 電子發燒友App
電子發燒友App


眾所周知,內存是操作系統的一項重要資源,直接影響系統性能。而在應用蓬勃發展的今天,系統中運行的應用越來越多,這讓內存資源變得越來越緊張。在此背景下,方舟JS運行時在內存回收方面發力,推出了高性能內存回收技術——HPP GC(High Performance Partial Garbage Collection)。本文我們將從GC的基礎入手,由淺入深地為大家介紹HPP GC。
? ? ?一、什么是GC?
GC(全稱Garbage Collection),字面意思是垃圾回收。在計算機領域,GC就是找到內存中的垃圾,釋放和回收內存空間。目前主流編程語言實現的GC算法主要分為兩大類:引用計數和對象追蹤(即Tracing GC)。
1. 引用計數
我們通過一個示例來了解什么是引用計數:當一個對象A被另一個對象B指向時,A引用計數+1;反之當該指向斷開時,A引用計數-1。當A引用計數為0時,回收對象A。
? ?●?優點:
引用計數算法設計簡單,并且內存回收及時,在對象成為垃圾的第一時間就會被回收,所以沒有單獨的暫停業務代碼(Stop The World,STW)階段。
?●?缺點:
在對對象操作的過程中額外插入了計數環節,增加了內存分配和內存賦值的開銷,對程序性能必然會有影響。最致命的一點是存在循環引用問題。
- ?
- ?
- ?
- ?
- ?
- ?
function main() {var parent = {};var child = {};parent.child = child;child.parent = parent;}
(左右滑動,查看更多)
比如以上代碼中,對象parent被另一個對象child持有,對象parent引用計數加1,同時child也被parent持有,對象child引用計數也加1,這就是循環引用。一直到main函數結束后,對象parent和child依然無法釋放,導致內存泄漏。
2. 對象追蹤
為了方便大家理解對象追蹤算法,我們通過一個圖來進行介紹:如圖1所示,從根對象開始遍歷對象以及對象的域,所有可達的對象打上標記(黑色),即為活對象,剩下的不可達對象(白色)即為垃圾。
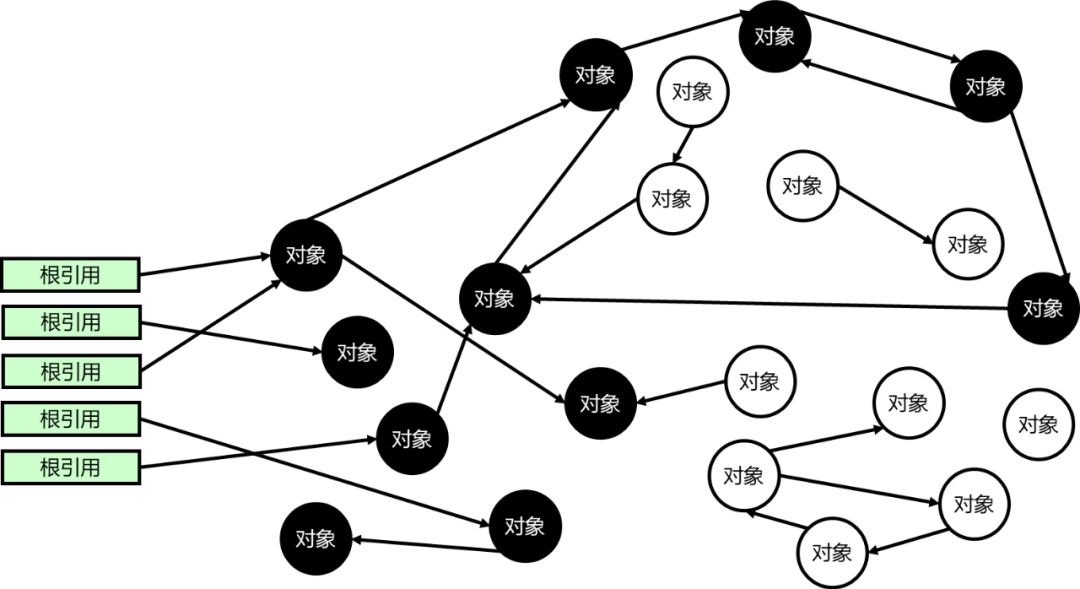
圖1 對象追蹤
? ? ?●?優點:
對象追蹤算法可以解決循環引用的問題,且對內存的分配和賦值沒有額外的開銷。
