 電子發(fā)燒友App
電子發(fā)燒友App


背景
為了提高數(shù)據(jù)訪問的速度,一般數(shù)據(jù)庫操作系統(tǒng)都會引入內(nèi)存作為緩存,而為了方便管理和合并I/O,一般會開辟一個緩存池(buffer pool)。本文主要講述PostgreSQL 如何進行緩存池管理。 ?
數(shù)據(jù)庫物理結(jié)構(gòu)
在下文講述緩存池管理之前,我們需要簡單介紹下PostgreSQL 的數(shù)據(jù)庫集簇的物理結(jié)構(gòu)。PostgreSQL 的數(shù)據(jù)文件是按特定的目錄和文件名組成: 如果是特定的tablespace 的表/索引數(shù)據(jù),則文件名形如
$PGDATA/pg_tblspc/$tablespace_oid/$database_oid/$relation_oid.no如果不是特定的tablespace 的表/索引數(shù)據(jù),則文件名形如
$PGDATA/base/$database_oid/$relation_oid.num其中PGDATA 是初始化的數(shù)據(jù)根目錄,tablespace_oid 是tablespace 的oid,database_oid 是database 的oid,relation_oid是表/索引的oid。no 是一個數(shù)值,當表/索引的大小超過了1G(該值可以在編譯PostgreSQL 源碼時由configuration的–with-segsize 參數(shù)指定大小),該數(shù)值就會加1,初始值為0,但是為0時文件的后綴不加.0。 除此之外,表/索引數(shù)據(jù)文件中還包含以_fsm(與free space map 相關(guān),詳見文檔?) 和_vm (與visibility map 相關(guān),詳見文檔?)為后綴的文件。這兩種文件在PostgreSQL 中被認為是表/索引數(shù)據(jù)文件的另外兩種副本,其中_fsm 結(jié)尾的文件為該表/索引的數(shù)據(jù)文件副本1,_vm結(jié)尾的文件為該表/索引的數(shù)據(jù)文件副本2,而不帶這兩種后綴的文件為該表/索引的數(shù)據(jù)文件副本0。 無論表/索引的數(shù)據(jù)文件副本0或者1或者2,都是按照頁面(page)為組織單元存儲的,具體數(shù)據(jù)頁的內(nèi)容和結(jié)構(gòu),我們這里不再詳細展開。但是值得一提的是,緩沖池中最終存儲的就是一個個的page。而每個page我們可以按照(tablespace_oid, database_oid, relation_oid, fork_no, page_no) 唯一標示,而在PostgreSQL 源碼中是使用結(jié)構(gòu)體BufferTag 來表示,其結(jié)構(gòu)如下,下文將會詳細分析這個唯一標示在內(nèi)存管理中起到的作用。
typedef struct buftag{ RelFileNode rnode;
/* physical relation identifier */ ForkNumber forkNum; BlockNumber blockNum;
/* blknum relative to begin of reln */} BufferTag;typedef struct RelFileNode{
Oid
spcNode;
/* tablespace */
Oid
dbNode;
/* database */
Oid
relNode;
/* relation */} RelFileNode;
緩存管理結(jié)構(gòu)
在PostgreSQL中,緩存池可以簡單理解為在共享內(nèi)存上分配的一個數(shù)組,其初始化的過程如下:
