 電子發燒友App
電子發燒友App


云尊幣(WC)一一是一種以區塊鏈為底層安全技術的加密數字資產,它的發展趨勢和價值將隨著時間的推移而日益彰顯。云尊加密數字資產的發行量源于龐大的經銷商數量和可循環的綠色生態系統,目前得到了全球各地的忠誠支持者支持 。
云尊幣滿足了所有這些需求,它消除了巨大的算力和處理在工作證明所帶來的競爭。云尊幣是一款采用了工作證明(POW)和權益證明(POS)雙重共識機制的加密數字資產,它由加密技術(SCRYPT) 作為保證的,由區塊鏈中的分布式節點維護,允許用戶在網絡上進行點對點交易,而不受任何企業、中介或人為因素的干擾。
云尊幣技術架構
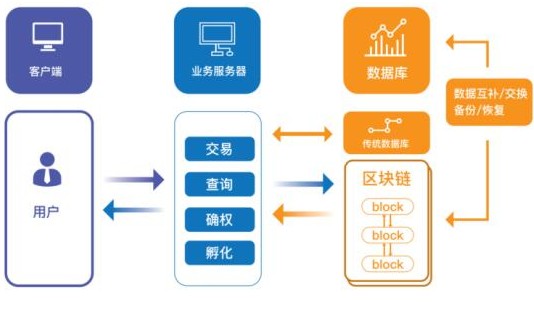
基于區塊鏈的應用要可靠落地 , 我們認為需要將傳統技術體系基于區塊鏈系統進行整合,讓區塊鏈技術恰當的融入到平臺。 區塊鏈技術的安全、不可篡改等特性, 保證了去中心化可靠性,成熟技術的有序結合也保證了系統性能穩定流暢。
傳統銀行系統里的電子交易通常是可逆的,如果有人竊取你的信用卡金額,你可以對這項交易提出質疑,在大多數情況下損失是由銀行或商家承擔,消費者不用自掏腰包。這對消費者而言十分方便,但卻要求金融系統必須是一個相當嚴謹的誠信網。允許一個新成員加入就給其他每位成員增加了風險。所以當前的金融機構不愿與不知名或資本不雄厚的電子商務網站對接,這也是可以理解的。云尊幣就不一樣了,由于交易是經過密碼認證的并且不可逆,所以沒有必要對接入該網絡加以限制。接受毫不相識的人的付款也沒有風險。這意味著,作為一個基于云尊幣的商家或者金融中介的門檻將會降低,使誠信的從業者更容易的加入商務活動,而各種隱含欺詐動機的行為無法得以實施。接受云尊幣也可使商家避免許多管理間接費,使交易得到更多的保障。
?
1、云尊幣數據層
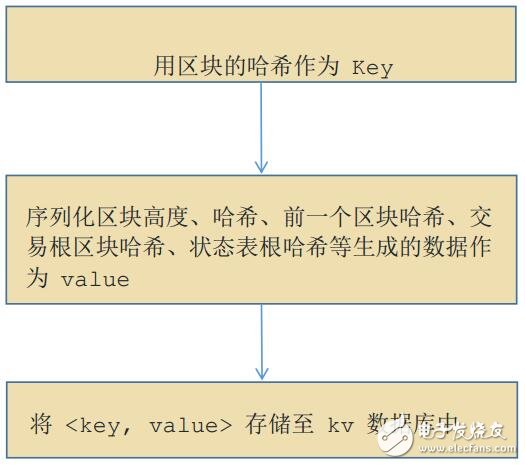
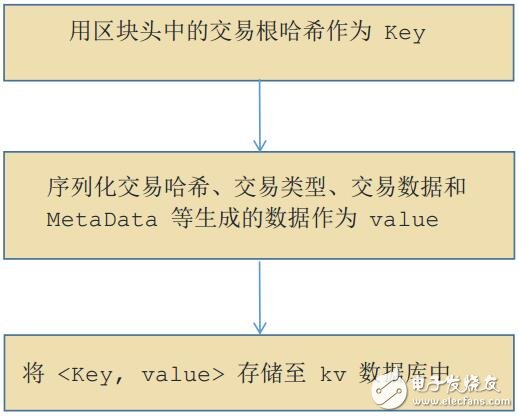
云尊幣的區塊鏈數據存儲系統是由關系型數據庫(sqlite)和 kv 數據庫組成,其中關系型數據庫用來存儲區塊頭信息和每筆交易的具體信息, kv 數據庫主要存儲區塊頭、交易和狀態表序列化后的數據。
這樣處理的主要目的是單純在查詢區塊頭信息和具體每筆交易的時候,可以直接從關系型數據庫中查找;而要構造整個區塊數據的時候,除了從關系型數據庫構造區塊頭信息外,還要依據區塊頭里的交易根哈希和狀態表根哈希從 kv數據庫中獲取具體的交易和狀態表信息。
區塊頭信息的序列化具體步驟:
交易的序列化具體步驟:
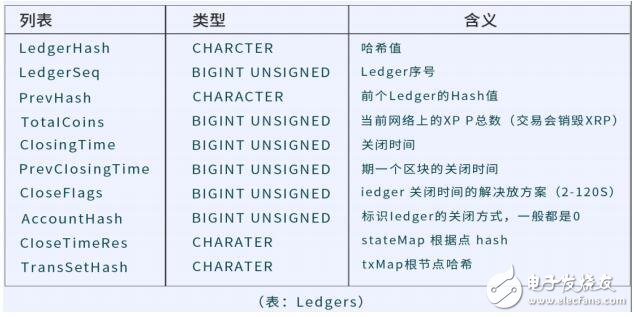
下表分別是 Ledgers 和 Transactions 表結構。
1、1 關系型數據庫(sqlite)的特性
關系型數據庫(sqlite)誕生于 2000 年 5 月。作為一個自包含的、基于文件的數據庫,SQLite 提供了非常出色的工具集能夠處理所有類型的數據,與托管在服務器上基于進程的關系型數據庫相比它的約束更少,也更易用。
