 電子發燒友App
電子發燒友App


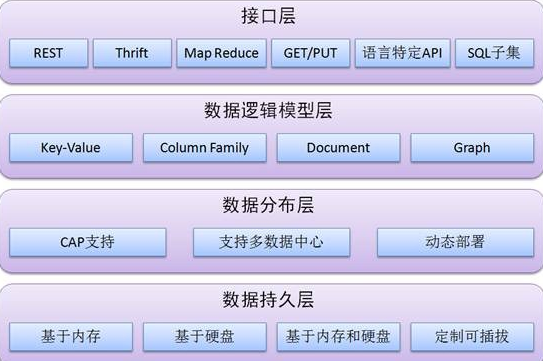
設計中存儲資源的使用
不同的用戶可能需要不同容量的RAM來構建他們的特定應用。所以FGPA底層的RAM基塊大小就是一個有意思的話題。如果太大,則不夠靈活,難以滿足小容量的應用,當然可以直接用大容量RAM來實現小容量應用,但這難免造成大量的資源浪費;如果基塊太小,則中等或者大型RAM應用會需要大量的小型RAM來構成,小型RAM為了普適性,也會配備同樣的信號輸入接口,這樣一來則會大大消耗FPGA內部的布線資源,甚至會造成布線擁擠和時序問題。
幾乎所有在 FPGA 中構建的設計都需要使用一定大小的內部存儲器資源來存儲系數、緩沖數據以及各種其他用途。典型系統需要小型、中型和大型存儲器陣列的組合來滿足它們的所dfe有要求,存儲器的整體功耗因此成為設計的主要關注點。
在設計FPGA時,重要的是要創建滿足大多數客戶需求的器件。如果 FPGA是用適合一個 應用的小型、中型和大型存儲器資源構建的,那么該解決方案對于某些客戶來說將是最佳的,而其他想要使用相同部件的客戶可能需要做出相當大的取舍。
試圖從他們的 FPGA 中獲得最佳價值的用戶可能會擔心大容量RAM 中的資源浪費。但是,構建更精細、更小的 RAM基塊需要額外的連線,這是有代價的。本文解釋了權衡取舍:為什么更精細的RAM基塊的成本通常更高。
圖 1 顯示了 FPGA 中小型、中型和大型存儲器塊的理論分布(未按任何特定比例繪制)。
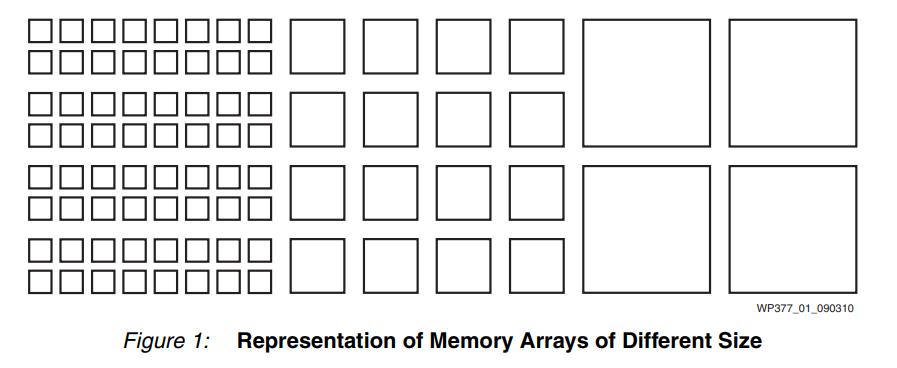
恰好需要這種塊組合的設計能夠完美地利用可用資源(參見圖 2)。
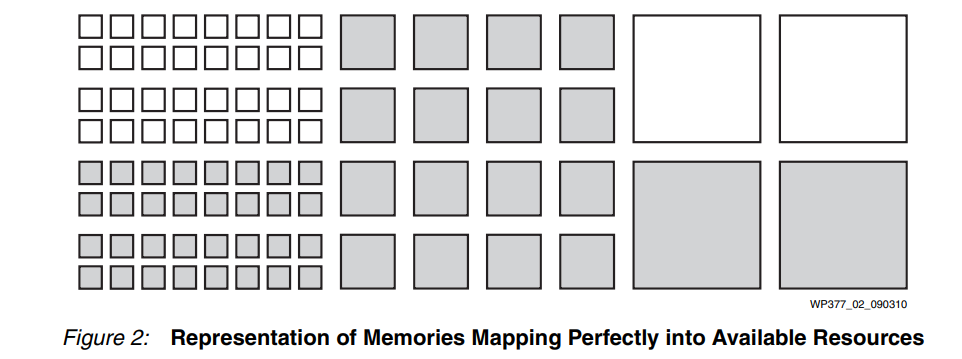
然而,想象一個場景----用戶只需要另外四個中等大小的資源。
一種方法是用大量小組件構建中型內存陣列,這會消耗大量資源并導致將它們連接在一起的復雜性。另一種選擇是使用一個大塊作為中塊,使大塊中的所有剩余資源不可用,同時保持它們通電,因此會消耗功耗(參見圖 3)。
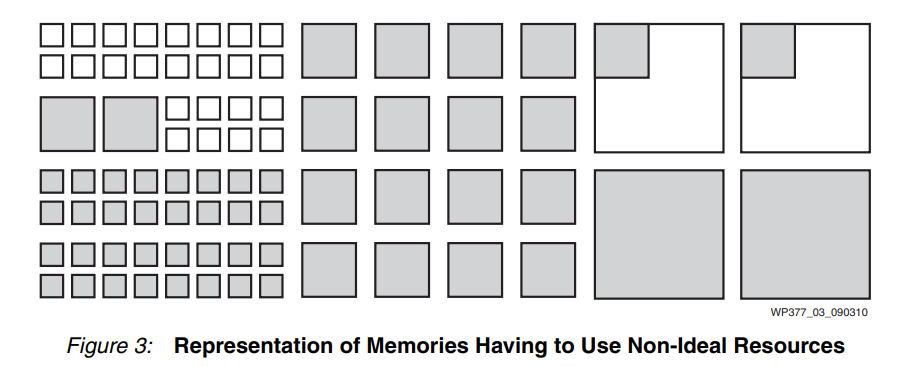
FPGA 制造商面臨的挑戰是構建具有最靈活的內存資源組合的設備,讓所有用戶能夠將他們所需的內存陣列大小安裝到設備中,同時實現所需的性能且不會浪費大量的資源和功耗。
FPGA 中的存儲資源 這一章是對BRAM資源的講述,更詳細的內容可以看這里:從底層結構開始學習FPGA----Block RAM(BRAM,塊RAM)
