 電子發燒友App
電子發燒友App


圖數據庫的性能和 schema 的設計息息相關,但是 Nebula Graph 官方本身對圖 schema 的設計其實沒有一個定論,唯一的共識就是面向性能去做 schema 設計。?
背景知識
先來講解下存儲背景,再講 schema 設計中會遇到的問題,最后講下實踐過程中我們能達成一致的最佳實踐。
在使用圖數據庫之前,先了解下圖數據庫這個 NoSQL 數據庫同關系型數據庫不一樣的地方。
關系型數據庫存儲結構
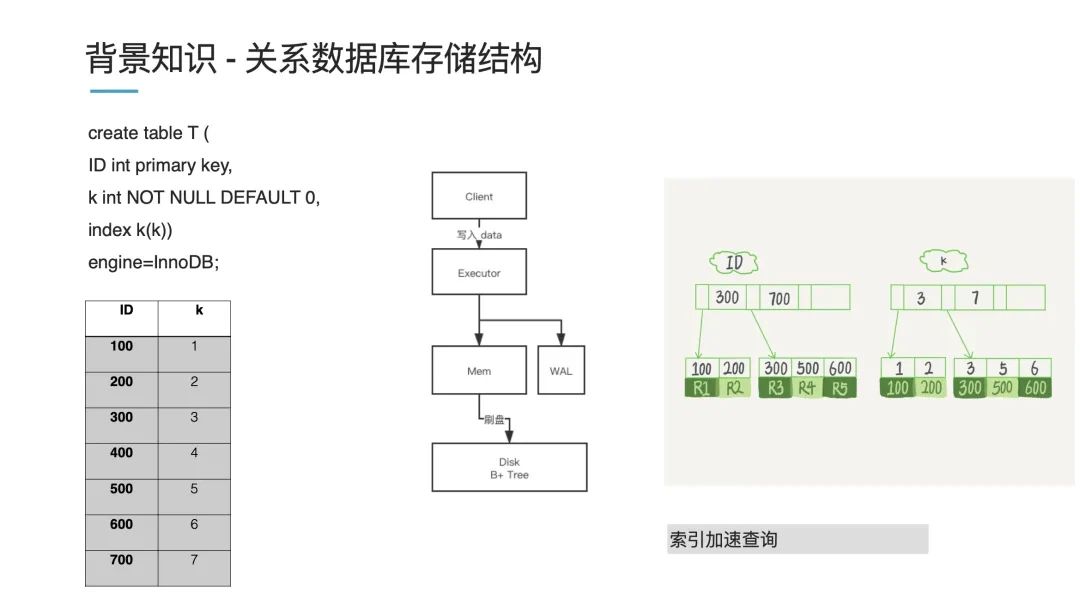
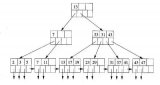
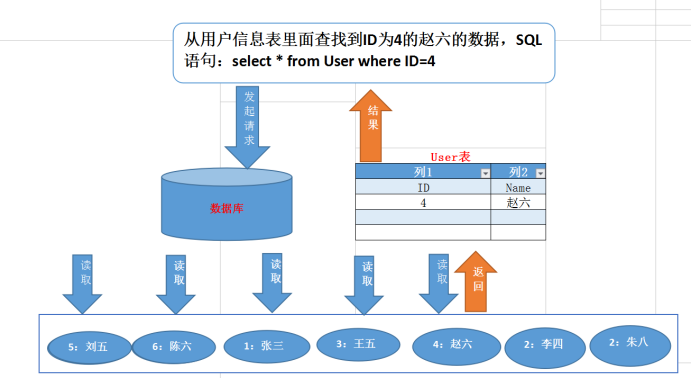
以上圖為例,存一個 ID 作為一個主鍵,然后它有個特征 k,我們對 k 創建索引進行查詢,對于左下角這份列表數據,內存中存儲的話,會以一個 B+ 樹進行存儲(上圖右側):一個主索引 ID 和一個從索引 k。舉個例子,現在我們要查詢 k=3 的數據,它就先查詢 ID=100 然后經過回表后回到具體的值。
這體現了關系型數據庫的一個特點,如果你要查詢速度快,那就需要創建一個索引。假如你不創建索引,那數據庫就會掃全表。
我們再來看下寫過程。數據一般先寫到內存 Mem(這是一個常規的優化減小磁盤壓力),寫到一定程度再同步到磁盤中,這個過程我們叫原位刷盤,刷盤就是說找到這個地方的數據,然后修改掉數據,即原位修改。
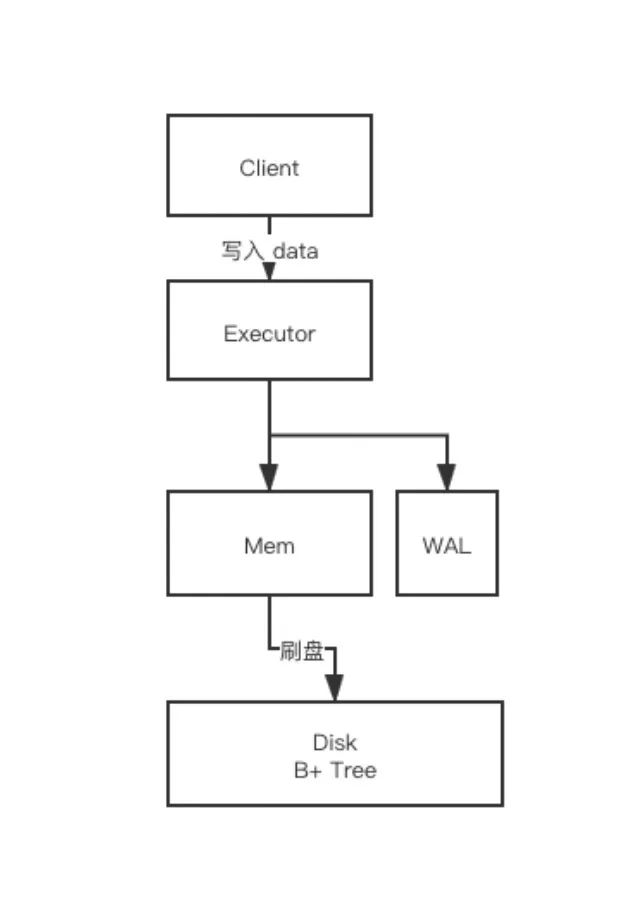
如果你之前熟悉 MySQL 或者是其他關系型數據庫,這套原理應該是比較熟悉的。
而相對應的,用傳統的數據庫來實現圖功能的話,代價比較大,下圖便展示了它的實現弊端:
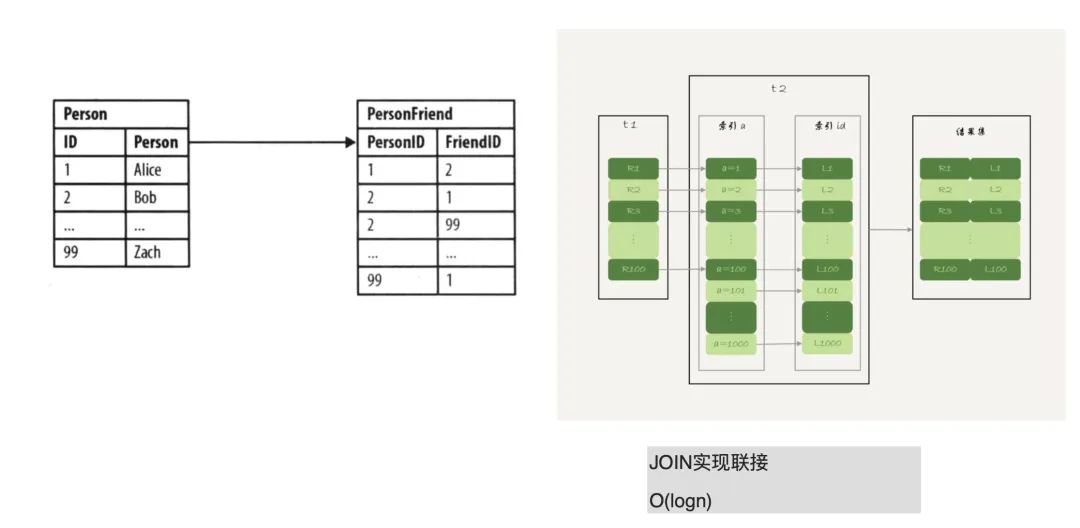
現在有個場景,現在我們有某個人(上圖 Person 表),我們要找朋友的朋友(上圖的 PersonFriend 表),在關系型數據庫中便是兩級索引,先查 Person 表索引找到 Person ID,再查 PersonFriend 表通過 ID 找到對應的人,就是一個 JOIN 查詢過程。如果這里使用的是 B+ 樹,那么程序復雜度便是 O(logn);如果是這里的多級大小表,在笛卡爾積上即 O(n*m),都加索引有一定程度優化,但查詢這種多級關系的話,到了一定程度會遇到系統“爆炸”,無法進行相關查詢。
LSM 存儲模型
本文主題是圖的高性能設計,主要基于 Nebula Graph 來講解。這里部分存儲細節同 Neo4j 會略有不同。