?●?缺點:
和引用計數算法相反,對象追蹤算法較為復雜,且有短暫的STW階段。此外,回收會有延遲,導致比較多的浮動垃圾。
引用計數和對象追蹤算法各有優劣,但考慮到引用計數存在循環引用的致命性能問題,方舟JS運行時選擇基于對象追蹤(即Tracing GC)算法來設計自己的GC算法。
? ? ?二、Tracing GC介紹
在介紹HPP GC之前,我們先來了解一下Tracing GC。從前面的介紹可知,Tracing GC算法通過遍歷對象圖標記出垃圾。而根據垃圾回收方式的不同,Tracing GC可以分為三種基本類型:標記-清掃回收、標記-復制回收、標記-整理回收。
1. 標記-清掃回收
此算法的回收方式是:完成對象圖遍歷后,將不可達對象內容擦除,并放入一個空閑隊列,用于下次對象的再分配。該種回收方式不需要搬移對象,所以回收效率非常高。但由于回收的對象內存地址不一定連續,所以該回收方式最大的缺點是會導致內存空間碎片化,降低內存分配效率,極端情況下甚至會出現還有大量內存的情況下分配不出一個比較大的對象的情況。

圖2 標記-清掃回收
(注:灰色塊表示可達對象的內存空間,白色塊表示不可達對象的內存空間。)
2. 標記-復制回收
此算法的回收方式是:在對象圖的遍歷過程中,將找到的可達對象直接復制到一個全新的內存空間中。遍歷完成后,一次將舊的內存空間全部回收。顯然,這種方式可以解決內存碎片的問題,且通過一次遍歷便完成整個GC過程,效率較高。但同時在極端情況下,這種回收方式需要預留一半的內存空間,以確保所有活的對象能被拷貝,空間利用率較低。
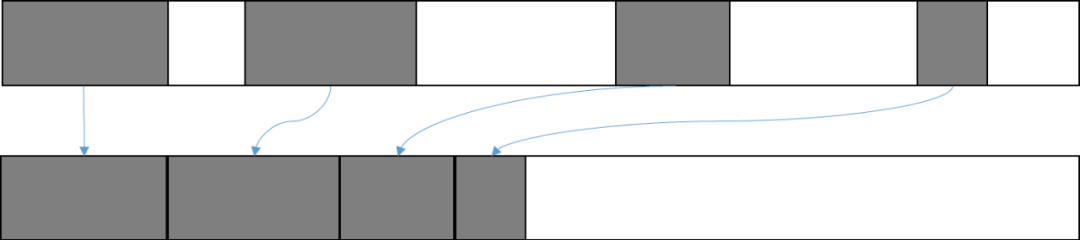
圖3 標記-復制回收
3. 標記-整理回收
此算法的回收方式是:完成對象圖遍歷后,將可達對象(紅色)往本區域(或指定區域)的頭部空閑位置復制,然后將已經完成復制的對象回收整理到空閑隊列中。這種回收方式既解決了“標記-清掃回收”引入的大量內存空間碎片的問題,又不需要像“標記-復制回收”那樣浪費一半的內存空間,但是性能上開銷比“標記-復制回收”稍大一些。
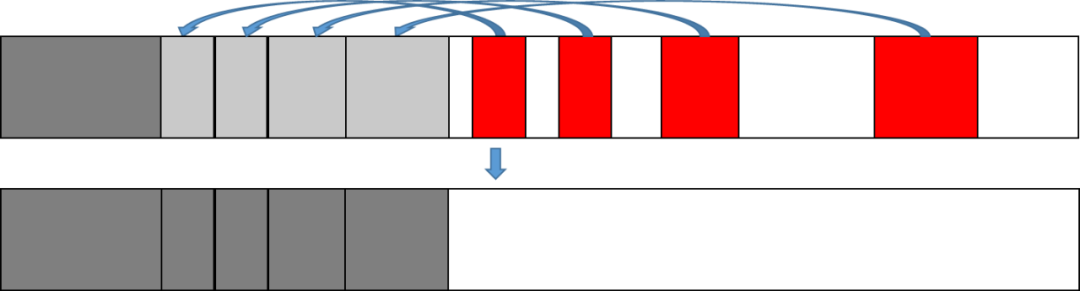
圖4 標記-整理回收
綜上所述,Tracing GC的三種基本類型各有優缺點,那么方舟JS運行時的HPP GC是基于哪種類型實現的呢?