Xilinx FPGA 使用各種存儲資源,以提供最好的靈活性和低成本組合。包括 Artix-7、Kintex-7 和 Virtex-7 系列在內的所有 7 系列 FPGA 都使用相同的內存塊,從而能夠從一個 7 系列 FPGA 系列完美遷移到另一個系列。
顯然,構建存儲資源以滿足每個用戶的需求是一項艱巨的挑戰。Xilinx 7 系列 FPGA 中實現的解決方案是創建稱被為 塊RAM 的基塊(參見圖 4),這些塊基塊可以組合在一起形成更大的陣列,也可以分割形成更小的陣列。將塊 RAM 與 FPGA 邏輯中的 6 輸入查找表 (LUT) 組合成小型存儲器陣列的能力為用戶提供了最靈活的資源來創建各種大小的存儲陣列。
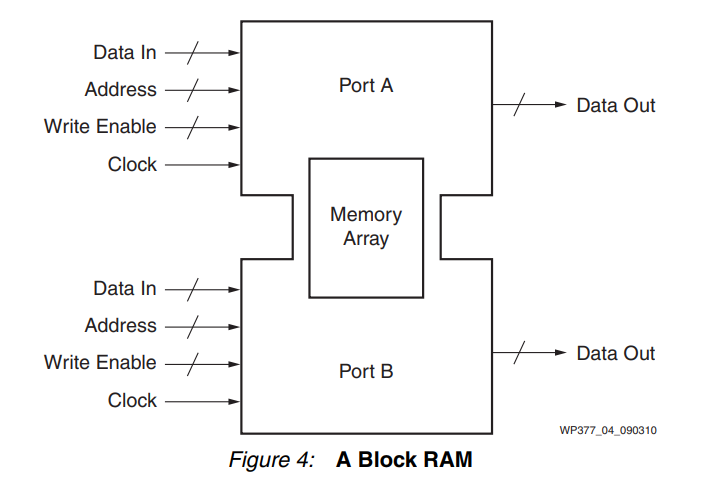
塊 RAM 每個 7 系列 FPGA 有 135 到 1880 個雙端口塊RAM,每個 塊RAM 能夠存儲 36 Kb數據,其中 32 Kb 分配給數據存儲,在某些內存配置中,額外的 4 Kb 分配給奇偶校驗位。每個 Block RAM 都有兩個完全獨立的端口,它們只共享存儲的數據。
每個端口可以配置為:
32K x 1 16K x 2 8K x 4 4K x 9(或 8) 2K x 18(或 16) 1K x 36(或 32) 512 x 72(或 64) 每個 Block RAM 可以分為兩個完全獨立的 18 Kb Block RAM,每個 RAM 可以配置為從16K x 1 到 512 x 36 的比例。當一個 36K 塊 RAM 被分成兩個獨立的塊 RAM,兩個獨立的塊RAM 中的每一個的行為都與一個 36 Kb 塊 RAM 完全相同,只是大小變成了一半。
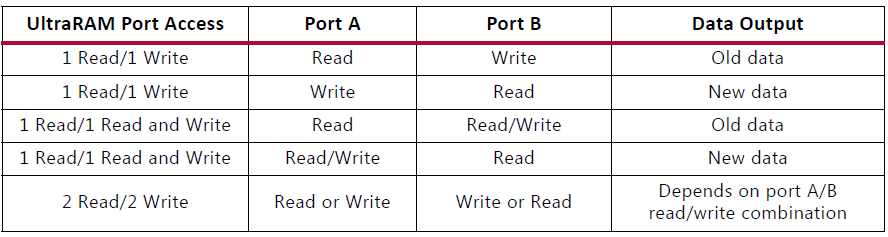
相反,如果用戶需要更大的存儲器陣列,則可以將兩個相鄰的 36 Kb 塊 RAM 配置為一個級聯的 64K x 1 雙端口 RAM,而無需任何額外的邏輯與資源。Xilinx 7 系列 FPGA 中的 Block RAM 組件可以配置為單端口、簡單雙端口或真雙端口模式。此外,可以通過以下三種方式之一從 Block RAM 讀取數據:READ_FIRST、WRITE_FIRST 或 NO_CHANGE 模式。
拆分塊RAM 如果用戶只需要單端口存儲器,而不是實現完全真正的雙端口功能,則可以將塊 RAM 分成更小的內存陣列。當 Block RAM 處于真雙端口模式(默認模式)時,端口 A 和端口 B可以通過將 ADDRA 地址總線的最高有效位連接到VCC(高電平)來實現單獨的、獨立的延遲線存儲器、單端口存儲器或 ROM和 ADDRB 地址總線的最高有效位接地,因此創建兩個單端口塊 RAM。
