基于概率的大數據查詢系統
大小:0.78 MB 人氣: 2017-12-25 需要積分:3
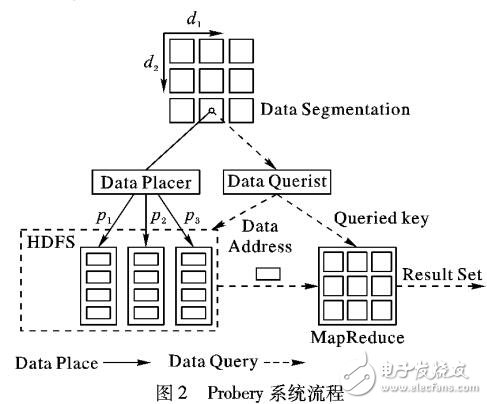
針對大數據環境下完整性查詢時間代價消耗過高的問題,提出了一種采用近似完整性查詢方法的系統-Probery。Probery所采用的近似完整性查詢方法不同于傳統的近似查詢,其近似性主要體現為數據查全的可能性,是一種新型的數據查詢方法。Probery首先將存入系統的數據劃分為多個數據分段;然后,根據概率放置模型將各個數據分段的數據存儲在分布式文件系統中;最后,對于給定的查詢條件,Probery采用一種啟發式查詢方法進行概率查詢。通過與其他主流的非關系型數據管理系統的查詢性能進行比較,對Probery進行驗證,Probery在損失8%查詢完整性的情形下,查詢時間較HBase相比節約了51%,較Cassandra相比節約了23%,較MongoDB相比節約了12%,較Hive相比節約了3%。實驗結果表明,Probery可以適當地損失查詢完整性來提高數據的查詢性能,具有較好的通用性、適應性和可擴展性。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
基于概率的大數據查詢系統下載
相關電子資料下載
- 數據分析工具有哪幾種模式 83
- 中交興路入選2024北京“數據要素×”典型案例集 886
- 中國鐵塔與海康威視達成戰略合作 217
- spark運行的基本流程 91
- 季豐電子與孤波科技攜手合作為車規量產提供大數據支持 740
- 智慧園區綜合安防系統解決方案 83
- 大數據采集系統分為幾類 269
- 如何在數字化時代實現精益生產的創新發展? 117
- 智慧水文監測系統 87
- 大數據分析平臺網站 96