 電子發燒友App
電子發燒友App


2009 年 1 月 3 日,比特幣作為一種自持的 P2P 系統啟動了創世區塊,以巧妙的設計驅使參與者維持它的運轉,并提供受限但極具顛覆性的金融功能至今。2015 年 6月 30 日,以太坊上線,為區塊鏈增加了圖靈完備的智能合約,可以對一些短小的程序的執行結果形成共識。相對于比特幣,以太坊可以執行更復雜的計算,提供更豐富的響應,然而這些合約是不具備學習能力和自我進化規則的,是純粹的基于簡單規則(rule-based) 與遞歸調用的子程序的集合。參考 Conway 的生命游戲,基于 P2P 技術的虛擬貨幣網絡可以被界定為生存在互聯網上的生命,通過提供金融功能維持自身的存在,只要還有一個全節點在,網絡的狀態就可以得到保存,并且能夠響應來自外界的交互。然而人類渴望的智能還沒有出現,這些原始的網絡生命只停留在簡單規則的水平。
Cortex 在此基礎上更進一步,為區塊鏈增加了人工智能的共識推斷,所有全節點共同運作,對一個要求人工智能的智能合約的執行達成共識,為系統賦予智能響應的能力。Cortex 作為一條兼容 EVM 智能合約的獨立公鏈,可以運行現有的合約和帶有人工智能推斷的合約,在創世區塊發布后,也將作為一個更加智能的網絡生命永續存在下去。在 Cortex 中,由于開源和天然的競爭機制,最優秀的模型終將會存留下來,提升網絡的智能水平。從機器學習研究者的角度來講,Cortex 平臺集合了各種基本智能應用的公開模型,并且是當前的世界級水準 (state of the art),這將大大加速他們的研究,并朝向 AI in All 的智能世界快速前進。這條公鏈同時使得模型在部署后的計算結果自動地得到全網公證。外星人存在與否我們尚不可知,但有人工智能的陪伴,人類不再孤獨前行。
系統架構
1.擴充智能合約和區塊鏈的功能
Cortex 智能推斷框架
模型的貢獻者將不限于 Cortex 團隊,全球的機器學習從業人員都可以將訓練好的相應數據模型上傳到存儲層,其他需要該數據模型的用戶可以在其訓練好的模型上進行推斷,并且支付費用給模型上傳者。每次推斷的時候,全節點會從存儲層將模型和數據同步到本地。通過 Cortex 特有的虛擬機 CVM (Cortex Virtual Machine) 進行一次推斷,將結果同步到全節點,并返回結果。
將需要預測的數據進行代入計算到已知一個數據模型獲得結果就是一次智能推斷的過程。用戶每發起一筆交易,執行帶有數據模型的智能合約和進行推斷都需要支付一定的 Endorphin,每次支付的 Endorphin 數量取決于模型運算難度和模型排名等。Endorphin和 Cortex Coin 會有一個動態的轉換關系,Endorphin 的價格由市場決定,反映了Cortex 進行模型推斷和執行智能合約的成本。這部分 Endorphin 對應的 Cortex Coin會分成兩個部分,一部分支付給智能合約調用 Infer 的模型提交者,另一部分支付給礦工作為打包區塊的費用。對于支付給模型提交者的比例,Cortex 會為這個比例設定一個上限。
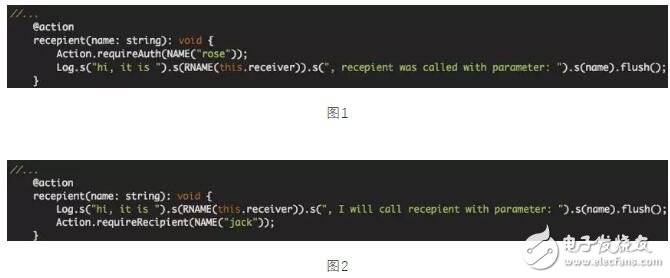
ortex 在原有的智能合約中額外添加一個 Infer 指令,使得在智能合約中可以支持使用 Cortex 鏈上的模型。
下述偽代碼表述了如何在智能合約里使用 Infer ,當用戶調用智能合約的時候就會對這個模型進行一次推斷:
模型提交框架
前面分析了鏈上訓練的難處和不可行性,Cortex 提出了鏈下 (Offchain) 進行訓練的提交接口,包括模型的指令解析虛擬機。這能夠給算力提供方和模型提交者搭建交易和合作的橋梁。