這是一款輕型的嵌入式數據庫,它占用資源非常的低,在嵌入式設備中,可能只需要幾百 K 的內存就足夠了。它的處理速度比 Mysql、PostgreSQL 這兩款著名的數據庫都還快,sqlite 還具
有以下特性:
?零配置,無需安裝和配置
sqlite 的核心引擎本身不依賴第三方的軟件,使用它也不需要“安裝”。所以在部署的時候能夠省去不少麻煩。
?儲存在單一磁盤文件中的一個完整的數據庫
數據庫中所有的信息(比如表、視圖、觸發器、等)都包含在一個文件內。這個文件可以 copy 到其它目錄或其它機器上,也照用不誤。
?數據庫文件可以在不同字節順序的機器間自由共享
sqlite 支持多種系統,除了主流操作系統,QLite 也支持了很多冷門的操作系統。例如對很多嵌入式系統(比如 Android、Windows Mobile、Symbin、Palm、VxWorks 等)的支持。SQLite生成的數據庫文件可以在各種智能設備進行移植,為云尊幣普及到其他智能設備提供了基礎。
?足夠小,全部源代碼大約幾百 KB,能夠實現在輕便的智能設備中運行。
?比目前流行的大多數數據庫對數據的操作要快。
1、2 sqlite 數據庫工作原理
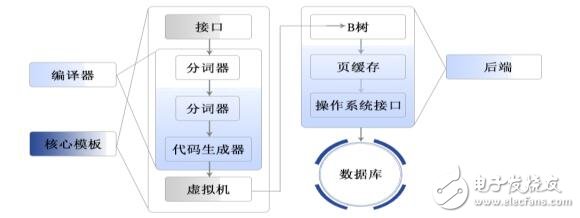
qlite 主要由 7 個構件子系統(也就是模塊)組成,這些模塊被分割為前端解析系統和后端引擎。
前端:
前端預處理應用程序傳遞過來的 SQL 語句和 SQLite 命令。對獲取的編碼分析,優化,并轉換 為后端能夠執行的 SQLite 內部字節編碼。前端可分為三個模塊。
?標示分析(Tokenizer):將輸入的 SQL 語句分成標識符。
?語法分析(Parser):解析器分析通過標識器產生的標識分析語句的結構,并且得到一顆語法樹。解析器同時也包含了重構語法樹的優化器,因此能夠找到一顆產生一個高效的字節編碼程序的語法樹。
?代碼生成器(Code Generator):代碼生成器遍歷語法樹,并且生成一個等價的字節編碼程序,前端實現了sqlite3_prepare API 函數。
后端:
后端是用來解釋字節編碼程序的引擎。該引擎做的才是真正的數據庫處理工作。后端部分由四個模塊組成。
?虛擬機(VM):VM 模塊是一個內部字節編碼語言的解釋器。它通過執行字節編碼語句來實現 SQL 語句的工作。它是數據庫中數據的最終的操作者。它把數據庫看成表和索引的集合,而表和索引則是一系列的元組或者記錄。
?B/B+樹:B/B+樹模塊把每一個元組集組織進一個一次排好序的樹狀數據結構中,表和索引被分別置于單獨的 B+和B樹中。該模塊幫助 VM 進行搜索,插入和刪除樹中的元組。它也幫助 VM創建新的樹和刪除舊的樹。
?頁面調度程序(pager):頁面調度程序模塊在原始文件的上層實現了一個面向頁面的數據庫文件抽象。它管理 B/B+樹使用的內存內緩存(數據庫頁的),另外,他也管理文件的鎖定,并用日志來實現事物的 ACID 屬性。
