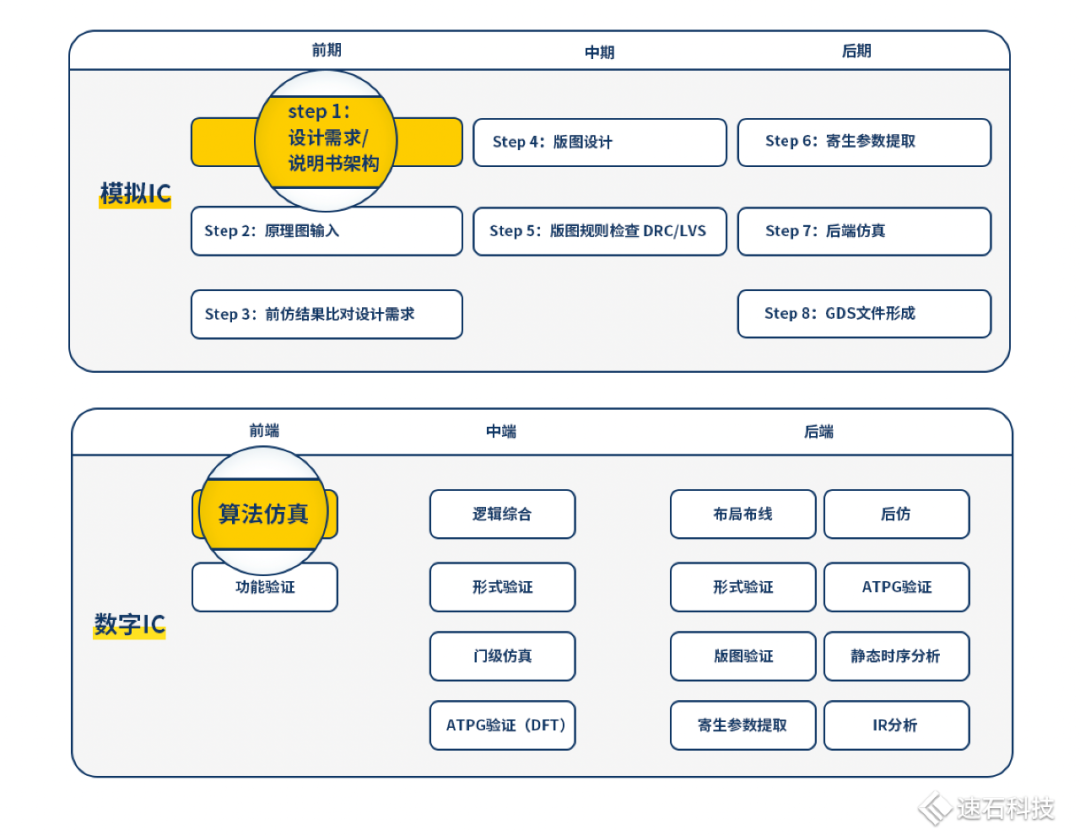
第三集:算法仿真
算法是對芯片系統進行的整體戰略規劃,決定了芯片各個模塊功能定義及實現方式,指引著整個芯片設計的目標和方向。可謂,牽一發而動全身。
不管是模擬IC還是數字IC設計,算法仿真都是第一步。通常,會由算法工程師組成獨立的算法團隊。
CPU/GPU本應該是算法仿真的常客,但因為歷史比較悠久,發展成熟,市場幾乎被英偉達和AMD壟斷,很多IC設計公司選擇直接采購IP的方式跳過這一步。
近幾年,無線通信芯片成為了算法業務的最大甲方。因為這類芯片的信號編解碼與頻譜遷移時方式十分復雜,再加上種類繁多,各國的通信協議、標準、頻率也在不斷變化。隨著我國5G通信標準的放開,算法仿真的地位與日俱進。
另一個涉及大量算法業務的場景是AI芯片,應用場景小到手機、智能家電,大至汽車。
跟前兩篇數字和模擬IC的設計場景相比,算法仿真有著非常不一樣的表現。
所以我們單獨把ta拉出來,結合一家無線通信芯片公司實際業務場景,看看算法仿真有哪四大特性,以及從動態視角出發,看我們怎么幫算法工程師解決問題,提高研發效率。
算法仿真的本質
算法(Algorithm),是指在數學和計算機科學間,一種被定義好的、計算機可施行指示的步驟和次序。算法代表著用系統的方法描述解決問題的策略機制,解決一個問題可以有很多種算法。
舉個栗子。