Nebula Graph 存儲模型采用了 LSM 存儲模型,同上面我們講的原位修改不同,LSM 模型是先寫內存,寫到一定程度之后再寫入到對應磁盤中,每次都是增量順序寫。LSM 模型是一個多級模型,第一層是 L0,第二層是 L1,一般默認是 7 層。
這里引用網圖來講解下 LSM 層級結構:
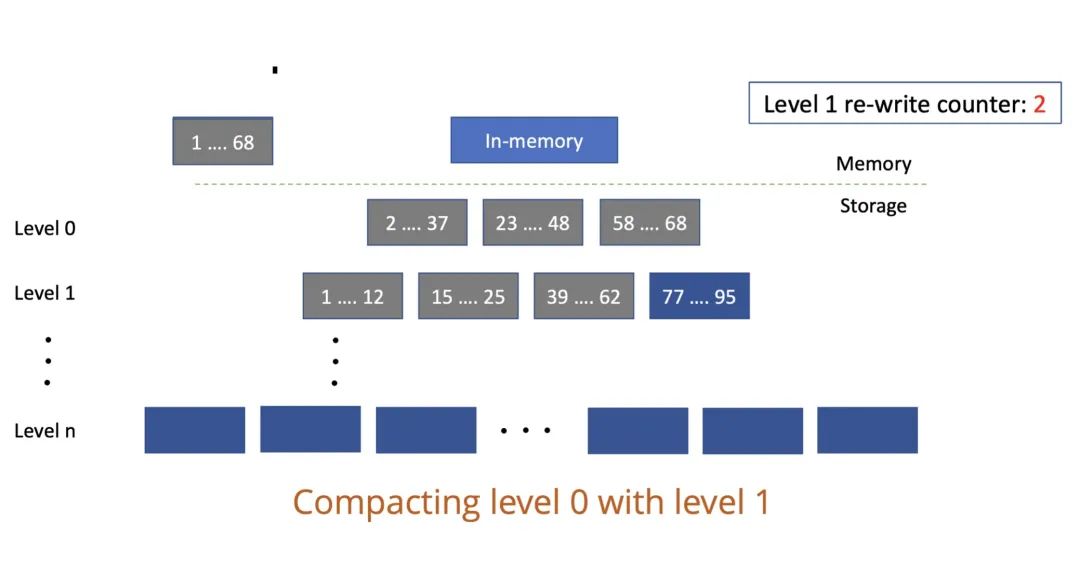
上圖的 L0 層其實有重復數據,像上圖的 1-68 的 key 在 L0 層的 2-37,以及 23-48,其實這兩步數據是存在重疊的;但 L1 層的數據就不存在重疊情況了,1-12、15-25…要最大地發揮圖性能的話,先得了解它的寫入過程。LSM 模型的寫是順序寫,即不會進行上文說到的原位修改。不管是寫入新數據還是更新原來數據,永遠是在后面插入新的數據(參考上圖右側深藍色數據)。這樣設計的好處在于,寫入數據就不需要找之前的數據,一旦涉及查找數據就會慢,這樣設計提升了寫速度。
但這也會帶來一個問題:我們寫入重復的數據,或是寫入的數據越來越多,查詢會不會受影響呢?我們來看看 LSM 是如何查數據的。LSM 進行數據查詢時,先查內存,內存里沒有數據再查不可變區域(Immutable Memtable),沒有的話,再往下一級級地查(參考上圖左側部分)。所以,重復的數據越多,或者磁盤數據越多,便會越慢。
所以為了保證寫入和查詢性能,無論我們設計屬性還是其他 schema,都要控制寫入量,也就是 LSM 的寫入不能是無限制追加,它有一個定時的合并操作,定期地將重復數據進行合并,叫做 Compaction。
Compaction 過程也需要控制。合并數據能減小數據量,但同時 Compaction 會帶來磁盤壓力,磁盤壓力過大,讀操作速度也會變慢。綜合來看,Compaction 是一個寫入平衡的過程。
Nebula Graph 存儲結構和索引
下面再來了解下 Nebula Graph?本身的存儲結構和索引。
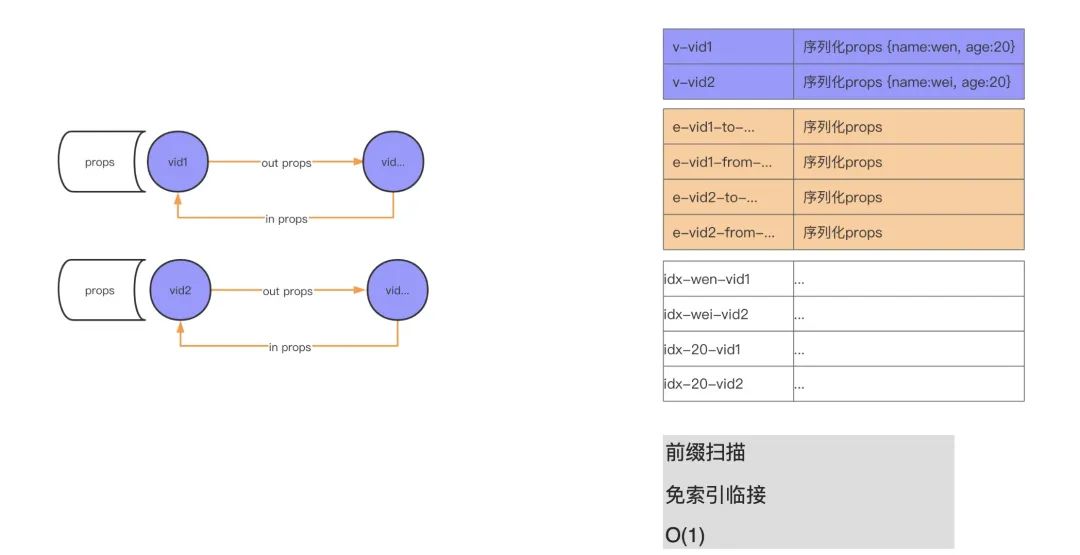
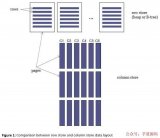
Nebula Graph 本身是分布式數據庫,因為便于理解這里剔除了相關的分布式結構。簡單來了解下 Nebula Graph 的結構,上面提到過的 LSM 其實是 KV(key value)存儲,所以我們圖里存儲點、邊、索引在磁盤上都是 KV 結構。我們可以看到上圖左側(紫色部分)有個 vid 帶著出邊(out)和入邊(in)以及相關屬性。再看下上圖右側部分(紫色部分),可以看到一條邊的兩個點是存儲在一起的,對應的點屬性序列化保存。