聲紋識別技術在身份認證方面的應用分析
虛擬引擎
時變問題
人的整個發聲系統隨著時間的推移會產生一定的變化,這些變化直接導致了其語音信息中的聲紋信息的變化,如果算法或系統不考慮這些變化,那么一段時間后,系統的識別性能將有所下降。為此我們錄制了長達4年的100人的時變語音庫,基于此語音庫分析,我們找到了和時變相關的一些特征信息和規律,并試用其對MFCC和PLP特征的提取過程進行了修改。另外在工程方面,以聲密保系為例,其在架構設計中就考慮到了模型的在線更新問題,并設計了專門的語音篩選算法,系統會定期的挑選用戶符合條件的最新語音進行模型的重新訓練。
噪音問題
正如軟件工程中所提的沒有銀彈的概念一樣,任何技術都有一定的局限性,不可能無限制地應用于任何場景,聲紋技術在大噪音環境下并不適用。針對此我們開發了一套語音質量檢測的庫來對環境噪音和語音的信噪比進行檢測,將不符合條件的語音排除在系統之外并對用戶進行提示。此套噪音檢測系統采用了傳統的基于能量、包絡、自相關系數等特征的檢測算法和RNN/LSTM相結合方法,能準確的檢測出96%以上不符合條件的場景。
防錄音重放攻擊措施
在解決這些傳統問題的同時,為了保證用聲紋進行遠程身份認證的安全性,我們還提出了一系列防攻擊措施,包括動態密碼語音、用戶自定義密碼、多特征活體檢測和錄音重放等。由于篇幅有限,下面詳細介紹我們在錄音重放上的工作。
錄音重放是一種常見的聲紋特征盜取手段,由于采用動態密碼的方式,很難將一個人的各種發音組合全部錄制下來。但我們還是假設如果把這個人所有的文本發音(在聲密保系統中為0~9的數字發音)全部錄下來,然后根據系統提示的數字密碼進行拼接重放,那么還是同一個人的聲音,是否能夠通過聲紋識別系統驗證呢?
我們先分析一個典型的錄音重放過程:
正常語音信號:y(t)=x(t)*a(t)
錄音重放語音信號:y’(t)=x(t)*a’(t) *d’(t)*a(t)
圖5中錄音ADCs(模數轉換)和重放DACs(數模轉換)是對語音信號的兩次傳輸,均會對原始信號產生影響,且ADCs和DACs是非連續可逆的,除了ADCs和DACs外,傳輸過程還包括噪音、混響等因素,錄音重放會造成信道失配和信號強度衰減等現象。
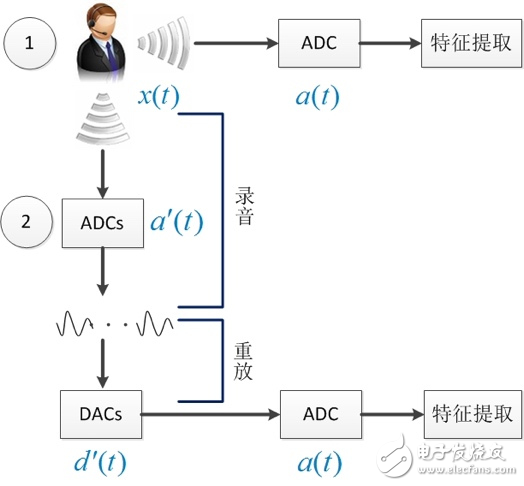
圖5 典型的錄音重放過程
圖6給出了一段真實語音和其錄音重放后語音的時頻分析,可以看出在這種情況下真實語音和錄音重放語音很難被區分,錄音重放可以說是最容易實施和最難被檢測的假體攻擊方式。