?操作系統交界面(system interface):操作系統界面模塊提供了對應于不同本地操作系統的統一交界面,后端實現了sqlite3_bind_*,sqlite3_setp,sqlite3_coloumn_*,sqlite3_reset 和 sqlite3_finalize API 函數。
關系型數據庫的特點能夠滿足云尊幣在輕便智能設備中運行的要求,并且能夠在多種技術架構的的操作系統中進行移植,而無需很大的改動,這保證了云尊幣在普通群體的能夠快速的推廣和普及。
2、加密算法
數據加密的基本過程就是對原來為明文的文件或數據按某種算法進行處理,使其成為不可讀的一段代碼。目前區塊鏈一般常用的加密算法有對稱加密、非對稱加密、公私匙、Hash 算法等
等。
對稱加密:對稱加密是最快速、最簡單的一種加密方式,加密(encryption)與解密(decryption)用的是同樣的密(secretkey)。對稱加密通常使用的是相對較小的密鑰,一般小于 256bit。密鑰的大小既要照顧到安全性,也要照顧到效率,是一個 trade-off。
非對稱加密:非對稱加密為數據的加密與解密提供了一個非常安全的方法,它使用了一對密鑰,公鑰(public key)和私鑰(privatekey)。私鑰只能由一方安全保管,不能外泄,而公鑰則可以發給任何請求它的人。非對稱加密使用這對密鑰中的一個進行加密,而解密則需要另一個密鑰。
私鑰(private key):非公開,是一個 256 位的隨機數,由用戶保管且不對外開放。私鑰通常是由系統隨機生成,是用戶賬戶使用權及賬戶內資產所有權的唯一證明,其有效位長足夠大,因此不可能被攻破,無安全隱患。
公鑰(public key):可公開,每一個私鑰都有一個與之相匹配的公鑰。 ECC 公鑰可以由私鑰通過單向的、確定性的算法生成,目前常用的方案包括: secp256r1(國際通用標準)、secp256k1(比特幣標準)和 SM2(中國國標)Photon chain 控制鏈與初始數據鏈選擇 secp256r1 作為密鑰方案。
Hash 算法:通常 Hash 算法是指安全散列算法 SHA(Secure Hash Algorithm),該算法是美國國家安全局 (NSA) 設計,美國國家標準與技術研究院(NIST) 發布的一系列密碼散列函數,包括 SHA-1、SHA-224、SHA-256、SHA-384 和 SHA-512 等變體。目前比特幣采用 SHA-256 算法。Photon chain 除 PoW 外,其余 Hash 算法均指 SHA-256。
云尊幣在此基礎上進行了改進,使用的同態加密是一種無需對加密數據進行提前解密就可以執行計算的方法。它提供了一種急需的方法,能夠在原有基礎上使用區塊鏈技術。
通過使用同態加密技術在區塊鏈上存儲數據可以達到一種完美的平衡,不會對區塊鏈屬性造成任何重大的改變。也就是說,區塊鏈仍舊是公有區塊鏈。然而,區塊鏈上的數據將會被加密,因此照顧到了公有區塊鏈的隱私問題,同態加密技術使公有區塊鏈具有私有區塊鏈的隱私效果。
2、1 同態加密算法處理過程
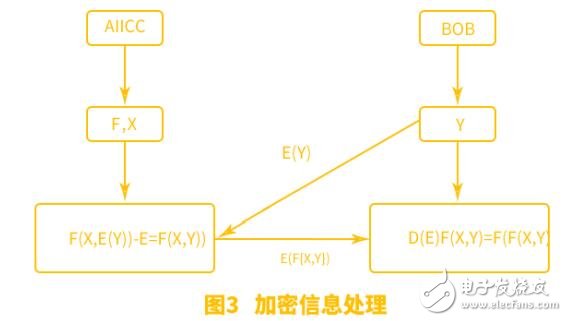
