 電子發燒友App
電子發燒友App


一、內存管理概覽
內存是計算機最重要的資源之一,內存管理是操作系統最重要的任務之一。內存管理并不是簡單地管理一下內存而已,它還直接影響著操作系統的風格以及用戶空間編程的模式。可以說內存管理的方式是一個系統刻入DNA的秉性。既然內存管理那么重要,那么今天我們就來全面系統地講一講Linux內存管理。
1.1 內存管理的意義
外存是程序存儲的地方,內存是進程運行的地方。外存相當于是軍營,內存相當于是戰場。選擇一個良好的戰場才有利于軍隊打勝仗,實現一個完善的內存管理機制才能讓進程多快好省地運行。如何更好地實現內存管理一直是操作系統發展的一大主題。在此過程中內存管理的基本模式也經歷了好幾代的發展,下面我們就來看一下。
1.2 原始內存管理
最初的時候,內存管理是十分的簡陋,大家都運行在物理內存上,內核和進程運行在一個空間中,內存分配算法有首次適應算法(FirstFit)、最佳適應算法(BestFit)、最差適應算法(WorstFit)等。顯然,這樣的內存管理方式問題是很明顯的。內核與進程之間沒有做隔離,進程可以隨意訪問(干擾、竊取)內核的數據。而且進程和內核沒有權限的區分,進程可以隨意做一些敏感操作。還有一個問題就是當時的物理內存非常少,能同時運行的進程比較少,運行進程的吞吐量比較少。
1.3 分段內存管理
于是第二代內存管理方式,分段內存管理誕生了。分段內存管理需要硬件的支持和軟件的配合。在分段內存中,軟件可以把物理內存分成一個一個的段,每個段都有段基址和段限長,還有段類型和段權限。段基址和段限長確定一個段的范圍,可以防止內存訪問越界。段與段之間也可以互相訪問,但是不能隨便訪問,有一定的規則限制。段類型分為代碼段和數據段,正好對應程序的代碼和數據,代碼段是只讀和可執行的,數據段有只讀數據段和讀寫數據段。代碼段是不可寫的,只讀數據段也是不可寫,數據段是不可執行的,這樣又增加了一層安全性。段權限分為有特權(內核權限)和無特權(用戶權限),內核的代碼段和數據段都設置為特權段,進程的代碼段和數據段都設置為用戶段,這樣進程就不能隨意訪問內核了。當CPU執行特權段代碼的時候會把自己設置為特權模式,此時CPU可以執行所以的指令。當CPU執行用戶段代碼的時候會把自己設置為用戶模式,此時CPU只能執行普通指令,不能執行敏感指令。
至此,分段內存管理完美解決了原始內存管理存在的大部分問題:進程與內核之間的隔離實現了,進程不能隨意訪問內核了;CPU特權級實現了,進程無法再執行敏感指令了;內存訪問的安全性提高了,越界訪問和野指針問題得到了一定程度的遏制。但是分段內存管理還有一個嚴重的問題沒有解決,那就是當時的物理內存非常少的問題。為此當時想的辦法是用軟件方法來解決,而且是進程自己解決。程序員在編寫程序的時候就要想好,把程序分成幾個模塊,關聯不大的模塊,它們占用相同的物理地址。然后再編寫一個overlay manager,在程序運行的時候,動態地加載即將會運行的模塊,覆蓋掉暫時不用的模塊。這樣一個程序占用較少的物理內存,也能順利地運行下去。顯然這樣的方法很麻煩,每個程序都要寫overlay manager也不太優雅。
1.4 分頁內存管理
于是第三代內存管理方式,虛擬內存管理(分頁內存管理)誕生了。虛擬內存管理也是需要硬件的支持和軟件的配合。在虛擬內存中,CPU訪問任何內存都是通過虛擬內存地址來訪問的,但是實際上最終訪問內存還是得用物理內存地址。所以在CPU中存在一個MMU,負責把虛擬地址轉化為物理地址,然后再去訪問內存。而MMU把虛擬地址轉化為物理的過程需要頁表的支持,頁表是由內核負責創建和維護的。一套頁表可以用來表達一個虛擬內存空間,不同的進程可以用不同的頁表集,頁表集是可以不停地切換的,哪個進程正在運行就切換到哪個進程的頁表集。于是一個進程就只能訪問自己的虛擬內存空間,而訪問不了別人的虛擬內存空間,這樣就實現了進程之間的隔離。一個虛擬內存空間又分為兩部分,內核空間和用戶空間,內核空間只有一個,用戶空間有N個,所有的虛擬內存空間都共享同一個內核空間。內核運行在內核空間,進程運行在用戶空間,內核空間有特權,用戶空間無特權,用戶空間不能隨意訪問內核空間。這樣進程和內核之間的隔離就形成了。內核空間的代碼運行的時候,CPU會把自己設置為特權模式,可以執行所有的指令。用戶空間運行的時候,CPU會把自己設置為用戶模式,只能執行普通指令,不能執行敏感指令。
至此,分段內存實現的功能,虛擬內存都做到了,下面就是虛擬內存如何解決物理內存不足的問題了。系統剛啟動的時候還是運行在物理內存上的,內核也被全部加載到了物理內存。然后內核建立頁表體系并開啟分頁機制,內核的物理內存和虛擬內存就建立映射了,整個系統就運行在虛擬內存上了。后面運行進程的時候就不是這樣了,內核會記錄進程的虛擬內存分配情況,但是并不會馬上分配物理內存建立頁表映射,而是讓進程先運行著。進程運行的時候,CPU都是通過MMU訪問虛擬內存地址的,MMU會用頁表去解析虛擬內存,如果找到了其對應的物理地址就直接訪問,如果頁表項是空的,就會觸發缺頁異常,在缺頁異常中會去分配物理內存并建立頁表映射。然后再重新執行剛才的那條指令,然后CPU還是通過MMU訪問內存,由于頁表建立好了,這下就可以訪問到物理內存了。當物理內存不足的時候,內核還會把一部分物理內存解除映射,把其內容存放到外存中,等其再次需要的時候再加載回來。這樣,一個進程運行的時候并不需要立馬加載其全部內容到物理內存,進程只需要少量的物理內存就能順利地運行,于是系統運行進程的吞吐量就大大提高了。
分頁內存管理不僅實現了分段內存管理的功能,還有額外的優點,于是分段內存管理就沒有存在的意義了。但是這里面還有一個歷史包袱問題。對于那些比較新的CPU,比如ARM、RISC-V,它們沒有歷史包袱,直接實現的就是分頁內存管理,根本不存在分段機制。但是對于x86就不一樣了,x86是從直接物理內存、分段內存、分頁內存一步一步走過來的,有著沉重的歷史包袱。在x86 32上,分段機制和分頁機制是并存的,系統可以選擇只使用分段機制或者兩種機制都使用。Linux的選擇是使用分頁機制,并在邏輯上屏蔽分段機制,因為分段機制是不能禁用的。邏輯上屏蔽分段機制的方法是,所有段的段基址都是0,段限長都是最大值,這樣就相當于是不分段了。分段機制無法禁用的原因是因為CPU特權級是在分段機制中實現的,分頁機制沒有單獨的CPU特權級機制。所以Linux創建了4個段,__KERNEL_CS、__KERNEL_DS用于內核空間,__USER_CS、__USER_DS用于用戶空間,它們在會空間切換時自動切換,這樣CPU特權級就跟著切換了。對于x86 64,從硬件上基本屏蔽了分段,因為硬件規定CS、DS、ES、SS這些段的段基址必須是0,段限長必須是最大值,軟件設置其它值也沒用。
因此我們在這里要強調一句,分段機制早就是歷史了,x86 64已經從硬件上屏蔽了分段機制,Linux早就從軟件上屏蔽了分段機制。X86 CPU的寄存器CS、DS、ES、FS和內核的__KERNEL_CS、__KERNEL_DS、__USER_CS、__USER_DS,已經不具有分段的意義了,它們的作用是為了實現CPU特權級的切換。
1.5 內存管理的目標
內存管理的目標除了前面所說的進程之間的隔離、進程與內核之間的隔離、減少物理內存并發使用的數量之外,還有以下幾個目標。
1.減少內存碎片,包括外部碎片和內部碎片。外部碎片是指還在內存分配器中的內存,但是由于比較分散,無法滿足用戶大塊連續內存分配的申請。內部碎片是指你申請了5個字節的內存,分配器給你分配了8個字節的內存,其中3個字節的內存是內部碎片。內存管理要盡量同時減少外部碎片和內部碎片。
2.內存分配接口要靈活多樣,同時滿足多種不同的內存分配需求。既要滿足大塊連續內存分配的需求,又能滿足小塊零碎內存分配的需求。
3.內存分配效率要高。內存分配要盡量快地完成,比如說你設計了一種算法,能完全解決內存碎片問題,但是內存算法實現得特別復雜,每次分配都需要1毫秒的時間,這就不可取了。
4.提高物理內存的利用率。比如及時回收物理內存、對內存進行壓縮。
1.6 Linux內存管理體系
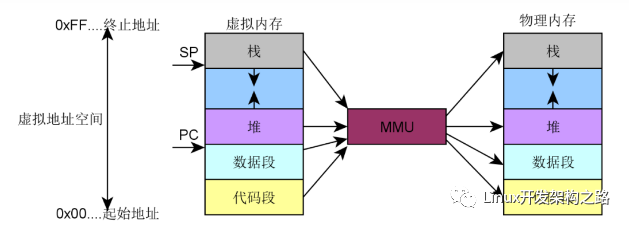
Linux內存管理的整體模式是虛擬內存管理(分頁內存管理),并在此基礎上建立了一個龐大的內存管理體系。我們先來看一下總體結構圖。
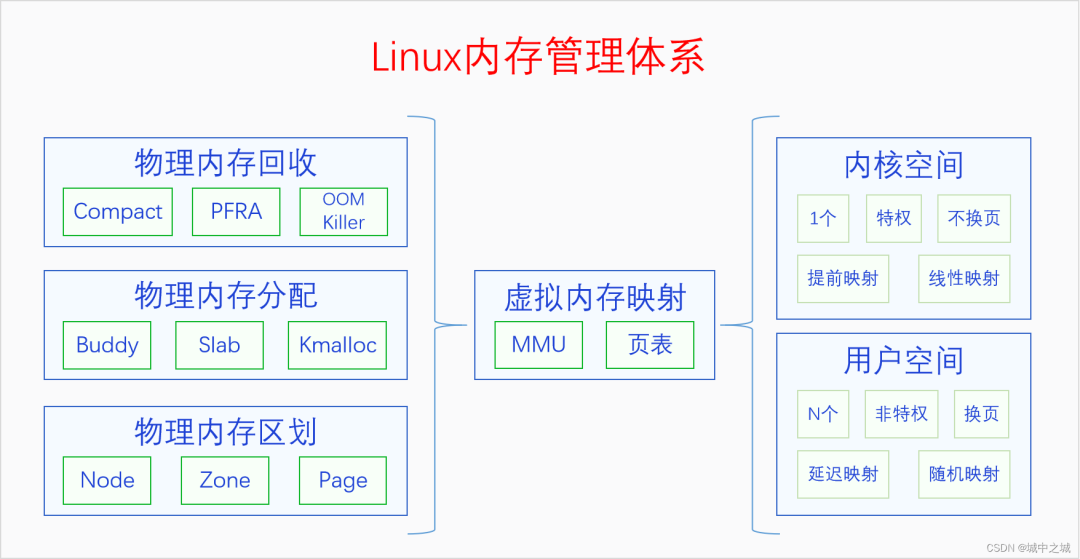
整個體系分為3部分,左邊是物理內存,右邊是虛擬內存,中間是虛擬內存映射(分頁機制)。我們先從物理內存說起,內存管理的基礎還是物理內存的管理。
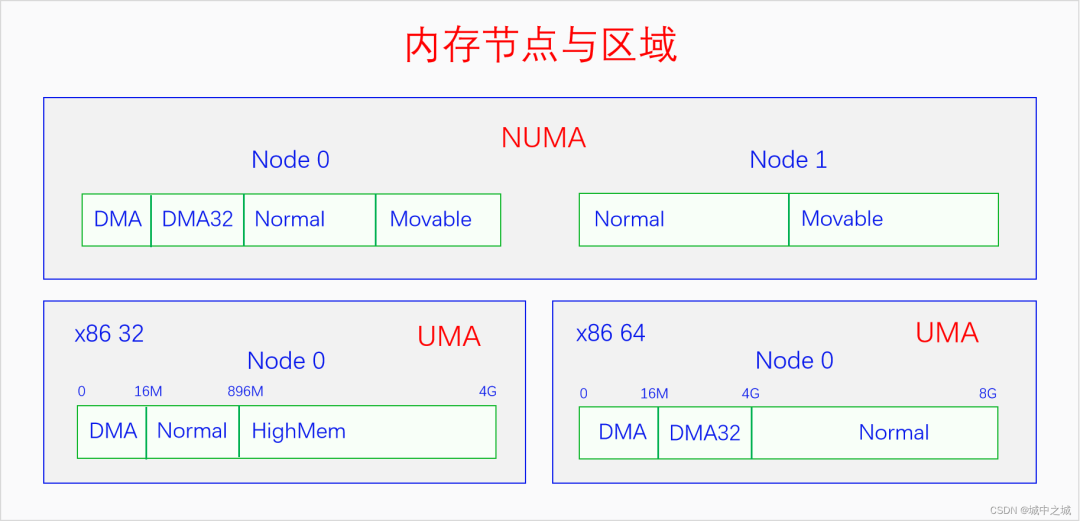
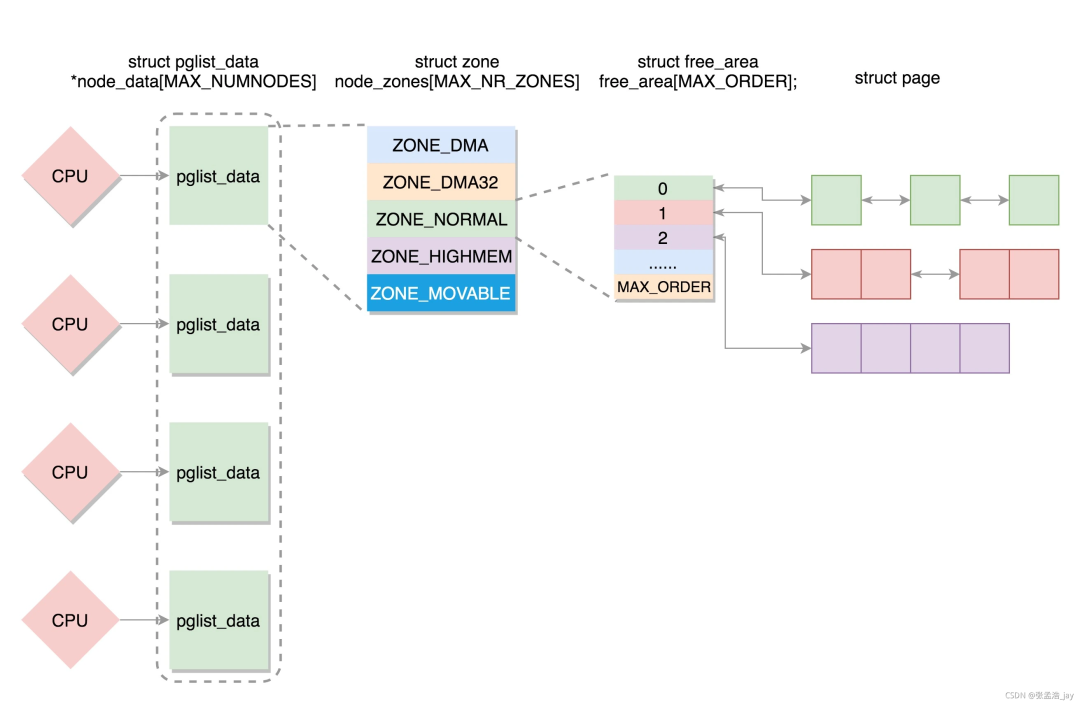
物理內存那么大,應該怎么管理呢?首先要對物理內存進行層級區劃,其原理可以類比于我國的行政區劃管理。我國幅員遼闊,國家直接管理個人肯定是不行的,我國采取的是省縣鄉三級管理體系。把整個國家按照一定的規則和歷史原因分成若干個省,每個省由省長管理。每個省再分成若干個縣,每個縣由縣長管理。每個縣再分成若干個鄉,每個鄉由鄉長管理,鄉長直接管理個人。(注意,類比是理解工具,不是論證工具)。對應的,物理內存也是采用類似的三級區域劃分的方式來管理的,三個層級分別叫做節點(node)、區域(zone)、頁面(page),對應到省、縣、鄉。系統首先把整個物理內存劃分為N個節點,內存節點只是叫節點,大家不能把它看成一個點,要把它看成是相當于一個省的大區域。每個節點都有一個節點描述符,相當于是省長。節點下面再劃分區域,每個區域都有區域描述符,相當于是縣長。區域下面再劃分頁面,每個頁面都有頁面描述符,相當于是鄉長。頁面再下面就是字節了,相當于是個人。
對物理內存建立三級區域劃分之后,就可以在其基礎之上建立分配體系了。物理內存的分配體系可以類比于一個公司的銷售體系,有工廠直接進行大額銷售,有批發公司進行大量批發,有小賣部進行日常零售。物理內存的三級分配體系分別是buddy system、slab allocator和kmalloc。buddy system相當于是工廠銷售,slab allocator相當于是批發公司,kmalloc相當于是小賣部,分別滿足人們不同規模的需求。
物理內存有分配也有釋放,但是當分配速度大于釋放速度的時候,物理內存就會逐漸變得不夠用了。此時我們就要進行內存回收了。內存回收首先考慮的是內存規整,也就是內存碎片整理,因為有可能我們不是可用內存不足了,而是內存太分散了,沒法分配連續的內存。內存規整之后如果還是分配不到內存的話,就會進行頁幀回收。內核的物理內存是不換頁的,所以內核只會進行緩存回收。用戶空間的物理內存是可以換頁的,所以會對用戶空間的物理內存進行換頁以便回收其物理內存。用戶空間的物理內存分為文件頁和匿名頁。對于文件頁,如果其是clean的,可以直接丟棄內容,回收其物理內存,如果其是dirty的,則會先把其內容寫回到文件,然后再回收內存。對于匿名頁,如果系統配置的有swap區的話,則會把其內容先寫入swap區,然后再回收,如果系統沒有swap區的話則不會進行回收。把進程占用的但是當前并不在使用的物理內存進行回收,并分配給新的進程來使用的過程就叫做換頁。進程被換頁的物理內存后面如果再被使用到的話,還會通過缺頁異常再換入內存。如果頁幀回收之后還沒有得到足夠的物理內存,內核將會使用最后一招,OOM Killer。OOM Killer會按照一定的規則選擇一個進程將其殺死,然后其物理內存就被釋放了。
內核還有三個內存壓縮技術zram、zswap、zcache,圖里并沒有畫出來。它們產生的原因并不相同,zram和zswap產生的原因是因為把匿名頁寫入swap區是IO操作,是非常耗時的,使用zram和zswap可以達到用空間換時間的效果。zcache產生的原因是因為內核一般都有大量的pagecache,pagecache是對文件的緩存,有些文件緩存暫時用不到,可以對它們進行壓縮,以節省內存空間,到用的時候再解壓縮,以達到用時間換空間的效果。
物理內存的這些操作都是在內核里進行的,但是CPU訪問內存用的并不是物理內存地址,而是虛擬內存地址。內核需要建立頁表把虛擬內存映射到物理內存上,然后CPU就可以通過MMU用虛擬地址來訪問物理內存了。虛擬內存地址空間分為兩部分,內核空間和用戶空間。內核空間只有一個,其頁表映射是在內核啟動的早期就建立的。用戶空間有N個,用戶空間是隨著進程的創建而建立的,但是其頁表映射并不是馬上建立,而是在程序的運行過程中通過缺頁異常逐步建立的。內核頁表建立好了之后就不會再取消了,所以內核是不換頁的,用戶頁表建立之后可能會因為內存回收而取消,所以用戶空間是換頁的。內核頁表是在內核啟動時建立的,所以內核空間的映射是線性映射,用戶空間的頁表是在運行時動態創建的,不可能做到線性映射,所以是隨機映射。
有些書上會說用戶空間是分頁的,內核是不分頁的,這是對英語paging的錯誤翻譯,paging在這里不是分頁的意思,而是換頁的意思。分頁是指整個分頁機制,換頁是內存回收中的操作,兩者的含義是完全不同的。
現在我們對Linux內存管理體系已經有了宏觀上的了解,下面我們就來對每個模塊進行具體地分析。
二、物理內存區劃
內核對物理內存進行了三級區劃。為什么要進行三級區劃,具體怎么劃分的呢?這個不是軟件隨意決定的,而是和硬件因素有關。下面我們來看一下每一層級劃分的原因,以及軟件上是如果描述的。
2.1 物理內存節點
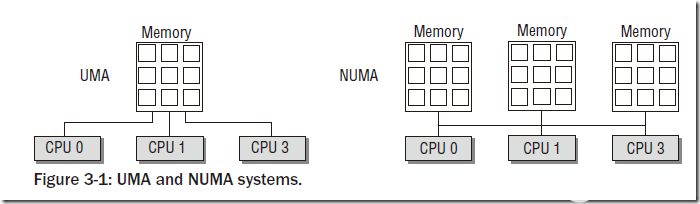
我國的省為什么要按照現在的這個形狀來劃分呢,主要是依據山川地形還有民俗風情等歷史原因。那么物理內存劃分為節點的原因是什么呢?這就要從UMA、NUMA說起了。我們用三個圖來看一下。
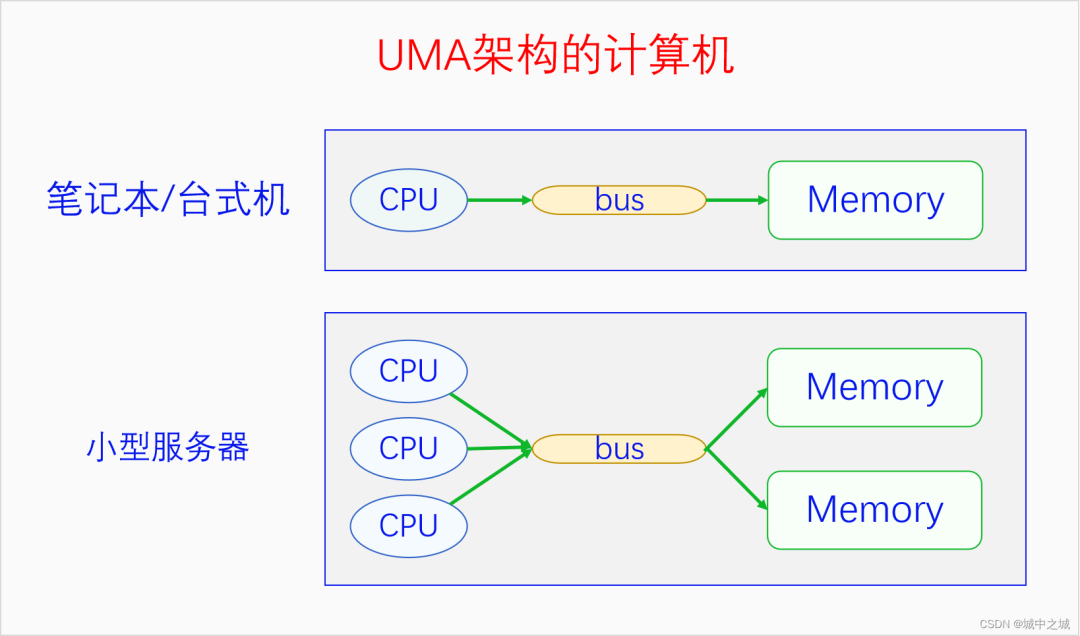
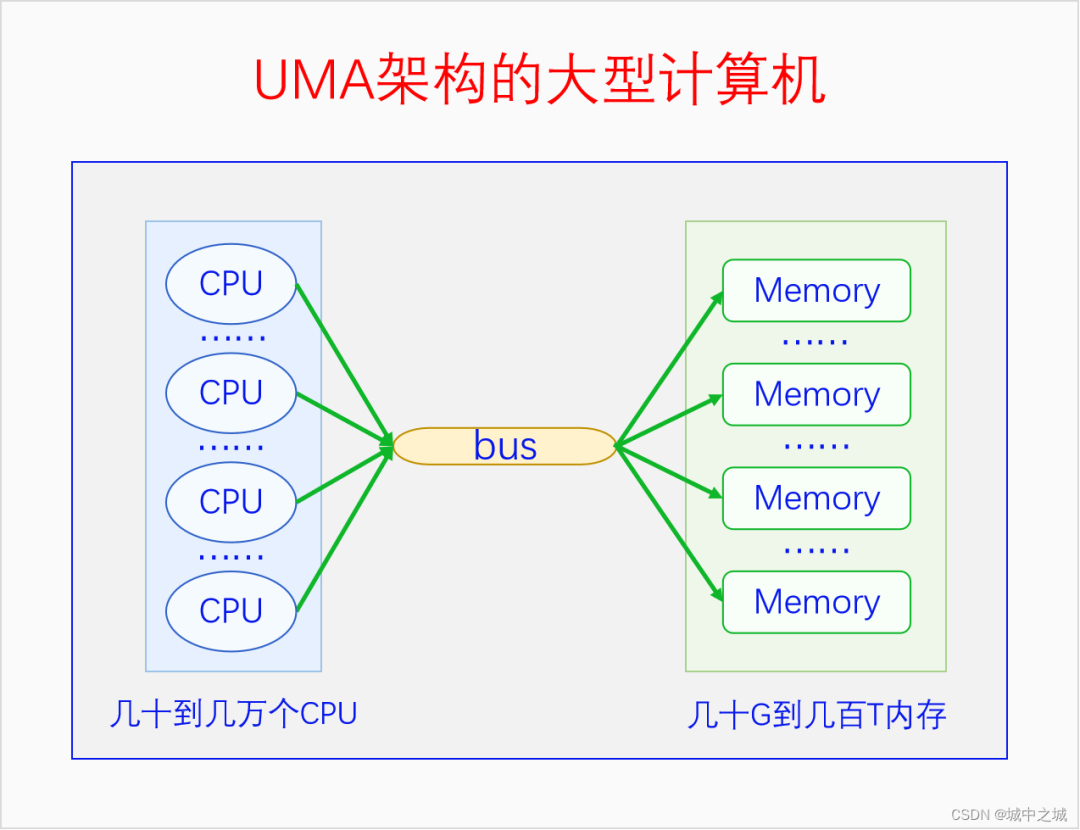
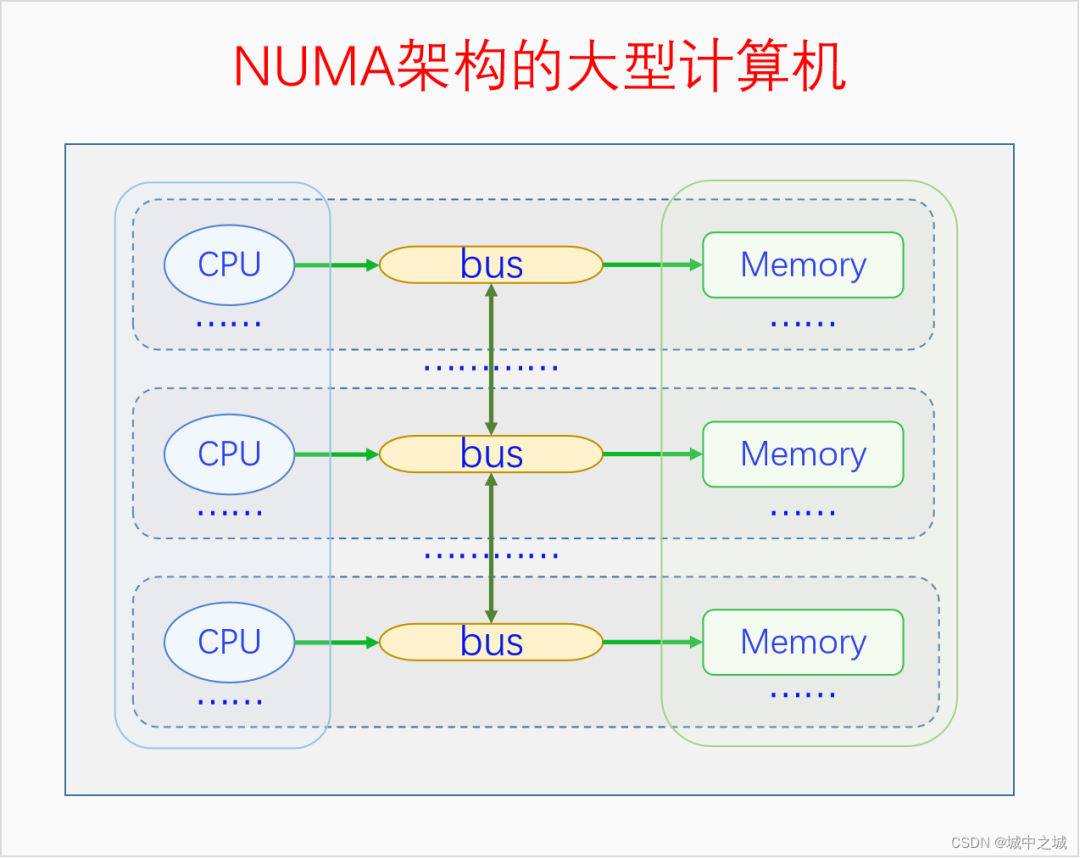
圖中的CPU都是物理CPU。當一個系統中的CPU越來越多、內存越來越多的時候,內存總線就會成為一個系統的瓶頸。如果大家都還擠在同一個總線上,速度必然很慢。于是我們可以采取一種方法,把一部分CPU和一部分內存直連在一起,構成一個節點,不同節點之間CPU訪問內存采用間接方式。節點內的內存訪問速度就會很快,節點之間的內存訪問速度雖然很慢,但是我們可以盡量減少節點之間的內存訪問,這樣系統總的內存訪問速度就會很快。
