詳解OpenStack虛擬機的資源調度錯誤排查
大小:0.8 MB 人氣: 2017-10-11 需要積分:1
本文將基于OpenStack最新release的liberty版本,分析OpenStack的虛擬機資源調度服務nova-scheduler的調度流程,并逐步說明OpenStack管理員在進行資源調度的錯誤排查過程中的尷尬境遇,然后提出一個OpenStack資源調度錯誤排查的改進方案,最后,本文會為大家展示IBM PRS(Platform Resource Scheduler)基于此方案的實現(xiàn)版本。
OpenStack虛擬機的資源調度
OpenStack對虛擬機的資源調度由nova模塊的nova-scheduler服務實現(xiàn),根據(jù)調度策略的不同,有兩個插件:基于filter的調度和基于隨機策略的調度,其中基于隨機策略的調度僅對正在服務的host隨機選擇,不進行任何資源審查,在實際生產環(huán)境中基本上不會用到,所以本文僅就OpenStack的默認的調度策略:基于filter的調度進行分析。如圖1所示,該策略主要通過三步完成虛擬機的資源調度返回候選host:
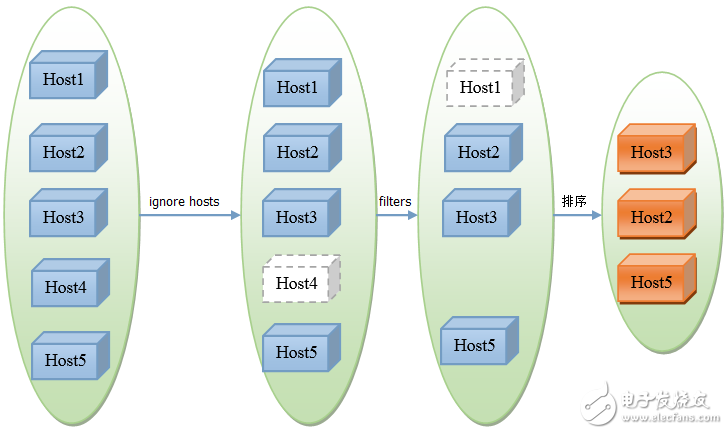
圖1.基于filter的調度workflow
Step 1: 獲取所有host的信息,如果調度請求中要求忽略一些host(ignore hosts),就將這些host從本次的候選host中刪除掉(一種特殊的情況是如果調度請求中要求虛擬機只能調度到一些host或者節(jié)點上,則只保留這些host作為候選host,不會對這些host做進一步額外的資源審查即step 2便直接返回)。
Step 2: 將第一步中返回的host列表依次迭代地通過scheduler_default_filters配置的所有filter的host_passes處理函數(shù),該函數(shù)會過濾掉不滿足相應filter條件的host。
Step 3:對第二步返回的host列表根據(jù)scheduler_weight_classes配置的weigher對候選host進行排序。
至此調度服務完成對虛擬機的資源調度,nova-conductor服務將會向調度服務選出的host所對應的nova-compute服務發(fā)出虛擬機部署請求。由于OpenStack調度服務固有的race condition,當虛擬機在compute節(jié)點部署失敗時,相應nova-compute服務將會向nova-conductor服務發(fā)送重新部署對應虛擬機的請求,用戶可以通過scheduler_max_attempts配置最多可以容忍compute部署失敗的次數(shù),該reschedule機制如圖2所示:
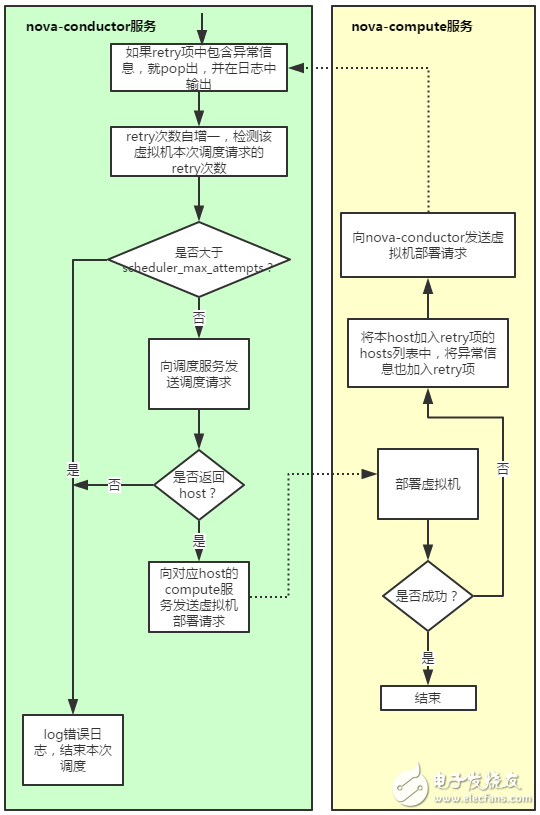
圖2.OpenStack資源調度的reschedule機制
由上可知,當我們在部署一個虛擬機的時候,本質上有兩類型的錯誤可能導致部署失敗:第一是調度服務發(fā)現(xiàn)沒有host可以滿足虛擬機的資源需求,第二是虛擬機在調度服務選出的目標host上部署時因為某種原因部署失敗(如卷請求超時或者網(wǎng)卡創(chuàng)建失敗等等)。我們在虛擬機部署失敗的錯誤排查時,需要從這兩類錯誤類型逐一排查。怎么查呢?當然是看日志(其實也可以首先通過nova show命令查看fault項,但基本上通過這個信息是看不出錯誤所在的),從圖2可以看出,我們應該從nova-conductor的日志開始,然后根據(jù)對應錯誤信息決定下一步該看nova-scheduler的日志還是對應nova-compute的日志。下面舉一個最簡單的由第一種錯誤導致虛擬機部署失敗的錯誤排查的例子來說明一下OpenStack原生資源調度的錯誤排查是如何讓管理員望而生畏的。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
詳解OpenStack虛擬機的資源調度錯誤排查下載
相關電子資料下載
- Openstack網(wǎng)絡模型場景及代碼解析 161
- 2023年了,OpenStack仍是第三大開源項目 849
- 圖數(shù)據(jù)庫驅動的基礎設施運維代碼編程案例 83
- openEuler資源利用率提升之道:虛擬機混部OpenStack調度 398
- 使用Ansible的OpenStack自動化 501
- 中國OpenStack往事回望 449
- openEuler社區(qū)鄧一諾:實踐是探索和提升的最佳捷徑 663
- 后OpenStack時代的Kubernetes 398
- NestOS實例創(chuàng)建與配置 517
- 開源云基礎設施軟件OpenStack最新版本Yoga發(fā)布 1644