例如,一個 RAMB36E1,36K 塊 RAM 原語,可分為兩個18K單口存儲器,RAMB18E1可分為兩個9K單口存儲器。使用這種方法,可以在 7 系列 FPGA 中為每個 Block RAM 陣列創建四個延遲線存儲器。要以這種方式在 Block RAM 中實現延遲線,必須使用 READ_FIRST 或 Read-Before-Write 模式。
如果實現單端口存儲器,則允許的模式沒有這樣的限制;可以使用任何支持的模式(READ_FIRST、WRITE_FIRST 或NO_CHANGE),并且一個塊 RAM 中的不同存儲器可以具有不同的端口寬度。由此產生的存儲器方案在每個時鐘周期為每個端口執行一個操作,因此每個時鐘周期每個塊 RAM 執行四個操作。
同步操作 每次訪問內存,無論是讀取還是寫入,都由時鐘控制。所有輸入、數據、地址、時鐘使能和寫使能都已寄存。沒有時鐘什么都不會發生。輸入地址始終被時鐘控制,在下一次操作之前保留數據。一個可選的輸出數據流水線寄存器允許更高的時鐘速率,但代價是額外的延遲周期。在寫入操作期間,數據輸出可以反映先前存儲的數據、新寫入的數據或保持不變。
字節寬寫使能 Block RAM 的字節寫使能特性提供了一次寫入輸入數據的八位(一個字節)的能力。真雙端口 RAM 最多有四個獨立的字節寬寫使能輸入。每個字節范圍的寫使能與一個字節的輸入數據和一個奇偶校驗位相關聯。當使用塊 RAM 與微處理器接口時,此功能很有用。
錯誤檢測和糾正 Xilinx 7 系列 FPGA 中的每個 64 位寬塊 RAM 可以生成、存儲和利用 8 個額外的漢明碼位(Hamming-code),并在讀取過程中執行單位錯誤校正和雙位錯誤檢測 (ECC)。當寫入或讀取外部 64/72 位寬存儲器時,也可以使用 ECC 邏輯。這適用于簡單的雙端口模式,不支持 read-during-write。
FIFO控制器 Xilinx 7 系列 FPGA 中用于單時鐘(同步)或雙時鐘(異步或多速率)操作的內置 FIFO 控制器增加內部地址并提供四個握手標志:已滿、空、幾乎滿和幾乎空。幾乎滿和幾乎空的標志是可自由編程的。類似于 塊 RAM,FIFO 寬度和深度是可編程的,但寫入和讀取端口始終具有相同的寬度。首字直通模式呈現第一甚至在第一次讀取操作之前,在數據輸出上寫入字。讀完第一個字后,此模式與標準模式沒有區別。