Linux中的代碼對UMA和NUMA是統一處理的,因為UMA可以看成是只有一個節點的NUMA。如果編譯內核時配置了CONFIG_NUMA,內核支持NUMA架構的計算機,內核中會定義節點指針數組來表示各個node。如果編譯內核時沒有配置CONFIG_NUMA,則內核只支持UMA架構的計算機,內核中會定義一個內存節點。這樣所有其它的代碼都可以統一處理了。
下面我們先來看一下節點描述符的定義。linux-src/include/linux/mmzone.h
typedef?struct?pglist_data?{
?/*
??*?node_zones?contains?just?the?zones?for?THIS?node.?Not?all?of?the
??*?zones?may?be?populated,?but?it?is?the?full?list.?It?is?referenced?by
??*?this?node's?node_zonelists?as?well?as?other?node's?node_zonelists.
??*/
?struct?zone?node_zones[MAX_NR_ZONES];
?/*
??*?node_zonelists?contains?references?to?all?zones?in?all?nodes.
??*?Generally?the?first?zones?will?be?references?to?this?node's
??*?node_zones.
??*/
?struct?zonelist?node_zonelists[MAX_ZONELISTS];
?int?nr_zones;?/*?number?of?populated?zones?in?this?node?*/
#ifdef?CONFIG_FLATMEM?/*?means?!SPARSEMEM?*/
?struct?page?*node_mem_map;
#ifdef?CONFIG_PAGE_EXTENSION
?struct?page_ext?*node_page_ext;
#endif
#endif
#if?defined(CONFIG_MEMORY_HOTPLUG)?||?defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
?/*
??*?Must?be?held?any?time?you?expect?node_start_pfn,
??*?node_present_pages,?node_spanned_pages?or?nr_zones?to?stay?constant.
??*?Also?synchronizes?pgdat->first_deferred_pfn?during?deferred?page
??*?init.
??*
??*?pgdat_resize_lock()?and?pgdat_resize_unlock()?are?provided?to
??*?manipulate?node_size_lock?without?checking?for?CONFIG_MEMORY_HOTPLUG
??*?or?CONFIG_DEFERRED_STRUCT_PAGE_INIT.
??*
??*?Nests?above?zone->lock?and?zone->span_seqlock
??*/
?spinlock_t?node_size_lock;
#endif
?unsigned?long?node_start_pfn;
?unsigned?long?node_present_pages;?/*?total?number?of?physical?pages?*/
?unsigned?long?node_spanned_pages;?/*?total?size?of?physical?page
??????????range,?including?holes?*/
?int?node_id;
?wait_queue_head_t?kswapd_wait;
?wait_queue_head_t?pfmemalloc_wait;
?struct?task_struct?*kswapd;?/*?Protected?by
????????mem_hotplug_begin/end()?*/
?int?kswapd_order;
?enum?zone_type?kswapd_highest_zoneidx;
?int?kswapd_failures;??/*?Number?of?'reclaimed?==?0'?runs?*/
#ifdef?CONFIG_COMPACTION
?int?kcompactd_max_order;
?enum?zone_type?kcompactd_highest_zoneidx;
?wait_queue_head_t?kcompactd_wait;
?struct?task_struct?*kcompactd;
?bool?proactive_compact_trigger;
#endif
?/*
??*?This?is?a?per-node?reserve?of?pages?that?are?not?available
??*?to?userspace?allocations.
??*/
?unsigned?long??totalreserve_pages;
#ifdef?CONFIG_NUMA
?/*
??*?node?reclaim?becomes?active?if?more?unmapped?pages?exist.
??*/
?unsigned?long??min_unmapped_pages;
?unsigned?long??min_slab_pages;
#endif?/*?CONFIG_NUMA?*/
?/*?Write-intensive?fields?used?by?page?reclaim?*/
?ZONE_PADDING(_pad1_)
#ifdef?CONFIG_DEFERRED_STRUCT_PAGE_INIT
?/*
??*?If?memory?initialisation?on?large?machines?is?deferred?then?this
??*?is?the?first?PFN?that?needs?to?be?initialised.
??*/
?unsigned?long?first_deferred_pfn;
#endif?/*?CONFIG_DEFERRED_STRUCT_PAGE_INIT?*/
#ifdef?CONFIG_TRANSPARENT_HUGEPAGE
?struct?deferred_split?deferred_split_queue;
#endif
?/*?Fields?commonly?accessed?by?the?page?reclaim?scanner?*/
?/*
??*?NOTE:?THIS?IS?UNUSED?IF?MEMCG?IS?ENABLED.
??*
??*?Use?mem_cgroup_lruvec()?to?look?up?lruvecs.
??*/
?struct?lruvec??__lruvec;
?unsigned?long??flags;
?ZONE_PADDING(_pad2_)
?/*?Per-node?vmstats?*/
?struct?per_cpu_nodestat?__percpu?*per_cpu_nodestats;
?atomic_long_t??vm_stat[NR_VM_NODE_STAT_ITEMS];
}?pg_data_t;
對于UMA,內核會定義唯一的一個節點。linux-src/mm/memblock.c
#ifndef?CONFIG_NUMA struct?pglist_data?__refdata?contig_page_data; EXPORT_SYMBOL(contig_page_data); #endif
查找內存節點的代碼如下:linux-src/include/linux/mmzone.h
extern?struct?pglist_data?contig_page_data; static?inline?struct?pglist_data?*NODE_DATA(int?nid) { ?return?&contig_page_data; }
對于NUMA,內核會定義內存節點指針數組,不同架構定義的不一定相同,我們以x86為例。linux-src/arch/x86/mm/numa.c
struct?pglist_data?*node_data[MAX_NUMNODES]?__read_mostly; EXPORT_SYMBOL(node_data);
查找內存節點的代碼如下:linux-src/arch/x86/include/asm/mmzone_64.h
extern?struct?pglist_data?*node_data[]; #define?NODE_DATA(nid)??(node_data[nid])
可以看出對于UMA,Linux是統一定義一個內存節點的,對于NUMA,Linux是在各架構代碼下定義內存節點的。由于我們常見的電腦手機都是UMA的,后面的我們都以UMA為例進行講解。pglist_data各自字段的含義我們在用到時再進行分析。
2.2 物理內存區域
內存節點下面再劃分為不同的區域。劃分區域的原因是什么呢?主要是因為各種軟硬件的限制導致的。目前Linux中最多可以有6個區域,這些區域并不是每個都必然存在,有的是由config控制的。有些區域就算代碼中配置了,但是在系統運行的時候也可能為空。下面我們依次介紹一下這6個區域。
ZONE_DMA:由配置項CONFIG_ZONE_DMA決定是否存在。在x86上DMA內存區域是物理內存的前16M,這是因為早期的ISA總線上的DMA控制器只有24根地址總線,只能訪問16M物理內存。為了兼容這些老的設備,所以需要專門開辟前16M物理內存作為一個區域供這些設備進行DMA操作時去分配物理內存。
ZONE_DMA32:由配置項CONFIG_ZONE_DMA32決定是否存在。后來的DMA控制器有32根地址總線,可以訪問4G物理內存了。但是在32位的系統上最多只支持4G物理內存,所以沒必要專門劃分一個區域。但是到了64位系統時候,很多CPU能支持48位到52位的物理內存,于是此時就有必要專門開個區域給32位的DMA控制器使用了。
ZONE_NORMAL:常規內存,無配置項控制,必然存在,除了其它幾個內存區域之外的內存都是常規內存ZONE_NORMAL。
ZONE_HIGHMEM:高端內存,由配置項CONFIG_HIGHMEM決定是否存在。只在32位系統上有,這是因為32位系統的內核空間只有1G,這1G虛擬空間中還有128M用于其它用途,所以只有896M虛擬內存空間用于直接映射物理內存,而32位系統支持的物理內存有4G,大于896M的物理內存是無法直接映射到內核空間的,所以把它們劃為高端內存進行特殊處理。對于64位系統,從理論上來說,內核空間最大263-1,物理內存最大264,好像內核空間還是不夠用。但是從現實來說,內核空間的一般配置為247,高達128T,物理內存暫時還遠遠沒有這么多。所以從現實的角度來說,64位系統是不需要高端內存區域的。
ZONE_MOVABLE:可移動內存,無配置項控制,必然存在,用于可熱插拔的內存。內核啟動參數movablecore用于指定此區域的大小。內核參數kernelcore也可用于指定非可移動內存的大小,剩余的內存都是可移動內存。如果兩者同時指定的話,則會優先保證非可移動內存的大小至少有kernelcore這么大。如果兩者都沒指定,則可移動內存大小為0。
ZONE_DEVICE:設備內存,由配置項CONFIG_ZONE_DEVICE決定是否存在,用于放置持久內存(也就是掉電后內容不會消失的內存)。一般的計算機中沒有這種內存,默認的內存分配也不會從這里分配內存。持久內存可用于內核崩潰時保存相關的調試信息。
下面我們先來看一下這幾個內存區域的類型定義。linux-src/include/linux/mmzone.h
enum?zone_type?{
#ifdef?CONFIG_ZONE_DMA
?ZONE_DMA,
#endif
#ifdef?CONFIG_ZONE_DMA32
?ZONE_DMA32,
#endif
?ZONE_NORMAL,
#ifdef?CONFIG_HIGHMEM
?ZONE_HIGHMEM,
#endif
?ZONE_MOVABLE,
#ifdef?CONFIG_ZONE_DEVICE
?ZONE_DEVICE,
#endif
?__MAX_NR_ZONES
};
我們再來看一下區域描述符的定義。linux-src/include/linux/mmzone.h
struct?zone?{
?/*?Read-mostly?fields?*/
?/*?zone?watermarks,?access?with?*_wmark_pages(zone)?macros?*/
?unsigned?long?_watermark[NR_WMARK];
?unsigned?long?watermark_boost;
?unsigned?long?nr_reserved_highatomic;
?/*
??*?We?don't?know?if?the?memory?that?we're?going?to?allocate?will?be
??*?freeable?or/and?it?will?be?released?eventually,?so?to?avoid?totally
??*?wasting?several?GB?of?ram?we?must?reserve?some?of?the?lower?zone
??*?memory?(otherwise?we?risk?to?run?OOM?on?the?lower?zones?despite
??*?there?being?tons?of?freeable?ram?on?the?higher?zones).??This?array?is
??*?recalculated?at?runtime?if?the?sysctl_lowmem_reserve_ratio?sysctl
??*?changes.
