 電子發燒友App
電子發燒友App


"不可糾正的內存錯誤是數據中心的主要故障原因之一"
本文利用今日頭條服務器集群中3個主要的雙內聯存儲模塊( dual inline memory module,DIMM )制造商的大規模現場數據,對可糾正錯誤( corrected error,CE )和不可糾正錯誤( uncorrectable error,UE )進行了實證研究。與以往的研究不同,本文的研究首次理解了CE和DIMM部件號的錯誤比特信息之間的關系。與傳統的芯片失效糾錯碼( Chipkill Error Correction Code,ECC )不同,在當今的Intel服務器平臺中,ECC被削弱,無法容忍單個芯片的某些錯誤位模式。利用可獲取的粗粒度ECC知識,本文從錯誤比特信息中推導出一個新的指標:Risky CE。從數據中,本文表明新指標在測試來自不同制造商的DIMM的未來UE發生時具有一致的高靈敏度和特異性。
背景
一、數據收集
研究中使用的DRAM錯誤數據來自字節跳動的一個服務器集群。在服務器農場,大約有10萬臺服務器采用SkyLake或Cascade Lake架構,即英特爾最新的服務器架構。包括互聯網服務、在線數據饋送、離線數據分析等在內的各種工作負載混合在服務器上運行。服務器上的DIMM來自三星、海力士和美光。
DRAM錯誤數據主要通過Linux檢錯糾錯驅動程序采集。同時獲取每個CE的微觀地址信息,即channel、rank、bank、row和column。通過引用驅動程序日志中記錄的讀取重試寄存器來提取每個CE的錯誤位信息。數據收集時間為2021年1月至8月。期間未啟用硬件保護技術(例如,部分緩存行空閑、行空閑、行空閑或片空閑)和軟件保護技術(例如,操作系統中的頁面裁剪)。值得注意的是,在這項研究中,特別感興趣的是過去CE歷史中未來UE發生的線索。對于具有一個UE的DIMM,本文將其誤差日志限制為其第一個UE出現的時間(即只保留UE之前的CE歷史)。在此期間,超過1萬個DIMM上觀測到超過800萬個CE。在574個DIMM上觀測到UE。
特別要注意的是,本文使用的數據集和先前工作中有兩點是比較特殊的:
1、對于每個CE,能夠知道哪些比特是錯誤的。這使得可以基于CE的錯誤比特模式進行進一步的分析,以更好地理解與UE的相關性。
2、對于每個DIMM,記錄其部分編號。這樣可以看到,某種分析是否可以推廣到來自制造商的不同零件編號,或者與特定零件編號相關。
表中給出了DRAM故障數據集關于不同DIMM廠商和零件編號的特征。
新的風險指標
一、Risky CE
與Chipkill ECC不同,當代英特爾服務器平臺上的ECC并不能保證完全覆蓋單個芯片在訪存過程中數據位上的所有可能錯誤。雖然精確的ECC算法是高度機密的,并且從未公開過,但英特爾確實概述了一些粗粒度的錯誤位模式,這些錯誤位模式被保證是完全可糾正的。如果一個錯誤的實際錯誤位模式不能被其中任何一個完全可以糾正的模式所覆蓋,則該錯誤有小概率是不可糾正的。
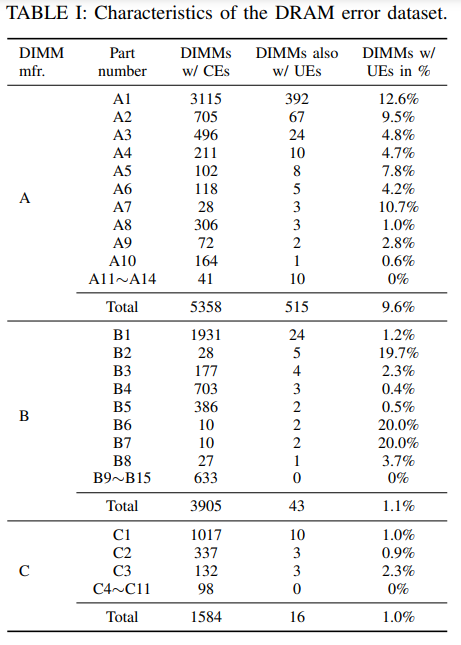
如圖所示,假設將兩種完全可糾正模式具象化為圖(a)和(b)。圖(d)和圖(e)所示情況即為完全可糾正的比特錯誤模式,因為其錯誤的比特被完全可糾正模式完全覆蓋,但是圖(c)既不能被(a)覆蓋,也不能被(b)覆蓋,因此可以被認為存在概率不可糾正,當出現這種情況的CE時,就被認為是Risky CE。
二、新指標
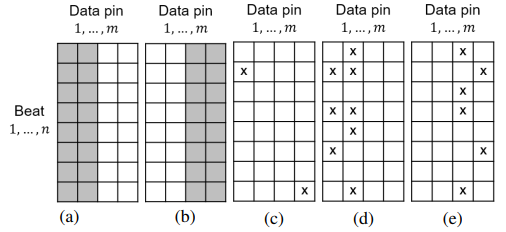
將每個制造商的DIMM分為兩個互斥的種群,僅有CE的DIMM和同時有UE的DIMM。圖中的 ( a )、( b )和( c )分別比較了來自制造商A、B和C的兩個種群的風險CE數的累積分布函數( CDF )。在所有3個DIMM制造商中一致的觀察是CDF在風險CE數1處顯著偏離。對于僅含CE的DIMMs,80 %以上的風險CE數為0。相比之下,約80 %的DIMMs同時具有UEs,則風險CE數至少為1。這表明風險CE的發生是兩個人群之間的一個突出的判別器。值得注意的是,風險CE數大于1并不能提供更好的區分度,因為風險CE數越大,兩個CDF的散度就越小。