相當于說,KV 結構中的 key 便是我們的點的 vid,然后 value 便是屬性的序列化結構。因為是序列化的結構,所以你的屬性名是什么便會存成什么,比如這里原始數據 name 字段,它改命名為 family_name,實際存儲就是序列化后的 family_name,也就是屬性名越長,存儲量越大。除了屬性名之外,其實屬性值也會導致存儲量增大。舉個例子,現在有個人(點),他的生平介紹要不要放在屬性里進行存儲?答案是:不應該。因為你的生平介紹會很長,這就會導致 LSM 的存儲壓力會很大。無論是 Compaction 還是讀寫,都會有很大的壓力。類似比如存儲進程實體,對應的進程描述文本也較大,會帶來較大存儲壓力。
再來說下我們的邊,Nebula Graph?中出邊和入邊保存在一個 KV 結構中(參考上圖右側橙色部分)。Nebula Graph 中有個詞叫做前綴掃描,具體來說便是現在要查找某個 vid 對應的邊,它是如何查找的呢?先按照 vid 來前綴掃描,在內存中這個過程是個二分查找,所以 Nebula Graph 查詢快就是在這里。在 Neo4j 里面這種叫做“免索引鄰接”。像上面的朋友的朋友的場景,傳統數據庫是通過索引進行查找的,而在這里直接掃描找尋某個人便可。在物理存儲這塊,點(人和相關的人)都是存儲在一起的,找到了某個人便找到了他的朋友。查詢上速度非常快,這也是原生圖數據庫帶來的好處。
除了上面的存儲結構,索引也是高性能 schema 設計的一個作用因素。像上圖的右側部分,上面的紫色部分存儲著點,這里有 2 個點:第一個點是 vid1,name 是 wen,age 是 20;另外一個是 vid2,name 是 wei,age 是 20。這里我們創建了 2 個索引,一個是針對 name,一個是針對 age。這兩個索引的存儲結構參考上圖右側下方的白色部分,查找 name 為 wen 的數據時,按照上面我們科普過的會進行二分查找,掃描到對應的 name 索引的 wen 數據,然后再從索引數據中找到對應的點(vid1)數據,再借助 vid 數據來找尋它的相關信息。這里 vid 找關聯數據的原理同上面的存儲結構描述。
小結
小結下 Nebula Graph 存儲結構和索引,在這里關系是一等公民,索引輔助查詢(并非用來提速),重要的是抽象關系。
schema 設計
進入本文的重點——schema 的設計,schema 設計的三大基本原則:
尊重領域實體關系
以性能為目標
考慮可視化分析
而三者并不沖突,上面三點其中某一點做得很好,另外兩點也會做的不錯。
Talking is cheap,下面我們來結合具體的例子來了解下三大原則。這些 case 圖主要引用自 Neo4j,但是對于 Nebula Graph 相關的 schema 設計也有參考意義。