求解下圖黃色區域圖形面積,我們有三種算法。
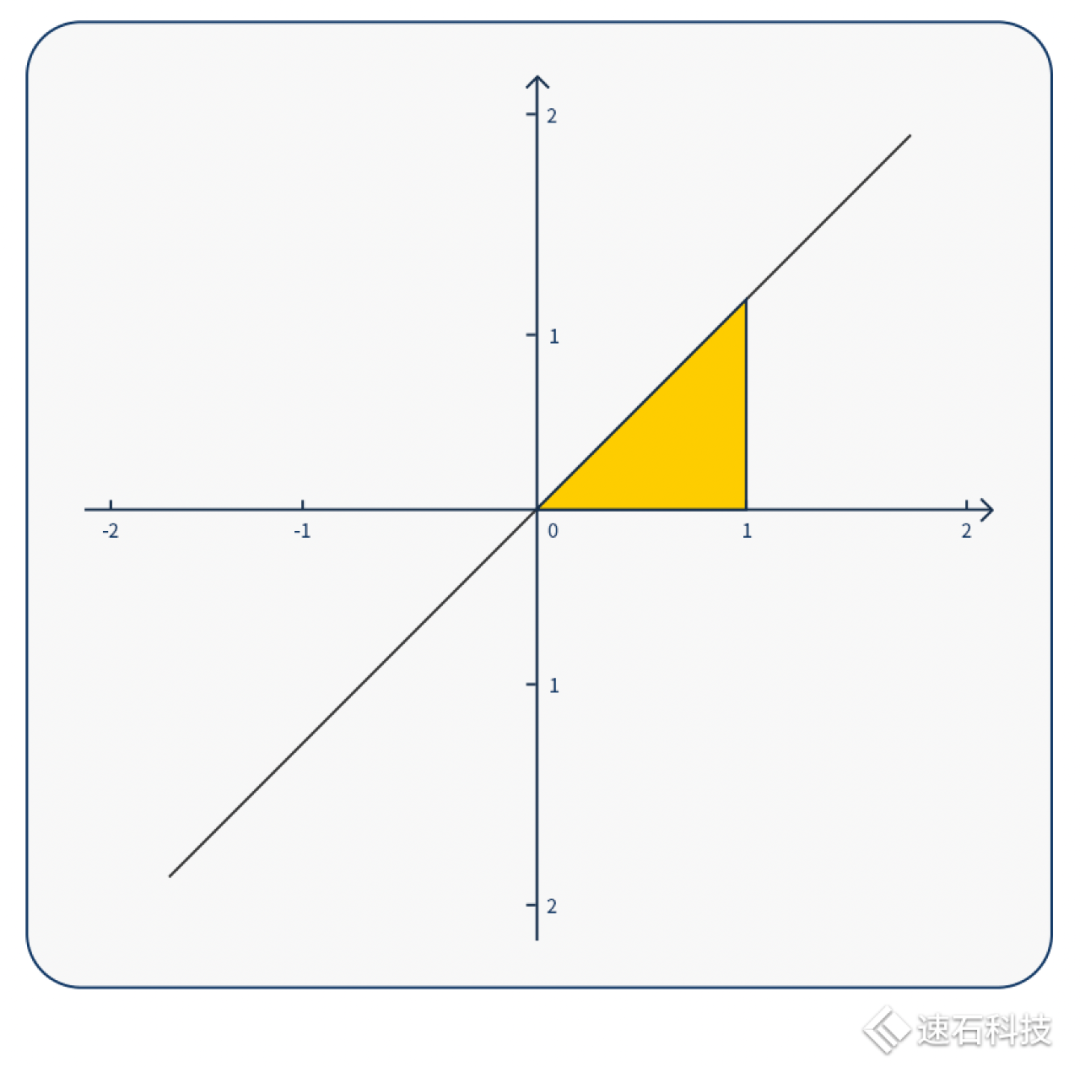
方法一:你可以直接用三角形的面積公式解。這種方法快速、直觀,小學文化程度即可,但局限性也高、不通用,不適用于圖像復雜的情況;
方法二:也可以用符號計算求不定積分。求解析解方法,適用于各類不定積分中有解析表達式的函數圖像。計算門檻較高,大多手算,很少有計算工具。而且實際工程應用場景中,很多函數沒有解析解;
方法三:用數值計算方式解積分,求數值解。數值計算法適用范圍最廣,可以求任意函數曲線的定積分,將函數一段段分解,再算出面積。不同的分解方法就代表不同的算法。這種方法只能求數值解,無法求解析解,且計算量巨大,適合機器計算,不適合人工計算,在工程領域應用甚廣。
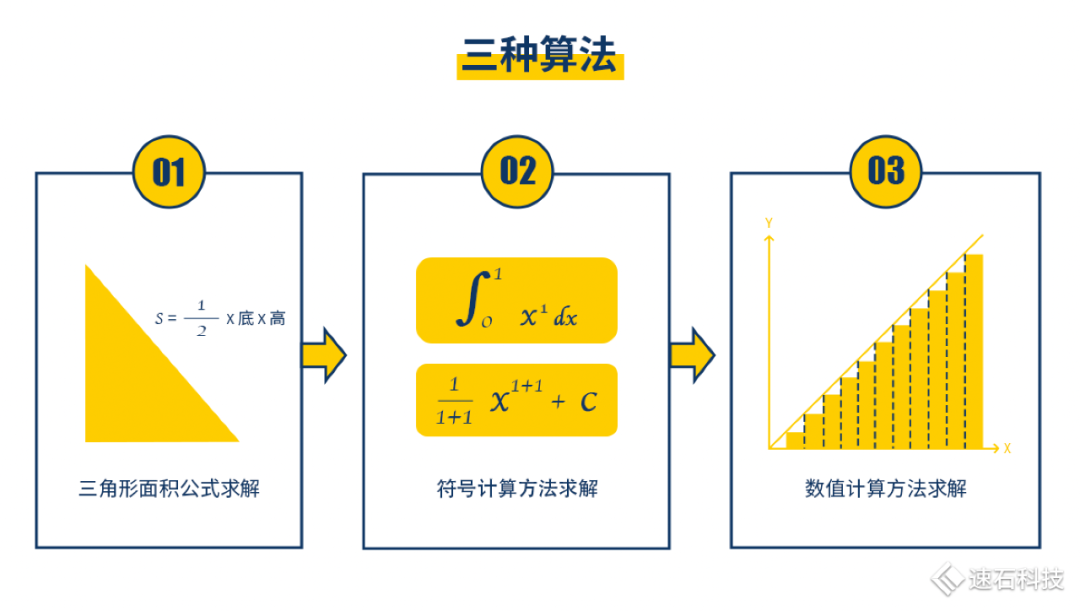
在芯片設計領域,算法仿真的本質是評估不同數值計算解法的工作量、計算效率適用范圍,選出最優算法,使ta不僅要滿足算得最快、最準,還要能確保功能、精度、效率、吞吐量等指標。
算法仿真是一個不斷迭代、優化的過程,一般都要反復調整參數,進行N次回歸測試。
一家算法團隊的小目標
一家無線通信芯片公司算法團隊,開局情況如下:
算法部門共有15人,全公司有480核共享本地資源,各部門按需提前申請使用。