??*/
?long?lowmem_reserve[MAX_NR_ZONES];
#ifdef?CONFIG_NUMA
?int?node;
#endif
?struct?pglist_data?*zone_pgdat;
?struct?per_cpu_pages?__percpu?*per_cpu_pageset;
?struct?per_cpu_zonestat?__percpu?*per_cpu_zonestats;
?/*
??*?the?high?and?batch?values?are?copied?to?individual?pagesets?for
??*?faster?access
??*/
?int?pageset_high;
?int?pageset_batch;
#ifndef?CONFIG_SPARSEMEM
?/*
??*?Flags?for?a?pageblock_nr_pages?block.?See?pageblock-flags.h.
??*?In?SPARSEMEM,?this?map?is?stored?in?struct?mem_section
??*/
?unsigned?long??*pageblock_flags;
#endif?/*?CONFIG_SPARSEMEM?*/
?/*?zone_start_pfn?==?zone_start_paddr?>>?PAGE_SHIFT?*/
?unsigned?long??zone_start_pfn;
?atomic_long_t??managed_pages;
?unsigned?long??spanned_pages;
?unsigned?long??present_pages;
#if?defined(CONFIG_MEMORY_HOTPLUG)
?unsigned?long??present_early_pages;
#endif
#ifdef?CONFIG_CMA
?unsigned?long??cma_pages;
#endif
?const?char??*name;
#ifdef?CONFIG_MEMORY_ISOLATION
?/*
??*?Number?of?isolated?pageblock.?It?is?used?to?solve?incorrect
??*?freepage?counting?problem?due?to?racy?retrieving?migratetype
??*?of?pageblock.?Protected?by?zone->lock.
??*/
?unsigned?long??nr_isolate_pageblock;
#endif
#ifdef?CONFIG_MEMORY_HOTPLUG
?/*?see?spanned/present_pages?for?more?description?*/
?seqlock_t??span_seqlock;
#endif
?int?initialized;
?/*?Write-intensive?fields?used?from?the?page?allocator?*/
?ZONE_PADDING(_pad1_)
?/*?free?areas?of?different?sizes?*/
?struct?free_area?free_area[MAX_ORDER];
?/*?zone?flags,?see?below?*/
?unsigned?long??flags;
?/*?Primarily?protects?free_area?*/
?spinlock_t??lock;
?/*?Write-intensive?fields?used?by?compaction?and?vmstats.?*/
?ZONE_PADDING(_pad2_)
?/*
??*?When?free?pages?are?below?this?point,?additional?steps?are?taken
??*?when?reading?the?number?of?free?pages?to?avoid?per-cpu?counter
??*?drift?allowing?watermarks?to?be?breached
??*/
?unsigned?long?percpu_drift_mark;
#if?defined?CONFIG_COMPACTION?||?defined?CONFIG_CMA
?/*?pfn?where?compaction?free?scanner?should?start?*/
?unsigned?long??compact_cached_free_pfn;
?/*?pfn?where?compaction?migration?scanner?should?start?*/
?unsigned?long??compact_cached_migrate_pfn[ASYNC_AND_SYNC];
?unsigned?long??compact_init_migrate_pfn;
?unsigned?long??compact_init_free_pfn;
#endif
#ifdef?CONFIG_COMPACTION
?/*
??*?On?compaction?failure,?1<
Zone結構體中各個字段的含義我們在用到的時候再進行解釋。
2.3 物理內存頁面
每個內存區域下面再劃分為若干個面積比較小但是又不太小的頁面。頁面的大小一般都是4K,這是由硬件規定的。內存節點和內存區域從邏輯上來說并不是非得有,只不過是由于各種硬件限制或者特殊需求才有的。內存頁面倒不是因為硬件限制才有的,主要是出于邏輯原因才有的。頁面是分頁內存機制和底層內存分配的最小單元。如果沒有頁面的話,直接以字節為單位進行管理顯然太麻煩了,所以需要有一個較小的基本單位,這個單位就叫做頁面。頁面的大小選多少合適呢?太大了不好,太小了也不好,這個數值還得是2的整數次冪,所以4K就非常合適。為啥是2的整數次冪呢?因為計算機是用二進制實現的,2的整數次冪做各種運算和特殊處理比較方便,后面用到的時候就能體會到。為啥是4K呢?因為最早Intel選擇的就是4K,后面大部分CPU也都跟著選4K作為頁面的大小了。
物理內存頁面也叫做頁幀。物理內存從開始起每4K、4K的,構成一個個頁幀,這些頁幀的編號依次是0、1、2、3......。頁幀的編號也叫做pfn(page frame number)。很顯然,一個頁幀的物理地址和它的pfn有一個簡單的數學關系,那就是其物理地址除以4K就是其pfn,其pfn乘以4K就是其物理地址。由于4K是2的整數次冪,所以這個乘除運算可以轉化為移位運算。下面我們看一下相關的宏操作。
linux-src/include/linux/pfn.h
#define?PFN_ALIGN(x)?(((unsigned?long)(x)?+?(PAGE_SIZE?-?1))?&?PAGE_MASK)
#define?PFN_UP(x)?(((x)?+?PAGE_SIZE-1)?>>?PAGE_SHIFT)
#define?PFN_DOWN(x)?((x)?>>?PAGE_SHIFT)
#define?PFN_PHYS(x)?((phys_addr_t)(x)?<>?PAGE_SHIFT))
PAGE_SHIFT的值在大部分平臺上都是等于12,2的12次方冪正好就是4K。
下面我們來看一下頁面描述符的定義。linux-src/include/linux/mm_types.h
struct?page?{
?unsigned?long?flags;??/*?Atomic?flags,?some?possibly
??????*?updated?asynchronously?*/
?/*
??*?Five?words?(20/40?bytes)?are?available?in?this?union.
??*?WARNING:?bit?0?of?the?first?word?is?used?for?PageTail().?That
??*?means?the?other?users?of?this?union?MUST?NOT?use?the?bit?to
??*?avoid?collision?and?false-positive?PageTail().
??*/
?union?{
??struct?{?/*?Page?cache?and?anonymous?pages?*/
???/**
????*?@lru:?Pageout?list,?eg.?active_list?protected?by
????*?lruvec->lru_lock.??Sometimes?used?as?a?generic?list
????*?by?the?page?owner.
????*/
???struct?list_head?lru;
???/*?See?page-flags.h?for?PAGE_MAPPING_FLAGS?*/
???struct?address_space?*mapping;
???pgoff_t?index;??/*?Our?offset?within?mapping.?*/
???/**
????*?@private:?Mapping-private?opaque?data.
????*?Usually?used?for?buffer_heads?if?PagePrivate.
????*?Used?for?swp_entry_t?if?PageSwapCache.
????*?Indicates?order?in?the?buddy?system?if?PageBuddy.
????*/
???unsigned?long?private;
??};
??struct?{?/*?page_pool?used?by?netstack?*/
???/**
????*?@pp_magic:?magic?value?to?avoid?recycling?non
????*?page_pool?allocated?pages.
????*/
???unsigned?long?pp_magic;
???struct?page_pool?*pp;
???unsigned?long?_pp_mapping_pad;
???unsigned?long?dma_addr;
???union?{
????/**
?????*?dma_addr_upper:?might?require?a?64-bit
?????*?value?on?32-bit?architectures.
?????*/
????unsigned?long?dma_addr_upper;
????/**
?????*?For?frag?page?support,?not?supported?in
?????*?32-bit?architectures?with?64-bit?DMA.
?????*/
????atomic_long_t?pp_frag_count;
???};
??};
??struct?{?/*?slab,?slob?and?slub?*/
???union?{
????struct?list_head?slab_list;
????struct?{?/*?Partial?pages?*/
?????struct?page?*next;
#ifdef?CONFIG_64BIT
?????int?pages;?/*?Nr?of?pages?left?*/
?????int?pobjects;?/*?Approximate?count?*/
#else
?????short?int?pages;
?????short?int?pobjects;
#endif
????};
???};
???struct?kmem_cache?*slab_cache;?/*?not?slob?*/
???/*?Double-word?boundary?*/
???void?*freelist;??/*?first?free?object?*/
???union?{
????void?*s_mem;?/*?slab:?first?object?*/
????unsigned?long?counters;??/*?SLUB?*/
????struct?{???/*?SLUB?*/
?????unsigned?inuse:16;
?????unsigned?objects:15;
?????unsigned?frozen:1;
????};
???};
??};
??struct?{?/*?Tail?pages?of?compound?page?*/
???unsigned?long?compound_head;?/*?Bit?zero?is?set?*/
???/*?First?tail?page?only?*/
???unsigned?char?compound_dtor;
???unsigned?char?compound_order;
???atomic_t?compound_mapcount;
???unsigned?int?compound_nr;?/*?1?<ptl?*/
???unsigned?long?_pt_pad_2;?/*?mapping?*/
???union?{
????struct?mm_struct?*pt_mm;?/*?x86?pgds?only?*/
????atomic_t?pt_frag_refcount;?/*?powerpc?*/
???};
#if?ALLOC_SPLIT_PTLOCKS
???spinlock_t?*ptl;
#else
???spinlock_t?ptl;
#endif
??};
??struct?{?/*?ZONE_DEVICE?pages?*/
???/**?@pgmap:?Points?to?the?hosting?device?page?map.?*/
???struct?dev_pagemap?*pgmap;
???void?*zone_device_data;
???/*
????*?ZONE_DEVICE?private?pages?are?counted?as?being
????*?mapped?so?the?next?3?words?hold?the?mapping,?index,
????*?and?private?fields?from?the?source?anonymous?or
????*?page?cache?page?while?the?page?is?migrated?to?device
????*?private?memory.
????*?ZONE_DEVICE?MEMORY_DEVICE_FS_DAX?pages?also
????*?use?the?mapping,?index,?and?private?fields?when
????*?pmem?backed?DAX?files?are?mapped.
????*/
??};
??/**?@rcu_head:?You?can?use?this?to?free?a?page?by?RCU.?*/
??struct?rcu_head?rcu_head;
?};
?union?{??/*?This?union?is?4?bytes?in?size.?*/
??/*
???*?If?the?page?can?be?mapped?to?userspace,?encodes?the?number
???*?of?times?this?page?is?referenced?by?a?page?table.
???*/
??atomic_t?_mapcount;
??/*
???*?If?the?page?is?neither?PageSlab?nor?mappable?to?userspace,
???*?the?value?stored?here?may?help?determine?what?this?page
???*?is?used?for.??See?page-flags.h?for?a?list?of?page?types
???*?which?are?currently?stored?here.
???*/
??unsigned?int?page_type;
??unsigned?int?active;??/*?SLAB?*/
??int?units;???/*?SLOB?*/
?};
?/*?Usage?count.?*DO?NOT?USE?DIRECTLY*.?See?page_ref.h?*/
?atomic_t?_refcount;
#ifdef?CONFIG_MEMCG
?unsigned?long?memcg_data;
#endif
?/*
??*?On?machines?where?all?RAM?is?mapped?into?kernel?address?space,
??*?we?can?simply?calculate?the?virtual?address.?On?machines?with
??*?highmem?some?memory?is?mapped?into?kernel?virtual?memory
??*?dynamically,?so?we?need?a?place?to?store?that?address.
??*?Note?that?this?field?could?be?16?bits?on?x86?...?;)
??*
??*?Architectures?with?slow?multiplication?can?define
??*?WANT_PAGE_VIRTUAL?in?asm/page.h
??*/
#if?defined(WANT_PAGE_VIRTUAL)
?void?*virtual;???/*?Kernel?virtual?address?(NULL?if
????????not?kmapped,?ie.?highmem)?*/
#endif?/*?WANT_PAGE_VIRTUAL?*/
#ifdef?LAST_CPUPID_NOT_IN_PAGE_FLAGS
?int?_last_cpupid;
#endif
}?_struct_page_alignment;
可以看到頁面描述符的定義非常復雜,各種共用體套共用體。為什么這么復雜呢?這是因為物理內存的每個頁幀都需要有一個頁面描述符。對于4G的物理內存來說,需要有4G/4K=1M也就是100多萬個頁面描述符。所以竭盡全力地減少頁面描述符的大小是非常必要的。又由于頁面描述符記錄的很多數據不都是同時在使用的,所以可以使用共用體來減少頁面描述符的大小。頁面描述符中各個字段的含義,我們在用到的時候再進行解釋。
2.4 物理內存模型
計算機中有很多名稱叫做內存模型的概念,它們的含義并不相同,大家要注意區分。此處講的內存模型是Linux對物理內存地址空間連續性的抽象,用來表示物理內存的地址空間是否有空洞以及該如何處理空洞,因此這個概念也被叫做內存連續性模型。由于內存熱插拔也會導致物理內存地址空間產生空洞,因此Linux內存模型也是內存熱插拔的基礎。
最開始的時候是沒有內存模型的,后來有了其它的內存模型,這個最開始的情況就被叫做平坦內存模型(Flat Memory)。平坦內存模型看到的物理內存就是連續的沒有空洞的內存。后來為了處理物理內存有空洞的情況以及內存熱插拔問題,又開發出了離散內存模型(Discontiguous Memory)。但是離散內存模型的實現復用了NUMA的代碼,導致NUMA和內存模型的耦合,實際上二者在邏輯上是正交的。內核后來又開發了稀疏內存模型(Sparse Memory),其實現和NUMA不再耦合在一起了,而且稀疏內存模型能同時處理平坦內存、稀疏內存、極度稀疏內存,還能很好地支持內存熱插拔。于是離散內存模型就先被棄用了,后又被移出了內核。現在內核中就只有平坦內存模型和稀疏內存模型了。而且在很多架構中,如x86、ARM64,稀疏內存模型已經變成了唯一的可選項了,也就是必選內存模型。
系統有一個頁面描述符的數組,用來描述系統中的所有頁幀。這個數組是在系統啟動時創建的,然后有一個全局的指針變量會指向這個數組。這個變量的名字在平坦內存中叫做mem_map,是全分配的,在稀疏內存中叫做vmemmap,內存空洞對應的頁表描述符是不被映射的。學過C語言的人都知道指針與數組之間的關系,指針之間的減法以及指針與整數之間的加法與數組下標的關系。因此我們可以把頁面描述符指針和頁幀號相互轉換。
我們來看一下頁面描述符數組指針的定義和指針與頁幀號之間的轉換操作。linux-src/mm/memory.c
#ifndef?CONFIG_NUMA
struct?page?*mem_map;
EXPORT_SYMBOL(mem_map);
#endif
linux-src/arch/x86/include/asm/pgtable_64.h
#define?vmemmap?((struct?page?*)VMEMMAP_START)
linux-src/arch/x86/include/asm/pgtable_64_types.h
#ifdef?CONFIG_DYNAMIC_MEMORY_LAYOUT
#?define?VMEMMAP_START??vmemmap_base
#else
#?define?VMEMMAP_START??__VMEMMAP_BASE_L4
#endif?/*?CONFIG_DYNAMIC_MEMORY_LAYOUT?*/
linux-src/include/asm-generic/memory_model.h
#if?defined(CONFIG_FLATMEM)
#ifndef?ARCH_PFN_OFFSET
#define?ARCH_PFN_OFFSET??(0UL)
#endif
#define?__pfn_to_page(pfn)?(mem_map?+?((pfn)?-?ARCH_PFN_OFFSET))
#define?__page_to_pfn(page)?((unsigned?long)((page)?-?mem_map)?+?
?????ARCH_PFN_OFFSET)
#elif?defined(CONFIG_SPARSEMEM_VMEMMAP)
/*?memmap?is?virtually?contiguous.??*/
#define?__pfn_to_page(pfn)?(vmemmap?+?(pfn))
#define?__page_to_pfn(page)?(unsigned?long)((page)?-?vmemmap)
#elif?defined(CONFIG_SPARSEMEM)
/*
?*?Note:?section's?mem_map?is?encoded?to?reflect?its?start_pfn.
?*?section[i].section_mem_map?==?mem_map's?address?-?start_pfn;
?*/
#define?__page_to_pfn(pg)?????
({?const?struct?page?*__pg?=?(pg);????
?int?__sec?=?page_to_section(__pg);???
?(unsigned?long)(__pg?-?__section_mem_map_addr(__nr_to_section(__sec)));?
})
#define?__pfn_to_page(pfn)????
({?unsigned?long?__pfn?=?(pfn);???
?struct?mem_section?*__sec?=?__pfn_to_section(__pfn);?
?__section_mem_map_addr(__sec)?+?__pfn;??