實體和關系的選擇
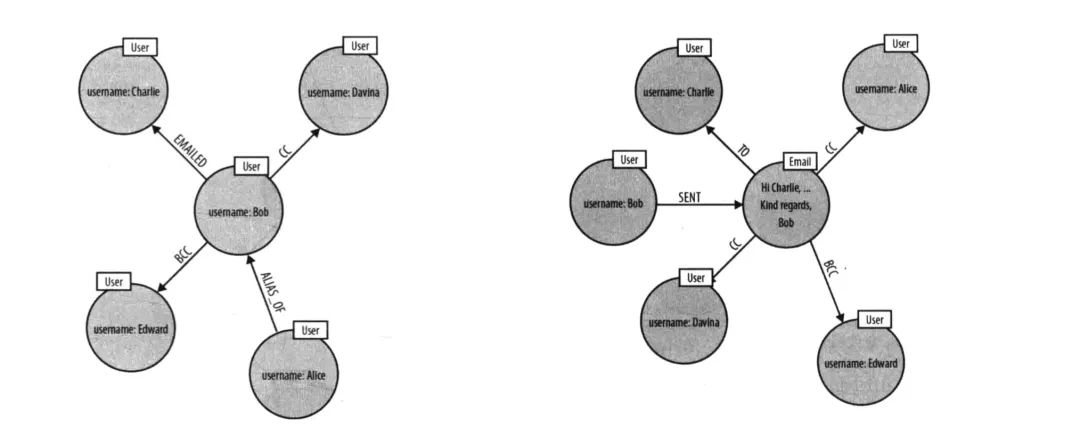
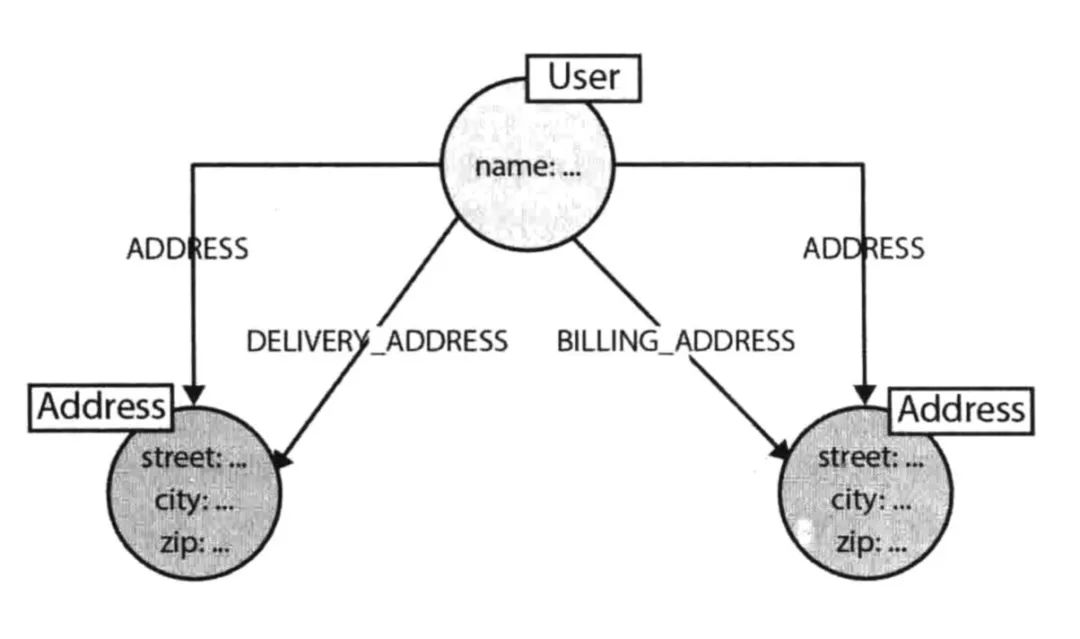
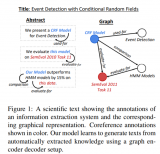
上圖是 Neo4j 圖數據庫書籍中的示例圖。簡單描述下這個場景,Bob 和 Charlie 等人在發郵件。那你設計這么一個場景的 schema 是否很自然就會將發郵件變成關系邊?因為 Bob 同 Charlie 發郵件,不是很明顯就是發郵件關系嗎?那我們來回顧下上面說的三大原則第一點:尊重領域實體關系。Bob 和 Charlie 建立聯系自然不是通過發郵件這個行為,而是通過郵件本身來建立聯系,所以這里便缺少了一個實體。在考慮可視化分析原則這邊,你要分析實體之間的關系,你思考它們是通過什么來建立的聯系。這時候就會發生之前提到過的發郵件設置為邊的情況(把郵件放置在邊上),單看 Bob 的話(左圖),我們可以清楚地看到發郵件這個動作。左圖上面部分,Bob Emailed Charlie。但如果這時候,要查看這個郵件抄送給了誰,還有這封郵件有哪些相關人,像左圖的 schema 就不能很好地進行查詢。因為缺少了 Email 這個實體。而上圖右側部分便能可以方便地找尋相關信息。
下面再來講下如何進行實體和屬性選擇。
實體和屬性選擇
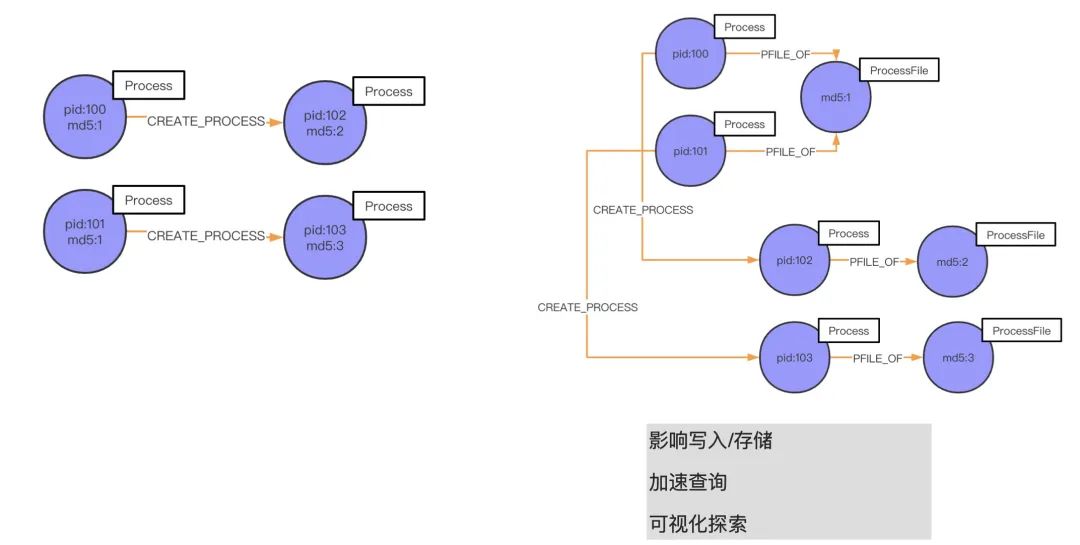
在這個部分,我將結合青藤云的情況來講一個我們的 case——進程之間的父子關系。
如上圖左側所示,md5 為 1 的 pid 100 進程起了一個 pid 102 的子進程,這個子進程的 md5 是 2。同時,md5 也為 1 的 pid 101 也起了進程,pid 為 103、md5 為 3。按照我們之前的實現方法,是在 md5 上創建索引,繼而建立起跟 pid 102、pid 103 的聯系。但這種做法,上面講過性能并不高,免索引復雜是 O(1),而這種做法的復雜度是 O(logn)。所以說,我們這時候應該基于 ProcessFile 進程文件 md5 來建立關系(進程間是基于 md5 聯系起來的):我們先抽取 md5 建立一個名叫 ProcessFile 的實體,屬性是 md5。如果我們要查詢指定進程所關聯的進程,很直觀地去找尋和這個 ProcessFile 關聯的進程就可以分析出來我們要的結果。舉個例子,pid 102 的進程是一個木馬,我想找尋是哪個父進程釋放的它,或者是同它父進程同 md5 文件的進程,該怎么找?