BufferBlocks = (char *) ShmemInitStruct("Buffer Blocks", NBuffers * (Size) BLCKSZ, &foundBufs);
其中NBuffers 即緩存池的大小與GUC 參數(shù)shared_buffers 相關(guān)(詳見鏈接)。數(shù)組中每個元素存儲一個緩存頁,對應(yīng)的下標buf_id 可以唯一標示一個緩存頁。 為了對每個緩存頁進行管理,我們需要管理其元數(shù)據(jù),在PostgreSQL 中利用BufferDesc 結(jié)構(gòu)體來表示每個緩存頁的元數(shù)據(jù),下文稱其為緩存描述符,其初始化過程如下:
BufferDescriptors = (BufferDescPadded *) ShmemInitStruct("Buffer Descriptors", NBuffers * sizeof(BufferDescPadded), &foundDescs);可以發(fā)現(xiàn),緩存描述符是和緩存池的每個頁面一一對應(yīng)的,即如果有16384 個緩存頁面,則就有16384 個緩存描述符。而其中的BufferTag 即是上文的PostgreSQL 中數(shù)據(jù)頁面的唯一標示。 直到這里,我們?nèi)绻獜木彺娉刂姓埱竽硞€特定的頁面,只需要遍歷所有的緩存描述符即可。但是很顯然這樣的性能會非常的差。為了優(yōu)化這個過程,PostgreSQL 引入了一個BufferTag 和緩存描述符的hash 映射表。通過它,我們可以快速找到特定的數(shù)據(jù)頁面在緩存池中的位置。 概括起來,PostgreSQL 的緩存管理主要包括三層結(jié)構(gòu),如下圖:
緩存池,是一個數(shù)組,每個元素其實就是一個緩存頁,下標buf_id 唯一標示一個緩存頁。
緩存描述符,也是一個數(shù)組,而且和緩存池的緩存一一對應(yīng),保存每個緩存頁的元數(shù)據(jù)信息。
緩存hash 表,是存儲BufferTag 和緩存描述符之間映射關(guān)系的hash 表。 ?
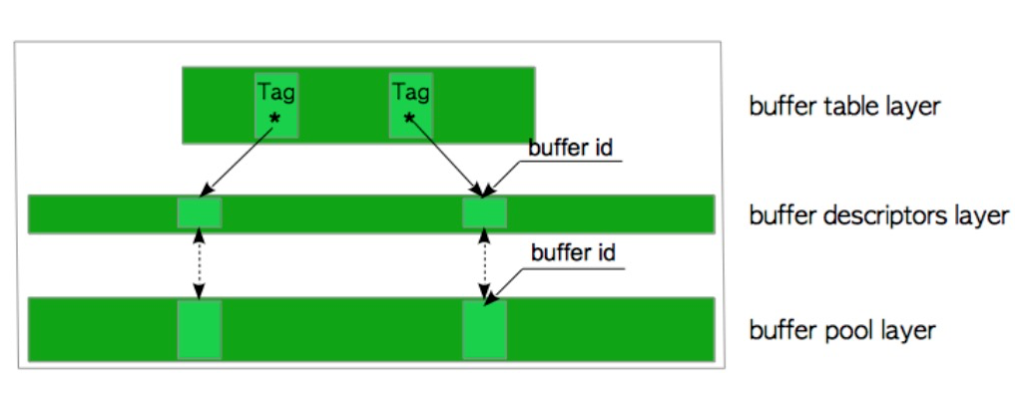
下文,我們將分析每層結(jié)構(gòu)的具體實現(xiàn)以及涉及到的鎖管理和緩沖頁淘汰算法,深入淺出,介紹PostgreSQL 緩存池的管理機制。
緩存hash 表
從上文的分析,我們知道緩存hash 表是為了加快BufferTag 和緩存描述符的檢索速度構(gòu)造的數(shù)據(jù)結(jié)構(gòu)。在PostgreSQL 中,緩存hash 表的數(shù)據(jù)結(jié)構(gòu)設(shè)計比較復(fù)雜,我們會在接下來的月報去介紹在PostgreSQL 中緩存hash 表是如何實現(xiàn)的。在本文中,我們把緩存hash 表抽象成一個個的bucket slot。因為哈希函數(shù)還是有可能碰撞的,所以bucket slot 內(nèi)可能有幾個data entry 以鏈表的形式存儲,如下圖:
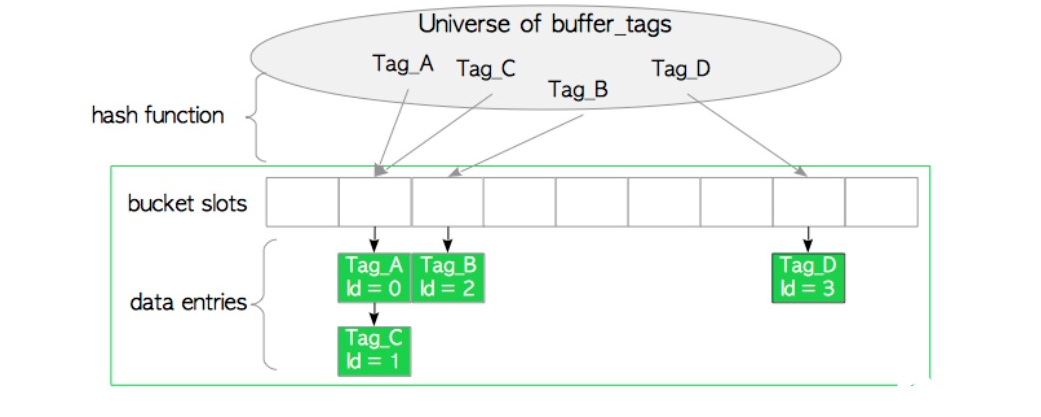
而使用BufferTag 查找對應(yīng)緩存描述符的過程可以簡述如下:
獲取BufferTag 對應(yīng)的哈希值hashvalue
通過hashvalue 定位到具體的bucket slot
遍歷bucket slot 找到具體的data entry,其數(shù)據(jù)結(jié)構(gòu)BufferLookupEnt 如下:
/* entry for buffer lookup hashtable */typedef struct{ BufferTag key;
/* Tag of a disk page */ int
id;
/* Associated buffer ID */} BufferLookupEnt;
