關于Java HashMap的認知
HashMap詳解
HashMap 和 HashSet 是 Java Collection Framework 的兩個重要成員,其中 HashMap 是 Map 接口的常用實現類,HashSet 是 Set 接口的常用實現類。雖然 HashMap 和 HashSet 實現的接口規范不同,但它們底層的 Hash 存儲機制完全一樣,甚至 HashSet 本身就采用 HashMap 來實現的(使用HashMap的key來存儲HashSet的值,value是一個無意義的對象)。
通過 HashMap、HashSet 的源代碼分析其 Hash 存儲機制
實際上,HashSet 和 HashMap 之間有很多相似之處,對于 HashSet 而言,系統采用 Hash 算法決定集合元素的存儲位置,這樣可以保證能快速存、取集合元素;對于 HashMap 而言,系統 key-value 當成一個整體進行處理,系統總是根據 Hash 算法來計算 key-value 的存儲位置,這樣可以保證能快速存、取 Map 的 key-value 對。
在介紹集合存儲之前需要指出一點:雖然集合號稱存儲的是 Java 對象,但實際上并不會真正將 Java 對象放入 Set 集合中,只是在 Set 集合中保留這些對象的引用而言。也就是說:Java 集合實際上是多個引用變量所組成的集合,這些引用變量指向實際的 Java 對象。
集合和引用
就像引用類型的數組一樣,當我們把 Java 對象放入數組之時,并不是真正的把 Java 對象放入數組中,只是把對象的引用放入數組中,每個數組元素都是一個引用變量。
HashMap 的存儲實現
當程序試圖將多個 key-value 放入 HashMap 中時,以如下代碼片段為例:
HashMap《 String, Double》 map= newHashMap《 String, Double》(); map.put( “高數”,60.0); map.put( “大英”, 89.0); map.put( “大物”, 78.2);
HashMap 采用一種所謂的“Hash 算法”來決定每個元素的存儲位置。
當程序執行 map.put(“高數” , 60.0); 時,系統將調用”高數”的 hashCode() 方法得到其 hashCode 值——每個 Java 對象都有 hashCode() 方法,都可通過該方法獲得它的 hashCode 值。得到這個對象的 hashCode 值之后,系統會根據該 hashCode 值來決定該元素的存儲位置。
我們可以看 HashMap 類的 put(K key , V value) 方法的源代碼:
publicV put(K key, V value) { // 如果 key 為 null,調用 putForNullKey 方法進行處理 if(key == null) returnputForNullKey( value); // 根據 key 的 keyCode 計算 Hash 值 inthash = hash(key.hashCode()); // 搜索指定 hash 值在對應 table 中的索引 inti = indexFor(hash, table.length); // 如果 i 索引處的 Entry 不為 null,通過循環不斷遍歷 e 元素的下一個元素for(Entry《K,V》 e = table[i]; e != null; e = e.next) { Object k; // 找到指定 key 與需要放入的 key 相等(hash 值相同 // 通過 equals 比較放回 true) if(e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e. value; e. value= value; e.recordAccess( this);returnoldValue; } } // 如果 i 索引處的 Entry 為 null,表明此處還沒有 Entry modCount++; // 將 key、value 添加到 i 索引處 addEntry(hash, key, value, i); returnnull; }
上面程序中用到了一個重要的內部接口:Map.Entry,每個 Map.Entry 其實就是一個 key-value 對。從上面程序中可以看出:當系統決定存儲 HashMap 中的 key-value 對時,完全沒有考慮 Entry 中的 value,僅僅只是根據 key 來計算并決定每個 Entry 的存儲位置。這也說明了前面的結論:我們完全可以把 Map 集合中的 value 當成 key 的附屬,當系統決定了 key 的存儲位置之后,value 隨之保存在那里即可。
上面方法提供了一個根據 hashCode() 返回值來計算 Hash 碼的方法:hash(),這個方法是一個純粹的數學計算,其方法如下:
staticinthash( inth) { h ^= (h 》》》 20) ^ (h 》》》 12); returnh ^ (h 》》》 7) ^ (h 》》》 4); }