上圖的展示了兩種形式,第一種(左側)的話就需要找索引;第二種(右側)通過 CREATE_PROCESS 就可以直接找到 pid 102 的父進程 pid 100,再通過 PFILE_OF 關系你可以找到它同 md 文件的進程 pid 101。
好的,簡單結合 schema 設計三大原則來回顧下這個 case:
屬性上創建索引會影響寫入,此外屬性放在 ProcessFile 還是放在 Process 中,存儲性能是不一樣的。這里主要涉及到寫入量,因為 Process 進程是一直可以不停地啟動,但是 md5 文件可能本身并不多。如果是放在 Process 中,進程起得越多,數據寫入量也就會越大,進而查詢壓力也會增大查詢變慢。
可視化探索這塊主要和不定需求有關。因為一開始我們設計 schema 的時候可能并沒有全方位考量,或者說像是一些安全、防作弊規則并未擬定,不知道它會是什么樣。而這時你要根據這種不確定來設計 schema,就需要將圖“釋放”給相關業務人員,讓他在圖里點擊,設計他的關系,所以相對應的我們就不能通過索引來實現這種需求,因為業務人員可能沒有相關的技術背景。
添加屬性
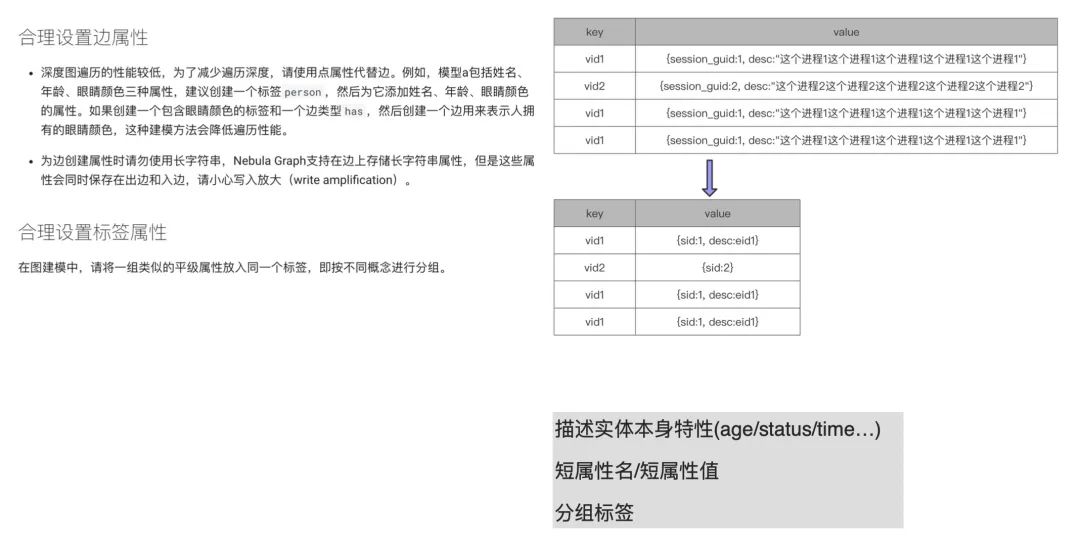
上圖左邊描述文字截自 Nebula Graph v2.0 的官方文檔:
https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/1.nGQL-overview/2.graph-modeling/#_3。
在合理設置邊屬性的第二部分提到,“為邊創建屬性時請勿使用長字符串”。這個和我們之前提到過的,屬性名和屬性值都應該短,不應該長是一個意思。像上圖右側部分,很明顯可以看到 vid 重復寫多次的話,每次寫就是重復的流量和存儲,這會大大增大內存占用和磁盤容量。如果我們把 session_guid 變成 sid 會節約很多存儲。而后面的描述信息,也有兩種處理方式。第一種,直接刪除描述;第二種,將過長的描述存儲在外部,比如放置在 Elasticsearch,然后將 ES 存儲這塊內容的 eid 存儲在上圖的 value 中。這樣也可以大大減少存儲量,提升寫入 / 查詢性能。
除了這點之外,我們還要注意合理設置分組標簽。青藤云暫時沒遇到類似 case,所以這里講下這句話什么意思。簡單來說,就是寫入這邊需要做一個 tag 的區分,結合上文提到的二分查找,你就比較好理解了。舉個簡單例子,這里有個人,他的公司相關信息,或者年齡相關的信息,或者是個人喜好之類的信息用相關的 tag 區分開,這樣查詢時可以更快地找到對應的信息。
最后回到文檔「合理設置邊屬性」中第一部分中的“深度圖遍歷的性能較低,為了減少遍歷深度,請使用點屬性代替邊。例如,模型 a 包括姓名、年齡、眼睛顏色三種屬性,建議您創建一個標簽 person,然后為它添加姓名、年齡、眼睛顏色的屬性。”,按照官方舉的例子,固然是這樣的。但實際應用中,并非一定要遵循這一原則——屬性用點屬性而不是用邊,該用實體的時候還是得用實體。所以我這里下面備注寫了:描述實體本身特性。像實體本身的特性 age / status,邊的 time / count 這些屬性會變成相對應的屬性,這樣能更好地描述本質特性,也能起到比較好的輔助效果。