分布式內存(DRAM) Xilinx 7 系列 FPGA 的邏輯由 6 輸入 LUT 等元素組成。LUT 以四個為一組排列,并組合成一個Slice。7 系列 FPGA 有兩種Slice----SLICEM 和 SLICEL。SLICEM 中的 LUT 占 7 系列 FPGA 中 Slice 總數的 25-50%,可以實現為稱為分布式 RAM 元素的同步RAM 資源。每個 6 輸入 LUT 可配置為一個 64 x 1 位 RAM 或兩個 32 x 1 位 RAM。SLICEM 中的 6 輸入 LUT 可以級聯以形成更大的元素,在簡單的雙端口配置中高達 64 x 3 位或在單端口配置中高達 256 x 1 位。請參見圖 5。
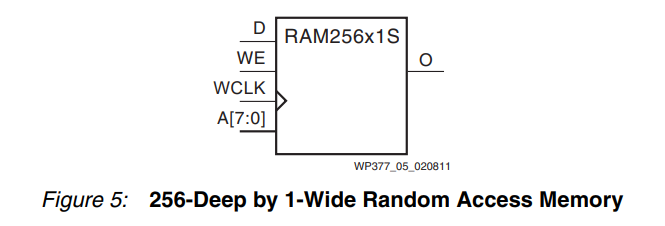
分布式 RAM 模塊是同步(寫入)資源。可以使用同一片中的存儲元件或觸發器來實現同步讀取。通過放置這個觸發器,分布式 RAM 性能通過減少觸發器時鐘輸出值的延遲而得到改善。但是,會增加額外的時鐘延遲。分布式元件共享相同的時鐘輸入。對于寫操作,由 SLICEM 的 CE 或 WE 引腳驅動的寫使能 (WE) 輸入必須設置為高電平。
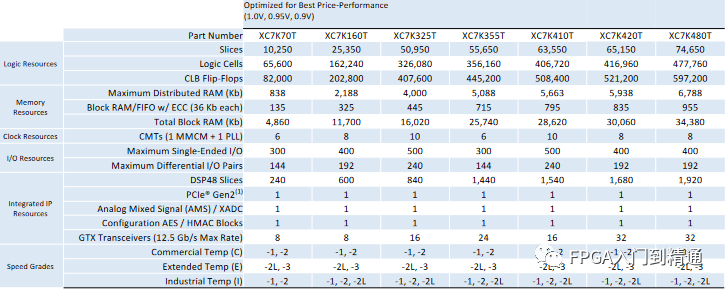
典型的用戶設計利用 表 1 顯示了針對 Kintex-7 XC7K410T FPGA 的典型存儲高利用率設計中的資源映射。此數據基于關注比特浪費的用戶的真實示例。

多個不同的資源利用了以不同大小配置塊 RAM 資源的能力。
無窮小基塊的代價 確定賽靈思 FPGA 架構提供了多種不同的存儲器深度/寬度粒度后,了解向架構添加更精細基塊所涉及的權衡非常重要。例如,如果 7 系列 FPGA 中的 36K 塊 RAM 不僅分成兩個 18K 塊,而且可以進一步分成四個 9K 真雙端口塊,但這需要付出代價。將單個 Block RAM 中的唯一存儲器數量加倍意味著要進出每個 Block RAM 的最大信號數量也需要加倍,這反過來又需要將互連資源(或塊)的數量加倍以適應約 400 個信號的路由布線。 例如,一個 8K 塊 RAM 可以配置為 16 位寬和 512 位深,總共需要 25 個輸入信號----16 條數據線和 9 條地址線。然后 8K 塊 RAM 分為兩個 4K 塊 RAM。這些塊 RAM 中的每一個都可以配置為 16 位寬和 256 位深。此配置每個塊 需要16 條數據線和 8 條地址線,每個 4K 塊 RAM 總共有 24 個輸入信號或總共 48 個信號。48 個信號大約是 8K 塊 RAM 所需的 25 個輸入信號的兩倍。與每個關聯的互連塊數量增加一倍的效果 塊 RAM 將硅面積增加了 25% — 無論使用何種配置,所有塊都會受到懲罰。因此,每個 Block RAM 能夠配置為四個 9K 塊的能力意味著每個塊從四個區域單元增加到五個區域單元。從積極的方面來說,它允許較小的存儲器利用較小的塊大小(參見表 2)。
