 電子發(fā)燒友App
電子發(fā)燒友App


如圖1a中所示的那樣,基本交織耦合鎖存器和有源負(fù)載單元組成了6T存儲單元,這種單元可以用于容量從數(shù)位到幾兆位的存儲器陣列。
經(jīng)過精心設(shè)計(jì)的這種存儲器陣列可以滿足許多不同的性能要求,具體要求取決于設(shè)計(jì)師是否選用針對高性能或低功率優(yōu)化過的CMOS工藝。高性能工藝生產(chǎn)的SRAM塊的存取時(shí)間在130nm工藝時(shí)可以輕松低于5ns,而低功率工藝生產(chǎn)的存儲器塊的存取時(shí)間一般要大于10ns。
存儲單元的靜態(tài)特性使所需的輔助電路很少,只需要地址譯碼和使能信號就可以設(shè)計(jì)出解碼器、檢測電路和時(shí)序電路。
隨著一代代更先進(jìn)工藝節(jié)點(diǎn)的發(fā)展,器件的特征尺寸越來越小,使用傳統(tǒng)六晶體管存儲單元制造的靜態(tài)RAM可以提供越來越短的存取時(shí)間和越來越小的單元尺寸,但漏電流和對軟故障的敏感性卻呈上升趨勢,設(shè)計(jì)師必須增加額外電路來減小漏電流,并提供故障檢測和糾正機(jī)制來“擦除”存儲器的軟故障。
當(dāng)前6T SoC RAM單元的局限性
然而,用來組成鎖存器和高性能負(fù)載的六晶體管導(dǎo)致6T單元尺寸很大,從而極大地限制了可在存儲器陣列中實(shí)現(xiàn)的存儲容量。
這種限制的主因是存儲器塊消耗的面積以及由于用于實(shí)現(xiàn)芯片設(shè)計(jì)的技術(shù)工藝節(jié)點(diǎn)(130,90,65nm)導(dǎo)致的單元漏電。隨著存儲器陣列的總面積占整個(gè)芯片面積的比率增加,芯片尺寸和成本也越來越大。
漏電流也可能超過整個(gè)功率預(yù)算或限制6T單元在便攜式設(shè)備中的應(yīng)用。更大面積或高漏電芯片最終可能無法滿足應(yīng)用的目標(biāo)價(jià)格要求,因此無法成為一個(gè)經(jīng)濟(jì)的解決方案。
作為6T RAM單元替代技術(shù)的1T單元
對那些要求大容量片上存儲(通常大于256kb)但不要求絕對最快存取時(shí)間的應(yīng)用來說還有另外一種解決方案技術(shù)。這種解決方案所用的存儲器陣列功能類似SRAM,但基于的是類似動(dòng)態(tài)RAM中使用的單晶體管/單電容(1T)存儲器單元(圖1b)。

圖1a:典型的六晶體管靜態(tài)RAM存儲單元。圖1b:典型的單晶體管/單電容動(dòng)態(tài)存儲器存儲單元。
這種存儲器陣列在相同芯片面積上的密度可以達(dá)到6T存儲器陣列的2到3倍。當(dāng)嵌入式存儲器要求超過幾兆位時(shí)可以使用簡單的動(dòng)態(tài)RAM陣列,但這種陣列要求系統(tǒng)控制器和邏輯理解存儲器的動(dòng)態(tài)特性,并正確地提供刷新控制和時(shí)序信號。
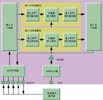
嵌入簡單DRAM存儲器塊的另外一種方法是將DRAM陣列和它自身的控制器捆綁在一起,使它看起來像是易于使用的SRAM陣列。通過整合高密度1T存儲單元和提供刷新信號的一些支持邏輯,存儲單元的動(dòng)態(tài)特性對ASIC/SoC設(shè)計(jì)師來說是看不見的,設(shè)計(jì)師在實(shí)現(xiàn)ASIC和SoC解決方案時(shí)可以將它們當(dāng)作靜態(tài)RAM使用(圖2)。