用戶將模型通過 Cortex 的 CVM 解析成模型字符串以及參數,打包上傳到存儲層,并發布通用接口,讓智能合約編寫用戶進行調用。模型提交者需要支付一定的存儲費用得以保證模型能在存儲層持續保存。對智能合約中調用過此模型進行 Infer 所收取的費用會有一部分交付給模型提交者。提交者也可以根據需要進行撤回和更新等操作。對于撤回的情況,為了保證調用此模型的智能合約可以正常運作,Cortex 會根據模型的使用情況進行托管,并且保持調用此模型收取的費用和存儲維護費用相當。Cortex 同時會提供一個接口將模型上傳到存儲層并獲得模型哈希。之后提交者發起一筆交易,執行智能合約將模型哈希寫入存儲中。這樣所有用戶就可以知道這個模型的輸入輸出狀態。
智能 AI 合約
Cortex 允許用戶在 Cortex 鏈上進行和機器學習相關的編程,并且提交一些依賴其他合約的交互,這將變得十分有趣。比如以太坊上運行的電子寵物 Cryptokitties ,寵物之間的交互可以是動態的、智能的、進化的。通過用戶上傳的增強學習模型,賦予智能合約結合人工智能,可以很方便的實現類似帶有人工智能的各種應用。
同時 Cortex 為其他鏈提供 AI 調用接口。比如在比特幣現金和以太坊上,Cortex 提供基于人工智能的合約錢包地址上分析的調用結果。那些分析地址的模型將將不僅有助于監管科技 (RegTech),也能給一般用戶提供轉賬目標地址的動態風險評估。
2.模型和數據存儲
Cortex 鏈并不實際存儲模型和數據,只存儲模型和數據的 Hash 值,真正的模型和數據存儲在鏈外的 key-value 存儲系統中。新模型和新數據在節點上有足夠多的副本之后將可以在鏈上可用。
3.Cortex 共識推斷標準
當用戶發起一筆交易到某個合約之后,全節點需要執行該智能合約的代碼。Cortex 和普通智能合約不同的地方在于其智能合約中可能涉及推斷指令,需要全節點對于這個推斷指令的結果進行共識。整個全節點的執行流程是:
1. 全節點通過查詢模型索引找到模型在存儲層的位置,并下載該模型的模型字符串和對應的參數數據。
2. 通過 Cortex 模型表示工具將模型字符串轉換成可執行代碼。
3. 通過 Cortex 提供的虛擬機 CVM ,執行可執行代碼,得到結果后進行全節點廣播共識。
Cortex 模型表示工具的作用可以分為兩部分:
1. 模型提交者需要將自己編寫的模型代碼通過模型表示工具轉化為模型字符串之后才可以提交到存儲層。
2. 全節點下載模型字符串之后通過模型表示工具提供的轉換器轉換成可執行代碼后,在 Cortex 虛擬機中執行推斷操作。
Cortex 虛擬機的作用在于全節點的每次推斷執行都是確定的。
4.如何挑選優秀的模型
Cortex 鏈不會對模型進行限制,用戶可以依靠模型 infer 的調用次數作為相對客觀的模型評價標準。當模型使用者對模型有不計計算代價的高精度需求時,Cortex 支持保留
原有模型參數使用浮點數來表示。從而,官方或者第三方機構可以通過自行定義對模型的排序機制(召回率,準確率,計算速度,基準排序數據集等),達成模型的甄選工作,并展示在第三方的網站或者應用中。
5 共識機制:PoW 挖礦
一直以來,一機一票的加密數字貨幣社區設想并未實現。原因是 ASIC 的特殊設計使得計算加速比得到大幅提升。社區和學術界探索了很多內存瓶頸算法來對顯卡和 CPU 挖礦更加友好,而無需花費大量資金購買專業挖礦設備。近年來社區實踐的結果顯示,以太坊的 Dagger-Hashimoto和 Zcash 的 Equihash是比較成功的顯卡優先原則的算法實踐。