})
#endif?/*?CONFIG_FLATMEM/SPARSEMEM?*/
/*
?*?Convert?a?physical?address?to?a?Page?Frame?Number?and?back
?*/
#define?__phys_to_pfn(paddr)?PHYS_PFN(paddr)
#define?__pfn_to_phys(pfn)?PFN_PHYS(pfn)
#define?page_to_pfn?__page_to_pfn
#define?pfn_to_page?__pfn_to_page
2.5 三級區劃關系
我們對物理內存的三級區劃有了簡單的了解,下面我們再對它們之間的關系進行更進一步地分析。雖然在節點描述符中包含了所有的區域類型,但是除了第一個節點能包含所有的區域類型之外,其它的節點并不能包含所有的區域類型,因為有些區域類型(DMA、DMA32)必須從物理內存的起點開始。Normal、HighMem和Movable是可以出現在所有的節點上的。頁面編號(pfn)是從物理內存的起點開始編號,不是每個節點或者區域重新編號的。所有區域的范圍都必須是整數倍個頁面,不能出現半個頁面。節點描述符不僅記錄自己所包含的區域,還會記錄自己的起始頁幀號和跨越頁幀數量,區域描述符也會記錄自己的起始頁幀號和跨越頁幀數量。
下面我們來畫個圖看一下節點與頁面之間的關系以及x86上具體的區分劃分情況。
三、物理內存分配
當我們把物理內存區劃弄明白之后,再來學習物理內存分配就比較容易了。物理內存分配最底層的是頁幀分配。頁幀分配的分配單元是區域,分配粒度是頁面。如何進行頁幀分配呢?Linux采取的算法叫做伙伴系統(buddy system)。只有伙伴系統還不行,因為伙伴系統進行的是大粒度的分配,我們還需要批發與零售,于是便有了slab allocator和kmalloc。這幾種內存分配方法分配的都是線性映射的內存,當系統連續內存不足的時候,Linux還提供了vmalloc用來分配非線性映射的內存。下面我們畫圖來看一下它們之間的關系。
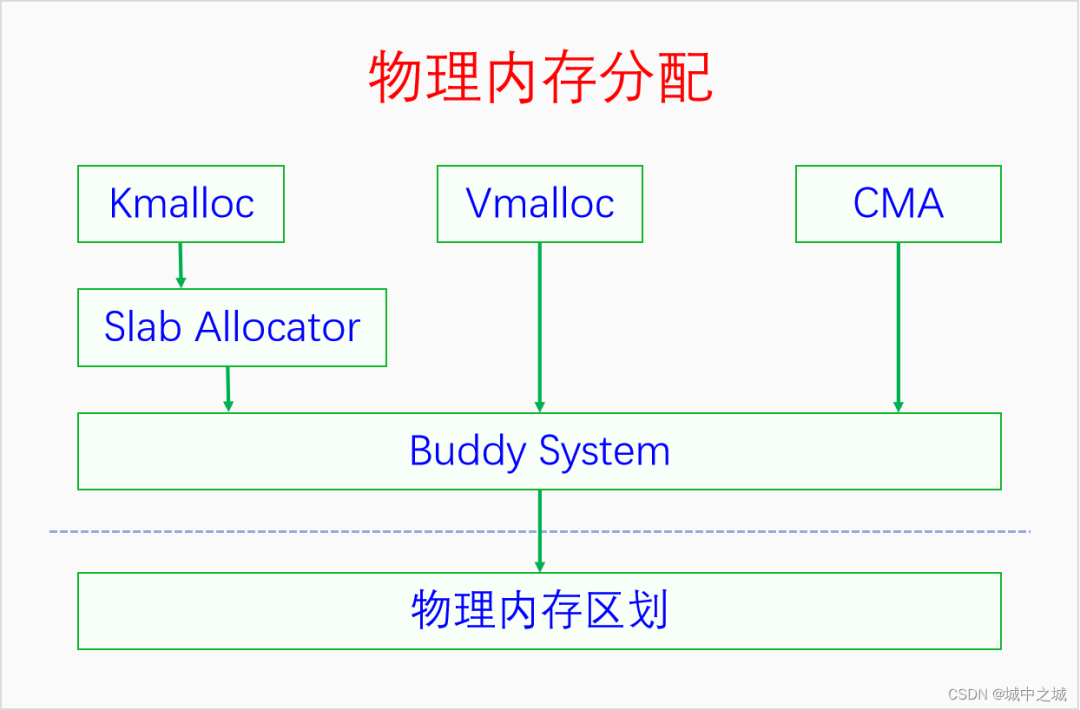
Buddy System既是直接的內存分配接口,也是所有其它內存分配器的底層分配器。Slab建立在Buddy的基礎之上,Kmalloc又建立在Slab的基礎之上。Vmalloc和CMA也是建立在Buddy的基礎之上。Linux采取的這種內存分配體系提供了豐富靈活的內存接口,還能同時減少外部碎片和內部碎片。
3.1 Buddy System
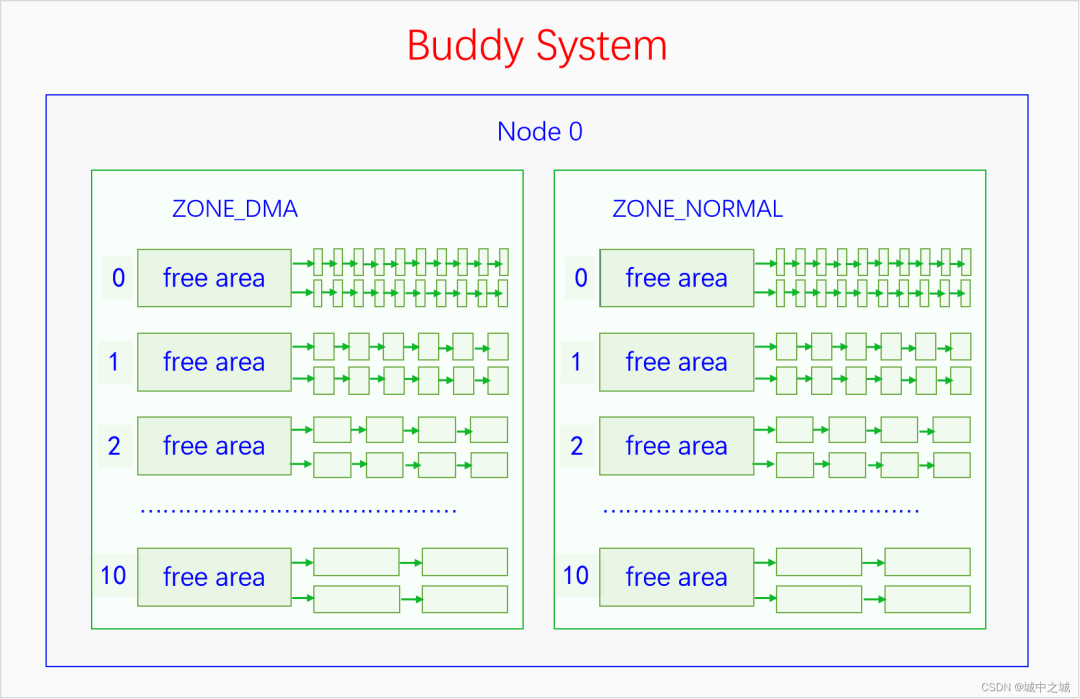
伙伴系統的基本管理單位是區域,最小分配粒度是頁面。因為伙伴系統是建立在物理內存的三級區劃上的,所以最小分配粒度是頁面,不能比頁面再小了。基本管理單位是區域,是因為每個區域的內存都有特殊的用途或者用法,不能隨便混用,所以不能用節點作為基本管理單位。伙伴系統并不是直接管理一個個頁幀的,而是把頁幀組成頁塊(pageblock)來管理,頁塊是由連續的2^n^個頁幀組成,n叫做這個頁塊的階,n的范圍是0到10。而且2^n^個頁幀還有對齊的要求,首頁幀的頁幀號(pfn)必須能除盡2^n^,比如3階頁塊的首頁幀(pfn)必須除以8(2^3^)能除盡,10階頁塊的首頁幀必須除以1024(2^10^)能除盡。0階頁塊只包含一個頁幀,任意一個頁幀都可以構成一個0階頁塊,而且符合對齊要求,因為任何整數除以1(2^0^)都能除盡。
3.1.1 伙伴系統的內存來源
伙伴系統管理的內存并不是全部的物理內存,而是內核在完成初步的初始化之后的未使用內存。內核在剛啟動的時候有一個簡單的早期內存管理器,它會記錄系統的所有物理內存以及在它之前就被占用的內存,并為內核提供早期的內存分配服務。當內核的基礎初始化完成之后,它就會把所有剩余可用的物理內存交給伙伴系統來管理,然后自己就退出歷史舞臺了。早期內存管理器會首先嘗試把頁幀以10階頁塊的方式加入伙伴系統,不夠10階的以9階頁塊的方式加入伙伴系統,以此類推,直到以0階頁塊的方式把所有可用頁幀都加入到伙伴系統。顯而易見,內核剛啟動的時候高階頁塊比較多,低階頁塊比較少。早期內存管理器以前是bootmem,后來是bootmem和memblock共存,可以通過config選擇使用哪一個,現在是只有memblock了,bootmem已經被移出了內核。
3.1.2 伙伴系統的管理數據結構
伙伴系統的管理數據定義在區域描述符中,是結構體free_area的數組,數組大小是11,因為從0到10有11個數。free_area的定義如下所示:linux-src/include/linux/mmzone.h
struct?free_area?{
?struct?list_head?free_list[MIGRATE_TYPES];
?unsigned?long??nr_free;
};
enum?migratetype?{
?MIGRATE_UNMOVABLE,
?MIGRATE_MOVABLE,
?MIGRATE_RECLAIMABLE,
?MIGRATE_PCPTYPES,?/*?the?number?of?types?on?the?pcp?lists?*/
?MIGRATE_HIGHATOMIC?=?MIGRATE_PCPTYPES,
#ifdef?CONFIG_CMA
?/*
??*?MIGRATE_CMA?migration?type?is?designed?to?mimic?the?way
??*?ZONE_MOVABLE?works.??Only?movable?pages?can?be?allocated
??*?from?MIGRATE_CMA?pageblocks?and?page?allocator?never
??*?implicitly?change?migration?type?of?MIGRATE_CMA?pageblock.
??*
??*?The?way?to?use?it?is?to?change?migratetype?of?a?range?of
??*?pageblocks?to?MIGRATE_CMA?which?can?be?done?by
??*?__free_pageblock_cma()?function.??What?is?important?though
??*?is?that?a?range?of?pageblocks?must?be?aligned?to
??*?MAX_ORDER_NR_PAGES?should?biggest?page?be?bigger?than
??*?a?single?pageblock.
??*/
?MIGRATE_CMA,
#endif
#ifdef?CONFIG_MEMORY_ISOLATION
?MIGRATE_ISOLATE,?/*?can't?allocate?from?here?*/
#endif
?MIGRATE_TYPES
};
可以看到free_area的定義非常簡單,就是由MIGRATE_TYPES個鏈表組成,鏈表連接的是同一個階的遷移類型相同的頁幀。遷移類型是內核為了減少內存碎片而提出的技術,不同區域的頁塊有不同的默認遷移類型,比如DMA、NORMAL默認都是不可遷移(MIGRATE_UNMOVABLE)的頁塊,HIGHMEM、MOVABLE區域默認都是可遷移(MIGRATE_UNMOVABLE)的頁塊。我們申請的內存有時候是不可移動的內存,比如內核線性映射的內存,有時候是可以移動的內存,比如用戶空間缺頁異常分配的內存。我們把不同遷移類型的內存分開進行分配,在進行內存碎片整理的時候就比較方便,不會出現一片可移動內存中夾著一個不可移動的內存(這種情況就很礙事)。如果要分配的遷移類型的內存不足時就需要從其它的遷移類型中進行盜頁了。內核定義了每種遷移類型的后備類型,如下所示:linux-src/mm/page_alloc.c
/*
?*?This?array?describes?the?order?lists?are?fallen?back?to?when
?*?the?free?lists?for?the?desirable?migrate?type?are?depleted
?*/
static?int?fallbacks[MIGRATE_TYPES][3]?=?{
?[MIGRATE_UNMOVABLE]???=?{?MIGRATE_RECLAIMABLE,?MIGRATE_MOVABLE,???MIGRATE_TYPES?},
?[MIGRATE_MOVABLE]?????=?{?MIGRATE_RECLAIMABLE,?MIGRATE_UNMOVABLE,?MIGRATE_TYPES?},
?[MIGRATE_RECLAIMABLE]?=?{?MIGRATE_UNMOVABLE,???MIGRATE_MOVABLE,???MIGRATE_TYPES?},
#ifdef?CONFIG_CMA
?[MIGRATE_CMA]?????????=?{?MIGRATE_TYPES?},?/*?Never?used?*/
#endif
#ifdef?CONFIG_MEMORY_ISOLATION
?[MIGRATE_ISOLATE]?????=?{?MIGRATE_TYPES?},?/*?Never?used?*/
#endif
};
一種遷移類型的頁塊被盜頁之后,它的遷移類型就改變了,所以一個頁塊的遷移類型是會改變的,有可能變來變去。當物理內存比較少時,這種變來變去就會特別頻繁,這樣遷移類型帶來的好處就得不償失了。因此內核定義了一個變量page_group_by_mobility_disabled,當物理內存比較少時就禁用遷移類型。
伙伴系統管理頁塊的方式可以用下圖來表示:
3.1.3 伙伴系統的算法邏輯
伙伴系統對外提供的接口只能分配某一階的頁塊,并不能隨意分配若干個頁幀。當分配n階頁塊時,伙伴系統會優先查找n階頁塊的鏈表,如果不為空的話就拿出來一個分配。如果為空的就去找n+1階頁塊的鏈表,如果不為空的話,就拿出來一個,并分成兩個n階頁塊,其中一個加入n階頁塊的鏈表中,另一個分配出去。如果n+1階頁塊鏈表也是空的話,就去找n+2階頁塊的鏈表,如果不為空的話,就拿出來一個,然后分成兩個n+1階的頁塊,其中一個加入到n+1階的鏈表中去,剩下的一個再分成兩個n階頁塊,其中一個放入n階頁塊的鏈表中去,另一個分配出去。如果n+2階頁塊的鏈表也是空的,那就去找n+3階頁塊的鏈表,重復此邏輯,直到找到10階頁塊的鏈表。如果10階頁塊的鏈表也是空的話,那就去找后備遷移類型的頁塊去分配,此時從最高階的頁塊鏈表往低階頁塊的鏈表開始查找,直到查到為止。如果后備頁塊也分配不到內存,那么就會進行內存回收,這是下一章的內容。
用戶用完內存還給伙伴系統的時候,并不是直接還給其對應的n階頁塊的鏈表就行了,而是會先進行合并。比如你申請了一個0階頁塊,用完了之后要歸還,我們假設其頁幀號是5,來推演一下其歸還過程。如果此時發現4號頁幀也是free的,則4和5會合并成一個1階頁塊,首頁幀號是4。如果4號頁幀不是free的,則5號頁幀直接還給0階頁塊鏈表中去。如果6號頁幀free呢,會不會和5號頁幀合并?不會,因為不滿足頁幀號對齊要求。如果5和6合并,將會成為一個1階頁塊,1階頁塊要求其首頁幀的頁號必須除以2(2^1^)能除盡,而5除以2除不盡,所以5和6不能合并。而4和5合并之后,4除以2(2^1^)是能除盡的。4和5合并成一個1階頁塊之后還要查看是否能繼續合并,如果此時有一個1階頁塊是free的,由6和7組成的,此時它們就會合并成一個2階頁塊,包含4、5、6、7共4個頁幀,而且符合對齊要求,4除以4(2^2^)是能除盡的。如果此時有一個1階頁塊是free的,由2和3組成的,那么就不能合并,因為合并后的首頁幀是2,2除以4(2^2^)是除不盡的。繼續此流程,如果合并后的n階頁塊的前面或者后面還有free的同階頁塊,而且也符合對齊要求,就會繼續合并,直到無法合并或者已經到達了10階頁塊,才會停止合并,然后把其插入到對應的頁塊鏈表中去。
3.1.4 伙伴系統的接口
下面我們來看一下伙伴系統的接口。伙伴系統提供了兩類接口,一類是返回頁表描述符的,一類是返回虛擬內存地址的。linux-src/include/linux/gfp.
struct?page?*alloc_pages(gfp_t?gfp,?unsigned?int?order);
#define?alloc_page(gfp_mask)?alloc_pages(gfp_mask,?0)
struct?page?*alloc_pages_node(int?nid,?gfp_t?gfp_mask,unsigned?int?order);
void?__free_pages(struct?page?*page,?unsigned?int?order);
#define?__free_page(page)?__free_pages((page),?0)
釋放的接口很簡單,只需要一個頁表描述符指針加一個階數。分配的接口中,有的會指定nodeid,就從那個節點中分配內存。不指定nodeid的接口,如果是在UMA中,那就從唯一的節點中分配內存,如果是NUMA,會按照一定的策略選擇在哪個節點中分配內存。最復雜的參數是gfp,gfp是標記參數,可以分為兩類標記,一類是指定分配區域的,一類是指定分配行為的,下面我們來看一下。linux-src/include/linux/gfp.h
#define?___GFP_DMA??0x01u
#define?___GFP_HIGHMEM??0x02u
#define?___GFP_DMA32??0x04u
#define?___GFP_MOVABLE??0x08u
#define?___GFP_RECLAIMABLE?0x10u
#define?___GFP_HIGH??0x20u
#define?___GFP_IO??0x40u
#define?___GFP_FS??0x80u
#define?___GFP_ZERO??0x100u
#define?___GFP_ATOMIC??0x200u
#define?___GFP_DIRECT_RECLAIM?0x400u
#define?___GFP_KSWAPD_RECLAIM?0x800u
#define?___GFP_WRITE??0x1000u
#define?___GFP_NOWARN??0x2000u
#define?___GFP_RETRY_MAYFAIL?0x4000u
#define?___GFP_NOFAIL??0x8000u
#define?___GFP_NORETRY??0x10000u
#define?___GFP_MEMALLOC??0x20000u
#define?___GFP_COMP??0x40000u
#define?___GFP_NOMEMALLOC?0x80000u
#define?___GFP_HARDWALL??0x100000u
#define?___GFP_THISNODE??0x200000u
#define?___GFP_ACCOUNT??0x400000u
#define?___GFP_ZEROTAGS??0x800000u
#define?___GFP_SKIP_KASAN_POISON?0x1000000u
#ifdef?CONFIG_LOCKDEP
#define?___GFP_NOLOCKDEP?0x2000000u
#else
#define?___GFP_NOLOCKDEP?0
#endif
其中前4個是指定分配區域的,內核里一共定義了6類區域,為啥只有4個指示符呢?因為ZONE_DEVICE有特殊用途,不在一般的內存分配管理中,當不指定區域類型時默認就是ZONE_NORMAL,所以4個就夠了。是不是指定了哪個區域就只能在哪個區域分配內存呢,不是的。每個區域都有后備區域,當其內存不足時,會從其后備區域中分配內存。后備區域是在節點描述符中定義,我們來看一下:linux-src/include/linux/mmzone.h
typedef?struct?pglist_data?{
?struct?zonelist?node_zonelists[MAX_ZONELISTS];
}?pg_data_t;
enum?{
?ZONELIST_FALLBACK,?/*?zonelist?with?fallback?*/
#ifdef?CONFIG_NUMA
?/*
??*?The?NUMA?zonelists?are?doubled?because?we?need?zonelists?that
??*?restrict?the?allocations?to?a?single?node?for?__GFP_THISNODE.