BufferLookupEnt 的結(jié)構(gòu)包含id 屬性,而這個屬性可以和唯一的緩存描述符或者唯一的緩存頁對應(yīng),所以我們就獲取了BufferTag 對應(yīng)的緩存描述符。 緩存hash 表初始化的過程如下:
InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);可以看出,緩存hash 表的bucket slot 個數(shù)要比緩存池個數(shù)NBuffers 要大。除此之外,多個后端進程同時訪問相同的bucket slot 需要使用鎖來進行保護,后文的鎖管理會詳細講述這個過程。
緩存描述符
上文的緩存hash 表可以通過BufferTag 查詢到對應(yīng)的 buffer ID,而PostgreSQL 在初始化 緩存描述符和緩存頁面一一對應(yīng),存儲每個緩存頁面的元數(shù)據(jù)信息,其數(shù)據(jù)結(jié)構(gòu)BufferDesc 如下:
typedef struct BufferDesc{ BufferTag tag;
/* ID of page contained in buffer */ int
buf_id;
/* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state;
int
wait_backend_pid;
/* backend PID of pin-count waiter */
int
freeNext;
/* link in freelist chain */
LWLock
content_lock;
/* to lock access to buffer contents */} BufferDesc;
其中:
tag 指的是對應(yīng)緩存頁存儲的數(shù)據(jù)頁的唯一標示
buffer_id 指的是對應(yīng)緩存頁的下標,我們通過它可以直接訪問對應(yīng)緩存頁
state 是一個無符號32位的變量,包含:
18 bits refcount,當前一共有多少個后臺進程正在訪問該緩存頁,如果沒有進程訪問該頁面,本文稱為該緩存描述符unpinned,否則稱為該緩存描述符pinned
4 bits usage count,最近一共有多少個后臺進程訪問過該緩存頁,這個屬性用于緩存頁淘汰算法,下文將具體講解。
10 bits of flags,表示一些緩存頁的其他狀態(tài),如下:
#define BM_LOCKED (1U << 22) /* buffer header is locked */#define BM_DIRTY (1U << 23) /* data needs writing */#define BM_VALID (1U << 24) /* data is valid */#define BM_TAG_VALID (1U << 25) /* tag is assigned */#define BM_IO_IN_PROGRESS (1U << 26) /* read or write in progress */#define BM_IO_ERROR (1U << 27) /* previous I/O failed */#define BM_JUST_DIRTIED (1U << 28) /* dirtied since write started */#define BM_PIN_COUNT_WAITER (1U << 29) /* have waiter for sole pin */#define BM_CHECKPOINT_NEEDED (1U << 30) /* must write for checkpoint */#define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged, * or init fork) */
freeNext,指向該緩存之后第一個空閑的緩存描述符