根據公司的業務發展目標,大致估算出未來新算法項目任務總數為1283980。
假設一:全公司本地資源均歸他們用,每個人的資源上限是32核;
假設二:單case運行時間為10小時;
假設三:回歸測試次數為1次;
假設四:1個case只有1個job,且只用1個核。

總運行時間達到3.05年。 ? 啊這。。 可能打開方式不對,再來: 增加假設五:人均資源上限逐漸提升到120核; 假設六:算法團隊人數逐步擴張至46人;
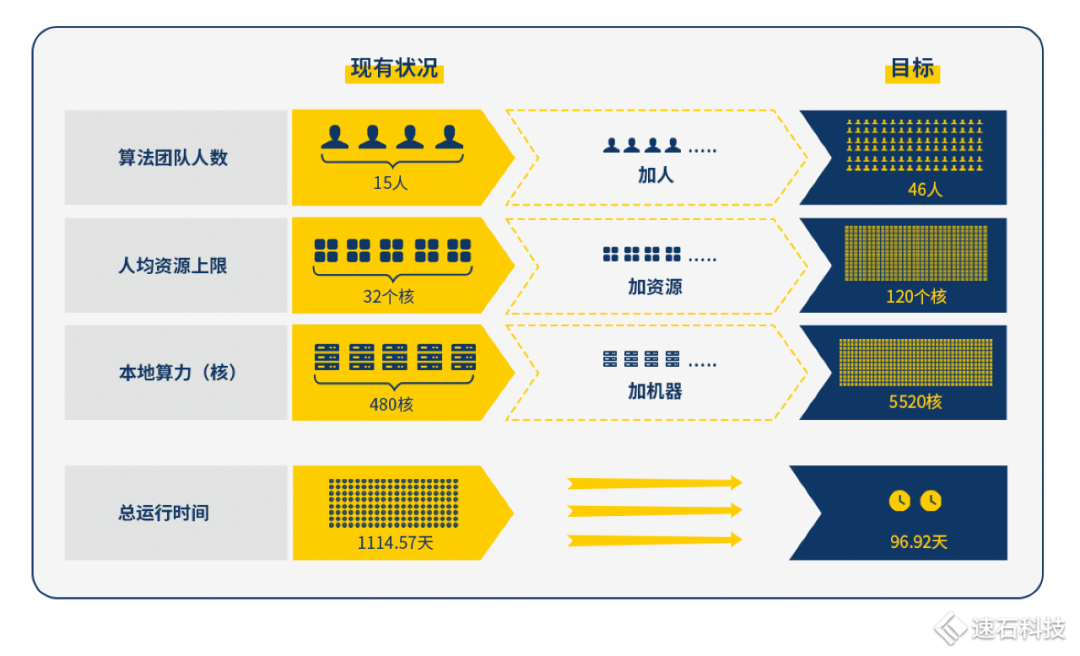
總運行時間約96.92天。
嗯,這回挺好。
想得是挺美,小目標怎么實現?
現實一:公司共享本地資源不可能只歸算法部門專用;
現實二:單case運行時間,難以估計;且1個case往往不止1個job,且1個job未必只用1個核;
現實三:回歸測試只有1次,幾乎不太可能,總任務數可能數倍增長;
現實四:本地機房從480核要擴張十幾倍,可不止是買買買硬件,機房建設、運維人力、硬件維保、存儲網絡、環境部署等等,都不是小事;
現實五:算法工程師要求非常高,招聘難度極大。
真是,沒一個字讓人愛聽的。
但算法仿真這里,此路不通。
我們來看看算法仿真的特性:
算法仿真的四大特性
下圖是這家無線通信芯片公司算法團隊9個月實際日平均資源用量波動總覽圖:
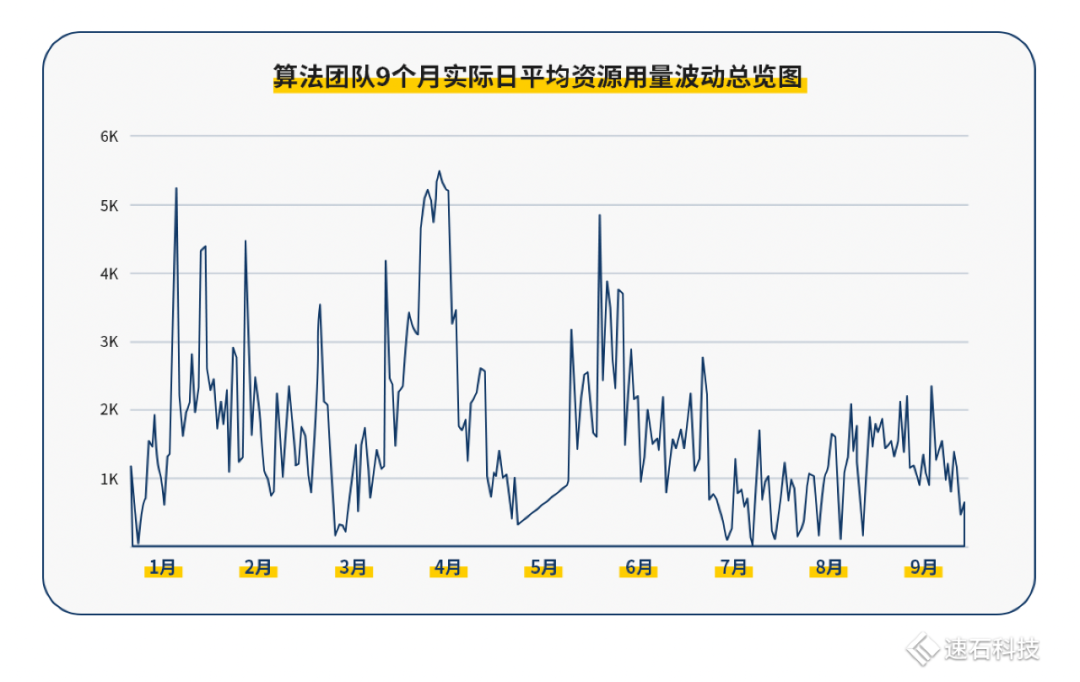