??*/
?ZONELIST_NOFALLBACK,?/*?zonelist?without?fallback?(__GFP_THISNODE)?*/
#endif
?MAX_ZONELISTS
};
struct?zonelist?{
?struct?zoneref?_zonerefs[MAX_ZONES_PER_ZONELIST?+?1];
};
struct?zoneref?{
?struct?zone?*zone;?/*?Pointer?to?actual?zone?*/
?int?zone_idx;??/*?zone_idx(zoneref->zone)?*/
};
在UMA上,后備區域只有一個鏈表,就是本節點內的后備區域,在NUMA中后備區域有兩個鏈表,包括本節點內的后備區域和其它節點的后備區域。這些后備區域是在內核啟動時初始化的。對于本節點的后備區域,是按照區域類型的id排列的,高id的排在前面,低id的排在后面,后面的是前面的后備,前面的區域內存不足時可以從后面的區域里分配內存,反過來則不行。比如MOVABLE區域的內存不足時可以從NORMAL區域來分配,NORMAL區域的內存不足時可以從DMA區域來分配,反過來則不行。對于其它節點的后備區域,除了會符合前面的規則之外,還會考慮后備區域是按照節點優先的順序來排列還是按照區域類型優先的順序來排列。
下面我們再來看一下分配行為的flag都是什么含義。
__GFP_HIGH:調用者的優先級很高,要盡量滿足分配請求。
__GFP_ATOMIC:調用者處在原子場景中,分配過程不能回收頁或者睡眠,一般是中斷處理程序會用。
__GFP_IO:可以進行磁盤IO操作。
__GFP_FS:可以進行文件系統的操作。
__GFP_KSWAPD_RECLAIM:當內存不足時允許異步回收。
__GFP_RECLAIM:當內存不足時允許同步回收和異步回收。
__GFP_REPEAT:允許重試,重試多次以后還是沒有內存就返回失敗。
__GFP_NOFAIL:不能失敗,必須無限次重試。
__GFP_NORETRY:不要重試,當直接回收和內存規整之后還是分配不到內存的話就返回失敗。
__GFP_ZERO:把要分配的頁清零。
還有一些其它的flag就不再一一進行介紹了。
如果我們每次分配內存都把這些flag一一進行組合,那就太麻煩了,所以系統為我們定義了一些常用的組合,如下所示:linux-src/include/linux/gfp.h
#define?GFP_ATOMIC?(__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define?GFP_KERNEL?(__GFP_RECLAIM?|?__GFP_IO?|?__GFP_FS)
#define?GFP_NOIO?(__GFP_RECLAIM)
#define?GFP_NOFS?(__GFP_RECLAIM?|?__GFP_IO)
#define?GFP_USER?(__GFP_RECLAIM?|?__GFP_IO?|?__GFP_FS?|?__GFP_HARDWALL)
#define?GFP_DMA??__GFP_DMA
#define?GFP_DMA32?__GFP_DMA32
#define?GFP_HIGHUSER?(GFP_USER?|?__GFP_HIGHMEM)
#define?GFP_HIGHUSER_MOVABLE?(GFP_HIGHUSER?|?__GFP_MOVABLE?|?__GFP_SKIP_KASAN_POISON)
中斷中分配內存一般用GFP_ATOMIC,內核自己使用的內存一般用GFP_KERNEL,為用戶空間分配內存一般用GFP_HIGHUSER_MOVABLE。
我們再來看一下直接返回虛擬內存的接口函數。linux-src/include/linux/gfp.h
unsigned?long?__get_free_pages(gfp_t?gfp_mask,?unsigned?int?order);
#define?__get_free_page(gfp_mask)??__get_free_pages((gfp_mask),?0)
#define?__get_dma_pages(gfp_mask,?order)?__get_free_pages((gfp_mask)?|?GFP_DMA,?(order))
unsigned?long?get_zeroed_page(gfp_t?gfp_mask);
void?free_pages(unsigned?long?addr,?unsigned?int?order);
#define?free_page(addr)?free_pages((addr),?0)
此接口不能分配HIGHMEM中的內存,因為HIGHMEM中的內存不是直接映射到內核空間中去的。除此之外這個接口和前面的沒有區別,其參數函數也跟前面的一樣,就不再贅述了。
3.1.5 伙伴系統的實現
下面我們再來看一下伙伴系統的分配算法。linux-src/mm/page_alloc.c
/*
?*?This?is?the?'heart'?of?the?zoned?buddy?allocator.
?*/
struct?page?*__alloc_pages(gfp_t?gfp,?unsigned?int?order,?int?preferred_nid,
???????nodemask_t?*nodemask)
{
?struct?page?*page;
?
?/*?First?allocation?attempt?*/
?page?=?get_page_from_freelist(alloc_gfp,?order,?alloc_flags,?&ac);
?if?(likely(page))
??goto?out;
?page?=?__alloc_pages_slowpath(alloc_gfp,?order,?&ac);
out:
?return?page;
}
伙伴系統的所有分配接口最終都會使用__alloc_pages這個函數來進行分配。對這個函數進行刪減之后,其邏輯也比較簡單清晰,先使用函數get_page_from_freelist直接從free_area中進行分配,如果分配不到就使用函數 __alloc_pages_slowpath進行內存回收。內存回收的內容在下一章里面講。
3.2 Slab Allocator
伙伴系統的最小分配粒度是頁面,但是內核中有很多大量的同一類型結構體的分配請求,比如說進程的結構體task_struct,如果使用伙伴系統來分配顯然不合適,如果自己分配一個頁面,然后可以分割成多個task_struct,顯然也很麻煩,于是內核中給我們提供了slab分配機制來滿足這種需求。Slab的基本思想很簡單,就是自己先從伙伴系統中分配一些頁面,然后把這些頁面切割成一個個同樣大小的基本塊,用戶就可以從slab中申請分配一個同樣大小的內存塊了。如果slab中的內存不夠用了,它會再向伙伴系統進行申請。不同的slab其基本塊的大小并不相同,內核的每個模塊都要為自己的特定需求分配特定的slab,然后再從這個slab中分配內存。
剛開始的時候內核中就只有一個slab,其接口和實現都叫slab。但是后來內核中又出現了兩個slab實現,slob和slub。slob是針對嵌入式系統進行優化的,slub是針對內存比較多的系統進行優化的,它們的接口還是slab。由于現在的計算機內存普遍都比較大,連手機的的內存都6G、8G起步了,所以現在除了嵌入式系統之外,內核默認使用的都是slub。下面我們畫個圖看一下它們的關系。
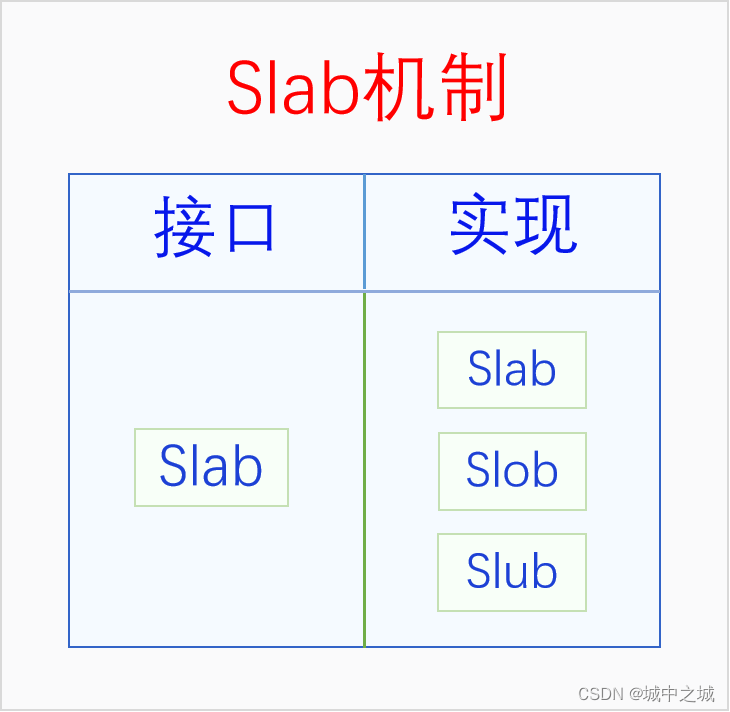
可以看到Slab在不同的語境下有不同的含義,有時候指的是整個Slab機制,有時候指的是Slab接口,有時候指的是Slab實現。如果我們在討論問題的時候遇到了歧義,可以加上漢語后綴以明確語義。
3.2.1 Slab接口
下面我們來看一下slab的接口:linux-src/include/linux/slab.h
struct?kmem_cache?*kmem_cache_create(const?char?*name,?unsigned?int?size,
???unsigned?int?align,?slab_flags_t?flags,
???void?(*ctor)(void?*));
void?kmem_cache_destroy(struct?kmem_cache?*);
void?*kmem_cache_alloc(struct?kmem_cache?*,?gfp_t?flags);
void?kmem_cache_free(struct?kmem_cache?*,?void?*);
我們在使用slab時首先要創建slab,創建slab用的是接口kmem_cache_create,其中最重要的參數是size,它是基本塊的大小,一般我們都會傳遞sizeof某個結構體。創建完slab之后,我們用kmem_cache_alloc從slab中分配內存,第一個參數指定哪個是從哪個slab中分配,第二個參數gfp指定如果slab的內存不足了如何從伙伴系統中去分配內存,gfp的函數和前面伙伴系統中講的相同,此處就不再贅述了,函數返回的是一個指針,其指向的內存大小就是slab在創建時指定的基本塊的大小。當我們用完一塊內存時,就要用kmem_cache_free把它還給slab,第一個參數指定是哪個slab,第二個參數是我們要返回的內存。如果我們想要釋放整個slab的話,就使用接口kmem_cache_destroy。
3.2.2 Slab實現
暫略
3.2.3 Slob實現
暫略
3.2.4 Slub實現
暫略
3.3 Kmalloc
內存中還有一些偶發的零碎的內存分配需求,一個模塊如果僅僅為了分配一次5字節的內存,就去創建一個slab,那顯然不劃算。為此內核創建了一個統一的零碎內存分配器kmalloc,用戶可以直接請求kmalloc分配若干個字節的內存。Kmalloc底層用的還是slab機制,kmalloc在啟動的時候會預先創建一些不同大小的slab,用戶請求分配任意大小的內存,kmalloc都會去大小剛剛滿足的slab中去分配內存。
下面我們來看一下kmalloc的接口:linux-src/include/linux/slab.h
void?*kmalloc(size_t?size,?gfp_t?flags);
void?kfree(const?void?*);
可以看到kmalloc的接口很簡單,使用接口kmalloc就可以分配內存,第一個參數是你要分配的內存大小,第二個參數和伙伴系統的參數是一樣的,這里就不再贅述了,返回值是一個內存指針,用這個指針就可以訪問分配到的內存了。內存使用完了之后用kfree進行釋放,參數是剛才分配到的內存指針。
我們以slub實現為例講一下kmalloc的邏輯。Kmalloc中會定義一個全局的slab指針的二維數組,第一維下標代表的是kmalloc的類型,默認有四種類型,分別有DMA和NORMAL,這兩個代表的是gfp中的區域,還有兩個是CGROUP和RECLAIM,CGROUP代表的是在memcg中分配內存,RECLAIM代表的是可回收內存。第二維下標代表的是基本塊大小的2的對數,不過下標0、1、2是例外,有特殊含義。在系統初始化的時候,會初始化這個數組,創建每一個slab,下標0除外,下標1對應的slab的基本塊大小是96,下標2對應的slab的基本塊的大小是192。在用kmalloc分配內存的時候,會先處理特殊情況,當size是0的時候直接返回空指針,當size大于8k的時候會則直接使用伙伴系統進行分配。然后先根據gfp參數選擇kmalloc的類型,再根據size的大小選擇index。如果2^n-1^+1 < size <= 2^n^,則index等于n,但是有特殊情況,當 64 < size <= 96時,index等于1,當 128 < size <= 192時,index等于2。Type和index都確定好之后,就找到了具體的slab了,就可以從這個slab中分配內存了。
3.4 Vmalloc
暫略
3.5 CMA
暫略
四、物理內存回收
內存作為系統最寶貴的資源,總是不夠用的。當內存不足的時候就要對內存進行回收了。內存回收按照回收時機可以分為同步回收和異步回收,同步回收是指在分配內存的時候發現無法分配到內存就進行回收,異步回收是指有專門的線程定期進行檢測,如果發現內存不足就進行回收。內存回收的類型有兩種,一是內存規整,也就是內存碎片整理,它不會增加可用內存的總量,但是會增加連續可用內存的量,二是頁幀回收,它會把物理頁幀的內容寫入到外存中去,然后解除其與虛擬內存的映射,這樣可用物理內存的量就增加了。內存回收的時機和類型是正交關系,同步回收中會使用內存規整和頁幀回收,異步回收中也會使用內存規整和頁幀回收。在異步回收中,內存規整有單獨的線程kcompactd,此類線程一個node一個,線程名是[kcompactd/nodeid],頁幀回收也有單獨的線程kswapd,此類線程也是一個node一個,線程名是[kswapd/nodeid]。在同步回收中,還有一個大殺器,那就是OOM Killer,OOM是內存耗盡的意思,當內存耗盡,其它所有的內存回收方法也回收不到內存的時候,就會使用這個大殺器。下面我們畫個圖來看一下:
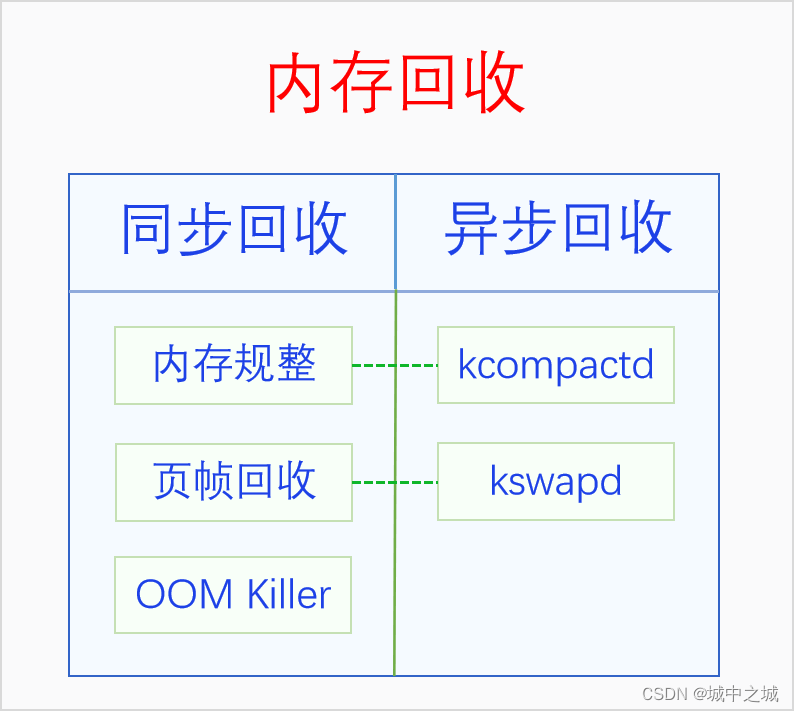
4.1 內存規整
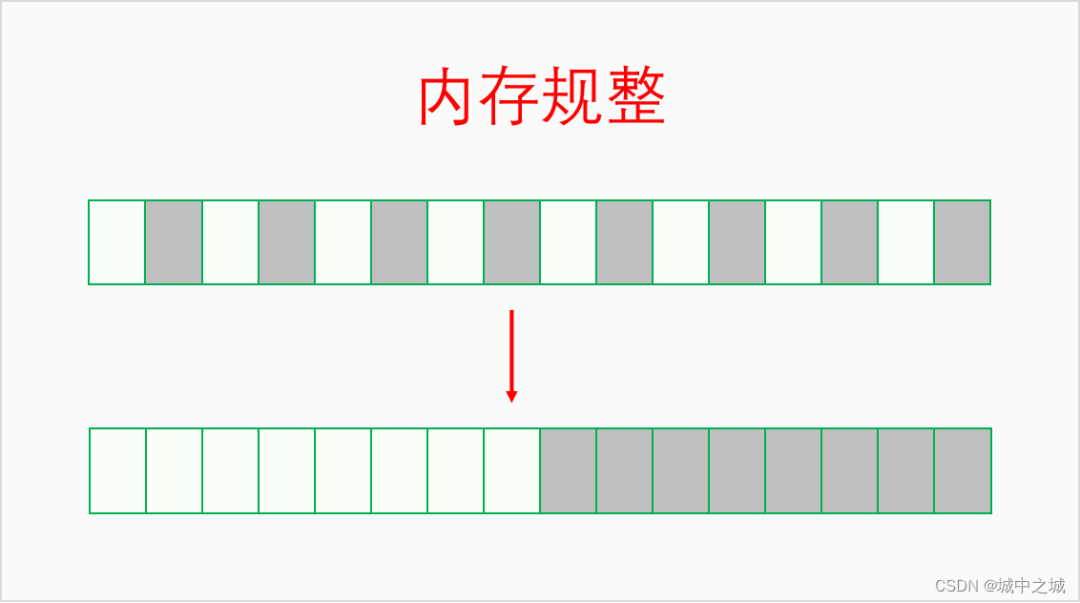
系統運行的時間長了,內存一會兒分配一會兒釋放,慢慢地可用內存就會變得很碎片化不連續。雖然總的可用內存還不少,但是卻無法分配大塊連續內存,此時就需要進行內存規整了。內存規整是以區域為基本單位,找到可用移動的頁幀,把它們都移到同一端,然后連續可用內存的量就增大了。其邏輯如下圖所示:
4.2 頁幀回收
內存規整只是增加了連續內存的量,但是可用內存的量并沒有增加,當可用內存量不足的時候就要進行頁幀回收。對于內核來說,其虛擬內存和物理內存的映射關系是不能解除的,所以必須同時回收物理內存和虛擬內存。對此采取的辦法是讓內核的每個模塊都注冊shrinker,當內存緊張時通過shrinker的回調函數通知每個模塊盡量釋放自己暫時用不到的內存。對于用戶空間,其虛擬內存和物理內存的映射關系是可以解除的,我們可以先把其物理內存上的內容保存到外存上去,然后再解除映射關系,這樣其物理內存就被回收了,就可以拿做它用了。如果程序后來又用到了這段內存,程序訪問其虛擬內存的時候就會發生缺頁異常,在缺頁異常里再給它分配物理內存,并把其內容從外存中加載建立,這樣程序還是能正常運行的。進程的內存頁可以分為兩種類型:一種是文件頁,其內容來源于文件,如程序的代碼區、數據區;一種是匿名頁,沒有內容來源,由內核直接為其分配內存,如進程的堆和棧。對于文件頁,有兩種情況:一種情況是文件頁是clean的,也就是和外存中的內容是一樣的,此時我們可以直接丟棄文件頁,后面用到時再從外存中加載進來;另一種情況是文件頁是dirty的,也就是其經歷過修改,和外存中的內容不同,此時要先把文件頁的內容寫入到外存中,然后才能回收其內存。對于匿名頁,由于其沒有文件做后備,沒辦法對其進行回收。此時就需要swap作為匿名頁的后備存儲了,有了swap之后,匿名頁也可以進行回收了。Swap是外存中的一片空間,可以是一個分區,也可以是文件,具體原理請看下一節。
頁幀回收時如何選擇回收哪些文件頁、匿名頁,不回收哪些文件頁、匿名頁呢,以及文件頁和匿名頁各回收多少比例呢?內核把所有的文件頁放到兩個鏈表上,活躍文件頁和不活躍文件頁,回收的時候只會回收不活躍文件頁。內核把所有的匿名頁也放到兩個鏈表上,活躍匿名頁和不活躍匿名頁,回收的時候只會回收不活躍匿名頁。有一個參數/proc/sys/vm/swappiness控制著匿名頁和文件頁之間的回收比例。
在回收文件頁和匿名頁的時候是需要把它們的虛擬內存映射給解除掉的。由于一個物理頁幀可能會同時映射到多個虛擬內存上,包括映射到多個進程或者同一個進程的不同地址上,所以我們需要找到一個物理頁幀所映射的所有虛擬內存。如何找到物理內存所映射的虛擬內存呢,這個過程就叫做反向映射(rmap)。之所以叫反向映射是因為正常的映射都是從虛擬內存映射到物理內存。
4.3 交換區
暫略
4.4 OOM Killer
如果用盡了上述所說的各種辦法還是無法回收到足夠的物理內存,那就只能使出殺手锏了,OOM Killer,通過殺死進程來回收內存。其觸發點在linux-src/mm/page_alloc.c:__alloc_pages_may_oom,當使用各種方法都回收不到內存時會調用out_of_memory函數。
下面我們來看一下out_of_memory函數的實現(經過高度刪減):linux-src/mm/oom_kill.c:out_of_memory
bool?out_of_memory(struct?oom_control?*oc)
{
????select_bad_process(oc);
????oom_kill_process(oc,?"Out?of?memory");
}
out_of_memory函數的代碼邏輯還是非常簡單清晰的,總共有兩步,1.先選擇一個要殺死的進程,2.殺死它。oom_kill_process函數的目的很簡單,但是實現過程也有點復雜,這里就不展開分析了,大家可以自行去看一下代碼。我們重點分析一下select_bad_process函數的邏輯,select_bad_process主要是依靠oom_score來進行進程選擇的。我們先來看一下和oom_score有關的三個文件。
/proc//oom_score系統計算出來的oom_score值,只讀文件,取值范圍0 –- 1000,0代表never kill,1000代表aways kill,值越大,進程被選中的概率越大。
/proc//oom_score_adj讓用戶空間調節oom_score的接口,root可讀寫,取值范圍 -1000 --- 1000,默認為0,若為 -1000,則oom_score加上此值一定小于等于0,從而變成never kill進程。OS可以把一些關鍵的系統進程的oom_score_adj設為-1000,從而避免被oom kill。
/proc//oom_adj舊的接口文件,為兼容而保留,root可讀寫,取值范圍 -16 — 15,會被線性映射到oom_score_adj,特殊值 -17代表 OOM_DISABLE。大家盡量不要再用此接口。
下面我們來分析一下select_bad_process函數的實現:
static?void?select_bad_process(struct?oom_control?*oc)
{
?oc->chosen_points?=?LONG_MIN;
?struct?task_struct?*p;
?rcu_read_lock();
?for_each_process(p)
??if?(oom_evaluate_task(p,?oc))
???break;
?rcu_read_unlock();
}
函數首先把chosen_points初始化為最小的Long值,這個值是用來比較所有的oom_score值,最后誰的值最大就選中哪個進程。然后函數已經遍歷所有進程,計算其oom_score,并更新chosen_points和被選中的task,有點類似于選擇排序。我們繼續看oom_evaluate_task函數是如何評估每個進程的函數。
static?int?oom_evaluate_task(struct?task_struct?*task,?void?*arg)
{
?struct?oom_control?*oc?=?arg;
?long?points;
?if?(oom_unkillable_task(task))
??goto?next;
?/*?p?may?not?have?freeable?memory?in?nodemask?*/
?if?(!is_memcg_oom(oc)?&&?!oom_cpuset_eligible(task,?oc))
??goto?next;
?if?(oom_task_origin(task))?{
??points?=?LONG_MAX;
??goto?select;
?}
?points?=?oom_badness(task,?oc->totalpages);
?if?(points?==?LONG_MIN?||?points?chosen_points)
??goto?next;
select:
?if?(oc->chosen)
??put_task_struct(oc->chosen);
?get_task_struct(task);
?oc->chosen?=?task;
?oc->chosen_points?=?points;
next:
?return?0;
abort:
?if?(oc->chosen)
??put_task_struct(oc->chosen);
?oc->chosen?=?(void?*)-1UL;
?return?1;
}
此函數首先會跳過所有不適合kill的進程,如init進程、內核線程、OOM_DISABLE進程等。然后通過select_bad_process算出此進程的得分points 也就是oom_score,并和上一次的勝出進程進行比較,如果小的會話就會goto next 返回,如果大的話就會更新oc->chosen 的task 和 chosen_points 也就是目前最高的oom_score。那么 oom_badness是如何計算的呢?