Cortex 鏈將進一步秉承一機一票優先,采用 Cuckoo Cycle 的 PoW 進一步縮小 CPU和顯卡之間加速比的差距。同時 Cortex 鏈將充分發掘智能手機顯卡的效能,使得手機和桌面電腦的顯卡差距符合通用硬件平臺測評工具(如 GFXBench )的差距比例:比如,最好的消費級別顯卡是最好的手機顯卡算力的 10-15 倍。考慮到手機計算的功耗比更低,使得大規模用戶在夜間充電時間利用手機挖礦將變得更加可行。
特別值得注意的一點是,出塊加密的共識算法和鏈上的智能推斷合約的計算并沒有直接聯系,PoW 保障參與挖礦的礦工們硬件上更加公平,而智能計算合約則自動提供公眾推理的可驗證性。
6.防作弊以及模型篩選
由于模型是完全公開的,所以可能會有模型被復制或抄襲等現象發生。在一般情況下,如果是一個非常優秀的模型,往往上線之后就會有很高的使用量,而針對這些模型進行抄襲并沒有很大優勢,但是,在一些特殊情況下,對一些很明顯的抄襲或者完全復制的行為,Cortex 會進行介入并且仲裁,并通過鏈上 Oracle 的方式公示。
軟件方案
1.CVM:EVM + Inference
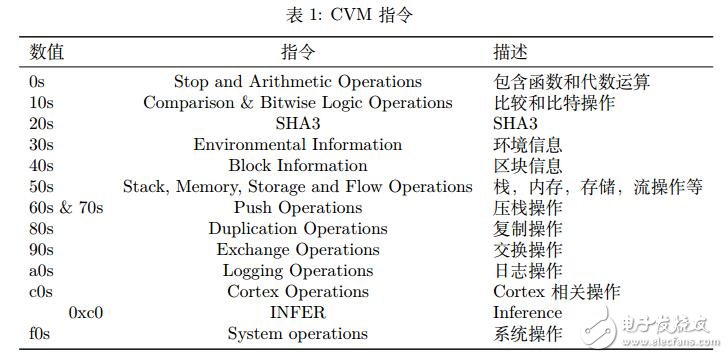
Cortex 擁有自己的虛擬機,稱為 Cortex Virtual Machine(CVM)。CVM 指令集完全兼容 EVM,此外,CVM 還提供對于推斷指令的支持。Cortex 將在 0xc0 加入一個新的 INFER 指令。這條指令的輸入是推斷代碼,輸出是推斷結果。CVM 使用的虛擬機指令包含的內容在表 1中說明。
2.Cortex 核心指令集與框架標準
人工智能的典型應用——圖像問題,語音/語義/文本問題,與強化學習問題無一例外的需要以下張量操作。Cortex 以張量操作的代價作為 Endorphin 計費的一種潛在錨定手段,剖析機器學習以及深度學習的核心指令集。在不同計算框架中,這一術語往往被稱為網絡層 (network layer) 或者操作符 (operator)。
? 張量的計算操作,包括:
– 張量的數值四則運算:輸入張量,數值與四則運算符
– 張量之間的按位四則運算:輸入兩個張量與四則運算符
– 張量的按位函數運算:輸入張量與乘方函數、三角函數、冪與對數函數、大小判斷函數、隨機數生成函數、取整函數等。
– 張量的降維運算:輸入張量與滿足結合律、交換律的操作符。
– 張量之間的廣播運算:輸入張量,用維度低張量補齊維度后進行按位操作。
– 張量之間的乘法操作:以 NCHW/NHWC 張量存儲模式為例,包含張量與矩陣、矩陣與向量等張量乘法/矩陣乘法操作。
? 張量的重構操作,包括:
– 維度交換,維度擴張與維度壓縮
– 按維度排序
– 值補充
– 按通道拼接
– 沿圖像平面拼接/剪裁
? 神經網絡特定操作
– 全連接
– 神經網絡激發函數主要依賴張量的按位函數運算的操作
– 1 維/2 維/3 維卷積(包括不同尺度卷積核、帶孔、分組等選項)
– 通過上采樣實現的 1 維/2 維/3 維反卷積操作與線性插值操作
– 通用輔助運算(如對一階/二階信息的統計 BatchNorm)
– 圖像類輔助計算(如可形變卷積網絡的形變參數模塊)
– 特定任務輔助計算(如 ROIPooling, ROIAlign 模塊)
Cortex 的核心指令集已覆蓋主流的人工智能計算框架操作。受制于不同平臺上 BLAS的實現,Cortex 把擁有浮點數 (Float32, Float16) 參數的 Cortex 模型通過 DevKit 轉化為定點數(INT8, INT6)參數模型 (Wu et al. [9]Han et al. [10]),從而支持跨平臺的推斷共識。