01
需求不可測
從個人角度出發,算法團隊每個人的算法任務都是互相獨立,互不影響的。算法確定之后,每一輪的計算量基本確定(case分解成的job數,job占用的核數基本確定),每個算法任務的單次耗時與回歸測試次數都是不一樣的,這導致最后的資源需求完全不可測。
如果再疊加團隊使用因素,資源的不可測性也會被成倍地放大。如果原先個人的資源使用區間是0到250核小時;如果團隊內有20人,那不可測區間就放大至0至5000核小時。
02
短時間使用量波動巨大
除了算法任務需求的不可測性,資源使用量的波動還受實際算法任務的進度影響。
每個算法工程師的工作獨立且進度不一,有時可能大量任務同時批量運行,也可能部分在調試,部分在運行,甚至可能一個在運行的任務都沒有。
不同工程師的工作進度差異與所用算法不一,不僅導致了波峰、波谷間的資源使用量差距極大,而且這樣的波動可能發生在極短時間內。
極限情況:所有工程師都在頂格跑任務,5520核的資源量瞬間拉滿(100%);而下一刻只有10%的工程師在跑任務,且每人都只使用自己配額80%的資源量,那總資源僅使用了一部分。
不同公司的算法團隊之間,因為團隊規模與業務差異,資源用量差異也非常大。
03
資源需求類型多樣
算法仿真整體來說,對資源的各方面需求并不算高。
但不同算法的需求都不一樣:
有的需要單核4G內存的機型,有的要單核8G內存的機型;
