十三個框架助你掌握機器學習
Apache Spark MLlib
Apache Spark 最為人所知的是它是Hadoop家族的一員,但是這個內存數據處理框架卻是脫胎于Hadoop之外,也正在Hadoop生態系統以外為自己獲得了名聲。Hadoop 已經成為可供使用的機器學習工具,這得益于其不斷增長的算法庫,這些算法可以高速度應用于內存中的數據。。
早期版本的Spark 增強了對MLib的支持,MLib是主要面向數學和統計用戶的平臺,它允許 通過持久化管道特性將Spark機器學習工作掛起和恢復。2016年發布的Spark2.0,對Tungsten高速內存管理系統和新的DataFrames流媒體API 進行了改進,這兩點都會提升機器學習應用的性能。

H2O
H2O,現在已經發展到第三版,可以提供通過普通開發環境(Python, Java, Scala, R)、大數據系統(Hadoop, Spark)以及數據源(HDFS, S3, SQL, NoSQL)訪問機器學習算法的途徑。H2O是用于數據收集、模型構建以及服務預測的端對端解決方案。例如,可以將模型導出為Java代碼,這樣就可以在很多平臺和環境中進行預測。
H2O可以作為原生Python庫,或者是通過Jupyter Notebook, 或者是 R Studio中的R 語言來工作。這個平臺也包含一個開源的、基于web的、在H2O中稱為Flow的環境,它支持在訓練過程中與數據集進行交互,而不只是在訓練前或者訓練后。

Apache Singa
“深度學習”框架增強了重任務類型機器學習的功能,如自然語言處理和圖像識別。Singa是一個Apache的孵化器項目,也是一個開源框架,作用是使在大規模數據集上訓練深度學習模型變得更簡單。
Singa提供了一個簡單的編程模型,用于在機器群集上訓練深度學習網絡,它支持很多普通類型的訓練工作:卷積神經網絡,受限玻爾茲曼機 以及循環神經網絡。 模型可以同步訓練(一個接一個)或者也異步(一起)訓練,也可以允許在在CPU和GPU群集上,很快也會支持FPGA。Singa也通過Apache Zookeeper簡化了群集的設置。
Caffe2
深度學習框架Caffe開發時秉承的理念是“表達、速度和模塊化”,最初是源于2013年的機器視覺項目,此后,Caffe還得到擴展吸收了其他的應用,如語音和多媒體。
因為速度放在優先位置 ,所以Caffe完全用C+ +實現,并且支持CUDA加速,而且根據需要可以在CPU和GPU處理間進行切換。分發內容包括免費的用于普通分類任務的開源參考模型,以及其他由Caffe用戶社區創造和分享的模型。
一個新的由Facebook 支持的Caffe迭代版本稱為Caffe2,現在正在開發過程中,即將進行1.0發布。其目標是為了簡化分布式訓練和移動部署,提供對于諸如FPGA等新類型硬件的支持,并且利用先進的如16位浮點數訓練的特性。
Google的TensorFlow
與微軟的DMTK很類似,Google TensorFlow是一個機器學習框架,旨在跨多個節點進行擴展。 就像Google的 Kubernetes一樣,它是是為了解決google內部的問題而設計的,google最終還是把它作為開源產品發布出來。
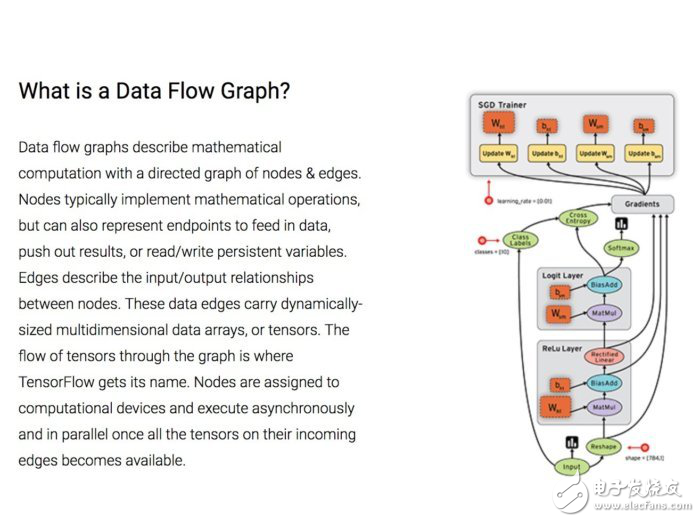
TensorFlow實現了所謂的數據流圖,其中的批量數據(“tensors”)可以通過圖描述的一系列算法進行處理。系統中數據的移動稱為“流”-其名也因此得來。這些圖可以通過C++或者Python實現并且可以在CPU和GPU上進行處理。
TensorFlow近來的升級提高了與Python的兼容性,改進了GPU操作,也為TensorFlow能夠運行在更多種類的硬件上打開了方便之門,并且擴展了內置的分類和回歸工具庫。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%