添加索引
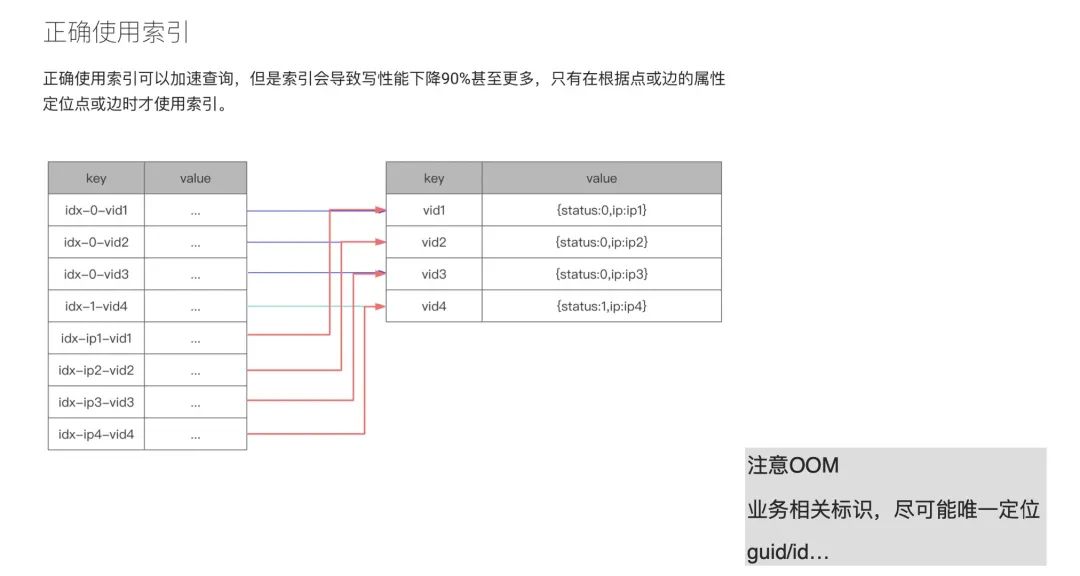
借助之前我們的實踐經驗,來講下索引這塊內容。在 Nebula Graph 的官方文檔中提及了:盡量少用索引。那么問題來了,到底什么時候應該用索引呢?我們先從原理上來解釋下索引。在上圖的例子中,value 中存儲了 2 樣東西:一個是 status,狀態;另外一個是 ip。右側的表格是對應的 KV 存儲結構,key 是個點結構。給點加索引之后,它便會變成左側表格的結構,idx-x-vid1。如果我們要查詢 status 等于 0 的這列值的時候,由于加了索引之后數據結構是以 0(status)為前綴,vid 放在 0 后面;如果我們要查詢 ip 的話,存儲結構則將 ip 變成前綴,vid 存儲在后面。這樣會產生何種問題呢?status 如果只有 1 和 0,現在你有 1 萬億的點,這樣添加索引是沒有意義的。而且,因為 Nebula Graph 的查找是二分查找,復雜度收斂到 O(n),相當于有多少數據就查多少數據。即便你添加了一個 limit,但是在 Nebula Graph 這邊(注:本次分享時,Nebula Graph 的最新版本為 v2.0.1)limit 并沒有下推,所以所有數據會先撈上來到計算層,在內存中使用 limit 進行數據過濾。
正是由于這種情況,所以在 v2.5 之前的 Nebula Graph 用戶會經常在論壇反饋 OOM 問題,其實就是內存爆炸。
所以說,索引應該是盡可能和業務相關的標識。
細粒度關系和通用關系
通過上面的 Neo4j 這個 case 我們來講解下顆粒度問題。
像上面的人有 2 個地址,一個是收件地址,另外一個是付款地址。如果此時,我們想找尋這個人的地址,如果沒有 ADDRESS 這個通用標簽的話,DELIVERY_ADDRESS 和 BILLING_ADDRESS 這兩個關系都得查下。這時候如果用的是二分查找,如果這堆關系本身存儲在一起還好,可以一次性查找出來;但,如果關系不在一起,就需要分 2 次查詢,這會降低它的查詢速率。
因此,我們可以再創建一個通用標簽,但是要注意的是,標簽的建立是基于對某個業務有強需求。像上面的例子,需要知道用戶的所有地址,也要知道他的單獨地址,比如:收件地址。這種情況下,建立一個通用標簽才是一個加速的方法,但注意要謹慎使用。同樣的,通用標簽設計時,也需要考慮可視化的情況。
加速查詢
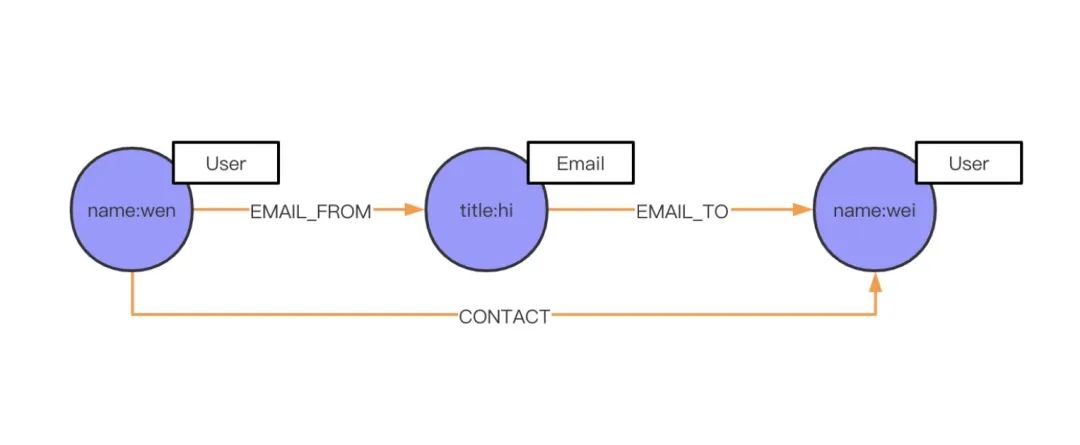
之前我們講過一個發郵件的例子,但是現在場景有所變化了,我現在不關心發郵件這個事情,我只關心人和人之間的關系,比如,wen 這個人的聯系關系,有誰和他聯系過,而這個聯系方式可能是 Email,也可能是手機(Phone),或者是微信。這時候我應該如何設計 schema 呢?當然之前的設計是可以沿用的,但為了加速查詢,滿足業務上的需求。這里加了 CONTACT 屬性,用來加速查找。
小結 schema 設計
講到這里,我們總結下上面的例子,其實我們的例子都是圍繞著三大原則來展開的,即:性能、可視化、領域關系。
?