3.Cortex 模型表示工具
Cortex 模型表示工具創建了一個開放,靈活的標準,使深度學習框架和工具能夠互操作。它使用戶能夠在框架之間遷移深度學習模型,使其更容易投入生產。Cortex 模型表示工具作為一個開放式生態系統,使人工智能更容易獲得,對不同的使用者都有價值:人工智能開發人員可以根據不同任務選擇正確的框架,框架開發人員可以專注于創新與更新,硬件供應商可以針對性的優化。例如,人工智能開發人員可以使用 PyTorch等框架訓練復雜的計算機視覺模型,并使用 CNTK 、Apache MXNet 或者 TensorFlow進行推斷。
模型表示的基礎是關于人工智能計算的 Cortex 核心指令集的規范化。隨著人工智能領域研究成果、軟件框架、指令集、硬件驅動、硬件形式的日益豐富,工具鏈碎片化問題逐漸突顯。很多新的論文站在前人的工作基礎上進行微創新;理論過硬的科研成果得到的模型、數據、結論并不是站在過去最佳成果之上進行進一步發展,為精度的提高帶來天花板效應;工程師為了解決特定問題而設計的硬編碼更加無法適應爆發式增長的數據。
Cortex 模型表示工具被設計為
? 表征:將字符串映射為主流神經網絡模型、概率圖模型所支持的最細粒度的指令集
? 組織:將指令集映射為主流神經網絡框架的代碼
? 遷移:提供同構檢測工具,使得不同機器學習/神經網絡框架中相同模型可以互相遷移
4.存儲層
Cortex 可以使用任何 key-value 存儲系統來存儲模型,可行的選擇是 IPFS 和 libtorrent。Cortex 的數據存儲抽象層并不依賴于任何具體的分布式存儲解決方案,分布式哈希表或者 IPFS 都可以用來解決存儲問題,對于不同設備,Cortex 采取不同策略:
? 全節點常年存儲公鏈數據模型
? 手機節點采取類似比特幣輕錢包模式,只存儲小規模的全模型
Cortex 只負責共識推斷,不存儲任何訓練集。為了幫助合約作者篩選模型,避免過擬合的數據模型難題,合約作者可以提交測試集到 Cortex 披露模型結果。
一條進入合約級別的調用,會在內存池 (Mempool) 中排隊,出塊后,將打包進入區塊確認交易。緩存期間數據會廣播到包括礦池的全節點。Cortex 當前的存儲能力,能夠支持目前圖片、語音、文字、短視頻等絕大部分典型應用,足以覆蓋絕大多數人工智能問題。對于超出當前存儲限制的模型和數據,比如醫療全息掃描數據,一條就可能幾十個 GB ,將在未來 Cortex 提升存儲限制后加入支持。
對于 Cortex 的全節點,需要比現有比特幣和以太坊更大的存儲空間來存儲緩存的數據測試集和數據模型。考慮到摩爾定律 (Moore’s Law),存儲設備價格將不斷下降,因此不會構成障礙。對于每個數據模型,Metadata 內將建立標注信息,用來進行鏈上調用的檢索。Metadata 的格式在表 2中表述。

5.模型索引
Cortex 存儲了所有的模型,在全節點中,對于每筆需要驗證的交易,如果智能合約涉及共識推斷,則需要從內存快速檢索出對應的模型進行推斷。Cortex 的全節點內存將為本地存儲的模型建立索引,根據智能合約存儲的模型地址去檢索。
6.模型緩存
Cortex 的全節點存儲能力有限,無法存下全網所有模型。Cortex 引入了緩存來解決這個問題,在全節點中維護一個 Model Cache 。Model Cache 數據模型的替換策略,有最近最常使用(LRU)、先進先出(FIFO)等,也可以使用任何其他方案來提高命中率。
