 電子發燒友App
電子發燒友App


作者 | Dr. Luo
簡介:東南大學工學博士,英國布里斯托大學博士后,復睿微電子英國研發中心GRUK首席AI科學家,常駐英國劍橋。Dr. Luo長期從事科學研究和機器視覺先進產品開發,曾在某500強ICT企業擔任機器視覺首席科學家。
AI算法在自動駕駛ADS領域的行業應用,其當前從感知到認知的演進方向,主要體現在:
1)能夠在統一空間支持多模傳感器感知融合與多任務共享,在提升有限算力的計算效率的同時,確保算法模型在信息提取中對極端惡劣場景(雨雪霧、低照度、高度遮擋、傳感器部分失效、主動或被動場景攻擊等)的泛化感知能力,降低對標注數據和高清地圖的過度依賴;
2)預測與規劃聯合建模,離線與在線學習相結合,監督與自監督學習相結合,從而能夠處理不確定性下的安全行駛與有效決策,提供認知決策行為的可解釋問題,通過持續學習解決新場景問題。
當前,對應于ADS傳感器負載多樣化和融合感知決策算法多樣化的演進趨勢,ADS的算力需求和芯片加速能力以(十倍速/每幾年)的持續高增長態勢呈現。ADS領域大算力NPU芯片的當前發展現狀,真可謂是:大算力之時代,以感知策,四兩撥千斤者;狂洗牌乎戰局,唯快應變,一力降十會也。
?
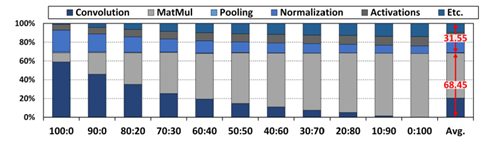
圖1. DNN任務占比分析: CNN vs Transformer
(圖表分析來自文獻1)
如圖1 所示,ADS算法從Compute-bound向Memory-bound演進。ADS的存算混合需求,可以通過“硬件預埋,算法迭代,算力均衡“ ,來提供一個向前兼容的解決方案,以通用大算力NPU設計來解決算法未來的不確定性,具體體現在:1) 底層架構的演進:從存算分離到近內存計算,最終走向內存計算; 2) 數據通道與模型:高速數據接口+數據壓縮+模型壓縮+低精度逼近計算+稀疏計算加速; 3) 并行的頂層架構:模型-硬件聯合設計,以及硬設計可配置+硬件調度+軟運行可編程調度引擎。
老子曾曰“合抱之木,生于毫末;九層之臺,起于壘土;千里之行,始于足下。” 老子又曰 ”天下難事,必作于易;天下大事,必作于細。”處理艱難問題從易入手,致力遠大目標從微著力。ADS-NPU芯片的架構設計,同樣需要用【見微知著】的能力,來解決異構計算、稀疏計算、逼近計算、內存計算等幾類常見的難題與挑戰。
1. 異構計算之設計挑戰
?
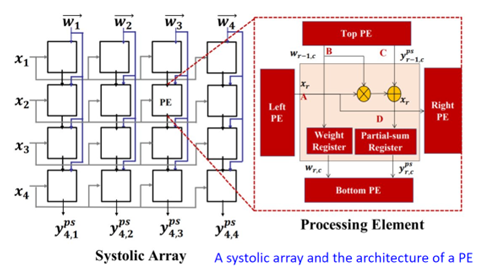
圖2. 脈動陣列架構(圖表分析來自文獻1)
?