HPP GC同時實現了這三種Tracing GC算法!沒想到吧?HPP GC綜合了這三種算法的優點,且支持根據不同對象區域、采取不同的回收方式。下面就為大家詳細解析HPP GC。
? ? ?三、HPP GC詳解
前面我們提到了,HPP GC支持根據不同對象區域,采取不同的回收方式。這是基于分代模型和混合算法來實現的。另外,為了實現HPP GC(High Performance Partial Garbage Collection)中的“High Performance”(高性能),HPP GC對GC流程做了大量優化。所以下面我們就從分代模型、混合算法和GC流程優化三個方面來為大家介紹HPP GC。
1. 分代模型
方舟JS運行時采用傳統的分代模型,將對象進行分類。考慮到大多數新分配的對象都會在一次GC之后被回收,而大多數經過多次GC之后依然存活的對象會繼續存活,方舟JS運行時將對象劃分為年輕代對象和老年代對象,并將對象分配到不同的空間。如圖5所示,方舟JS運行時將新分配的對象直接分配到年輕代(Young Generation)的From空間。經過一次GC后依然存活的對象,會進入To空間。而經過再次GC后依然存活的對象,會被復制到老年代(Old?Generation)。
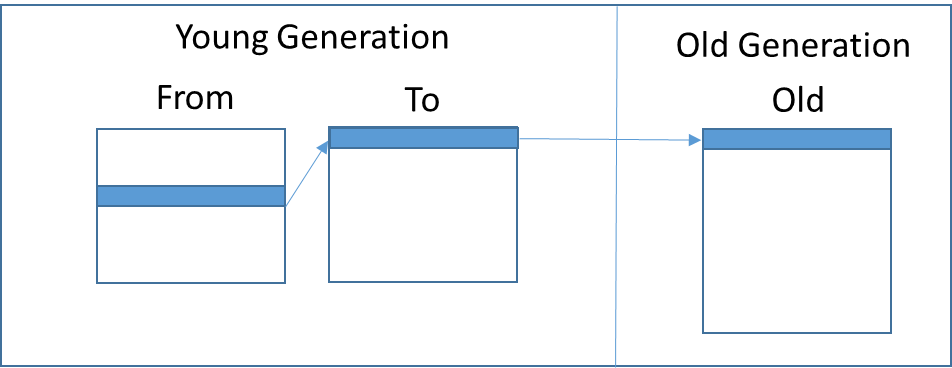
圖5 分代模型
2. 混合算法
通過前面的介紹,我們已經知道:HPP GC同時實現了“標記-清掃回收”、“標記-復制回收”和“標記-整理回收”這三種Tracing GC算法。也就是說,HPP GC是一種“部分復制+部分整理+部分清掃”的混合算法,支持根據年輕代對象和老年代對象的不同特點,分別采取不同的回收方式。(1) 部分復制
考慮到年輕代對象生命周期較短,回收較為頻繁,且年輕代對象大小有限的特點,方舟JS運行時對年輕代對象采用“標記-復制回收”算法。(2) 部分整理+部分清掃