如圖 3 所示,主要是對私有信息進行保護。Alice 有私有的函數 fA 和私有的信息 XA,Bob 把私有信息 yB用私有公鑰 pkB加密得到 E(y)發送給 Alice,Alice 用自己的私有函數 fA 加密私有信息 XA 和 E(yB),由于同態性質,函數 fA 被隱藏,而 Bob 獲得 E(fA(XA,yB))。Bob 通過私有的私鑰加密 D(E(fA (XA,yB)))=fA (XA,yB)。
如圖 4 所示,主要是對私有的操作函數進行保護。Alice 有私有的函數以,并用私有公鑰 pkA加密函數 fA發送給 Bob,Bob根據私有信息 XB計算 E(fA )(XB),由于同態性質,因此隱藏了Bob 的信息 XB,得到 E(fa(xb)),并發送給 Alice,Alice 用私鑰解密獲得 fA(XB)。
同態加密技術不僅提供了隱私保護,它同樣會允許隨時訪問公用區塊鏈上的加密數據進行審計或其他目的。換句話說,使用同態加密在公用區塊鏈上存儲數據將能夠同時提供公有和私有區塊鏈的最好的部分。
如果 E 為針對 function_a 的全同態函數,即
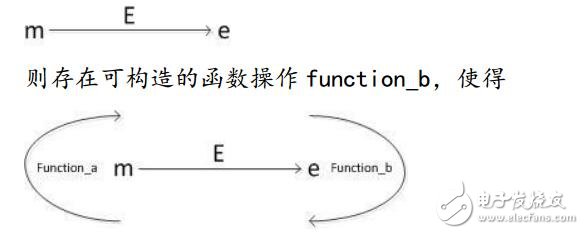
其中,加密操作為 E,明文為 m,加密得 e,如果對于任意復雜明文操作 function_a,都能針對 E 構造出相應的 function_b。那么,E 就是一個針對 function_a 的同態加密算法,則稱 E 為針對 function_a 的全同態加密算法。全同態加密的目的在于找到一種能在加密的數據上進行任意數量的加法和乘法運算的加密算法,使得對加密數據進行某種操作所得到的結果恰好等于對加密前的數據進行預期操作再加密后得到的密文。
3、Netty 構建高性能高可用的去中心化網絡
3、1 Netty 的 I/O 模型
基于非阻塞 I/O 實現,底層依賴的是 JDK NIO 框架的Selector。
Selector 提供選擇已經就緒的任務的能力。簡單來講,Selector 會不斷地輪詢注冊在其上的 Channel,如果某個Channel 上面有新的 TCP 連接接入、讀和寫事件,這個 Channel就處于就緒狀態,會被 Selector 輪詢出來,然后通過SelectionKey 可以獲取就緒 Channel 的集合,進行后續的 I/O操作。
一個多路復用器 Selector 可以同時輪詢多個 Channel,由于JDK1.5_update10 版本(+)使用了 epoll()代替傳統的 select實現,所以它并沒有最大連接句柄 1024/2048 的限制。這也就意味著只需要一個線程負責 Selector 的輪詢,就可以接入成千上萬的客戶端,這確實是個非常巨大的技術進步。使用非阻塞 I/O 模型之后,Netty 解決了傳統同步阻塞 I/O帶來的性能、吞吐量和可靠性問題。
3、2 線程調度模型
常用的 Reactor 線程模型有三種,分別如下:
Reactor 單線程模型:Reactor 單線程模型,指的是所有的I/O 操作都在同一個 NIO 線程上面完成。對于一些小容量應用場景,可以使用單線程模型。