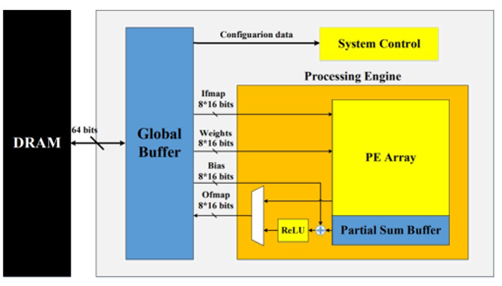
圖3. 可配置的脈動陣列架構(圖表分析來自文獻1)
對比CPU十百級的并行處理單元和GPU上萬級的并行處理單元,NPU會有百萬級的并行計算單元,可以采用Spatial加速器架構來實現,即Spatial PE空間單元陣列通過NoC,數據總線,或跨PE的互聯來實現矩陣乘運算(全卷積計算或全連接FC計算)、數據流高速交互、以及運算數據共享。
粗顆粒度的可配置架構CGRA是Spatial加速器的一種形態,即可配置的PE Array通過納秒或微秒級別可配置的Interconnect來對接,可以支持配置驅動或者數據流驅動運行。
如圖2和圖3所示,脈動Systolic加速器架構也是Spatial加速器的一類實現方式,其主要計算是通過1D或2D計算單元對數據流進行定向固定流動處理最終輸出累加計算結果,對DNN輸出對接卷積層或池化層的不同需求,可以動態調整硬件計算邏輯和數據通道,但存在的問題難以支撐壓縮模型的稀疏計算加速處理。
NPU的第二類計算單元是Vector矢量加速器架構,面向矢量的Element-wise Sum、Conv1x1卷積、Batch Normalization、激活函數處理等運算操作,其計算可以通過可配置的矢量核來實現,業界常用的設計是標量+矢量+陣列加速器的組合應用來應對ADS多類傳感器的不同前處理需求和多樣化算法模型流水線并行處理的存算混合需求。
NPU SoC也可以采用多核架構技術,即提供千百級的加速器物理核來組件封裝和Chiplet片上互聯提供更高程度的平行度,尤其是適合大算力下高并行數據負載,這需要底層硬件調度與上層軟件調度相結合,提供一個分布式硬件計算資源的細顆粒度運行態調用。
NPU另外一個在演進中的內存處理器PIM架構,即通過將計算靠近存儲的方式來降低數據搬移能耗和提升內存帶寬。可以分成近內存計算與內存計算兩種類型。近內存計算將計算引擎靠近傳統的DRAM或者SRAM cell,保持它們的設計特性。
內存計算需要對內存cell添加數據計算邏輯,多采用ReRAM或者STT-MRAM新型工藝,目前采用模擬或數字類型的設計,可實現》100TOPS/Watt的PPA性能,但技術難題是如何在運行態時進行大模型參數動態刷新,工藝實現可能也落后于市場預期。
?
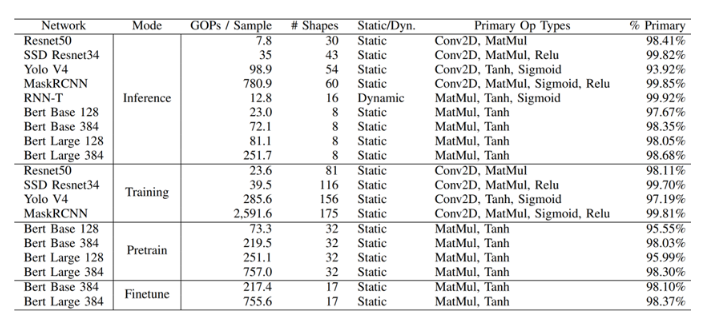
圖4. AI算法模型負載的算子分布統計(圖表分析來自文獻2)
?