方舟JS運行時根據老年代對象的特點,引入啟發式Collection Set(簡稱CSet)選擇算法。此選擇算法的基本原理是:在標記階段對每個區域的存活對象進行大小統計,然后在回收階段優先選出存活對象少、回收代價小的區域進行對象整理回收,再對剩下的區域進行清掃回收。具體的回收策略如下:
? ? ?(a) 根據設定的區域存活對象大小閾值,將滿足條件的區域納入初步的CSet隊列,并根據存活率進行從低到高的排序。
(注:存活率=存活對象大小/區域大小)
?(b) 根據設定的釋放區域個數閾值,選出最終的CSet隊列,進行整理回收。
?(c) 對未被選入CSet隊列的區域進行清掃回收。
由上可知,啟發式CSet選擇算法同時兼顧了 “標記-整理回收”和“標記-清掃回收”這兩種算法的優點,既避免了內存碎片問題,也兼顧了性能。
3. GC流程優化
在內存回收時,雖然釋放和回收了內存空間,讓系統有了更多可用的內存資源,但內存回收過程本身需要暫停應用業務代碼執行,影響用戶使用應用的體驗。回收內存時,如何盡可能的減小對應用性能的影響呢?為此,我們在HPP GC流程中引入了大量的并發和并行優化,以減少對應用性能的影響。如圖6所示,HPP GC流程中采用了并發+并行標記(Marking)、并發+并行清掃(Sweep)、并行復制/整理(Evacuation)、并行回改(Update)和并發清理(Clear)。
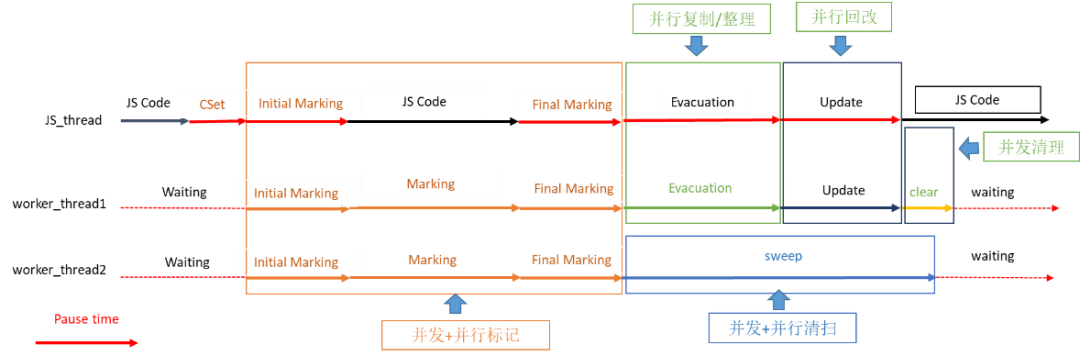
圖6 HPP GC流程
(1) 并發+并行標記
在JS線程執行業務代碼的同時,另外啟動線程執行標記,即為“并發標記”。如果另外啟動多個線程執行標記,即為“并發+并行標記”。 ?在并發+并行標記過程中,為確保標記的正確性和高性能,HPP GC采取了兩項優化措施:措施一:在新增引用關系時增加標記屏障(Marking Barrier),以確保標記結果的正確性。