有的算法對存儲要求高,有的算法對存儲沒要求:
有的涉及圖形計算,甚至還需要用到GPU機型。
04
長期可持續狀態
上述三大特性,都不是突發現象,屬于算法團隊的日常工作狀態。
這一狀態的長期可持續性,我們需要對此做好足夠的準備。
一種動態思路:增加時間維度
算法仿真的四大特性決定了:按這家公司原來的靜態處理方式,也就是把任務量當成恒定的,通過加人加機器的方式來滿足研發需求,變得很不現實。哪怕頂格準備資源,資源利用率也會長期處于較低狀態。
那按動態處理方式,也就是隨著時間變化,靈活根據需求匹配不同規模/類型資源的方式來動態滿足研發需求,從個人及團隊視角出發,看我們怎么幫算法工程師解決問題,提高研發效率。
01
算法工程師視角
1)資源無需申請,即開即用 再也不用跟同事搶資源或者漫長的排隊等待了,也不用走繁瑣的資源申請流程。 ? 2)資源選擇空間變大 選擇空間變大,資源類型變多,可用資源上限變高,可以靈活選擇更加適配算法任務的資源類型。 ? ? 3)提交任務立馬就能跑,告別等待 提交任務立馬就能跑,一整套研發環境現成的,即開即用。 靈活切換,今天跑一百,明天跑一萬,無需等待環境配置。 ? 4)以前怎么用,現在就怎么用 跟本地相比無感知,用戶使用習慣沒有任何改變,不需要調整任何腳本。 ? 5)任務跑得快,效率線性增長 多case高并發執行。同一批算法任務之間互相獨立,可以做到效率線性提升。 ?