7.全節點實驗
針對全節點執行推斷指令的吞吐情況,本章描述了一些在單機上實驗的結果。測試平臺配置為:
? CPU: E5-2683 v3
? GPU: 8x1080Ti
? 內存: 64 GB
? 硬盤: SSD 960 EVO 250 GB
實驗中使用的測試代碼基于 python 2.7 和 MXNet ,其中主要包含以下模型:
? CaffeNet
? Network in Network
? SqueezeNet
? VGG16
? VGG19
? Inception v3 / BatchNorm
? ResNet-152
? ResNet101-64x4d
所有模型都可以在 MXNet 的文檔 1 中找到。實驗分別在 CPU 和 GPU 中測試這些模型在平臺上的推斷速度,這些測試不考慮讀取模型的速度,所有模型會提前加載到內存或者顯存中。
測試結果如表 3,括號中是 Batch Size(即一次計算所傳入的數據樣本量),所有 GPU測試結果都是在單卡上的測試。
以上是單機測試的結果。為了模擬真實的情況,試驗平臺上設置 10 萬張的圖片不斷進行推斷,每次推斷選擇隨機的模型來進行并且 Batch Siz e 為 1,圖片發放到 8 張帶有負載均衡的顯卡上。對于兩種情況:
1. 所有模型都已經讀取完畢并存放到顯存中,其單張圖片推斷的平均速度為 3.16ms。
2. 每次重新讀取數據(包括模型和輸入數據)而不是提前加載進顯存,但是進行緩存,其單張圖片推斷的平均速度為 113.3 ms。
結論 全節點在模型已經預讀到顯存之后,支持負載均衡,并且將同一模型進行顯卡間并行推斷,測試結果大約每秒能執行接近 300 次的單一推斷。如果在極端情況下不進行顯存預讀,而只是進行緩存,每次重新讀取模型和輸入數據,大約每秒能進行 9 次左右的單一推斷。以上實驗都是在沒有優化的情況下進行的計算,Cortex 的目標之一是致力于不斷優化提高推斷性能。
硬件方案
1.CUDA and RoCM 方案
Cortex 的硬件方案大量采用了 NVidia 公司的 CUDA 驅動與 CUDNN 庫作為顯卡計算的開發框架。同時,AMD OpenMI 軟件項目采用了 RoCM 驅動與 HIP/HCC 庫人工智能研發計劃, 并計劃在 2018 年底推出后支持的開發框架。
2.FPGA 方案
FPGA 產品的特性是低位定點運算 (INT8 甚至 INT6 運算),延時較低,但是計算功耗較高,靈活性較差;在自動駕駛領域、云服務領域已經有較好的深度學習部署方案。Cortex 計劃對 Xilinx 與 Altera 系列產品提供 Infer 支持。
3.全節點的硬件配置需求 - 多顯卡和回歸傳統的 USB 挖礦
不同于傳統的比特幣和以太坊全節點,Cortex 對全節點的硬件配置需求較高。需要比較大的硬盤存儲空間和多顯卡桌面主機來達到最佳確認速度的性能,然而這并不是必需的。在比特幣領域 USB 曾經是一種即插即用的比特幣小型 ASIC 礦機,在大規模礦廠形成之前,這種去中心化的挖礦模式,曾經風靡一時,Cortex 全節點在缺少顯卡算力的情況下可以配置類似的神經網絡計算芯片或計算棒,這些設備已經在市場上逐漸成熟。與 USB 挖礦不同的是,計算芯片是做全節點驗證的硬件補足,并非計算挖礦具體過程中需要的設備。
4.現有顯卡礦廠需要的硬件改裝措施