并發標記過程中,JS線程有可能會更改對象之間的引用關系,從而導致對象標記結果出錯。如圖7所示,在marking線程完成對象1的標記、準備標記對象2的過程中,JS線程更改了對象3的引用關系。那么marking線程完成對象2的標記后,對象3不會被標記,回收器會判定對象3為垃圾,進行回收。此后,如果JS線程讀取對象1的字段,將會發生不可預知的錯誤。
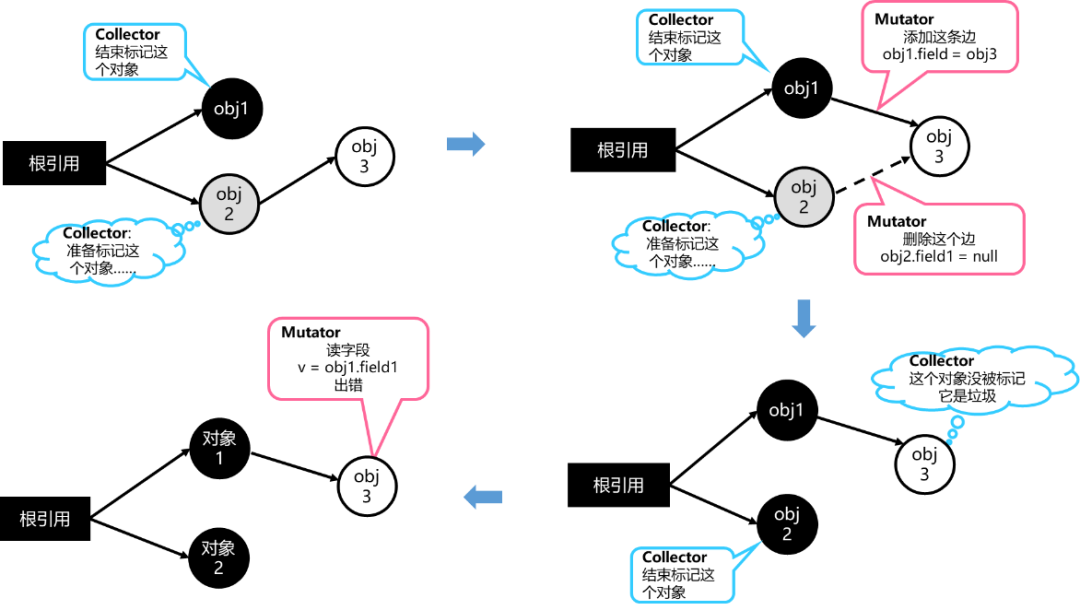
圖7 對象標記出錯
為確保標記結果的正確性,HPP GC在新增引用關系時增加標記屏障。如圖8所示,在marking線程完成對象1的標記、準備標記對象2的過程中,JS線程更改了對象3的引用關系。此時,JS線程會將對象3加入等待標記隊列,等marking線程完成對象2的標記后,繼續對象3的標記,從而確保對象3不會被回收。
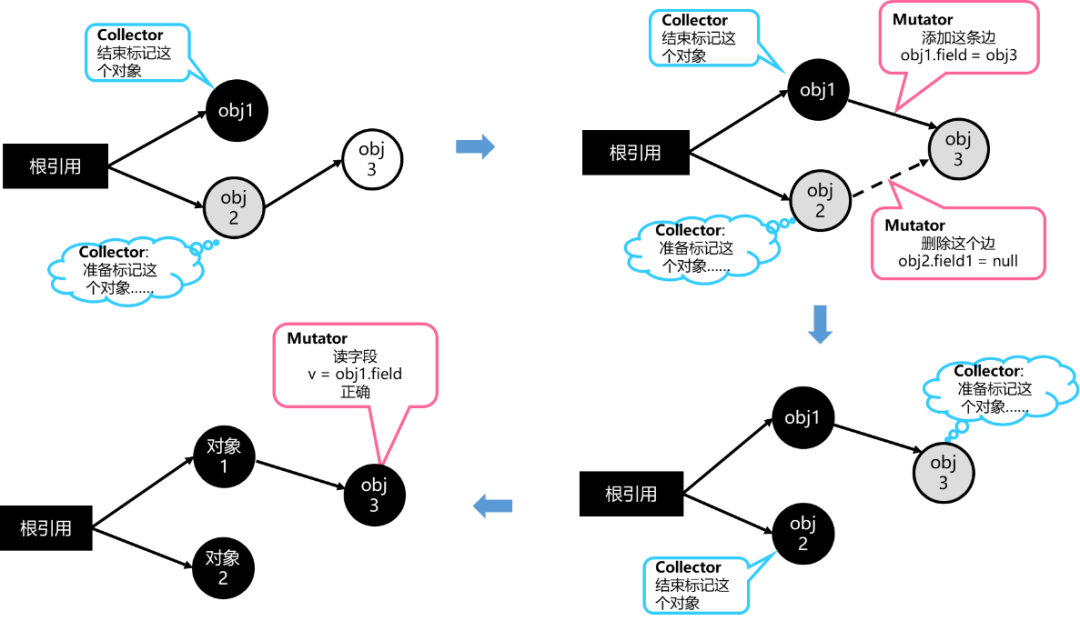
圖8 增加標記屏障
措施二:在共享全局工作隊列的基礎上,增加了本地工作隊列(Local Work List),以提高讀取對象的性能。
如圖9所示,并行標記時,每個Marking線程都要執行以下操作:從全局工作隊列(Global Work List)獲取一個對象,然后設置標記位,最后遍歷該對象的每個域,將子對象放入全局工作隊列中。考慮到線程之間讀取數據安全,必須在每個對象的Push/Pop操作時增加原子化或者鎖,這對對象的讀取性能有較大的影響。
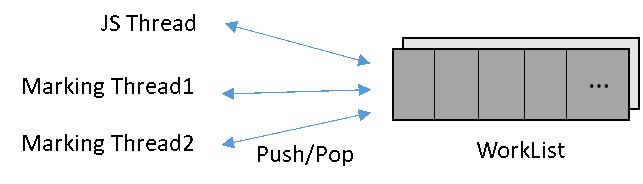
圖9 全局工作隊列