content_lock,是控制緩存描述符的一個輕量級鎖,我們會在緩存鎖管理具體分析其作用
上文講到,當數(shù)據(jù)啟動時,會初始化與緩存池大小相同的緩存描述符數(shù)組,其每個緩存描述符都是空的,這時整個緩存管理的三層結(jié)構(gòu)如下
第一個數(shù)據(jù)頁面從磁盤加載到緩存池的過程可以簡述如下:
從freelist 中找到第一個緩存描述符,并且把該緩存描述符pinned (增加refcount和usage_count)
在緩存hash 表中插入這個數(shù)據(jù)頁面的BufferTag 與buf_id 的對應(yīng)新的data entry
從磁盤中將數(shù)據(jù)頁面加載到緩存池中對應(yīng)緩存頁面中
在對應(yīng)緩存描述符中更新該頁面的元數(shù)據(jù)信息
緩存描述符是可以持續(xù)更新的,但是如下場景會使得對應(yīng)的緩存描述符狀態(tài)置為空并且放在freelist 中:
數(shù)據(jù)頁面對應(yīng)的表或者索引被刪除
數(shù)據(jù)頁面對應(yīng)的數(shù)據(jù)庫被刪除
數(shù)據(jù)頁面被VACUUM FULL 命令清理
緩存池
上文也提到過,緩存池可以簡單理解為在共享內(nèi)存上分配的一個緩存頁數(shù)組,每個緩存頁大小為PostgreSQL 頁面的大小,一般為8KB,而下標buf_id 唯一標示一個緩存頁。 緩沖池的大小與GUC 參數(shù)shared_buffers 相關(guān),例如shared_buffers 設(shè)置為128MB,頁面大小為8KB,則有128MB/8KB=16384個緩存頁。
緩存鎖管理
在PostgreSQL 中是支持并發(fā)查詢和寫入的,多個進程對緩存的訪問和更新是使用鎖的機制來實現(xiàn)的,接下來我們分析下在PostgreSQL 中緩存相關(guān)鎖的實現(xiàn)。 因為在緩存管理的三層結(jié)構(gòu)中,每層都有并發(fā)讀寫的情況,通過控制緩存描述符的并發(fā)訪問就能夠解決緩存池的并發(fā)訪問,所以這里的緩存鎖實際上就是講的緩存hash 表和緩存描述符的鎖。
BufMappingLock
BufMappingLock 是緩存hash 表的輕量級鎖。為了減少BufMappingLock 的鎖爭搶并且能夠兼顧鎖空間的開銷,PostgreSQL 中把BufMappingLock 鎖分為了很多片,默認為128片,每一片對應(yīng)總數(shù)/128 個bucket slot。 當我們檢索一個BufferTag 對應(yīng)的data entry是需要BufMappingLock 對應(yīng)分區(qū)的共享鎖,當我們插入或者刪除一個data entry 的時候需要BufMappingLock 對應(yīng)分區(qū)的排他鎖。 除此之外,緩存hash 表還需要其他的一些原子鎖來保證一些屬性的一致性,這里不再贅述。
content_lock
content_lock 是緩存描述符的輕量級鎖。當需要讀一個緩存頁的時候,后臺進程會去請求該緩存頁對應(yīng)緩存描述符的content_lock 共享鎖。而當以下的場景,后臺進程會去請求content_lock 排他鎖:
插入或者刪除/更新該緩存頁的元組
vacuum 該緩存頁
freeze 該緩存頁
io_in_progress_lock
io_in_progress_lock 是作用于緩存描述符上的I/O鎖。當后臺進程將對應(yīng)緩存頁加載至緩存或者刷出緩存,都需要這個緩存描述符上的io_in_progress_lock 排它鎖。
其他
緩存描述符中的state 屬性含有很多需要原子排他性的字段,例如refcount 和 usage count。但是在這里沒有使用鎖,而是使用pg_atomic_unlocked_write_u32()或者pg_atomic_read_u32() 方法來保證多進程訪問相同緩存描述符的state 的原子性。