對于一個現有顯卡算力的礦廠,特別是有高端顯卡的礦廠,Cortex 提供改造咨詢服務和整體技術解決方案,使得礦廠具有和世界一流 AI 公司同等水平的智能計算中心,硬件性價比將遠遠超過現有商用 GPU 云,多中心化的礦廠有機會出售算力給算法提供者,或者以合作的方式生成數據模型,和世界一流的互聯網、AI 公司同場競技。具體的改造策略有:
? 主板和 CPU 的定制策略,滿足多路 PCI-E 深度學習的數據傳輸帶寬
? 萬兆交換機和網卡的硬件解決方案
? 存儲硬件和帶寬解決方案
? 相關軟件在挖 Cortex 主鏈、挖其他競爭顯卡幣和鏈下深度學習訓練之間自動切換
? 相關的手機端監控收益、手動切換等管理軟件
5. 手機設備和物聯網設備挖礦和計算
平衡異構計算芯片 (CPU)、顯示芯片 (GPU)、FPGA 與 ASIC 計算模塊的算力收益比例,從而更加去中心的進行工作量證明挖礦,一直是主鏈設計的難點,特別是能夠讓算力相對弱小的設備,比如手機和 IoT 設備參與其中。同時,由于目前市場上的手機設備已經出現了支持 AI 計算的芯片或者計算庫、基于手機 AI 芯片的計算框架也可以參與智能推斷,只不過全節點的數據模型相對較大,移動端需要定制對可執行數據模型的規模做篩選。Cortex 主鏈將發布 Android 和 iOS 客戶端 App:
? 閑置中具有顯卡算力的設備能通過 SoC 、ARM 架構的 CPU/GPU 參與挖礦,比如市場中,電視盒子的顯卡性能其實已經很不錯了,而 90% 時間基本都在閑置
? 用戶手機在上班充電和睡覺充電中都可以參與挖礦,只要算法上讓手機的顯卡得到公平的收益競爭力
? 手機或其他配有 AI 芯片的設備,能夠自動在主鏈出塊和執行智能推斷之間切換
手機端的推斷能力可能會受到芯片供應商的軟件技術限制,不同軟件供應商正在封裝不同的計算協議,Cortex 將負責抽象層接口的編寫和輕智能客戶端的篩選。
代幣模型
1.Cortex Coin (CTXC)
模型提交者的獎勵收益
傳統的區塊鏈對于每個打包區塊的獎勵是直接支付給礦工的,Cortex 為了激勵開發者提交更加豐富和優秀的模型,調用合約需要支付的 Endorphin 不僅僅會分配給幫助區塊打包的節點礦工,還會支付給模型的提供者。費用的收取比例采用市場博弈價格,類似以太坊中 Gas 的機制。
模型提交者成本支出
為了防止模型提交者進行過度的提交和存儲攻擊 - 比如,隨意提交幾乎不可用的模型以及頻繁提交相同模型從而占用存儲資源 - 每個模型提交者必須支付存儲費用。這樣可以促使模型提交者提交更加優秀的模型。這樣調用者更多,模型提交者收益更大。
模型復雜度和 Endorphin 的耗費
Endorphin 用來衡量在推斷過程中將數據模型帶入合約時,計算所耗費的虛擬機級別硬件計算資源,Endorphin 的耗費正比于模型大小,同時 Cortex 也為模型的參數大小設置了 8GB 的上限,對應最多約 20 億個 Float32 的參數。
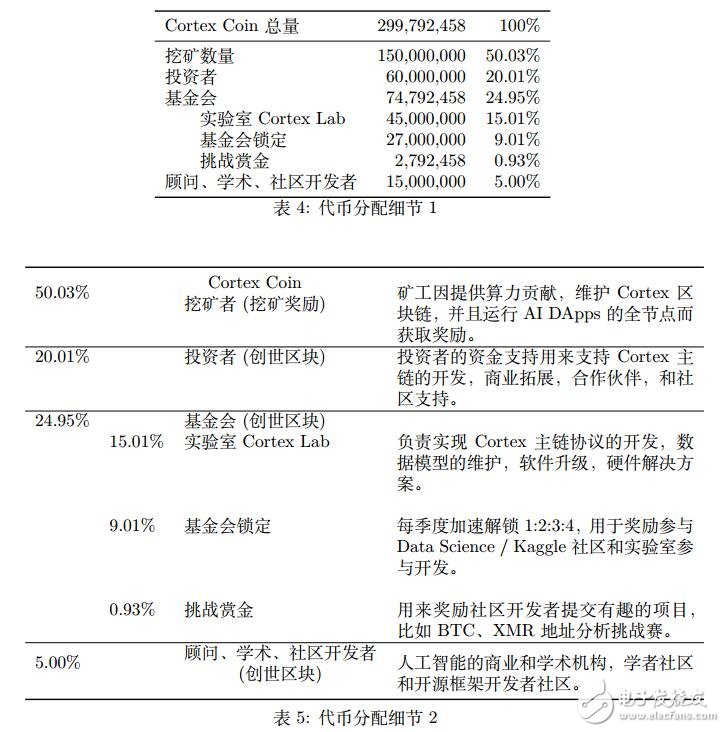
2.代幣分配
Cortex Coin (CTXC) 數量總共為 299,792,4582個。其中 60,000,000 (20.01%) 分配給早期投資者。
3 代幣發行曲線
Cortex Coin 發行總量為 299,792,458 個,其中 150,000,000 的 Cortex Coin 可以通過挖礦獲得。
第一個 4 年 75,000,000
第二個 4 年 37,500,000
第三個 4 年 18,750,000
第四個 4 年 9,375,000
第五個 4 年 4,687,500
…
依此類推,發行量按每四年減半。

















 工商網監
工商網監
評論