圖2:DRAM存儲器陣列周圍增加的控制和接口支持邏輯使得該陣列用起來像靜態(tài)RAM,因此可以提高存儲器密度。
一些公司和代工廠已經(jīng)開發(fā)的1T單元除了標(biāo)準(zhǔn)CMOS層外還需要額外的掩模層。因此這種方法增加了晶圓成本,并且與具體的代工廠密切相關(guān),只能將制造過程限制于特定的代工廠。為了彌合額外的晶圓處理成本,芯片中使用的總的DRAM陣列尺寸一般必須超過裸片面積的一半以上。另外,大部分DRAM宏是尺寸、長寬比和接口都受限的硬宏。
SoC設(shè)計(jì)則需要更具性價(jià)比的IP宏,根據(jù)成本或容量的需要,這些IP宏可以方便地在任何代工廠中制造,或者從一個(gè)代工廠轉(zhuǎn)移到另一個(gè)代工廠。在版圖和配置階段,這種宏還能向ASIC設(shè)計(jì)師提供更多的靈活性。
多家代工廠擁有這種所謂的“單晶體管SRAM”技術(shù),并作為可授權(quán)的知識產(chǎn)權(quán)。這樣一種以編譯器為主導(dǎo)的方法已見用于bulk CMOS工藝中,由于沒有額外的掩模步驟,因此可以降低15-20%的晶圓成本,并可縮短產(chǎn)品上市時(shí)間。
對于系統(tǒng)的其它部分來說,上述方法形成的存儲塊接口看起來就像是一個(gè)靜態(tài)RAM,但與采用6T單元的存儲器陣列相比,它的密度(單位面積的位數(shù))可以達(dá)到后者的2到3倍(在將作為面積計(jì)算一部分的支持電路開銷進(jìn)行平均后)。存儲器陣列越大,支持電路需要的總面積就越小,存儲塊就有更高的面積效率。
為了創(chuàng)建理想的存儲器陣列,可以使用像MemQuest這樣的存儲器編譯器工具。這些工具允許設(shè)計(jì)師實(shí)現(xiàn)更冷、更快或更高密度的coolSRAM-1T配置,這些配置可以在不同的代工廠和技術(shù)節(jié)點(diǎn)間移植(見圖3),從而可以避免人工陣列實(shí)現(xiàn)所需的非重復(fù)性工程費(fèi)用。

圖3:便攜式coolSRAM-1T設(shè)計(jì)用于特別低功率的設(shè)備,它通過自適應(yīng)電路尺寸調(diào)整、虛擬接地、自適應(yīng)后向偏置和其它電路技術(shù)來降低漏電流。
編譯器還可以幫助用戶使用最優(yōu)的內(nèi)核尺寸、接口和長寬比并實(shí)現(xiàn)最短的上市時(shí)間,并向設(shè)計(jì)師提供它編譯的存儲器陣列的電氣、物理、仿真(Verilog和VHDL)、測試和綜合結(jié)果。
在一個(gè)1Mb的存儲器陣列實(shí)例中,例如coolSRAM-1T配置,存在著室溫下為數(shù)微安的漏電流,對于供電電壓和時(shí)鐘速率來說這是一個(gè)典型的邊界條件(圖3)。
在采用100kHz或100kHz以下的典型刷新速率以及128k字×8位的組織結(jié)構(gòu)時(shí),1Mb coolSRAM-1T陣列有一個(gè)空閑功率能使數(shù)據(jù)保持時(shí)間與同樣容量的SRAM相當(dāng)。(coolSRAM-6T的1Mb實(shí)例在采用臺積電公司的130nm G工藝制造時(shí)將占用約2.6平方毫米的面積,每兆赫茲消耗功率小于100微瓦)
雖然SRAM-1T功能如同SRAM,但內(nèi)部卻具有DRAM的特征-當(dāng)采用130nm工藝實(shí)現(xiàn)時(shí),室溫下的存儲單元可以保持?jǐn)?shù)據(jù)數(shù)十毫秒的時(shí)間。支持的刷新控制邏輯透明地提供刷新功能,并能根據(jù)溫度調(diào)節(jié)刷新周期。
如果設(shè)計(jì)師想用SoC管理刷新,也可以選擇旁路掉存儲器陣列中的刷新控制器,使用來自SoC邏輯的刷新信號。這樣可以有效地節(jié)省SoC中的一些動(dòng)態(tài)功耗,因?yàn)橄到y(tǒng)邏輯可以“按需”而不是“自動(dòng)”實(shí)現(xiàn)SRAM-1T的嵌入式刷新邏輯。
SRAM-1T實(shí)例中的存儲單元也支持睡眠和待機(jī)模式。在睡眠模式時(shí),可以通過抑制大部分存儲器陣列的時(shí)鐘來極大地降低功耗。
當(dāng)陣列“被喚醒時(shí)”,數(shù)據(jù)必須被重新裝載進(jìn)存儲單元。在待機(jī)模式時(shí),存儲器通過使用低頻刷新操作使數(shù)據(jù)得以保持,此時(shí)功耗是很小的。當(dāng)返回到工作模式時(shí),存儲器可以立即投入使用,數(shù)據(jù)不需要重新被裝載進(jìn)存儲器陣列。
設(shè)計(jì)師還能通過配置讓存儲器陣列以不同的行尺寸-256、512、1024或2048位進(jìn)行刷新,甚至實(shí)現(xiàn)多行同時(shí)刷新。還允許設(shè)計(jì)師有選擇的只刷新陣列的一小部分以保持關(guān)鍵數(shù)據(jù)不丟失,同時(shí)切斷陣列其余部分的供電。
對任何存儲器陣列來說,制造工藝的變化總是有可能導(dǎo)致存儲器陣列中出現(xiàn)一二個(gè)壞的位。這樣的芯片不一定要廢棄,設(shè)計(jì)師只需增加列和行冗余機(jī)制就能提高良品率。
如果芯片交付后發(fā)生位故障,可以采用內(nèi)置自修復(fù)功能以及一次性可編程coolOTP存儲器修復(fù)存儲器陣列。另外,內(nèi)置自檢功能也可以增加進(jìn)存儲器IP塊中,它不會影響芯片的性能。
當(dāng)存儲器陣列的基本性能不能滿足系統(tǒng)需要時(shí),設(shè)計(jì)師可以使用一些結(jié)構(gòu)化技術(shù)從存儲器陣列中獲得更高的性能。然而,使用這些技術(shù)需要付出一定的代價(jià),它們會影響芯片的功耗、尺寸和復(fù)雜性,因此必須認(rèn)真地進(jìn)行權(quán)衡分析,確定最佳的存儲器陣列和芯片架構(gòu)組合,這樣才能實(shí)現(xiàn)理想的性能和成本目標(biāo)。
對芯片架構(gòu)設(shè)計(jì)師來說使用寬字架構(gòu)是一種不錯(cuò)的選擇,它能將存儲器組織成在內(nèi)部提供128、256或1024位寬數(shù)據(jù)字,然后向下復(fù)用成想要的字寬度(見圖4)。

