分布式機器學習平臺的實現方法
本文選自紐約州里大學計算機系教授Murat和學生的論文,主要介紹了分布式機器學習平臺的實現方法并提出了未來的研究方向。
論文地址:www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf
機器學習特別是深度學習為語音識別、圖像識別、自然語言處理、推薦系統和搜索引擎等領域帶來的革命性的突破。這些技術將會廣泛用于自動駕駛、醫療健康系統、客戶關系管理、廣告、物聯網等場景。在資本的驅動下機器學習的發展十分迅速,近年來我們看到了各個公司和研究機構紛紛推出了自己的機器學習平臺。
由于需要訓練的數據集合模型十分巨大,機器學習平臺通常采用分布式的架構來實現,會采用成百上千的機器來訓練模型。在不遠的未來,涉及機器學習的計算將會成為數據中心的主要任務。
由于作者分布式系統的專業背景,本文從分布式系統的角度來研究這些機器學習平臺,并分析他們在通信和控制方面的瓶頸。同時我們還研究并比較了這些平臺的容錯性以及編程實現的難易程度。
根據實現原理和架構的不同,我們將分布式機器學習平臺分為三種不同的基本類型:
基礎數據流模式
參數服務器模型
先進的數據流模式
對于三種主流的實現方式做了簡短的介紹,分別利用Spark、PMLS和Tensorflow(MXNet)來對三種類型進行解讀。我們對不同的平臺進行了比較,詳細的結果見論文。
在文章的最后我們總結了分布式機器學習平臺并對未來給出了一些建議,如果你很熟悉機分布式器學習平臺的話可以跳過這部分。
Spark
在Spark里計算通過有向無環圖來建模,其中每一個頂點代表一個彈性分布式數據集(Resilient Distributed Dataset, RDD) ,而每條邊表示一種對于RDD的操作。RDD是一組分配在不同邏輯分區里的對象,這些邏輯分區直接在內存里儲存并處理,當內存空間不夠的時候,部分分區會被存放在硬盤上,需要的時候再和內存里的分區替換位置。
在有向無環圖中,從A定點指向B定點的E邊表示RDD A 通過E操作得到了RDD B。其中包含兩類操作:轉換類和動作類。轉換類操作意味著會產生新的RDD。
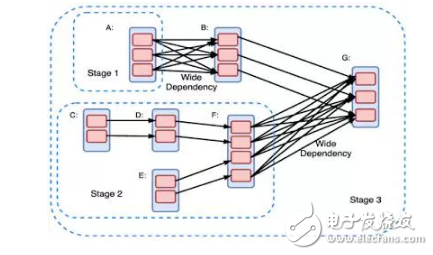
Spark的用戶通過建立對有向無環圖上RDD的轉換或者運行操作來實現計算。有向無環圖被編譯為一個個不同的級別,每一個級別包含一系列可以并行計算的任務(每個分區中一個任務)。任務間較弱的依賴性有利于高效的執行,而較強的依賴性則會因為大量的通信造成性能的嚴重下降。
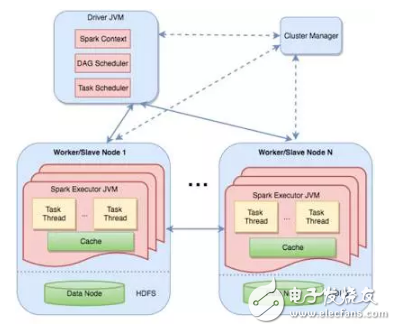
Spark通過將這些有向無環圖分級分配到不同的機器上來實現分布式計算,上圖顯示了主節點的清晰的工作架構。驅動包含兩個部分的調度器單元,DAG調度器和任務調度器,同時運行和協調不同機器間的工作。
Spark的設計初衷是用于通用的數據處理,并沒有針對機器學習的特殊設計。但是在MKlib工具包的幫助下,也能在Spark上實現機器學習。通常來說,Spark將模型參數存儲于驅動節點上,每一個機器在完成迭代之后都會與驅動節點通信更新參數。對于大規模的應用來說,模型參數可能會存在一個RDD上。由于每次迭代后都會引入新的RDD來存儲和更新參數,這會引入很多額外的負載。更新模型將會在機器和磁盤上引入數據的洗牌操作,這限制了Spark的大規模應用。這是基礎數據流模型的缺陷,Spark對于機器學習的迭代操作并沒有很好的支持。
PMLS
PMLS是為機器學習量身打造的平臺,通過引入了參數服務器抽象概念來處理機器學習訓練過程中頻繁的迭代。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%