為提高讀取對象的性能,HPP GC增加了本地工作隊列。每個線程持有一個獨立的本地工作隊列,優先從本地工作隊列獲取/放入對象。當本地工作隊列滿時,將本地工作隊列的部分隊列一次發布到全局工作隊列中;當本地工作隊列空時,一次從全局工作隊列獲取若干對象到本地工作隊列。這樣,只有從全局工作隊列發布/獲取對象那一次需要增加原子化或者鎖,兼顧了多線程的并發效率和任務均衡,大大提高了并發標記的效率。
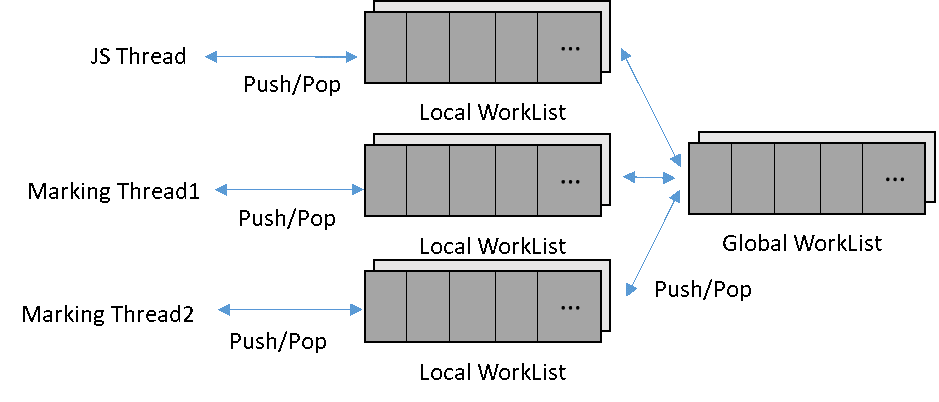
圖10 增加本地工作隊列
(2) 并發+并行清掃
在JS線程執行業務代碼的同時,另外啟動線程執行清掃,即為“并發清掃”。如果另外啟動多個線程執行清掃,即為“并發+并行清掃”。在并發+并行清掃過程中,HPP GC采取增加區域空閑隊列(Region Free List)的優化措施,用于提高多線程并發清掃的效率。
并發+并行清掃過程中,Sweeping線程發現不可達對象后,需要將對象放入全局的空閑隊列,同時JS線程執行的業務代碼可能需要從空閑隊列分配對象。為了確保數據安全,這個過程需要增加原子化或者鎖,但會影響到分配和清掃的效率。
為了提升效率,HPP GC增加區域空閑隊列。將所有需要清掃的內存按內存地址分成若干個區域,每個區域擁有獨立的空閑隊列,且每個區域同時只有一個線程進行清掃。在并發清掃過程中,Sweeping線程會首先將不可達對象放入本區域的空閑隊列。當JS線程需要從空閑隊列分配對象時,先獲取已經完成清掃的區域,再將這些區域的空閑隊列發布到全局空閑隊列中,用于對象分配,如圖11所示。由于發布的任務由JS線程單獨完成,所以整個并行清掃的過程都不需要加鎖,大大提高了并發+并行清掃的效率。
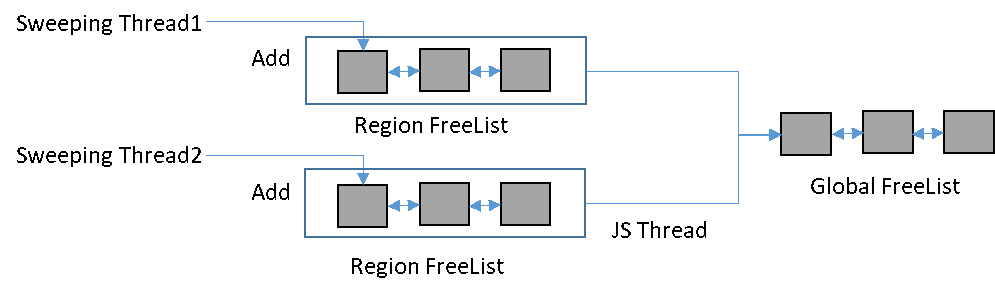
圖11 增加區域空閑隊列
(3) 并行復制/整理