02
團隊管理視角
1)動態方式解決資源不可測問題 算法任務的不可預測且波動巨大,導致了資源預測與規劃基本不可能。 按傳統靜態處理方式來解決問題: 按頂格規劃,這筆賬都不用算,會造成黃色區域的巨大浪費; 按中間取值準備,當某個時間點算法仿真短時間內任務量激增,就會出現人機不匹配,不是有人力沒機器,就是有機器沒人力。這種錯配導致資源利用率極低,影響研發進度。
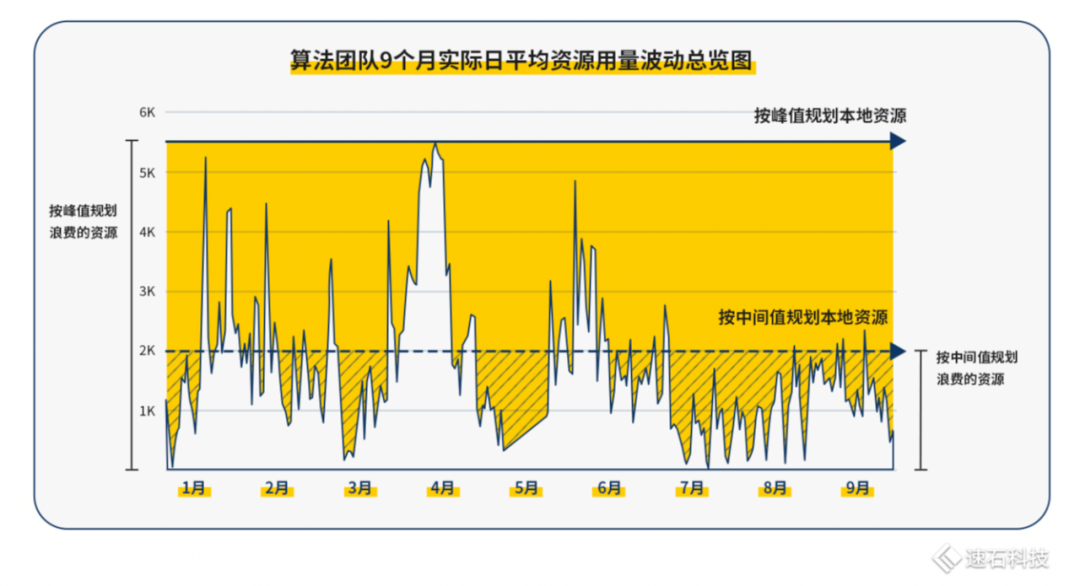
圖中3-5月,峰值算力就從200核攀升27倍達到5520核,隨即又迅速從5520核下跌到500核左右,這波動幅度簡直比過山車還劇烈,而且毫無規律。 ? 我們的動態處理方式,會隨著時間變化,靈活根據當前時間點任務需求匹配不同規模/類型資源的方式,動態滿足研發需求。 不管500核還是5000核,我們都能實時根據需要,滿足整個團隊的大幅波動資源需求,保障日常算力和峰值算力任務調度效率。 ? 2)Auto-Scale自動伸縮,隨用隨關不浪費? Fsched調度器的Auto-Scale功能,能解決團隊資源利用率與成本問題。資源“自由”的同時不浪費。 ? 一方面隨用戶任務需求,設置自動伸縮上下限,自動化調用資源完成任務; Auto-Scale功能可以根據任務運算情況動態開啟云端資源,需要多少開多少,并在任務完成后自動關閉,讓資源的使用緊隨著用戶的需求自動擴張及縮小,最大程度匹配任務需求。