long?oom_badness(struct?task_struct?*p,?unsigned?long?totalpages)
{
?long?points;
?long?adj;
?if?(oom_unkillable_task(p))
??return?LONG_MIN;
?p?=?find_lock_task_mm(p);
?if?(!p)
??return?LONG_MIN;
?adj?=?(long)p->signal->oom_score_adj;
?if?(adj?==?OOM_SCORE_ADJ_MIN?||
???test_bit(MMF_OOM_SKIP,?&p->mm->flags)?||
???in_vfork(p))?{
??task_unlock(p);
??return?LONG_MIN;
?}
?points?=?get_mm_rss(p->mm)?+?get_mm_counter(p->mm,?MM_SWAPENTS)?+
??mm_pgtables_bytes(p->mm)?/?PAGE_SIZE;
?task_unlock(p);
?adj?*=?totalpages?/?1000;
?points?+=?adj;
?return?points;
}
oom_badness首先把unkiller的進程也就是init進程內核線程直接返回 LONG_MIN,這樣它們就不會被選中而殺死了,這里看好像和前面的檢測冗余了,但是實際上這個函數還被/proc//oom_score的show函數調用用來顯示數值,所以還是有必要的,這里也說明了一點,oom_score的值是不保留的,每次都是即時計算。然后又把oom_score_adj為-1000的進程直接也返回LONG_MIN,這樣用戶空間專門設置的進程就不會被kill了。最后就是計算oom_score了,計算方法比較簡單,就是此進程使用的RSS駐留內存、頁表、swap之和越大,也就是此進程所用的總內存越大,oom_score的值就越大,邏輯簡單直接,誰用的物理內存最多就殺誰,這樣就能夠回收更多的物理內存,而且使用內存最多的進程很可能是內存泄漏了,所以此算法雖然很簡單,但是也很合理。
可能很多人會覺得這里講的不對,和自己在網上的看到的邏輯不一樣,那是因為網上有很多講oom_score算法的文章都是基于2.6版本的內核講的,那個算法比較復雜,會考慮進程的nice值,nice值小的,oom_score會相應地降低,也會考慮進程的運行時間,運行時間越長,oom_score值也會相應地降低,因為當時認為進程運行的時間長消耗內存多是合理的。但是這個算法會讓那些緩慢內存泄漏的進程逃脫制裁。因此后來這個算法就改成現在這樣的了,只考慮誰用的內存多就殺誰,簡潔高效。
五、物理內存壓縮
暫略
5.1 ZRAM
5.2 ZSwap
5.3 ZCache
六、虛擬內存映射
開啟分頁內存機制之后,CPU訪問一切內存都要通過虛擬內存地址訪問,CPU把虛擬內存地址發送給MMU,MMU把虛擬內存地址轉換為物理內存地址,然后再用物理內存地址通過MC(內存控制器)訪問內存。MMU里面有兩個部件,TLB和PTW。TLB可以意譯地址轉換緩存器,它是緩存虛擬地址解析結果的地方。PTW可以意譯為虛擬地址解析器,它負責解析頁表,把虛擬地址轉換為物理地址,然后再送去MC進行訪問。同時其轉換結果也會被送去TLB進行緩存,下次再訪問相同虛擬地址的時候就不用再去解析了,可以直接用緩存的結果。
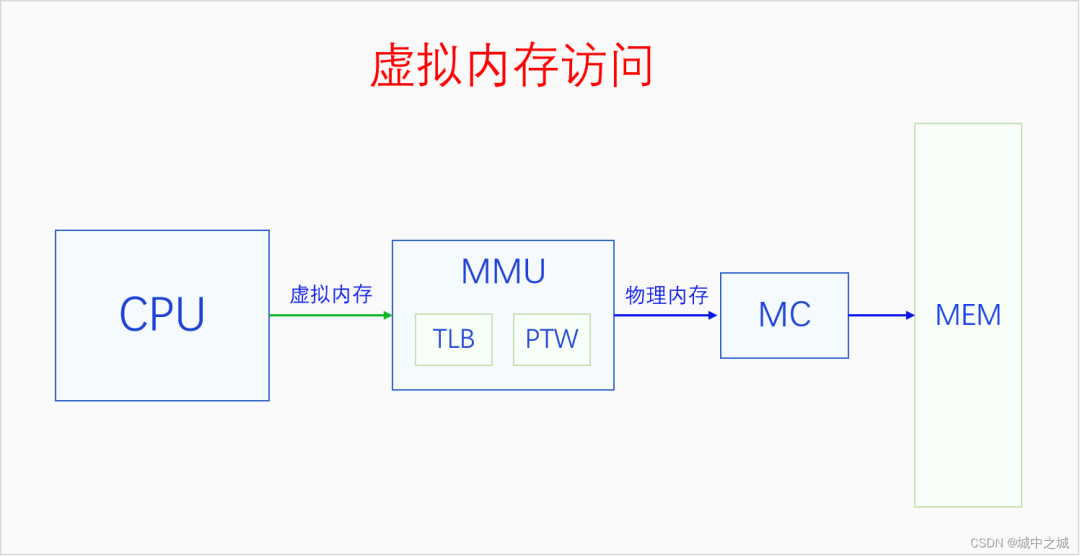
6.1 頁表
虛擬地址映射的基本單位是頁面不是字節,一個虛擬內存的頁面會被映射到一個物理頁幀上。MMU把虛擬地址轉換為物理地址的方法是通過查找頁表。一個頁表的大小也是一個頁面,4K大小,頁表的內容可以看做是頁表項的數組,一個頁表項是一個物理地址,指向一個物理頁幀,在32位系統上,物理地址是32位也就是4個字節,所以一個頁表有4K/4=1024項,每一項指向一個物理頁幀,大小是4K,所以一個頁表可以表達4M的虛擬內存,要想表達4G的虛擬內存空間,需要有1024個頁表才行,每個頁表4K,一共需要4M的物理內存。4M的物理內存看起來好像不大,但是每個進程都需要有4M的物理內存做頁表,如果有100個進程,那就需要有400M物理內存,這就太浪費物理內存了,而且大部分時候,一個進程的大部分虛擬內存空間并沒有使用。為此我們可以采取兩級頁表的方法來進行虛擬內存映射。在多級頁表體系中,最后一級頁表還叫頁表,其它的頁表叫做頁目錄,但是我們有時候也會都叫做頁表。對于兩級頁表體系,一級頁表還是一個頁面,4K大小,每個頁表項還是4個字節,一共有1024項,一級頁表的頁表項是二級頁表的物理地址,指向二級頁表,二級頁表的內容和前面一樣。一級頁表只有一個,4K,有1024項,指向1024個二級頁表,一個一級頁表項也就是一個二級頁表可以表達4M虛擬內存,一級頁表總共能表達4G虛擬內存,此時所有頁表占用的物理內存是4M加4K。看起來使用二級頁表好像還多用了4K內存,但是在大多數情況下,很多二級頁表都用不上,所以不用分配內存。如果一個進程只用了8M物理內存,那么它只需要一個一級頁表和兩個二級頁表就行了,一級頁表中只需要使用兩項指向兩個二級頁表,兩個二級頁表填充滿,就可以表達8M虛擬內存映射了,此時總共用了3個頁表,12K物理內存,頁表的內存占用大大減少了。所以在32位系統上,采取的是兩級頁表的方式,每級的一個頁表都是1024項,32位虛擬地址正好可以分成三份,10、10、12,第一個10位可以用于在一級頁表中尋址,第二個10位在二級頁表中尋址,最后12位可以表達一個頁面中任何一個字節。
在64位系統上,一個頁面還是4K大小,一個頁表還是一個頁面,但是由于物理地址是64位的,所以一個頁表項變成了8個字節,一個頁表就只有512個頁表項了,這樣一個頁表就只能表達2M虛擬內存了。尋址512個頁表項只需要9位就夠了。在x86 64上,虛擬地址有64位,但是64位的地址空間實在是太大了,所以我們只需要用其中一部分就行了。x86 64上有兩種虛擬地址位數可選,48位和57位,分別對應著四級頁表和五級頁表。為啥是四級頁表和五級頁表呢?因為48=9+9+9+12,57=9+9+9+9+12,12可以尋址一個頁面內的每一個字節,9可以尋址一級頁表中的512個頁表項。
Linux內核最多支持五級頁表,在五級頁表體系中,每一級頁表分別叫做PGD、P4D、PUD、PMD、PTE。如果頁表不夠五級的,從第二級開始依次去掉一級。
頁表項是下一級頁表或者最終頁幀的物理地址,頁表也是一個頁幀,頁幀的地址都是4K對齊的,所以頁表項中的物理地址的最后12位一定都是0,既然都是0,那么就沒必要表示出來了,我們就可以把這12位拿來做其它用途了。下面我們來看一下x86的頁表項格式。

這是32位的頁表項格式,其中12-31位是物理地址。
P,此頁表項是否有效,1代表有效,0代表無效,為0時其它字段無意義。
R/W,0代表只讀,1代表可讀寫。
U/S,0代表內核頁表,1代表用戶頁面。
PWT,Page-level write-through
PCD,Page-level cache disable
A,Accessed; indicates whether software has accessed the page
D,Dirty; indicates whether software has written to the ?page
PAT,If the PAT is supported, indirectly determines the memory type used to access the page
G,Global; determines whether the translation is global
64位系統的頁表項格式和這個是一樣的,只不過是物理地址擴展到了硬件支持的最高物理地址位數。
6.2 MMU
MMU是通過遍歷頁表把虛擬地址轉換為物理地址的。其過程如下所示:
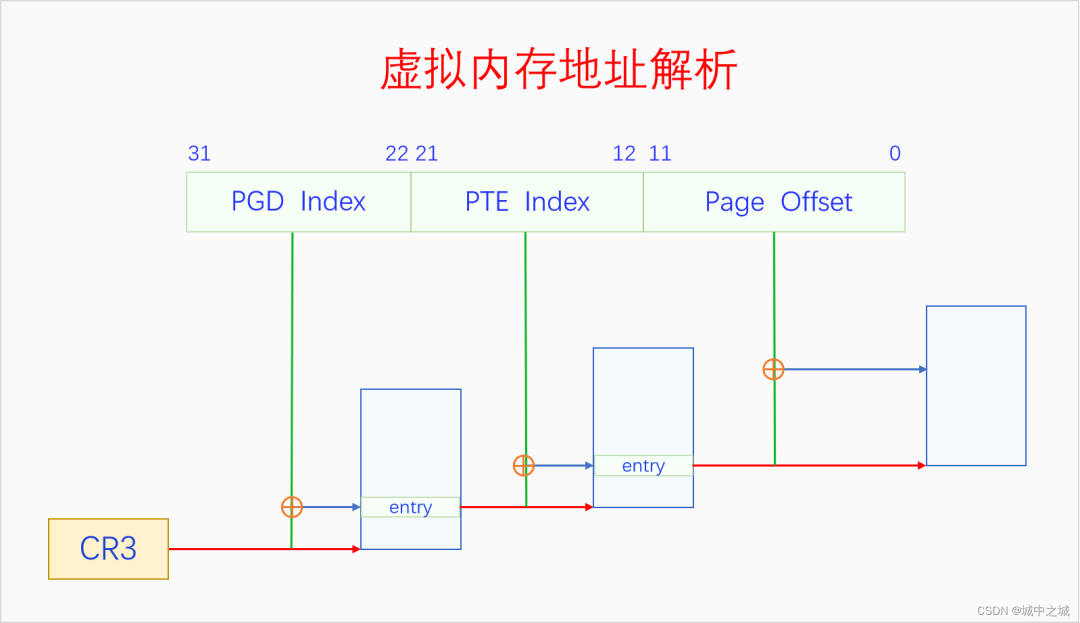
CR3是CPU的寄存器,存放的是PGD的物理地址。MMU首先通過CR3獲取PGD的物理地址,然后以虛擬地址的31-22位為index,在PGD中找到相應的頁表項,先檢測頁表項的P是否存在,R/W是否有讀寫權限,U/S是否有訪問權限,如果檢測都通過了,則進入下一步,如果沒通過則觸發缺頁異常。關于中斷與異常的基本原理請參看《深入理解Linux中斷機制》。如果檢測通過了,頁表項的31-12位代表PTE的物理地址,取虛擬地址中的21-12位作為index,在PTE中找到對應的頁表項,也是先各種檢測,如果沒通過則觸發缺頁異常。如果通過了,則31-12位代表最終頁幀的物理地址,然后把虛擬地址的11-0位作為頁內偏移加上去,就找到了虛擬地址對應的物理地址了,然后送到MC進行訪問。64位系統的邏輯和32位是相似的,只不過是多了幾級頁表而已,就不再贅述了。
一個進程的所有頁表通過頁表項的指向構成了一個頁表樹,頁表樹的根節點是PGD,根指針是CR3。頁表樹中所有的地址都是物理地址,MMU在遍歷頁表樹時使用物理地址可以直接訪問內存。一個頁表只有加入了某個頁表樹才有意義,孤立的頁表是沒有意義的。每個進程都有一個頁表樹,切換進程就會切換頁表樹,切換頁表樹的方法是給CR3賦值,讓其指向當前進程的頁表樹的根節點也就是PGD。進程的虛擬內存空間分為兩部分,內核空間和用戶空間,所有進程的內核空間都是共享的,所以所有進程的頁表樹根節點的內核子樹都相同。
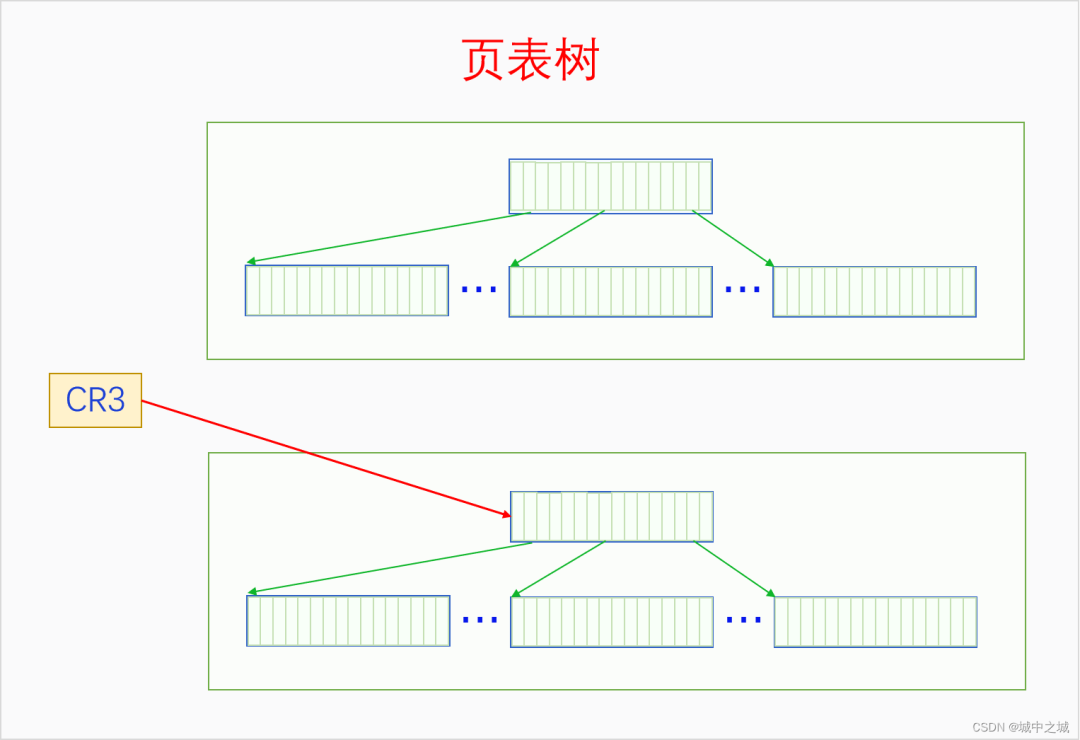
6.3 缺頁異常
MMU在解析虛擬內存時如果發現了讀寫錯誤或者權限錯誤或者頁表項無效,就會觸發缺頁異常讓內核來處理。下面我們來看一下x86的缺頁異常處理的過程。linux-src/arch/x86/mm/fault.c
DEFINE_IDTENTRY_RAW_ERRORCODE(exc_page_fault)
{
?unsigned?long?address?=?read_cr2();
?irqentry_state_t?state;
?prefetchw(¤t->mm->mmap_lock);
?if?(kvm_handle_async_pf(regs,?(u32)address))
??return;
?state?=?irqentry_enter(regs);
?instrumentation_begin();
?handle_page_fault(regs,?error_code,?address);
?instrumentation_end();
?irqentry_exit(regs,?state);
}
static?__always_inline?void
handle_page_fault(struct?pt_regs?*regs,?unsigned?long?error_code,
?????????unsigned?long?address)
{
?trace_page_fault_entries(regs,?error_code,?address);
?if?(unlikely(kmmio_fault(regs,?address)))
??return;
?/*?Was?the?fault?on?kernel-controlled?part?of?the?address?space??*/
?if?(unlikely(fault_in_kernel_space(address)))?{
??do_kern_addr_fault(regs,?error_code,?address);
?}?else?{
??do_user_addr_fault(regs,?error_code,?address);
??/*
???*?User?address?page?fault?handling?might?have?reenabled
???*?interrupts.?Fixing?up?all?potential?exit?points?of
???*?do_user_addr_fault()?and?its?leaf?functions?is?just?not
???*?doable?w/o?creating?an?unholy?mess?or?turning?the?code
???*?upside?down.