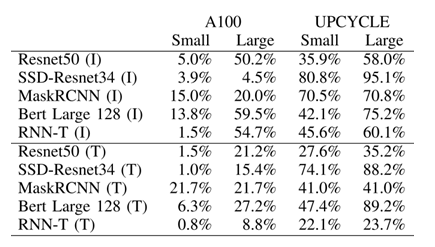
圖5. nVidia A100的TensorCore架構與UPCYCLE 融合架構的計算效率對比
(圖表分析來自文獻2)
當前市場上主流AI芯片,常用的架構有以下幾種形態:1) GEMM加速架構(TensorCore from nVidia, Matrix Core from AMD); 2) CGRA (初創公司); 3) Systolic Array (Google TPU); 4) Dataflow (Wave, Graphcore,初創公司); 4) Spatial Dataflow (Samba Nova, Groq); 5) Sparse架構 (Inferentia)。
如圖4與圖5所示案例可以看出,ADS-NPU設計其中有一個挑戰是低計算效率問題。異構計算架構一個主要的目的是希望從設計方法學上找到一個硬設計時優化可配置與軟運行時動態可編程的平衡點,從而能夠提供一個通用的方案覆蓋整個設計空間。
另外值得一提的是,UPCYCLE 的融合架構案例,涉及到SIMD/Short Vector, Matrix Multiply, Caching, Synchronization等多核優化策略,這個案例,說明只是通過短矢量處理+傳統的內存緩存+同步策略的傳統方法結合,在不使用標量+矢量+陣列的微架構組合條件下,依舊可以從頂層軟件架構層面的優化(指令集和工具鏈優化策略,模型-硬件聯合優化)來實現7.7x整體計算性能提升與23x功耗效率提升。
2. 稀疏計算之設計挑戰
ADS-NPU低效率計算問題,從微架構設計領域,可以涉及到:1) 稀疏數據(稀疏DNN網絡,或者稀疏輸入輸出數據)導致PE對大量零值數據的無效計算問題;2)PE之間由于軟件硬件調度算法的效率低,PE之間互相依賴導致的延遲問題;3)數據通道與計算通道峰值能力不匹配導致的數據等待問題。
上述問題2和問題3可以從頂層架構和存算微架構設計上來有效解決。問題1可以對稀疏數據進行壓縮處理來有效提升微架構計算單元PE的效率。如圖6和圖7所示,稀疏數據圖編碼的案例,可以有效提升數據存儲空間和對數據通道的沖擊,計算單元依據非零數據NZVL分布圖進行有效甄別計算,以添加簡單的邏輯單元為代價就可以將一個72PE的計算效率提升到95%,數據帶寬降低40%。
?
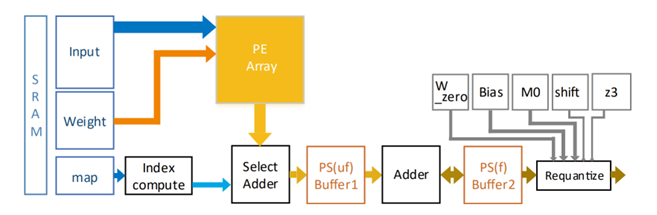
圖6. 稀疏計算微架構案例(圖表分析來自文獻3)
?
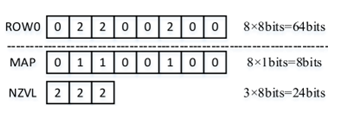
圖7. 稀疏數據圖編碼案例(圖表分析來自文獻3)
3. 逼近計算之設計挑戰
?
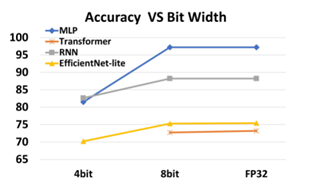
圖8. 算法模型與量化表征的關系案例(圖表分析來自文獻6)
算法模型與量化表征的關系案例如圖8所示,逼近計算設計可以通過算法模型的低比特參數表征+量化后訓練的方式,在不降低算法模型精度的情況下,通過時間和空間復用的方式,等效增加低比特MAC PE單元。
逼近計算的另外一個優勢是可以與稀疏計算相結合。低比特表征會增加數據的稀疏特性,類似ReLU等激活函數和池化計算也會產出大量零值數據。另外浮點數值如果用bit-slices進行表征,也會有大量高位零比特特征。
零值輸出數據意味著可以通過預計算可以直接跳過后續大量的卷積計算等。如圖9所示的案例,其中簡單的bit-slice數據分解表征會產生偏置分布,可以通過Signed Bit-Slice方法來解決,從而將PPA性能有效提升到(x4能耗,x5性能,x4面積)。
?