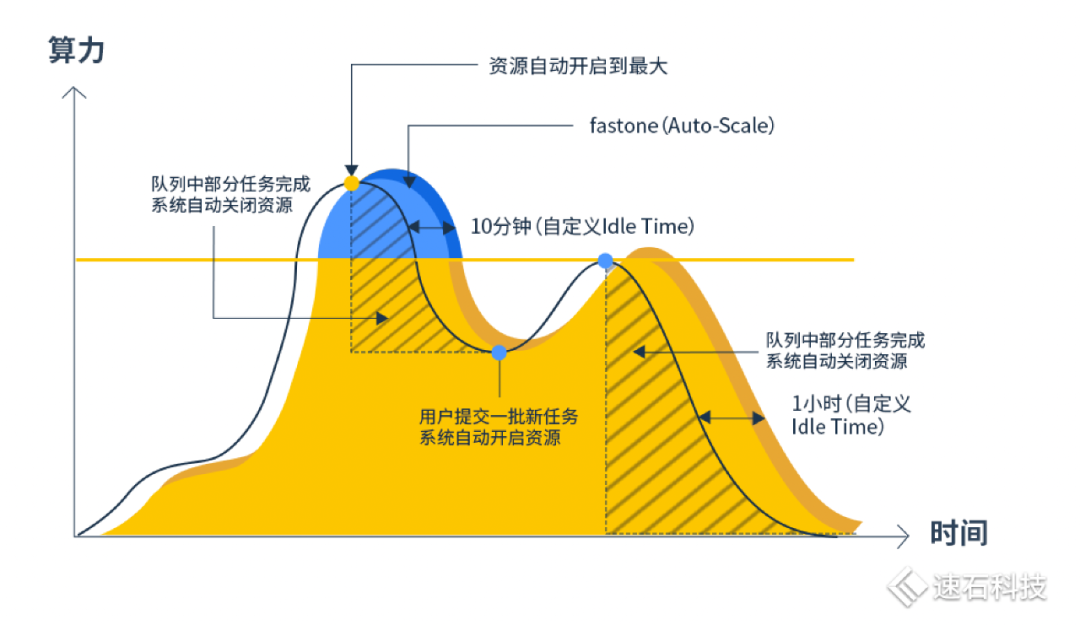
這既節約了用戶成本,不需要時刻保持開機,也最大限度保證了任務最大效率運行。中間也不需要用戶干預,手動操作。
另一方面我們還能監控用戶提交的任務數量和資源需求,在團隊內部進行資源及時適配,解決錯配問題。 ? ? 3)提升團隊整體運營效率 我們的運營數據dashboard能讓團隊管理者監控各個重要指標變化,從全局角度掌握項目的整體任務及資源情況,為未來項目合理規劃、集群生命周期管理、成本優化提供支持。 還能根據不同成員或小組的業務緊迫程度和業務重要性,合理分配與控制用戶使用資源。 ? 4)全球數據中心解決資源瓶頸 我們的全球數據中心,能持續穩定地提供用戶所需資源類型及數量,分鐘級調度開啟上萬核計算資源,滿足業務緊迫度。 用戶可以選擇自主選擇大內存、高主頻等多樣化的資源類型來滿足不同算法需求。一旦發現所選資源類型與算法任務不匹配,還可隨時中止任務、更換資源類型,任務進度不受影響。 ? ? ?
編輯:黃飛
?












 工商網監
工商網監
評論