Reactor 多線程模型:Rector 多線程模型與單線程模型最大的區別就是有一組 NIO 線程處理 I/O 操作。主要用于高并發、大業務量場景。
主從 Reactor 多線程模型:主從 Reactor 線程模型的特點是服務端用于接收客戶端連接的不再是個 1 個單獨的 NIO 線程,而是一個獨立的 NIO 線程池。利用主從 NIO 線程模型,可以解決 1個服務端監聽線程無法有效處理所有客戶端連接的性能不足問題。
事實上,Netty 的線程模型并非固定不變,通過在啟動輔助類中創建不同的 EventLoopGroup 實例并通過適當的參數配置,就可以支持上述三種 Reactor 線程模型。
在大多數場景下,并行多線程處理可以提升系統的并發性能。但是,如果對于共享資源的并發訪問處理不當,會帶來嚴重的鎖競爭,這最終會導致性能的下降。為了盡可能的避免鎖競爭帶來的性能損耗,可以通過串行化設計,即消息的處理盡可能在同一個線程內完成,期間不進行線程切換,這樣就避免了多線程競爭和同步鎖。
為了盡可能提升性能,Netty 采用了串行無鎖化設計,在 I/O線程內部進行串行操作,避免多線程競爭導致的性能下降。表面上看,串行化設計似乎 CPU 利用率不高,并發程度不夠。但是,通過調整 NIO 線程池的線程參數,可以同時啟動多個串行化的線程并行運行,這種局部無鎖化的串行線程設計相比一個隊列-多個工作線程模型性能更優。
3、3 序列化方式
影響序列化性能的關鍵因素總結如下:
序列化后的碼流大小(網絡帶寬占用)、序列化&反序列化的性能(CPU 資源占用)
并發調用的性能表現:穩定性、線性增長、偶現的時延毛刺等對 Java 序列化和二進制編碼分別進行性能測試,編碼 100 萬次,測試結果表明:Java 序列化的性能只有二進制編碼的 6.17%左右。
Netty 默認提供了對 Google Protobuf 的支持,通過擴展Netty 的編解碼接口,用戶可以實現其它的高性能序列化框架,例如 Thrift 的壓縮二進制編解碼框架。
不同的應用場景對序列化框架的需求也不同,對于高性能應用場景Netty默認提供了Google的Protobuf二進制序列化框架,如果用戶對其它二進制序列化框架有需求,也可以基于 Netty 提供的編解碼框架擴展實現。
3、4 采用 Netty 框架的原因
1)設計
· 統一的 API,適用于不同的協議(阻塞和非阻塞)
· 基于靈活、可擴展的事件驅動模型
· 高度可定制的線程模型
· 可靠的無連接數據 Socket 支持(UDP)
2)性能
·更好的吞吐量,低延遲、
·更省資源
·盡量減少不必要的內存拷貝
3)安全
完整的 SSL/TLS 和 STARTTLS 的支持能在 Applet 與Android 的限制環境運行良好
4)健壯性
·不再因過快、過慢或超負載連接導致 OutOfMemoryError不再有在高速網絡環境下 NIO 讀寫頻率不一致的問題
5)易用
· 完善的 JavaDoc,用戶指南和樣例
· 簡潔簡單
· 僅信賴于 JDK1.5