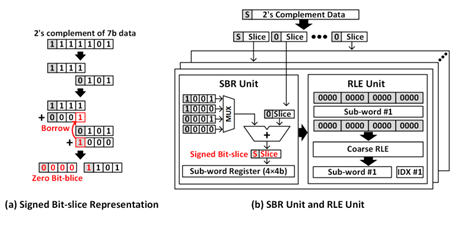
圖9. Signed Bit-Slice和RLE游程編碼案例 (圖表分析來自文獻4)
4. 內存計算之設計挑戰
ADS-NPU設計其中有一個挑戰是數據墻問題能耗墻問題,即計算單元PE存算分離設計導致數據重復搬移,數據共享困難,數據通道與計算通道峰值能力不匹配會導致PE的低效率和SRAM/DRAM高能耗。
?
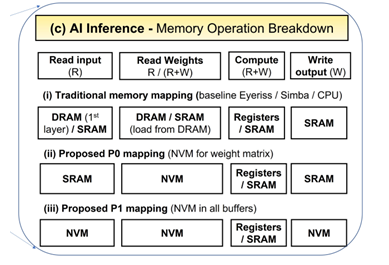
圖10. MRAM取代SRAM案例 (圖表分析來自文獻5)
一個有趣的嘗試是用新型工藝MRAM (STT/SOT/VGSOT-MRAM) 來部分或全部取代SRAM, P0方案是只取代算法模型參數緩存和全局參數緩存;P1方案是MRAM全面取代SRAM。對比SRAM-only架構,從圖10 的案例可以看出MRAM-P0解決方案可以有》30%能耗提升,MRAM-P1解決方案有》80%能耗提升,芯片面積減少》30%。
?
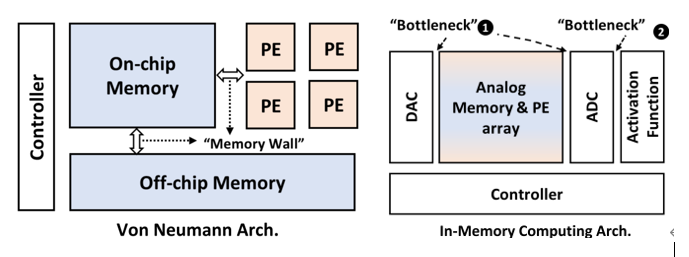
圖11. Von Neumann與內存計算的架構對比 (圖表分析來自文獻6)
?
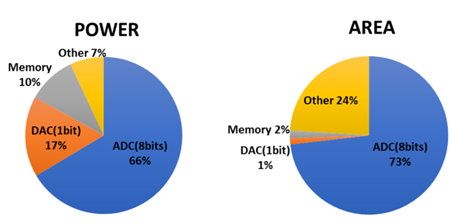
圖12. 內存計算的模擬墻問題 (圖表分析來自文獻6)
當前初創公司的內存計算架構策略需要對內存cell添加數據計算邏輯,通過采用ReRAM或者STT-MRAM新型工藝,采用模擬或數字類型的設計來實現。模擬內存計算IMC對打破傳統的Von Neumann計算機架構內存墻和能耗墻應該更有優勢,但需要同時打破設計中的模擬墻問題,這也是當前數字設計IMC-SRAM或者IMC-MRAM占多數的原因。
如圖11和圖12所示,IMC的主要問題來自于模數轉換ADC/DAC接口和激活函數的接口帶來的設計冗余。一種新的實驗設計是用基于RRAM的RFIMC微架構(RRAM cells + CLAMP circuits + JQNL-ADCs + DTACs)。每個RRAM cell代表2比特內存數據,4個RAM cell來存儲8比特的權重,JQNL-ADC采用8比特浮點數。
從圖13可以看出RFIMC的微架構能夠部分解決模擬墻的問題,可實現》100TOPS/Watt的PPA性能,但存在的問題是,只支持小規模的全矢量矩陣乘,超大尺寸的矩陣乘,需要將模擬數據進行局部搬移,是否有數據墻的問題仍未知。
?