典型 schema 設計
下面來我們來講下有些典型場景下的 schema 設計。
時間設計
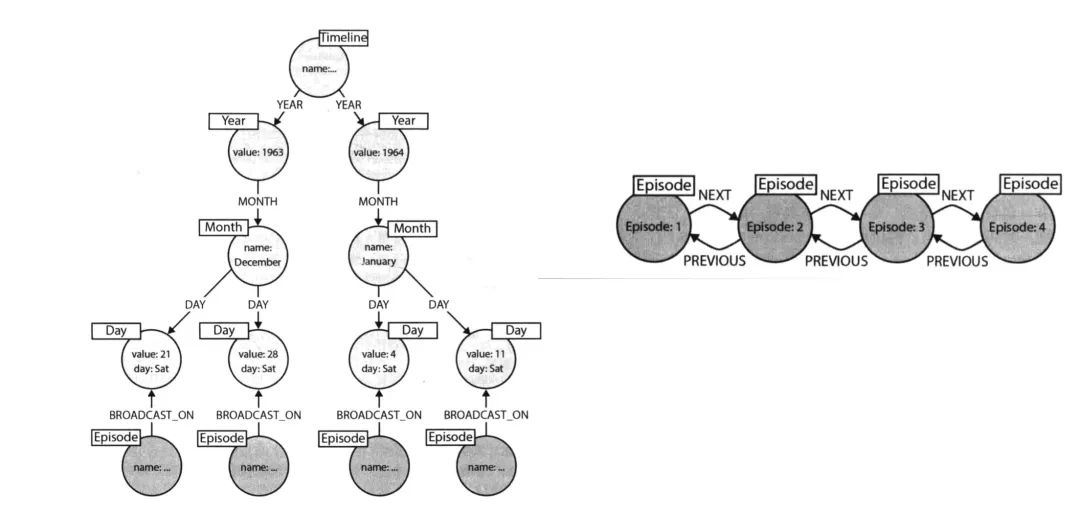
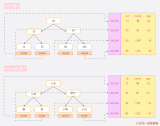
現在有個場景,有一堆發生過的事件,現在想查詢在某個月,或者是某個時間段內,發生了哪些事件,我們該如何設計 schema 呢?也許我們可以在時間屬性上創建個索引,把這個時間當作索引來存儲,但這樣的話,查詢速度不會很快,尤其是數據量較大的情況下。那我們應該怎么做呢?Neo4j 給了一種設計思路叫做時間樹,就是說時間本身是有層級關系的。如上圖所示,時間有個層級,想要查詢某個事件同時間段內的其他事件,可以通過這個層級快速找到。
上圖右側則是一個時序關系,可以快速找尋某事件發生的時間前后有哪些事情發生,而在 Nebula Graph 中,你可以通過 rank 來實現時序圖功能。
上面的例子只是給大家一個參考,并不代表會應用在青藤云實際業務中。
地址設計
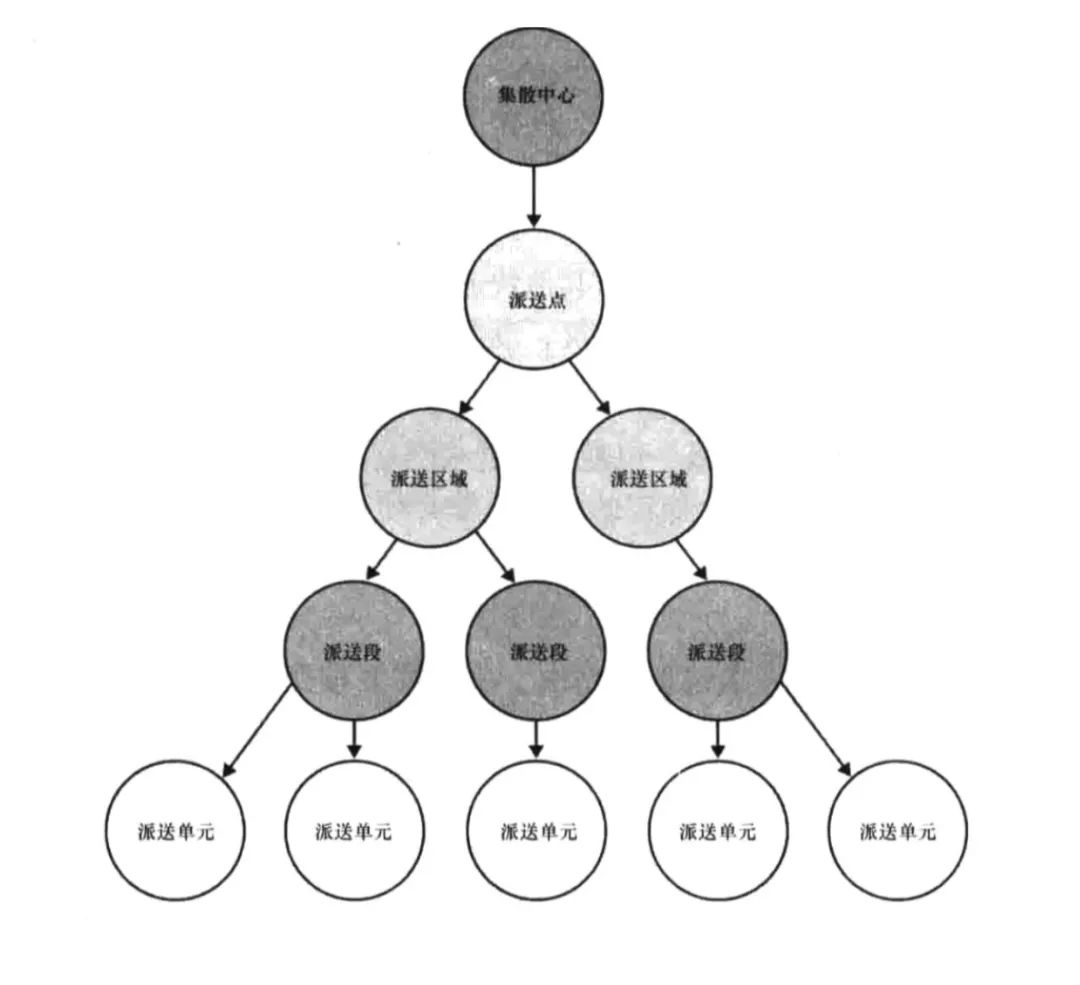
上面這個是地址的設計,可能大家都會遇到。假如,現在我們要查詢北京朝陽太陽宮在發生事件 A 時,同一個地理位置有多少用戶 / IP 在這。傳統的設計方法中,添加屬性是無法滿足該業務需求的。那怎么實現呢?其實這些地址劃分可以作為實體,而且地址之間是有關系的。以上述的物流為例,上面的例子:中國-北京-朝陽-太陽宮,就可以通過集散中心-派送點-派送區域-派送段形式進行查詢。如果你要查詢同一個街道或者是同個市,也可以按照這個關系快速進行查詢。
像我們遇到的地址位置,或者是網絡層問題,都可以參考這種設計。之前在 BOSS 直聘(分享嘉賓曾就職 BOSS 直聘)中,我們就是參考了類似的實現來找尋某個區域的相關用戶。
?