在JS線程暫停業務代碼(STW)對可達對象進行復制/整理時,另外啟動多個線程一起進行復制/整理,即為“并行復制/整理”。和并發+并行清掃相似,并行復制/整理的瓶頸點在于多個線程同時從全局空閑隊列/全局線性分配器分配對象時,需要增加原子化或者鎖。為了提高多線程分配性能,在并行復制/整理過程中引入了TLAB Allocator。TLAB英文全稱為Thread Local Allocation Buffer。顧名思義,TLAB Allocator就是每個線程擁有一個獨立的本地分配器,該分配器會從全局內存分配器一次分配一塊較大的內存,然后在線程內部再分配。這樣只需從全局分配器分配時保證多線程安全,即可完成高性能且安全的并行復制/整理功能。(4)?并行回改
在GC完成標記和復制/整理后,需要將可達對象中指向舊對象地址的域改成新對象地址,這個過程就是“地址回改”,如圖12所示。為了提升地址回改的效率,HPP GC引入了“并行回改”,同時啟動多個線程進行地址回改,每個線程負責其中一塊內存區域對象地址的回改。
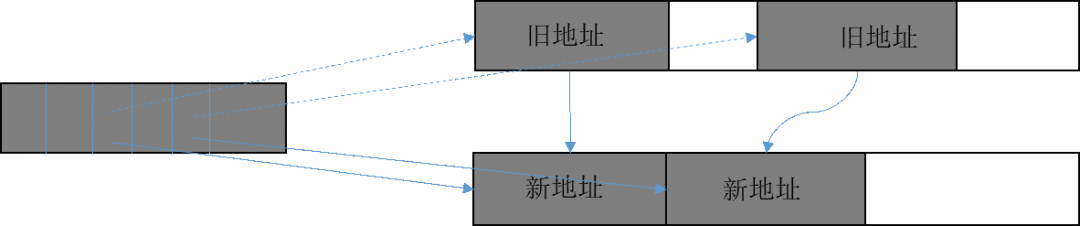
圖12 地址回改
(5)?并發清理
在GC復制/整理結束后,JS線程將不再讀寫遍歷出來的不可達對象和已經完成復制的可達對象,因此需要清理和回收對應的物理內存。為了減少STW時間,HPP GC引入“并發清理”,另外啟動一個工作線程進行并發的物理內存回收,這樣JS線程就可以繼續執行業務代碼。 ? ? ? ?四、結束語
本期就為大家介紹到這里了,最后我們總結一下: ? ?●??HPP GC基于分代模型將對象分為年輕代和老年代對象。
?●? HPP GC基于Tracing GC的三種基本類型,實現了“部分復制+部分整理+部分清掃”的混合算法,從而實現根據不同對象區域、采取不同的回收方式。
?●? HPP GC通過在GC流程中引入了大量的并發和并行優化,實現高性能。
HPP GC仍有很大的探索空間,我們還將繼續努力,為大家提供更高性能的內存回收能力!























 工商網監
工商網監
評論