???*/
??local_irq_disable();
?}
}
static?void
do_kern_addr_fault(struct?pt_regs?*regs,?unsigned?long?hw_error_code,
?????unsigned?long?address)
{
?WARN_ON_ONCE(hw_error_code?&?X86_PF_PK);
#ifdef?CONFIG_X86_32
?if?(!(hw_error_code?&?(X86_PF_RSVD?|?X86_PF_USER?|?X86_PF_PROT)))?{
??if?(vmalloc_fault(address)?>=?0)
???return;
?}
#endif
?if?(is_f00f_bug(regs,?hw_error_code,?address))
??return;
?/*?Was?the?fault?spurious,?caused?by?lazy?TLB?invalidation??*/
?if?(spurious_kernel_fault(hw_error_code,?address))
??return;
?/*?kprobes?don't?want?to?hook?the?spurious?faults:?*/
?if?(WARN_ON_ONCE(kprobe_page_fault(regs,?X86_TRAP_PF)))
??return;
?bad_area_nosemaphore(regs,?hw_error_code,?address);
}
static?inline
void?do_user_addr_fault(struct?pt_regs?*regs,
???unsigned?long?error_code,
???unsigned?long?address)
{
?struct?vm_area_struct?*vma;
?struct?task_struct?*tsk;
?struct?mm_struct?*mm;
?vm_fault_t?fault;
?unsigned?int?flags?=?FAULT_FLAG_DEFAULT;
?tsk?=?current;
?mm?=?tsk->mm;
?if?(unlikely((error_code?&?(X86_PF_USER?|?X86_PF_INSTR))?==?X86_PF_INSTR))?{
??/*
???*?Whoops,?this?is?kernel?mode?code?trying?to?execute?from
???*?user?memory.??Unless?this?is?AMD?erratum?#93,?which
???*?corrupts?RIP?such?that?it?looks?like?a?user?address,
???*?this?is?unrecoverable.??Don't?even?try?to?look?up?the
???*?VMA?or?look?for?extable?entries.
???*/
??if?(is_errata93(regs,?address))
???return;
??page_fault_oops(regs,?error_code,?address);
??return;
?}
?/*?kprobes?don't?want?to?hook?the?spurious?faults:?*/
?if?(WARN_ON_ONCE(kprobe_page_fault(regs,?X86_TRAP_PF)))
??return;
?/*
??*?Reserved?bits?are?never?expected?to?be?set?on
??*?entries?in?the?user?portion?of?the?page?tables.
??*/
?if?(unlikely(error_code?&?X86_PF_RSVD))
??pgtable_bad(regs,?error_code,?address);
?/*
??*?If?SMAP?is?on,?check?for?invalid?kernel?(supervisor)?access?to?user
??*?pages?in?the?user?address?space.??The?odd?case?here?is?WRUSS,
??*?which,?according?to?the?preliminary?documentation,?does?not?respect
??*?SMAP?and?will?have?the?USER?bit?set?so,?in?all?cases,?SMAP
??*?enforcement?appears?to?be?consistent?with?the?USER?bit.
??*/
?if?(unlikely(cpu_feature_enabled(X86_FEATURE_SMAP)?&&
???????!(error_code?&?X86_PF_USER)?&&
???????!(regs->flags?&?X86_EFLAGS_AC)))?{
??/*
???*?No?extable?entry?here.??This?was?a?kernel?access?to?an
???*?invalid?pointer.??get_kernel_nofault()?will?not?get?here.
???*/
??page_fault_oops(regs,?error_code,?address);
??return;
?}
?/*
??*?If?we're?in?an?interrupt,?have?no?user?context?or?are?running
??*?in?a?region?with?pagefaults?disabled?then?we?must?not?take?the?fault
??*/
?if?(unlikely(faulthandler_disabled()?||?!mm))?{
??bad_area_nosemaphore(regs,?error_code,?address);
??return;
?}
?/*
??*?It's?safe?to?allow?irq's?after?cr2?has?been?saved?and?the
??*?vmalloc?fault?has?been?handled.
??*
??*?User-mode?registers?count?as?a?user?access?even?for?any
??*?potential?system?fault?or?CPU?buglet:
??*/
?if?(user_mode(regs))?{
??local_irq_enable();
??flags?|=?FAULT_FLAG_USER;
?}?else?{
??if?(regs->flags?&?X86_EFLAGS_IF)
???local_irq_enable();
?}
?perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS,?1,?regs,?address);
?if?(error_code?&?X86_PF_WRITE)
??flags?|=?FAULT_FLAG_WRITE;
?if?(error_code?&?X86_PF_INSTR)
??flags?|=?FAULT_FLAG_INSTRUCTION;
#ifdef?CONFIG_X86_64
?/*
??*?Faults?in?the?vsyscall?page?might?need?emulation.??The
??*?vsyscall?page?is?at?a?high?address?(>PAGE_OFFSET),?but?is
??*?considered?to?be?part?of?the?user?address?space.
??*
??*?The?vsyscall?page?does?not?have?a?"real"?VMA,?so?do?this
??*?emulation?before?we?go?searching?for?VMAs.
??*
??*?PKRU?never?rejects?instruction?fetches,?so?we?don't?need
??*?to?consider?the?PF_PK?bit.
??*/
?if?(is_vsyscall_vaddr(address))?{
??if?(emulate_vsyscall(error_code,?regs,?address))
???return;
?}
#endif
?/*
??*?Kernel-mode?access?to?the?user?address?space?should?only?occur
??*?on?well-defined?single?instructions?listed?in?the?exception
??*?tables.??But,?an?erroneous?kernel?fault?occurring?outside?one?of
??*?those?areas?which?also?holds?mmap_lock?might?deadlock?attempting
??*?to?validate?the?fault?against?the?address?space.
??*
??*?Only?do?the?expensive?exception?table?search?when?we?might?be?at
??*?risk?of?a?deadlock.??This?happens?if?we
??*?1.?Failed?to?acquire?mmap_lock,?and
??*?2.?The?access?did?not?originate?in?userspace.
??*/
?if?(unlikely(!mmap_read_trylock(mm)))?{
??if?(!user_mode(regs)?&&?!search_exception_tables(regs->ip))?{
???/*
????*?Fault?from?code?in?kernel?from
????*?which?we?do?not?expect?faults.
????*/
???bad_area_nosemaphore(regs,?error_code,?address);
???return;
??}
retry:
??mmap_read_lock(mm);
?}?else?{
??/*
???*?The?above?down_read_trylock()?might?have?succeeded?in
???*?which?case?we'll?have?missed?the?might_sleep()?from
???*?down_read():
???*/
??might_sleep();
?}
?vma?=?find_vma(mm,?address);
?if?(unlikely(!vma))?{
??bad_area(regs,?error_code,?address);
??return;
?}
?if?(likely(vma->vm_start?<=?address))
??goto?good_area;
?if?(unlikely(!(vma->vm_flags?&?VM_GROWSDOWN)))?{
??bad_area(regs,?error_code,?address);
??return;
?}
?if?(unlikely(expand_stack(vma,?address)))?{
??bad_area(regs,?error_code,?address);
??return;
?}
?/*
??*?Ok,?we?have?a?good?vm_area?for?this?memory?access,?so
??*?we?can?handle?it..
??*/
good_area:
?if?(unlikely(access_error(error_code,?vma)))?{
??bad_area_access_error(regs,?error_code,?address,?vma);
??return;
?}
?/*
??*?If?for?any?reason?at?all?we?couldn't?handle?the?fault,
??*?make?sure?we?exit?gracefully?rather?than?endlessly?redo
??*?the?fault.??Since?we?never?set?FAULT_FLAG_RETRY_NOWAIT,?if
??*?we?get?VM_FAULT_RETRY?back,?the?mmap_lock?has?been?unlocked.
??*
??*?Note?that?handle_userfault()?may?also?release?and?reacquire?mmap_lock
??*?(and?not?return?with?VM_FAULT_RETRY),?when?returning?to?userland?to
??*?repeat?the?page?fault?later?with?a?VM_FAULT_NOPAGE?retval
??*?(potentially?after?handling?any?pending?signal?during?the?return?to
??*?userland).?The?return?to?userland?is?identified?whenever
??*?FAULT_FLAG_USER|FAULT_FLAG_KILLABLE?are?both?set?in?flags.
??*/
?fault?=?handle_mm_fault(vma,?address,?flags,?regs);
?if?(fault_signal_pending(fault,?regs))?{
??/*
???*?Quick?path?to?respond?to?signals.??The?core?mm?code
???*?has?unlocked?the?mm?for?us?if?we?get?here.
???*/
??if?(!user_mode(regs))
???kernelmode_fixup_or_oops(regs,?error_code,?address,
???????SIGBUS,?BUS_ADRERR,
???????ARCH_DEFAULT_PKEY);
??return;
?}
?/*
??*?If?we?need?to?retry?the?mmap_lock?has?already?been?released,
??*?and?if?there?is?a?fatal?signal?pending?there?is?no?guarantee
??*?that?we?made?any?progress.?Handle?this?case?first.
??*/
?if?(unlikely((fault?&?VM_FAULT_RETRY)?&&
???????(flags?&?FAULT_FLAG_ALLOW_RETRY)))?{
??flags?|=?FAULT_FLAG_TRIED;
??goto?retry;
?}
?mmap_read_unlock(mm);
?if?(likely(!(fault?&?VM_FAULT_ERROR)))
??return;
?if?(fatal_signal_pending(current)?&&?!user_mode(regs))?{
??kernelmode_fixup_or_oops(regs,?error_code,?address,
??????0,?0,?ARCH_DEFAULT_PKEY);
??return;
?}
?if?(fault?&?VM_FAULT_OOM)?{
??/*?Kernel?mode??Handle?exceptions?or?die:?*/
??if?(!user_mode(regs))?{
???kernelmode_fixup_or_oops(regs,?error_code,?address,
???????SIGSEGV,?SEGV_MAPERR,
???????ARCH_DEFAULT_PKEY);
???return;
??}
??/*
???*?We?ran?out?of?memory,?call?the?OOM?killer,?and?return?the
???*?userspace?(which?will?retry?the?fault,?or?kill?us?if?we?got
???*?oom-killed):
???*/
??pagefault_out_of_memory();
?}?else?{
??if?(fault?&?(VM_FAULT_SIGBUS|VM_FAULT_HWPOISON|
????????VM_FAULT_HWPOISON_LARGE))
???do_sigbus(regs,?error_code,?address,?fault);
??else?if?(fault?&?VM_FAULT_SIGSEGV)
???bad_area_nosemaphore(regs,?error_code,?address);
??else
???BUG();
?}
}
缺頁異常首先從CR2寄存器中讀取發生異常的虛擬內存地址。然后根據此地址是在內核空間還是在用戶空間,分別調用do_kern_addr_fault和do_user_addr_fault來處理。使用vmalloc時會出現內核空間的缺頁異常。用戶空間地址的缺頁異常在做完各種檢測處理之后會調用所有架構都通用的函數handle_mm_fault來處理。下面我們來看一下這個函數是怎么處理的。linux-src/mm/memory.c
vm_fault_t?handle_mm_fault(struct?vm_area_struct?*vma,?unsigned?long?address,
??????unsigned?int?flags,?struct?pt_regs?*regs)
{
?vm_fault_t?ret;
?__set_current_state(TASK_RUNNING);
?if?(!arch_vma_access_permitted(vma,?flags?&?FAULT_FLAG_WRITE,
?????????flags?&?FAULT_FLAG_INSTRUCTION,
?????????flags?&?FAULT_FLAG_REMOTE))
??return?VM_FAULT_SIGSEGV;
?if?(flags?&?FAULT_FLAG_USER)
??mem_cgroup_enter_user_fault();
?if?(unlikely(is_vm_hugetlb_page(vma)))
??ret?=?hugetlb_fault(vma->vm_mm,?vma,?address,?flags);
?else
??ret?=?__handle_mm_fault(vma,?address,?flags);
?return?ret;
}
static?vm_fault_t?__handle_mm_fault(struct?vm_area_struct?*vma,
??unsigned?long?address,?unsigned?int?flags)
{
?struct?vm_fault?vmf?=?{
??.vma?=?vma,
??.address?=?address?&?PAGE_MASK,
??.flags?=?flags,
??.pgoff?=?linear_page_index(vma,?address),
??.gfp_mask?=?__get_fault_gfp_mask(vma),
?};
?unsigned?int?dirty?=?flags?&?FAULT_FLAG_WRITE;
?struct?mm_struct?*mm?=?vma->vm_mm;
?pgd_t?*pgd;
?p4d_t?*p4d;
?vm_fault_t?ret;
?pgd?=?pgd_offset(mm,?address);
?p4d?=?p4d_alloc(mm,?pgd,?address);
?if?(!p4d)
??return?VM_FAULT_OOM;
?vmf.pud?=?pud_alloc(mm,?p4d,?address);