緩存頁淘汰算法
在PostgreSQL 中采用clock-sweep 算法來進行緩存頁的淘汰。clock-sweep 是NFU(Not Frequently Used)最近不常使用算法的一個優(yōu)化算法。其算法在PostgreSQL 中的實現(xiàn)可以簡述如下:
獲取第一個候選緩存描述符,存儲在freelist 控制信息的數(shù)據(jù)結(jié)構(gòu)BufferStrategyControl 的nextVictimBuffer 屬性中
如果該緩存描述符unpinned,則跳到步驟3,否則跳到步驟4
如果該候選緩存描述符的usage_count 屬性為0,則選取該緩存描述符為要淘汰的緩存描述符,跳到步驟5,否則,usage_count–,跳到步驟4
nextVictimBuffer 賦值為下一個緩存描述符(當緩存描述符全部遍歷完成,則從第0個繼續(xù)),跳到步驟1繼續(xù)執(zhí)行,直到發(fā)現(xiàn)一個要淘汰的緩存描述符
返回要淘汰的緩存描述符的buf_id
clock-sweep 算法一個比較簡單的例子如下圖:
總結(jié)
至此,我們已經(jīng)對PostgreSQL 的緩存池管理整個構(gòu)架和一些關(guān)鍵的技術(shù)有了了解,下面我們會舉例說明整個流程。 為了能夠涉及到較多的操作,我們將緩存池滿后訪問某個不在緩存池的數(shù)據(jù)頁面這種場景作為例子,其整個流程如下:
根據(jù)請求的數(shù)據(jù)頁面形成BufferTag,假設(shè)為Tag_M,用Tag_M 去從緩存hash 表中檢索data entry,很明顯這里沒有發(fā)現(xiàn)該BufferTag
使用clock-sweep 算法選擇一個要淘汰的緩存頁面,例如這里buf_id=5,該緩存頁的data entry 為’Tag_F, buf_id=5’
如果是臟頁,將buf_id=5的緩存頁刷新到磁盤,否則跳到步驟4。刷新一個臟頁的步驟如下: a. 獲得buffer_id=5的緩存描述符的content_lock 共享鎖和io_in_progress 排它鎖(步驟f會釋放) b. 修改該描述符的state,BM_IO_IN_PROGRESS 和BM_JUST_DIRTIED 字段設(shè)為1 c. 根據(jù)情況,執(zhí)行 XLogFlush() 函數(shù),對應(yīng)的wal 日志刷新到磁盤 d. 將緩存頁刷新到磁盤 e. 修改該描述符的state,BM_IO_IN_PROGRESS 字段設(shè)為1,BM_VALID 字段設(shè)為1 f. 釋放該緩存描述符的content_lock 共享鎖和io_in_progress 排它鎖
獲取buf_id=5的bucket slot 對應(yīng)的BufMappingLock 分區(qū)排他鎖,并將該data entry 標記為舊的
獲取新的Tag_M 對應(yīng)bucket slot 的BufMappingLock 分區(qū)排他鎖并且插入一條新的data entry
刪除buf_id=5的data entry,并且釋放buf_id=5的bucket slot 對應(yīng)的BufMappingLock 分區(qū)鎖
從磁盤上加載數(shù)據(jù)頁面到buf_id=5的緩存頁面,并且更新buf_id=5的緩存描述符state 屬性的BM_DIRTY字段為0,初始化state的其他字段。
釋放Tag_M 對應(yīng)bucket slot 的BufMappingLock 分區(qū)排他鎖
從緩存中訪問該數(shù)據(jù)頁面
其過程的示意圖如下所示:
編輯:hfy















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論