圖最佳實踐
上面講述的內容主要是圍繞 schema 設計,下面這塊當作補充資料,主要講的是圖的最佳實踐。
命名規范
如果你要編寫一個比較長的語句,不知道你有沒有注意過,這個語句該如何快速區分哪些是實體,哪些是關系,哪些又是屬性。所以,這里就要提一下命名規范問題。一旦命名規范了,一條長查詢語句也可能快速辨別實體、關系、屬性。
你可以參考下面的命名規范:
實體采用駝峰方式,例如:User、Email、Process;
關系采用全部大寫,包含動詞和副詞,例如:HAS_IP;
屬性采用英文小寫簡寫,例如:title、sid、pid
圖計算
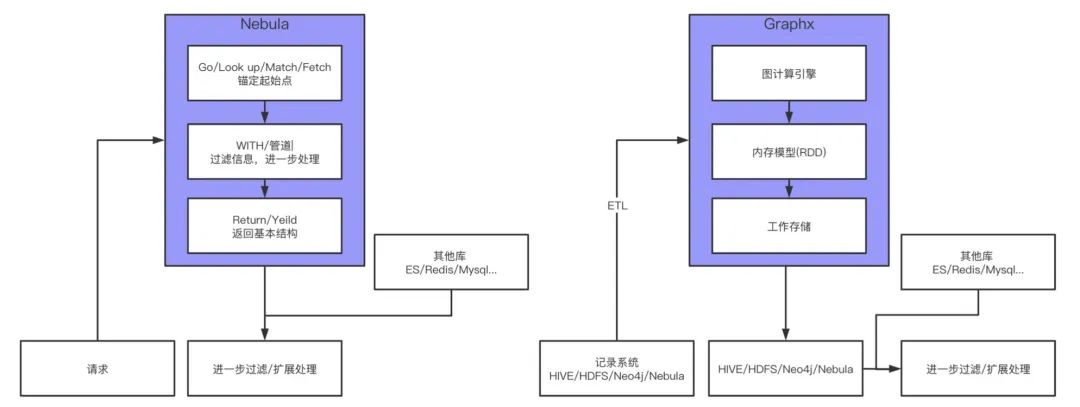
上圖給出了圖數據庫和圖計算的工作流,可以直觀地查看到二者的區別。圖數據庫的工作流相對簡單,拿我們常見的一個場景舉例,已知某個有問題的進程 A,要溯源找尋它的源頭。對應到圖這邊,圖數據庫的查詢一般會 GO / LOOKUP / MATCH / FETCH 錨定某個起始點,比如這里的進程 A,然后管道 / WITCH 進行下一步的處理,最后用 RETURN / YIELD 來返回基本結構。但,注意,這個基本結構會進行二次加工。剛設計 schema 的時候提到過,并不是所有的屬性都會設計進去,只有和業務相關的核心屬性才會設計進入。像請求接口之類的操作,都會在下一步過濾 / 擴展處理時完成。
上面說的是圖的直接業務簡單查詢,但還有一種場景是用圖來進行機器學習,比如 GNN 和 GCN 用圖來做特征,這塊本文就不展開講述,流程和上面有所不同。
那,什么時候用圖數據庫,什么時候用圖計算呢?

如上圖所示,有限點的拓展就比較適合用圖數據庫,或者說 Nebula Graph 來實現;而全局挖掘就比較適合用圖計算。從圖計算的流程上來看,簡單粗暴地講,圖計算就是把一批數據撈到內存中,一次性計算完,然后“吐”出來,再進行下一步的過濾和處理。至于它是如何計算的,圖計算里面配有計算引擎。
現在我們來問個問題,如果要找全圖點度 Top10 的點,應該用什么?
自然是圖計算,圖計算也就是 OLAP 主打的是吞吐,即一次性能處理多少數據;而圖數據庫,主要是應對 OLTP 場景,側重低延遲,就是查詢有多快,以及支持多大量的并發請求 QPS。
只要我們記住圖數據庫和圖計算各自的擅長場景,就比較好處理相關的業務。
大圖優化
像傳統關系型數據庫中,業務無限膨脹的話,就需要做分庫分表。圖也是類似的,在大圖上做某些查詢時,你會發現性能很差,這時候你就需要進行分圖處理。像上面說到過的關系細化和加速查詢,比如我現在只關心進程關系,在特定業務場景下就需要將進程關系單獨設計成一張圖。這就是圖的一個優化手段。或者,你也可以進行業務隔離。像現在的業務是針對推薦場景,剩下的安全場景是否要放置在同一個圖空間下呢?如果業務量不大的情況下,是可以的。但是如果是數據量大的話,還是需要同傳統數據庫一樣進行業務隔離,什么業務進入什么圖。
這里延伸一下,分圖場景下如何進行多圖查詢呢?簡單來說就是進程一張圖,網絡是一張圖,這時候要查詢進程和網絡的關系。業界的話,管這個叫做查詢端融合。雖然你要查詢的數據是 2 張圖,但是我假裝你是在一張圖上進行查詢。
編輯:黃飛
?

















 工商網監
工商網監
評論