Netty 框架能夠為云尊幣帶來更好的兼容性、安全性、穩定性可操作性,為云尊幣多功能性的應用快速讀寫提供基礎,目前Netty 已經在很多不同的領域取得了良好的效果。
大數據領域:經典的 Hadoop 的高性能通信和序列化組件Avro的RPC 框架,默認采用 Netty 進行跨節點通信,它的 NettyService 基于 Netty 框架二次封裝實現。
大數據計算往往采用多個計算節點和一個/N 個匯總節點進行分布式部署,各節點之間存在海量的數據交換。由于 Netty 的綜合性能是目前各個成熟 NIO 框架中最高的,因此,往往會被選中用作大數據各節點間的通信。
企業軟件:企業和 IT 集成需要 ESB,Netty 對多協議支持、私有協議定制的簡潔性和高性能是 ESB RPC 框架的首選通信組件。事實上,很多企業總線廠商會選擇 Netty 作為基礎通信組件,用于企業的 IT 集成。
通信行業:Netty 的異步高性能、高可靠性和高成熟度的優點,使它在通信行業得到了大量的應用。
4、云尊幣共識機制
云尊幣采用 PoW+PoS 的混合共識機制,能夠將受眾群體最大化。持有云尊幣的用戶與礦工均可以參與到投票中,共同參與重大決定,數字資產持有者與礦工都可以影響預先編制好的更新,而這才是真正的去中心化。
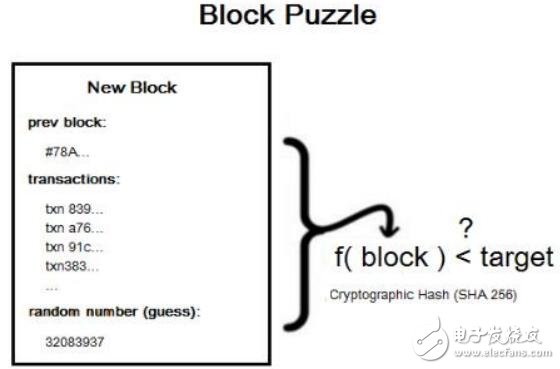
4、1 POW 工作量證明的過程
POW 是一個經過廣泛測試,并具有抗攻擊性和拓展性的解決方案。 我們可以把工作量證明的步驟大致歸納如下:
生成 Coinbase 交易,并與其他所有準備打包進區塊的交易組成交易列表,通過 Merkle Tree 算法生成 Merkle Root Hash
把 Merkle Root Hash 及其他相關字段組裝成區塊頭,將區塊頭的 80 字節數據(Block Header)作為工作量證明的輸入
不停的變更區塊頭中的隨機數即 nonce 的數值,并對每次變更 后 的 的 區 塊 頭 做 雙 重 SHA256 運算(即SHA256(SHA256(Block_Header))),將結果值與當前網絡的目標值做對比,如果小于目標值,則解題成功,工作量證明完成。
該過程可以用下圖表示:
4、2 權益證明(Proof of Stake)
在工作量證明中,各個節點協助創建和驗證新的區塊。獎勵與貢獻給整個網絡的算力資源成正比。當然也會出現惡意攻擊或者惡意欺騙其他節點的風險出現。權益證明系統試圖先保留工作量證明的好處,同時消除一些潛在的安全問題。
權益證明機制可以輔助加強工作量證明,而不是取代它。其可以簡單地作為添加和批準新區塊的附加步驟。
?PoS 背后的理性邏輯
(1)使權益所有者能夠通過投票決定記賬人
(2)最大化權益所有者的紅利
(3)最小化保證網絡安全的消耗
(4)最大化網絡的性能
(5)最小化運行網絡的成本
云尊幣這樣設計的好處,權益所有者擁有控制權,PoS 的根本特性是權益所有者保留了控制權,從而使系統去中心化。可以提高區塊鏈數字資產的安全性,因為工作量證明可能存在 51%攻擊的潛在風險,控制大部分算力資源的人將可以輕易控制整個網絡。