對于任意給定的對象,只要它的 hashCode() 返回值相同,那么程序調用 hash(int h) 方法所計算得到的 Hash 碼值總是相同的。接下來程序會調用 indexFor(int h, int length) 方法來計算該對象應該保存在 table 數組的哪個索引處。indexFor(int h, int length) 方法的代碼如下:
static intindexFor( inth, intlength) { returnh & ( length- 1); }
這個方法非常巧妙,它總是通過 h &(table.length -1) 來得到該對象的保存位置——而 HashMap 底層數組的長度總是 2 的 n 次方,這一點可參看后面關于 HashMap 構造器的介紹。
當 length 總是 2 的倍數時,h & (length-1) 將是一個非常巧妙的設計:假設 h=5,length=16, 那么 h & length - 1 將得到 5;如果 h=6,length=16, 那么 h & length - 1 將得到 6 ……如果 h=15,length=16, 那么 h & length - 1 將得到 15;但是當 h=16 時 , length=16 時,那么 h & length - 1 將得到 0 了;當 h=17 時 , length=16 時,那么 h & length - 1 將得到 1 了……這樣保證計算得到的索引值總是位于 table 數組的索引之內。
根據上面 put 方法的源代碼可以看出,當程序試圖將一個 key-value 對放入 HashMap 中時,程序首先根據該 key 的 hashCode() 返回值決定該 Entry 的存儲位置:如果兩個 Entry 的 key 的 hashCode() 返回值相同,那它們的存儲位置相同。如果這兩個 Entry 的 key 通過 equals 比較返回 true,新添加 Entry 的 value 將覆蓋集合中原有 Entry 的 value,但 key 不會覆蓋。如果這兩個 Entry 的 key 通過 equals 比較返回 false,新添加的 Entry 將與集合中原有 Entry 形成 Entry 鏈,而且新添加的 Entry 位于 Entry 鏈的頭部——具體說明繼續看 addEntry() 方法的說明。
當向 HashMap 中添加 key-value 對,由其 key 的 hashCode() 返回值決定該 key-value 對(就是 Entry 對象)的存儲位置。當兩個 Entry 對象的 key 的 hashCode() 返回值相同時,將由 key 通過 eqauls() 比較值決定是采用覆蓋行為(返回 true),還是產生 Entry 鏈(返回 false)。
上面程序中還調用了 addEntry(hash, key, value, i); 代碼,其中 addEntry 是 HashMap 提供的一個包訪問權限的方法,該方法僅用于添加一個 key-value 對。下面是該方法的代碼:
voidaddEntry( inthash, K key, V value, intbucketIndex) { // 獲取指定 bucketIndex 索引處的 Entry Entry《K,V》 e = table[bucketIndex]; // ① // 將新創建的 Entry 放入 bucketIndex 索引處,并讓新的 Entry 指向原來的 Entry table[bucketIndex] = newEntry《K,V》(hash, key,value, e); // 如果 Map 中的 key-value 對的數量超過了極限 if(size++ 》= threshold) // 把 table 對象的長度擴充到 2 倍。 resize( 2* table.length); // ② }
上面方法的代碼很簡單,但其中包含了一個非常優雅的設計:系統總是將新添加的 Entry 對象放入 table 數組的 bucketIndex 索引處——如果 bucketIndex 索引處已經有了一個 Entry 對象,那新添加的 Entry 對象指向原有的 Entry 對象(產生一個 Entry 鏈),如果 bucketIndex 索引處沒有 Entry 對象,也就是上面程序①號代碼的 e 變量是 null,也就是新放入的 Entry 對象指向 null,也就是沒有產生 Entry 鏈。
JDK 源碼
在 JDK 安裝目錄下可以找到一個 src.zip 壓縮文件,該文件里包含了 Java 基礎類庫的所有源文件。只要讀者有學習興趣,隨時可以打開這份壓縮文件來閱讀 Java 類庫的源代碼,這對提高讀者的編程能力是非常有幫助的。需要指出的是:src.zip 中包含的源代碼并沒有包含像上文中的中文注釋,這些注釋是筆者自己添加進去的。
Hash 算法的性能選項
根據上面代碼可以看出,在同一個 bucket 存儲 Entry 鏈的情況下,新放入的 Entry 總是位于 bucket 中,而最早放入該 bucket 中的 Entry 則位于這個 Entry 鏈的最末端。