?return?handle_pte_fault(&vmf);
}
static?vm_fault_t?handle_pte_fault(struct?vm_fault?*vmf)
{
?pte_t?entry;
?if?(!vmf->pte)?{
??if?(vma_is_anonymous(vmf->vma))
???return?do_anonymous_page(vmf);
??else
???return?do_fault(vmf);
?}
?if?(!pte_present(vmf->orig_pte))
??return?do_swap_page(vmf);
?if?(pte_protnone(vmf->orig_pte)?&&?vma_is_accessible(vmf->vma))
??return?do_numa_page(vmf);
?vmf->ptl?=?pte_lockptr(vmf->vma->vm_mm,?vmf->pmd);
?spin_lock(vmf->ptl);
?entry?=?vmf->orig_pte;
?if?(unlikely(!pte_same(*vmf->pte,?entry)))?{
??update_mmu_tlb(vmf->vma,?vmf->address,?vmf->pte);
??goto?unlock;
?}
?if?(vmf->flags?&?FAULT_FLAG_WRITE)?{
??if?(!pte_write(entry))
???return?do_wp_page(vmf);
??entry?=?pte_mkdirty(entry);
?}
?entry?=?pte_mkyoung(entry);
?if?(ptep_set_access_flags(vmf->vma,?vmf->address,?vmf->pte,?entry,
????vmf->flags?&?FAULT_FLAG_WRITE))?{
??update_mmu_cache(vmf->vma,?vmf->address,?vmf->pte);
?}?else?{
??if?(vmf->flags?&?FAULT_FLAG_TRIED)
???goto?unlock;
??if?(vmf->flags?&?FAULT_FLAG_WRITE)
???flush_tlb_fix_spurious_fault(vmf->vma,?vmf->address);
?}
unlock:
?pte_unmap_unlock(vmf->pte,?vmf->ptl);
?return?0;
}
static?vm_fault_t?do_fault(struct?vm_fault?*vmf)
{
?struct?vm_area_struct?*vma?=?vmf->vma;
?struct?mm_struct?*vm_mm?=?vma->vm_mm;
?vm_fault_t?ret;
?if?(!vma->vm_ops->fault)?{
??if?(unlikely(!pmd_present(*vmf->pmd)))
???ret?=?VM_FAULT_SIGBUS;
??else?{
???vmf->pte?=?pte_offset_map_lock(vmf->vma->vm_mm,
?????????????vmf->pmd,
?????????????vmf->address,
?????????????&vmf->ptl);
???if?(unlikely(pte_none(*vmf->pte)))
????ret?=?VM_FAULT_SIGBUS;
???else
????ret?=?VM_FAULT_NOPAGE;
???pte_unmap_unlock(vmf->pte,?vmf->ptl);
??}
?}?else?if?(!(vmf->flags?&?FAULT_FLAG_WRITE))
??ret?=?do_read_fault(vmf);
?else?if?(!(vma->vm_flags?&?VM_SHARED))
??ret?=?do_cow_fault(vmf);
?else
??ret?=?do_shared_fault(vmf);
?if?(vmf->prealloc_pte)?{
??pte_free(vm_mm,?vmf->prealloc_pte);
??vmf->prealloc_pte?=?NULL;
?}
?return?ret;
}
可以看到handle_mm_fault最終會調用handle_pte_fault進行處理。在handle_pte_fault中,會根據缺頁的內存的類型進行相應的處理。
七、虛擬內存空間
CPU開啟了分頁內存機制之后,就只能通過虛擬內存來訪問內存了。內核通過構建頁表樹來創建虛擬內存空間,一個頁表樹對應一個虛擬內存空間。虛擬內存空間又分為兩部分,內核空間和用戶空間。所有的頁表樹都共享內核空間,它們內核頁表子樹是相同的。內核空間和用戶空間不僅在數量上不同,在權限上不同,在構建方式上也不同。內核空間在系統全局都只有一個,不僅在UP上是如此,在SMP上也是只有一個,多個CPU共享同一個內核空間。內核空間是特權空間,可以執行所有的操作,也可以訪問用戶空間。用戶空間是非特權空間,很多操作不能做,也不能隨意訪問內核,唯一能訪問內核的方式就是通過系統調用。內核空間和用戶空間最大的不同是構建方式。內核空間是在系統啟動時就構建好的,是完整構建的,物理內存和虛擬內存是直接一次就映射好的,而且是不會銷毀的,因為系統運行著內核就要一直存在。用戶空間是在創建進程時構建的,但是并沒有完整構建,虛擬內存到物理內存的映射是隨著進程的運行通過觸發缺頁異常一步一步構建的,而且在內存回收時還有可能被解除映射,最后隨著進程的死亡,用戶空間還會被銷毀。下面我們看個圖:
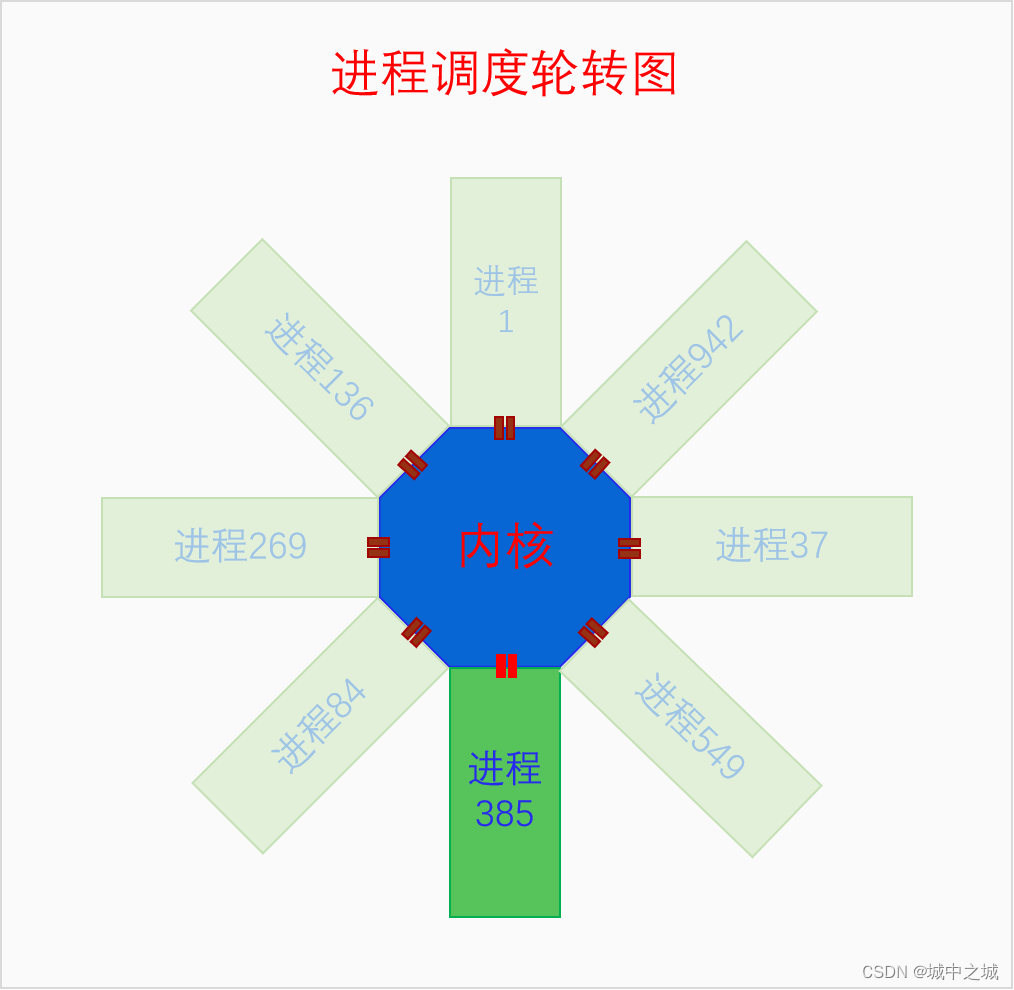
這個圖是在講進程調度時畫的圖,但是也能表明內核空間和用戶空間的關系。下面我們再來看一下單個進程角度下內核空間與用戶空間的關系圖。
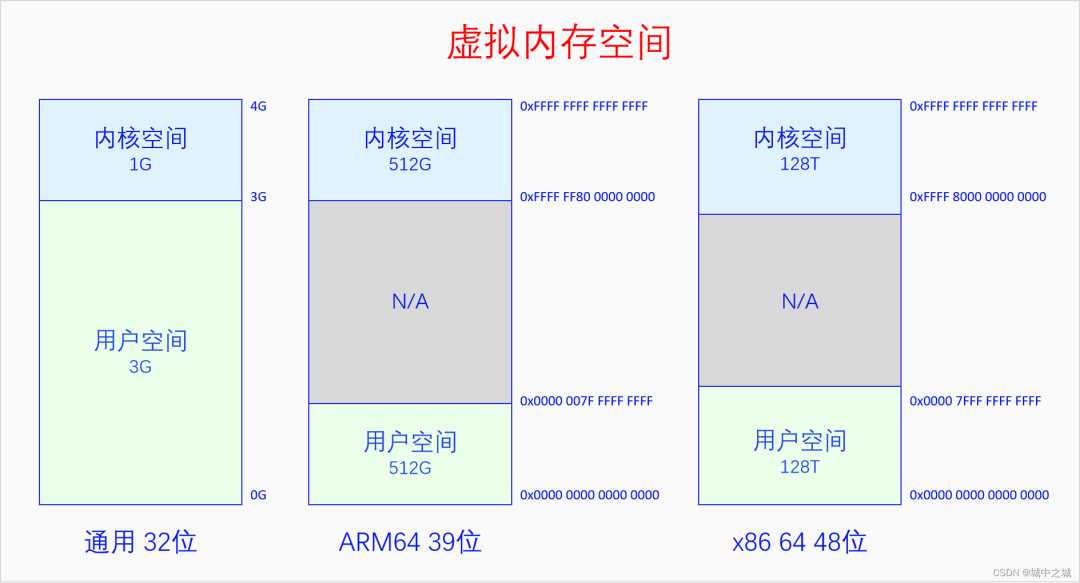
在32位系統上默認是內核占據上面1G虛擬空間,進程占據下面3G虛擬空間,有config選項可以選擇其它比列,所有CPU架構都是如此。在64位系統上,由于64位的地址空間實在是太大了,Linux并沒有使用全部的虛擬內存空間,而是只使用其中一部分位數。使用的方法是把用戶空間的高位補0,內核空間的高位補1,這樣從64位地址空間的角度來看就是只使用了兩段,中間留空,方便以后往中間擴展。中間留空的是非法內存空間,不能使用。具體使用多少位,高位如何補0,不同架構的選擇是不同的。ARM64在4K頁面大小的情況下有39位和48位兩種虛擬地址空間的選擇。X86 64有48位和57位兩種虛擬地址空間的選擇。ARM64是內核空間和用戶空間都有這么多的地址空間,x86 64是內核空間和用戶空間平分這么多的地址空間,上圖中的大小也可以反應出這一點。
7.1 內核空間
系統在剛啟動時肯定不可能直接就運行在虛擬內存之上。系統是先運行在物理內存上,然后去建立一部分恒等映射,恒等映射就是虛擬內存的地址和物理內存的地址相同的映射。恒等映射的范圍不是要覆蓋全部的物理內存,而是夠當時內核的運行就可以了。恒等映射建立好之后就會開啟分頁機制,此時CPU就運行在虛擬內存上了。然后內核再進一步構建頁表,把內核映射到其規定好的地方。最后內核跳轉到其目標虛擬地址的地方運行,并把之前的恒等映射取消掉,現在內核就完全運行在虛擬內存上了。
由于內核是最先運行的,內核會把物理內存線性映射到自己的空間中去,而且是要把所有的物理內存都映射到內核空間。如果內核沒有把全部物理內存都映射到內核空間,那不是因為不想,而是因為做不到。在x86 32上,內核空間只有1G,扣除一些其它用途保留的128M空間,內核能線性映射的空間只有896M,而物理內存可以多達4G,是沒法都映射到內核空間的。所以內核會把小于896M的物理內存都映射到內核空間,大于896M的物理內存作為高端內存,可以動態映射到內核的vmalloc區。對于64位系統,就不存在這個煩惱了,虛擬內存空間遠遠大于物理內存的數量,所以內核會一下子把全部物理內存都映射到內核空間。
大家在這里可能有兩個誤解:一是認為物理內存映射就代表使用,不使用就不會映射,這是不對的,使用時肯定要映射,但是映射了不代表在使用,映射了可以先放在那,只有被內存分配器分配出去的才算是被使用;二是物理內存只會被內核空間或者用戶空間兩者之一映射,誰使用了就映射到誰的空間中去,這也是不對的,對于用戶空間,只有其使用了物理內存才會去映射,但是對于內核空間,內核空間是管理者,它把所有物理內存都映射到自己的空間比較方便管理,而且映射了不代表使用。
64位和32位還有一個很大的不同。32位上是把小于896M的物理內存都線性映射到從3G開始的內核空間中去,32位上只有一個線性映射區間。64位上有兩個線性映射區間,一是把內核代碼和數據所在的物理內存映射到一個固定的地址區間中去,二是把所有物理內存都映射到某一段內存區間中去,顯然內核本身所占用的物理內存被映射了兩次。下面我們畫圖來看一看內核空間的布局。
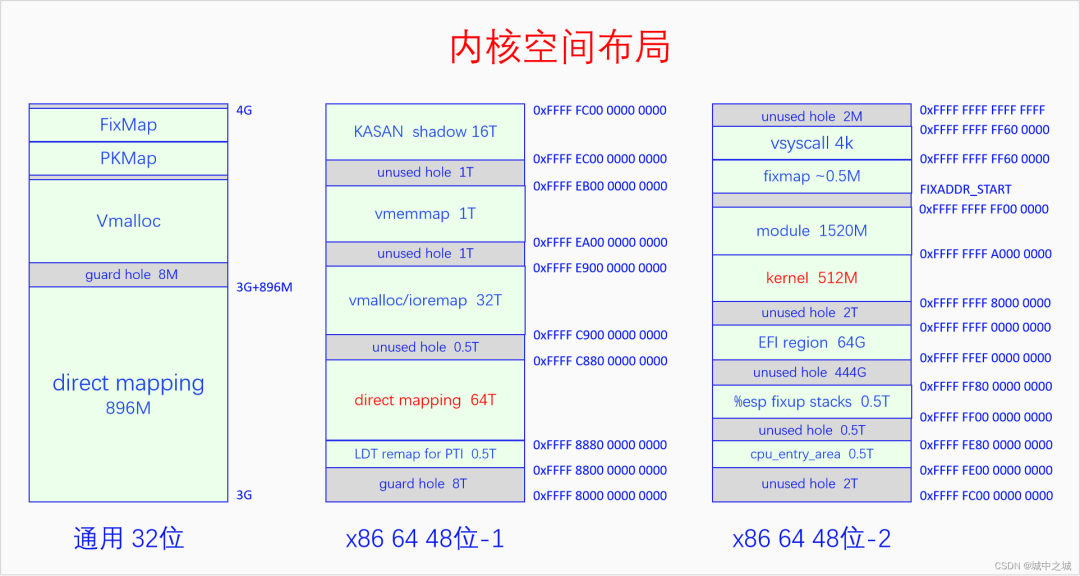
32位的內核空間布局比較簡單,前896M是直接映射區,后面是8M的的隔離區,然后是大約100多M的vmalloc區,再后面是持久映射區和固定映射區,其位置和大小是由宏決定的。
64位的內核空間布局比較復雜,而且不同的架構之間差異非常大,我們以x86 64 48位虛擬地址為例說一下。圖中一列畫不下,分成了兩列,我們從48位-1看起,首先是由一個8T的空洞,然后是LDT remap,然后是直接映射區有64T,用來映射所有的物理內存,目前來說對于絕大部分計算機都夠用了,然后是0.5T的空洞,然后是vmalloc和ioremap區有32T,然后是1T的空洞,然后是vmemmap區有1T,vmemmap就是我們前面所講的所有頁面描述符的數組,然后是1T的空洞,然后是KASAN的影子內存有16T,緊接著再看48位-2,首先是2T的空洞,然后是cpu_entry_area,然后是0.5T的空洞,然后是%esp fixup stack,然后是444G的空洞,然后是EFI的映射區域,然后是2T的空洞,然后是內核的映射區有512M,然后是ko的映射區有1520M,然后是fixmap和vsyscall,最后是2M的空洞。如果開啟了kaslr,內核和映射區會增加512M,相應的ko的映射區會減少512M。
64位的內核空間中有直接映射區和內核映射區兩個線性映射區,這兩個區域都是線性映射,只不過是映射的起點不同。為什么要把內核再單獨映射一遍呢?而且既然直接映射區已經把所有的物理內存都映射一遍了,那么為什么還有這么多的內存映射區呢?直接映射區的存在是為了方便管理物理內存,因為它和物理內存只差一個固定值。各種其它映射區的存在是為了方便內核的運行和使用。比如vmalloc區是為了方便進行隨機映射,當內存碎片化比較嚴重,我們需要的內存又不要求物理上必須連續時,就可以使用vmalloc,它能把物理上不連續的內存映射到連續的虛擬內存上。vmemmap區域是為了在物理內存有較大空洞時,又能夠使得memmap在虛擬內存上看起來是個完整的數組。這些都方便了內核的操作。
對比32位和64位的虛擬內存空間可以發現,空間大了就是比較闊綽,動不動就來個1T、2T的空洞。
7.2 用戶空間
用戶空間的邏輯和內核空間就完全不同了。首先用戶空間是進程創建時動態創建的。其次,對于內核,虛擬內存和物理內存是提前映射好的,就算是vmalloc,也是分配時就映射好的,對于用戶空間,物理內存的分配和虛擬內存的分配是割裂的,用戶空間總是先分配虛擬內存不分配物理內存,物理內存總是拖到最后一刻才去分配。而且對于進程本身來說,它只能分配虛擬內存,物理內存的分配對它來說是不可見的,或者說是透明的。當進程去使用某一個虛擬內存時如果發現還沒有分配物理內存則會觸發缺頁異常,此時才會去分配物理內存并映射上,然后再去重新執行剛才的指令,這一切對進程來說都是透明的,進程感知不到。
管理進程空間的結構體是mm_struct,我們先來看一下(代碼有所刪減):linux-src/include/linux/mm_types.h
struct?mm_struct?{
?struct?{
??struct?vm_area_struct?*mmap;??/*?list?of?VMAs?*/
??struct?rb_root?mm_rb;
??u64?vmacache_seqnum;???????????????????/*?per-thread?vmacache?*/
#ifdef?CONFIG_MMU
??unsigned?long?(*get_unmapped_area)?(struct?file?*filp,
????unsigned?long?addr,?unsigned?long?len,
????unsigned?long?pgoff,?unsigned?long?flags);
#endif
??unsigned?long?mmap_base;?/*?base?of?mmap?area?*/
??unsigned?long?mmap_legacy_base;?/*?base?of?mmap?area?in?bottom-up?allocations?*/
??unsigned?long?task_size;?/*?size?of?task?vm?space?*/
??unsigned?long?highest_vm_end;?/*?highest?vma?end?address?*/
??pgd_t?*?pgd;
??atomic_t?mm_users;
??atomic_t?mm_count;
#ifdef?CONFIG_MMU
??atomic_long_t?pgtables_bytes;?/*?PTE?page?table?pages?*/
#endif
??int?map_count;???/*?number?of?VMAs?*/
??spinlock_t?page_table_lock;?
??struct?rw_semaphore?mmap_lock;
??struct?list_head?mmlist;?
??unsigned?long?hiwater_rss;?/*?High-watermark?of?RSS?usage?*/
??unsigned?long?hiwater_vm;??/*?High-water?virtual?memory?usage?*/
??unsigned?long?total_vm;????/*?Total?pages?mapped?*/
??unsigned?long?locked_vm;???/*?Pages?that?have?PG_mlocked?set?*/
??atomic64_t????pinned_vm;???/*?Refcount?permanently?increased?*/
??unsigned?long?data_vm;????/*?VM_WRITE?&?~VM_SHARED?&?~VM_STACK?*/
??unsigned?long?exec_vm;????/*?VM_EXEC?&?~VM_WRITE?&?~VM_STACK?*/
??unsigned?long?stack_vm;????/*?VM_STACK?*/
??unsigned?long?def_flags;
??unsigned?long?start_code,?end_code,?start_data,?end_data;
??unsigned?long?start_brk,?brk,?start_stack;
??unsigned?long?arg_start,?arg_end,?env_start,?env_end;
??unsigned?long?saved_auxv[AT_VECTOR_SIZE];?/*?for?/proc/PID/auxv?*/
?
??struct?mm_rss_stat?rss_stat;
??struct?linux_binfmt?*binfmt;
??mm_context_t?context;
??unsigned?long?flags;?/*?Must?use?atomic?bitops?to?access?*/
??struct?core_state?*core_state;?/*?coredumping?support?*/
??struct?user_namespace?*user_ns;
??/*?store?ref?to?file?/proc//exe?symlink?points?to?*/
??struct?file?__rcu?*exe_file;
?}?__randomize_layout;
?unsigned?long?cpu_bitmap[];
};
可以看到mm_struct有很多管理數據,其中最重要的兩個是mmap和pgd,它們一個代表虛擬內存的分配情況,一個代表物理內存的分配情況。pgd就是我們前面所說的頁表樹的根指針,當要運行我們的進程時就需要把pgd寫到CR3上,這樣MMU用我們頁表樹來解析虛擬地址就能訪問到我們的物理內存了。不過pgd的值是虛擬內存,CR3需要物理內存,所以把pgd寫到CR3上時還需要把pgd轉化為物理地址。mmap是vm_area_struct(vma)的鏈表,它代表的是用戶空間虛擬內存的分配情況。用戶空間只能分配虛擬內存,物理內存的分配是自動的透明的。用戶空間想要分配虛擬內存,最終的唯一的方法就是調用函數mmap來生成一個vma,有了vma就代表虛擬內存分配了,vma會記錄虛擬內存的起點、大小和權限等信息。有了vma,缺頁異常在處理時就有了依據。如果造成缺頁異常的虛擬地址不再任何vma的區間中,則說明這是一個非法的虛擬地址,缺頁異常就會給進程發SIGSEGV。如果異常地址在某個vma區間中并且權限也對的話,那么說明這個虛擬地址進程已經分配了,是個合法的虛擬地址,此時缺頁異常就會去分配物理內存并映射到虛擬內存上。
調用函數mmap生成vma的方式有兩種,一是內核為進程調用,就是在內核里直接調用了,二是進程自己調用,那就是通過系統調用來調用mmap了。生成的vma也有兩種類型,文件映射vma和匿名映射vma,哪種類型取決于mmap的參數。文件映射vma,在發生缺頁異常時,分配的物理內存要用文件的內容來初始化,其物理內存也被叫做文件頁。匿名映射vma,在發生缺頁異常時,直接分配物理內存并初始化為0,其物理內存也被叫做匿名頁。
一個進程的text段、data段、堆區、棧區都是vma,這些vma都是內核為進程調用mmap生成的。進程自己也可以調用mmap來分配虛擬內存。堆區和棧區是比較特殊的vma,棧區的vma會隨著棧的增長而自動增長,堆區的vma則需要進程用系統調用brk或者sbrk來增長。不過我們在分配堆內存的時候都不是直接使用的系統調用,而是使用libc給我們提供的malloc接口,有了malloc接口,我們分配釋放堆內存就方便多了。Malloc接口的實現叫做malloc庫,目前比較流行的malloc庫有ptmalloc、jemalloc、scudo等。
八、內存統計
暫略
8.1 總體統計
8.2 進程統計
九、總結回顧
前面我們講了這么多的東西,現在再來總結回顧一下。首先我們再重新看一下Linux的內存管理體系圖,我們邊看這個圖邊進行總結。
首先要強調的一點是,這么多的東西,都是在內核里進行管理的,內核是可以操作這一切的。但是對進程來說這些基本都是透明的,進程只能看到自己的虛擬內存空間,只能在自己空間里分配虛擬內存,其它的,進程什么也看不見、管不著。
目前絕大部分的操作系統采用的內存管理模式都是以分頁內存為基礎的虛擬內存機制。虛擬內存機制的中心是MMU和頁表,MMU是需要硬件提供的,頁表是需要軟件來操作的。虛擬內存左邊連著物理內存管理,右邊連著虛擬內存空間,左邊和右邊有著復雜的關系。物理內存管理中,首先是對物理內存的三級區劃,然后是對物理內存的三級分配體系,最后是物理內存的回收。虛擬內存空間中,首先可以分為內核空間和用戶空間,兩者在很多方面都有著顯著的不同。內核空間是內核運行的地方,只有一份,永久存在,有特權,而且其內存映射是提前映射、線性映射,不會換頁。用戶空間是進程運行的地方,有N份,隨著進程的誕生而創建、進程的死亡而銷毀。用戶空間中虛擬內存的分配和物理內存的分配是分開的,進程只能分配虛擬內存,物理內存的分配是在進程運行過程中動態且透明地分配的。用戶空間的物理內存可以分為文件頁和匿名頁,頁幀回收的主要邏輯就是圍繞文件頁和匿名頁展開的。
編輯:黃飛






























 工商網監
工商網監
評論