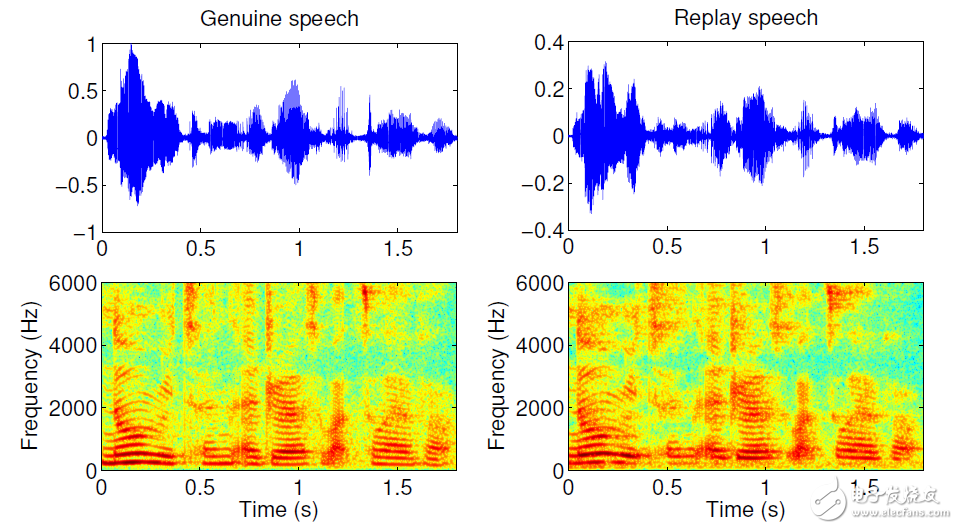
圖6 一段真語音和錄音重放語音的時頻分析
2017年的Automatic Speaker Verification Spoofing and Countermeasures (ASVspoof) Challenge中,首次將錄音重放檢測納入到說話人識別的防闖入比賽中,一個理想的錄音重放檢測系統應該在已知和未知的條件下都很魯棒,包含與訓練數據不同的說話人、不同的錄音重放內容和不同的錄音重放設備。ASVspoof針對錄音重放檢測進行的比賽中,全球近100個團隊參加,最終提交了49個,我司的結果排在第5。相關的聲紋確認防錄音論文發表在Interspeech上。
《A Study on Replay Attack and Anti-Spoofing for Automatic Speaker Verification》論文主要分兩部分:第一部分分析了不同的說話人、文本和設備對錄音重放檢測性能的影響;第二部分給出了有效的錄音重放檢測算法實現。
論文用F-ratio來分析不同因素對重放檢測性能的影響。F-ratio是一個簡單的頻域加權方法,頻帶的權重可以由其對任務的判別能力決定。假設在分析語音譜時采用的濾波器個數為M,第i個濾波器的F-ratio可以定義為:
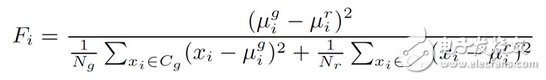
Cg表示真實語音,Cr表示重放語音。xi表示第i個濾波器語音幀x的值,uig和uir分別是濾波器內真實語音和重放語音所有幀的均值,Ng和Nr分別是兩類語音的語音幀數。最后用M個濾波器的F-ratio值組[F1,F2,…,FM]來分析真實語音和重放語音在不同頻帶上的區分性。
在ASVspoof中,開發集和測試集中含有比訓練集種類更多的錄音重放設備。在訓練集中利用少量設備的錄音重放語音進行模型訓練非常容易導致過擬合,弱化了提取的特征和訓練的模型的概化能力。為了提高概化能力,降低這種變化對重放檢測的影響,論文采用了頻率彎折的方法,如圖7所示,Mel方法增強了特征在低頻段的區分能力,IMel方法增強了特征在高頻段的區分能力。
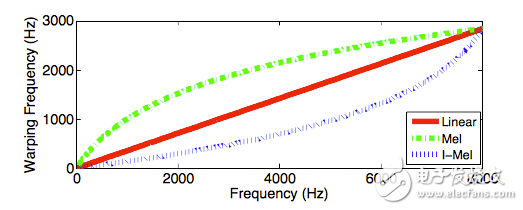
圖7 三種頻率彎折曲線