圖4:在典型的SoC設(shè)計(jì)中,寬的內(nèi)部存儲器總線可以用來快速傳送圖形和DSP處理中的實(shí)時(shí)性數(shù)據(jù)。
這種技術(shù)可以將視在時(shí)鐘速率(apparent clock rate)提高2倍或4倍,從而減少實(shí)際存取時(shí)間,最終降低功耗。在這種情況下,由于需要解復(fù)用邏輯將寬字減小到適合SoC其余部分使用的合適寬度字,會對IP設(shè)計(jì)產(chǎn)生面積上的消極影響。
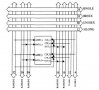
另外一種方法是將存儲器劃分成多個(gè)實(shí)例(區(qū)),并設(shè)置存儲器控制器,讓它以連續(xù)周期交替訪問這些實(shí)例(instance),這樣通過區(qū)與區(qū)之間的切換就可以隱藏掉某段存取時(shí)間(見圖5a)。
圖5a:通過增加一些額外的控制和時(shí)序電路可以實(shí)現(xiàn)多個(gè)存儲實(shí)例(區(qū))的交叉存取,從而將到主處理器的數(shù)據(jù)速率提高2倍、3倍甚至4倍(取決于區(qū)的數(shù)量)。
在非交織存取系統(tǒng)中,存儲器子系統(tǒng)必須工作在系統(tǒng)時(shí)鐘速度,此時(shí)如果存儲器訪問不能同步于時(shí)鐘,那么整個(gè)系統(tǒng)的運(yùn)行速度就會慢下來(見圖5b)。
圖5b:在非交叉存取系統(tǒng)中,存儲器區(qū)的訪問時(shí)間會在訪問存儲器陣列時(shí)限制系統(tǒng)時(shí)鐘速度。
但在交織存取的存儲器系統(tǒng)中,時(shí)鐘頻率可以2倍、3倍、4倍的提升,具體取決于區(qū)的數(shù)量。但當(dāng)交織存取超過兩個(gè)區(qū)時(shí),系統(tǒng)復(fù)雜性會有相當(dāng)大的增加。
對于雙區(qū)系統(tǒng),時(shí)鐘頻率可以是每個(gè)存儲區(qū)可處理的最大速度的2倍,但由于每個(gè)實(shí)例是以時(shí)鐘頻率的一半循環(huán)的,單個(gè)區(qū)不能感受到時(shí)鐘速度的變化(見圖5c)。
圖5c:在交叉存取的多區(qū)系統(tǒng)中,時(shí)鐘速度可以達(dá)到非交叉存取時(shí)鐘速度的數(shù)倍(時(shí)鐘x區(qū)數(shù)量)。
而且,圍繞存儲區(qū)的一些全局邏輯以雙倍于存儲器速度運(yùn)行,并在交替時(shí)鐘周期中向兩個(gè)區(qū)中的每個(gè)區(qū)傳遞地址信息。這種全局邏輯可以在多個(gè)區(qū)中 共享,從而可以節(jié)省面積和功率。
數(shù)據(jù)輸入/輸出端口的附加邏輯對數(shù)據(jù)進(jìn)行復(fù)用或解復(fù)用,并向主機(jī)系統(tǒng)以雙倍數(shù)據(jù)速率提供數(shù)據(jù),或以輸入速率的一半向存儲區(qū)提供數(shù)據(jù)。因此存儲器子系統(tǒng)的有效吞吐量提高了一倍,而有效功率比兩倍存儲容量的單個(gè)塊要低。
雖然這種方法可以將存取時(shí)間縮短近50%,但也帶來了額外的支持電路和設(shè)計(jì)/時(shí)序復(fù)雜性。此時(shí)對存儲器的數(shù)據(jù)訪問一般都要被延遲一個(gè)周期(單周期延遲訪問),并且訪問是準(zhǔn)隨機(jī)性的,系統(tǒng)無法在每個(gè)周期訪問相同的內(nèi)部區(qū)。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論