在技術上層面上,云尊運用了對區塊的投票交易機制(一種靈活且實用的 PoS 機制),并把具備雙層鏈結構和兩極挖礦思想的加強版 PoW 機制與該 PoS 機制進行有機結合從而得到新型混合共識機制,在該新型混合共識中,keyBlock 必須獲得足夠的贊同票才會被視為合法,因此 PoW 和 PoS 都能參與系統共識并發揮重要作用。
5、云尊幣解決區塊鏈網絡慢的弊端
云尊幣是如何解決區塊鏈網絡慢的呢?通過“RingBuffer”和“Disruptor”來實現,
Disruptor 它是一個開源的并發框架,能夠在無鎖的情況下實現網絡的 Queue 并發操作,Disruptor 為什么會這么快?
(1)鎖的缺點
Disruptor 根本就不用鎖。取而代之的是,在需要確保操作是線程安全的(特別是,在多生產者的環境下,更新下一個可用的序列號)地方,我們使用 CAS(Compare And Swap/Set)操作。CAS 操作比鎖消耗資源少的多,因為它們不牽涉操作系統,它們直接在 CPU 上操作。所有訪問者都記錄自己的序號的實現方式,允許多個生產者與多個消費者共享相同的數據結構。在每個對象中都能跟蹤序列號(ring buffer,claim Strategy,生產者和消費者),加上神奇的 cache line padding,就意味著沒有為偽共享和非預期的競爭。
(2)緩存行填充
CPU 來執行所有運算和程序。主內存(RAM)是你的數據(包括代碼行)存放的地方。Disruptor 的目標是盡可能多的在內存中運行,如果你訪問一個 long 數組,當數組中的一個值被加載到緩存中,它會額外加載另外多個。因此你能非常快地遍歷這個數組。事實上,你可以非常快速的遍歷在連續的內存塊中分配的任意數據結構。
(3)偽共享
(4)揭秘內存屏障
內存屏障作為另一個 CPU 級的指令,沒有鎖那樣大的開銷。內核并沒有在多個線程間干涉和調度。但凡事都是有代價的。內存屏障的確是有開銷的——編譯器/cpu 不能重排序指令,導致不可以盡可能地高效利用 CPU,另外刷新緩存亦會有開銷。Disruptor 的實現對序列號的讀寫頻率盡量降到最低。對volatile 字段的每次讀或寫都是相對高成本的操作。也應該認識到在批量的情況下可以獲得很好的表現。
我們使用 Disruptor 和 Ring Buffer。這種數據結構,是因為它給我們提供了可靠的消息傳遞特性。這個理由就足夠了,不過它還有一些其他的優點。首先,Ring Buffer 比鏈表要快,因為它是數組,而且有一個容易預測的訪問模式。這很不錯,對 CPU高速緩存友好 (CPU-cache-friendly)-數據可以在硬件層面預加載到高速緩存,因此 CPU 不需要經常回到主內存 RAM 里去尋找 Ring Buffer 的下一條數據。第二點,Ring Buffer 是一個數組,你可以預先分配內存,并保持數組元素永遠有效。這意味著內存垃圾收集(GC)在這種情況下幾乎什么也不用做。此外,也不像鏈表那樣每增加一條數據都要創建對象-當這些數據從鏈表里刪除時,這些對象都要被清理掉。
















 工商網監
工商網監
評論