圖8給出了在Mel和IMel兩種頻率彎折方法下,不同的說話人、文本內容、和錄音重放設備在濾波器組上的F-ratio值,從(c)列圖中可以看出用Mel方法,不同的錄音重放設備對濾波器組的F-ratio值影響很明顯;但是IMel方法大大降低了設備間差異對F-ratio的影響,這對后面建立概化能力更強的模型具有非常重要的意義。
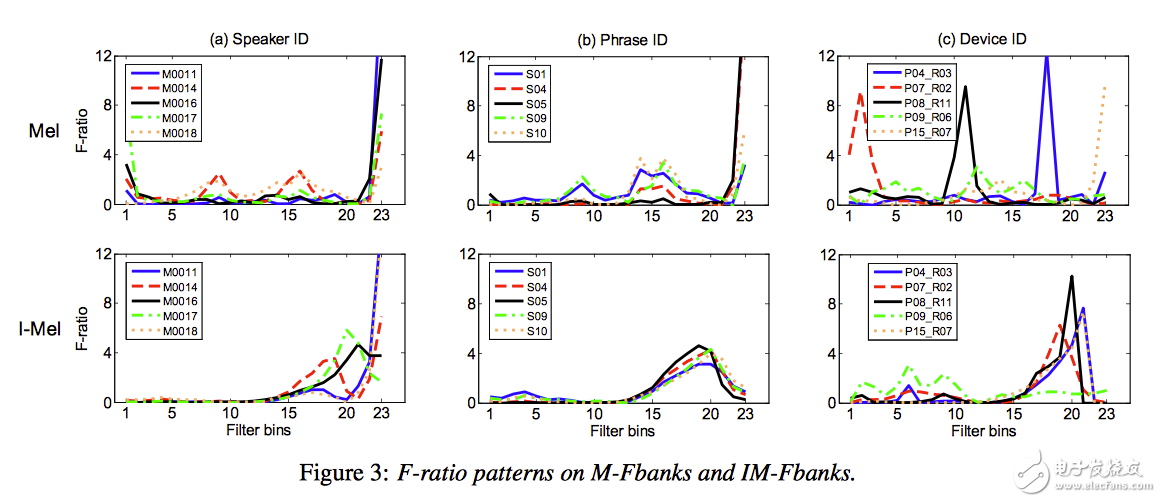
圖8 Mel和IMel方法在不同的說話人、文本和設備情況下對F-ratio的影響
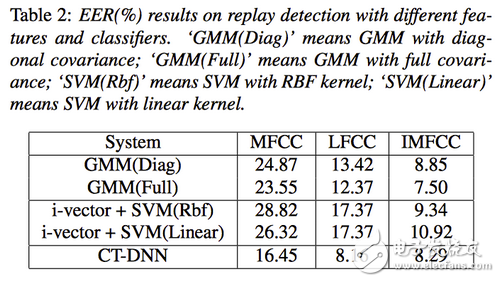
在錄音重放檢測部分,論文使用(MFCC,LPCC和IMFCC)三種特征在訓練集上建立了基于GMM、ivector/SVM和DNN的重放檢測系統,并在開發集中進行了測試。從下面結果可以看出IMFCC特征是最有效的,最簡單的GMM模型取得了最好的效果,DNN模型雖然在表中也取得了不錯的效果,但是存在不穩定的問題,不同的初始化將導致不同的結果,有的差異很大。
其實在日常生活中用手機進行錄音重放是最方便的。相比于多樣性的錄音重放設備,手機等移動設備上的錄音重放檢測要簡單的多,我們曾經對60種不同型號的手機進行了接近十萬條的錄音重放檢測,結果重放的檢出率基本為100%。
總結
聲紋作為生物特征中的行為特征,配合語音識別技術,通過互動方式在遠程身份認證“用自己來證明自己”方面有其他生物特征難以替代的優勢。當然,就像前面提到的任何技術都有一定的局限性,不可能無限制的應用于任何場景。只有通過結合聲紋和其他生物特征組成多因子認證手段,才能更好地保證遠程身份認證安全。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
聲紋識別技術在身份認證方面的應用分析下載
相關電子資料下載
- 曙光一體化算力服務平臺為聲紋識別技術提供大規模算力算法服務 860
- 聲紋識別技術與智慧城市建設同步發展 2561
- 人工智能(AI)推動聲紋識別技術應用落地 1533
- 六大場景 看懂聲紋識別技術怎樣“抗疫防疫” 1668
- 聲紋識別技術能否不像其他技術那樣多難 1055
- 聲紋識別技術研究的方向在哪里 668
- 聲紋識別技術或將成為下一個行業新風口 571
- 君林科技應邀做了《聲紋識別技術及其在電梯聲音監控及分析領域的應用》主題 3013
- 深度神經網絡算法打造頂尖聲紋識別技術 3347
- 聲紋識別技術排名全球前三,快商通憑什么? 7747