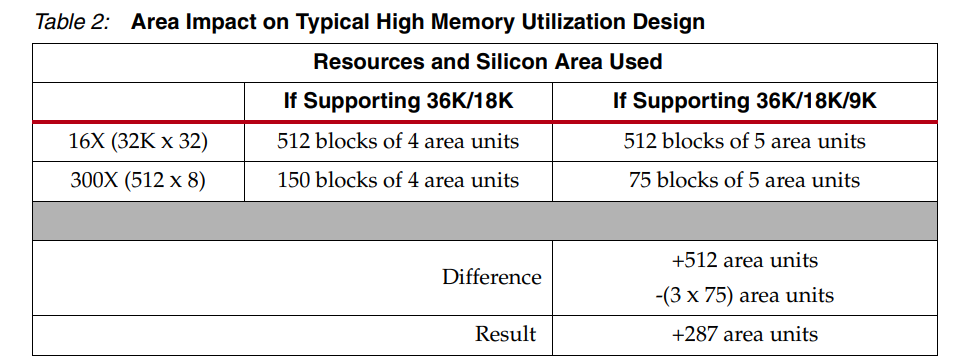
參考相同的設計示例,如果能夠將較小的 512 x 18 內存有效地打包到相鄰的 9K 塊中,則其影響相當于消耗更少的資源。然而,較大的塊都變大了 25%,增加了顯著的面積損失。因此,如果 Kintex-7 FPGA 中的 Block RAM 可以劃分為四個獨立的存儲器,并且用戶設計可以充分利用這些更小粒度的塊,那么這種典型設計仍然比當前的 36K/18K 配置占用更大的面積。然而,由于試圖將如此多的信號連接到一個總線上的布線擁塞,設計不可能通過將四個獨立的 9K 真正雙端口存儲器打包到同一個 36K 塊 RAM 中來充分利用它們。因此,表 2 中的面積乘法是最好的情況;實際上,并非所有 36K 塊 RAM 都將由四個 9K 存儲器填充。
對設備資源的影響 塊 RAM 資源大小增加的影響可能會在整體設備資源的中產生以下三種影響之一:
保持設備大小相同并丟失塊 RAM 位 保持 Block RAM 的位數相同,減少其他資源的數量,即 CLB 讓所有資源保持原樣 讓設備變得更大這些選擇中的每一個都有明顯的懲罰:
丟失塊 RAM 位并不理想,因為大多數用戶正在使用大部分可用內存。如果塊 RAM 全部增加 25%,Kintex-7 XC7K410T FPGA 中的塊數從 795 減少到 636,相當于從 28,620 Kb 減少到 22,896 Kb塊 RAM 大小增加 25% 意味著每塊 RAM 列損失一列 CLB。Kintex-7 XC7K410T FPGA 有 12 個塊 RAM 列,因此在這種情況下,它會從設備中丟失 12 列 CLB,相當于丟失 4,200 個 CLB,這相當于大約 54,000 個邏輯單元。這將產生將 Kintex-7 XC7K410T FPGA 從 406,720 個邏輯單元減少到 352,720 個邏輯單元的影響,從而以相同的成本生產出功能更差的設備。保持所有資源相同并允許增加硅面積有幾個缺點。顯而易見的第一個問題是,更大的設備意味著更昂貴的設備,但物理上更大的硅片也會對功耗產生重大影響。Block RAM 陣列的功率優化 功耗的重要性 功耗在大多數現代應用中至關重要,降低系統內的功耗對每個設計人員來說都是一項挑戰。降低功耗的方法有很多種,但很多都會伴隨明顯的性能損失。借助 7 系列 FPGA,Xilinx 采用了一種創新方法來降低與 Block RAM 存儲器陣列相關的功耗。降低功率的兩種主要方法是:
識別不必要地消耗功耗的區域并采取行動 提供在降低功耗與略微降低最大性能之間進行權衡的能力 未使用的 Block RAM 所有 Block RAM 組件在上電時都會消耗功率,無論它們是否在設計中使用。Xilinx 7 系列 FPGA 中的一項獨特功能使軟件能夠自動識別未使用的 Block RAM。識別出未使用的Block RAM后,它們會自動禁用并進入零功耗狀態,從而顯著降低 FPGA 的整體功耗。
使用 XST(xilinx synthesis tools) 推斷 RAM 模塊 如果讀取地址寄存在內,XST 會推斷塊 RAM。相反,如果 RAM 網絡使用異步讀取操作,則推斷為分布式 RAM。ram_style 屬性可用于指定是使用塊 RAM 還是分布式 RAM。當 RAM 網絡大于一個基塊的大小時,可以使用多個 Block RAM。默認策略是針對性能進行優化。在此策略中,小型 RAM 使用分布式 RAM 實現。RAM 網絡也可以針對功率和面積進行優化;這些在本文的使用 CORE Generator 軟件構建 RAM 部分中進行了描述。任何小于 128 位深度或 512 位深度 x 寬度的東西都在分布式 RAM 中實現,除非用戶使用 ram_style 屬性另外指定。為了確保最有效地使用Block RAM 和分布式 RAM 資源,XST 首先在 Block RAM 中實現最大的 RAM, 如果仍有可用的塊 RAM 資源,則將較小的 RAM 放入塊 RAM。XST 還可以將小型單端口 RAM 打包到單個塊 RAM 中。
可以在 XST 中啟用降低 Block RAM 功耗的技術。它們是由功耗降低 (POWER) 綜合選項控制的更大優化集的一部分,并且可以通過 RAM 樣式 (RAM_STYLE) 約束專門啟用。XST 中的 RAM 功率優化技術主要旨在減少設備上同時活動的 Block RAM 的數量。它們僅適用于需要分解多個 Block RAM 原語的推斷存儲器,并利用 Block RAM 資源的啟用能力。創建額外的啟用邏輯以確保僅同時啟用一個用于實現推斷存儲器的 Block RAM 原語。為適合單塊 RAM 原語的推斷存儲器激活功率降低技術沒有效果。啟用后,將結合區域和速度優化目標尋求降低功率。通過 RAM 樣式 (RAM_STYLE) 約束可以進行兩種優化權衡:
模式 block_power1 實現了一定程度的功耗降低,同時對電路性能的影響最小。在這種模式下,會保留默認的、面向性能的 Block RAM 分解算法。XST 只是添加了塊 RAM 啟用邏輯。根據內存特性,功率只能以有限的方式受到影響。 模式 block_power2 提供更顯著的功耗降低,但可能對性能產生輕微影響。也可以引入額外的切片邏輯。此模式使用不同的 Block RAM 分解方法。該方法首先旨在減少實現推斷內存所需的塊 RAM 原語的數量。然后通過插入 Block RAM 使能邏輯來最小化活動 Block RAM 的數量。還創建了多路復用邏輯以從活動塊 RAM 中讀取數據。如果設計的主要關注點是降低功耗,而速度和面積優化是次要的,那么賽靈思建議使用 block_power2 模式。 ROM 可以通過使用大的 case 語句來推斷。XST 還可以在 Block RAM 中實現有限狀態機 (FSM) 和邏輯,以最大限度地利用可用的邏輯資源。
使用 CORE Generator 構建 RAM CORE Generator 工具具有三種算法,可用于優化 Block RAM 網絡。最小面積方案使用盡可能少的資源(塊 RAM),但也最大限度地減少了輸出多路復用,以在最小面積上保持最高性能(參見圖 6)。低功耗方案可以使用更多資源,但確保在每次讀寫操作期間啟用的塊最少。這可能會在使能信號上產生少量額外的解碼邏輯,但與所節省的功率相比,這是一個小的面積損失。在此模式下運行時,CORE Generator 工具在 RAM_STYLE = block_power2 模式下執行與 XST 相同的功能。請注意,如果 Block RAM 網絡非常大,使用低功耗方案進行拆分可能會導致需要路由許多額外的信號,這可能會耗盡設計其他部分的路由資源。
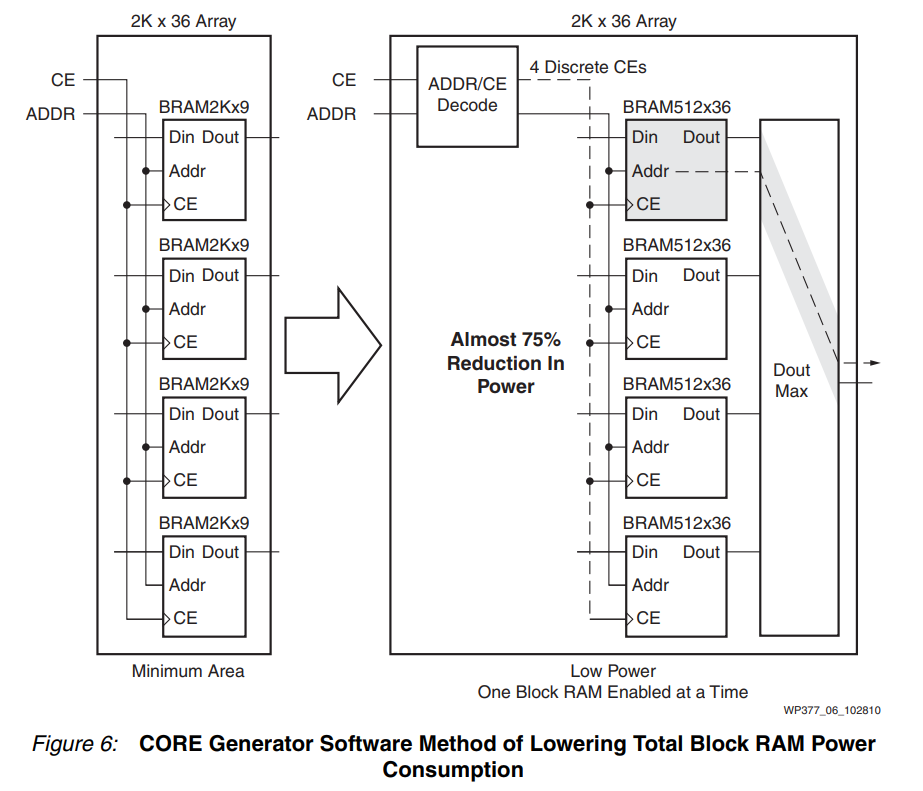
第三種優化方案是 Fixed Primitive,用戶可以在其中選擇一個特定的基元,例如 4K x 4,從中構建他們的 RAM 網絡。由用戶決定哪個原語最適合他們的應用程序。CORE Generator 工具還提供了一個選項來寄存 RAM 網絡的輸出以提高性能。如果網絡中使用了多個 Block RAM,用戶可以選擇是在每個 Block RAM 原語的輸出還是在內核的輸出上進行寄存。
結論 組合塊ram,可以配置在各種數據寬度/深度與分布式RAM的組合來支持更小的內存陣列提供最靈活的方式以最低的成本建立不同大小的存儲內存。向組件添加額外的功能,例如向塊RAM,如果準確的功能是正確的,最初可能是最好的解決方案必需的。然而,組件和它的組件都有區域懲罰用于添加新特性的相應互連。這些區域處罰有一個對設備資源影響較大。多年的開發經驗構建FPGA嵌入式存儲器已經導致了廣泛的高效解決方案范圍的應用程序
審核編輯:湯梓紅
















 工商網監
工商網監
評論