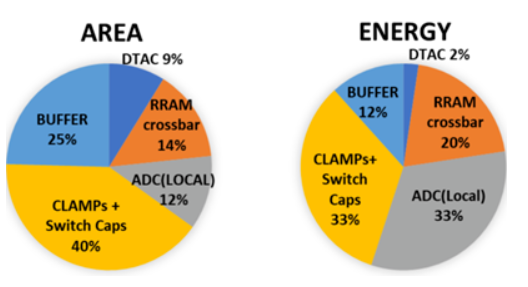
圖13. RFIMC的性能分解圖 (圖表分析來自文獻6)
5. 算法-硬件之共同設計挑戰
ADS算法多樣化的演進趨勢和對NPU大算力存算的混合需求,需要算法-NPU聯合設計來實現模型整體效率。
常用的量化與模型裁剪能夠解決一部分問題,模型-硬件聯合搜索,可以認為NPU預定義的硬件架構是模板,網絡模型ASIC-NAS是一個典型的案例,即在有限硬件計算空間內進行DNN的模型搜索和模型小型化,尋求計算單元的最佳組合模型來提升相同計算復雜度下的等效算力效率。
NPU添加了硬件的可配置和細顆粒可調度,但依舊存在很大的性能約束性。如圖14 和圖15所示,SkyNet算法與硬件共同設計的案例,是將NPU細顆粒度的PE單元進行Bundle優化封裝,其價值在于可以降低NAS架構搜索的高維空間,從而減低對硬件底層架構的依賴關系和優化算法的復雜度。
?
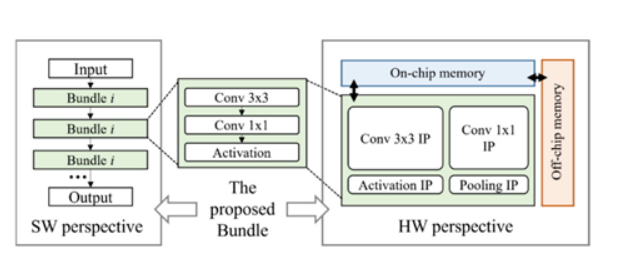
圖14. SkyNet算法與硬件共同設計案例 (圖表分析來自文獻7)
?
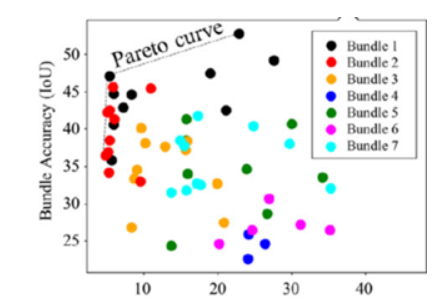
圖15. SkyNet-Bundle-NAS示例 (圖表分析來自文獻7)
作者 | Dr. L. Luo
參考文獻:
【1】J. Kim, and etc., “Exploration of Systolic-Vector Architecture with Resource Scheduling for Dynamic ML Workloads”,
https://arxiv.org/pdf/2206.03060.pdf【2】M Davies, and etc., “Understanding the limits of Conventional Hardware Architectures for Deep-Learning”, https://arxiv.org/pdf/2112.02204.pdf
【3】C. Wu, and etc., “Reconfigurable DL accelerator Hardware Architecture Design for Sparse CNN”,
https://ieeexplore.ieee.org/document/9602959
【4】D. Im, and etc., “Energy-efficient Dense DNN Acceleration with Signed Bit-slice Architecture”,
https://arxiv.org/pdf/2203.07679.pdf
【5】V Parmar, and etc., “Memory-Oriented Design-Space Exploration of Edge-AI Hardware for XR Applications”,
https://arxiv.org/pdf/2206.06780.pdf
【6】Z Xuan,and etc., “High-Efficiency Data Conversion Interface for Reconfigurable Function-in-MemoryComputing”,
https://ieeexplore.ieee.org/document/9795103
【7】X Zhang, and etc., “Algorithm/Accelerator Co-Design and Co-Search for Edge AI”,
https://ieeexplore.ieee.org/document/9785599













 工商網監
工商網監
評論