上面程序中還有這樣兩個變量:
size:該變量保存了該 HashMap 中所包含的 key-value 對的數量。
threshold:該變量包含了 HashMap 能容納的 key-value 對的極限,它的值等于 HashMap 的容量乘以負載因子(load factor)。
從上面程序中②號代碼可以看出,當 size++ 》= threshold 時,HashMap 會自動調用 resize 方法擴充 HashMap 的容量。每擴充一次,HashMap 的容量就增大一倍。
上面程序中使用的 table 其實就是一個普通數組,每個數組都有一個固定的長度,這個數組的長度就是 HashMap 的容量。HashMap 包含如下幾個構造器:
HashMap():構建一個初始容量為 16,負載因子為 0.75 的 HashMap。
HashMap(int initialCapacity):構建一個初始容量為 initialCapacity,負載因子為 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的負載因子創建一個 HashMap。
當創建一個 HashMap 時,系統會自動創建一個 table 數組來保存 HashMap 中的 Entry,下面是 HashMap 中一個構造器的代碼:
// 以指定初始化容量、負載因子創建 HashMap 我的Java學習交流QQ群:589809992public HashMap( intinitialCapacity, floatloadFactor) { // 初始容量不能為負數if(initialCapacity 《 0) throw newIllegalArgumentException( “Illegal initial capacity: ”+ initialCapacity); // 如果初始容量大于最大容量,讓出示容量 if(initialCapacity 》 MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // 負載因子必須大于 0 的數值 if(loadFactor 《= 0|| Float.isNaN(loadFactor)) throw newIllegalArgumentException( loadFactor); // 計算出大于 initialCapacity 的最小的 2 的 n 次方值。 intcapacity = 1;while(capacity 《 initialCapacity) capacity 《《= 1; this.loadFactor = loadFactor; // 設置容量極限等于容量 * 負載因子 threshold = ( int)(capacity * loadFactor); // 初始化 table 數組table = newEntry[capacity]; // ① init(); }
上面代碼中粗體字代碼包含了一個簡潔的代碼實現:找出大于 initialCapacity 的、最小的 2 的 n 次方值,并將其作為 HashMap 的實際容量(由 capacity 變量保存)。例如給定 initialCapacity 為 10,那么該 HashMap 的實際容量就是 16。
程序①號代碼處可以看到:table 的實質就是一個數組,一個長度為 capacity 的數組。
對于 HashMap 及其子類而言,它們采用 Hash 算法來決定集合中元素的存儲位置。當系統開始初始化 HashMap 時,系統會創建一個長度為 capacity 的 Entry 數組,這個數組里可以存儲元素的位置被稱為“桶(bucket)”,每個 bucket 都有其指定索引,系統可以根據其索引快速訪問該 bucket 里存儲的元素。
無論何時,HashMap 的每個“桶”只存儲一個元素(也就是一個 Entry),由于 Entry 對象可以包含一個引用變量(就是 Entry 構造器的的最后一個參數)用于指向下一個 Entry,因此可能出現的情況是:HashMap 的 bucket 中只有一個 Entry,但這個 Entry 指向另一個 Entry ——這就形成了一個 Entry 鏈。如圖 1 所示:
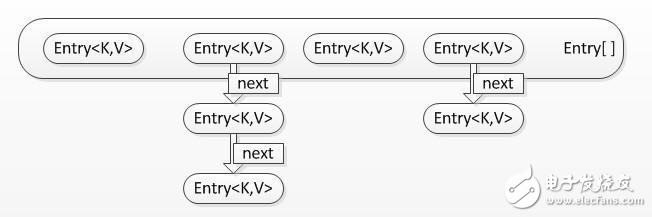
HashMap 的讀取實現
當 HashMap 的每個 bucket 里存儲的 Entry 只是單個 Entry ——也就是沒有通過指針產生 Entry 鏈時,此時的 HashMap 具有最好的性能:當程序通過 key 取出對應 value 時,系統只要先計算出該 key 的 hashCode() 返回值,在根據該 hashCode 返回值找出該 key 在 table 數組中的索引,然后取出該索引處的 Entry,最后返回該 key 對應的 value 即可。看 HashMap 類的 get(K key) 方法代碼
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%