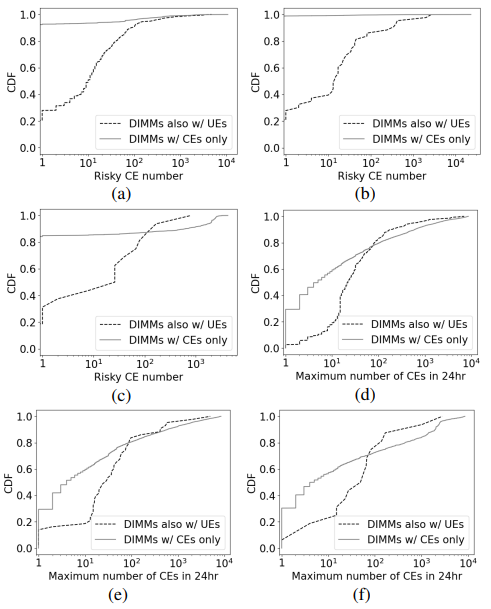
考慮到CE數量作為未來UEs 的常用指標,為了進行比較,分別在圖3 ( d )、( e )和( f )中繪制了來自制造商A、B和C的兩個種群的最大CE率(即CE歷史中過去24小時內的最大CE數)的CDF。兩個種群的CDF更接近。無論選擇哪種CE速率,它都不能從3個DIMM制造商中的任何一個中提供兩個群體之間令人滿意的區分。這表明CE率的區分度要低得多。
三、新指標的應用
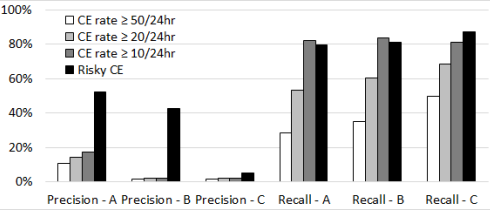
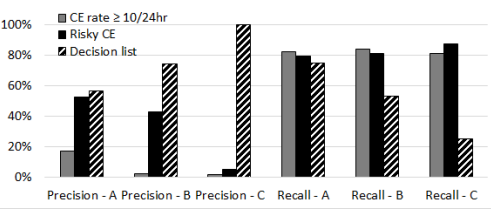
圖中顯示了直接使用新的風險CE指標對3個制造商的DIMM進行UE預測的準確率和召回率。為了比較,以最常用的預測因子,CE率預測因子的不同參數作為基線。雖然傳統的CE率預測器可以達到與低閾值(即過去24小時內有10次CEs)相當的召回率,但其精度明顯低于新的風險CE預測器。值得注意的是,即使是來自C廠商的DIMMs,雖然風險CE預測器的精度很低( 5.3 % ),但仍遠高于基線( < 2 % )。
四、使UE預測更加精確
1、用于UE預測的學習決策列表
[Part_number:] Risky_CE [∧()]→UE.()
簡單的講,決策列表就是從現象推導到結果。其中,端口號和故障位置是可選的。用于將故障推廣到同一廠商的同一端口或者同一故障位置。
文章提出通過迭代識別有信心的預測規則,以精確驅動的方式學習決策列表。在每次迭代中,執行兩個步驟。第一步是根據當前的訓練數據枚舉不同的規則并選擇最有信心的(即,精確)規則。第二步是從訓練數據中移除新識別規則覆蓋的正負訓練樣本。文章不限制迭代次數。相反,在最佳候選規則的置信度下降到預定義的閾值θ confidence之前,繼續決策列表的擴展。通過選擇最自信的規則,關注每次迭代中的精度。通過多次迭代擴展列表,逐步提高召回率。
Precision and Recall:
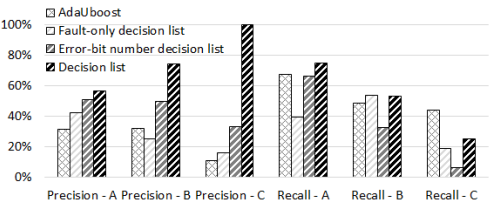
圖中顯示了新的決策列表方法在在線UE預測中的準確率和召回率。在圖中,還將使用新的風險CE指標和性能最好的CE率預測器的UE預測結果進行比較。可見,結合風險CE指標、微觀故障指標和DIMM零件編號信息,3個主要廠家的DIMM UE預測精度均得到提高。這種改進對于來自制造商B和C的DIMM來說尤為顯著。為了達到更高的精度,召回率變得相當低。
Comparison with Other Baselines:
?
?
五、分析
1、How the Decision Lists Look Like:

圖中展示了學習到的一些典型的決策列表示例。注意,對于每個制造商的DIMM,從10次交叉驗證中學習到10個列表。由于不同運行中訓練集的差異,這些列表之間存在較小的差異。這里挑選那些決策列表,它們的規則在許多其他列表中都能觀察到。針對不同廠家DIMM的決策列表也存在較大差異,說明針對不同廠家DIMM預測UE需要不同的預測機制。
2、Precision-Recall Trade-off:
在先前圖中,第三條規則比第一條規則更具一般性,即任何適用于第一條規則的數據樣本也適用于第三條規則。然而,第一條規則以較高的置信度得分。如果將θconfidence (選擇規則的置信度閾值)設置為較高的值0.5,則不會選擇第三條規則。10折交叉驗證的準確率提高了63.1 % ( vs.56.7 % ),召回率降低了32.8 %。這表明提高θ置信度限制了決策列表中選擇的規則,從而以較低的召回率換取較高的準確率。
3、Vital Role of the Risky CE Indicator and the DIMM Part Number Information:
由表可知,對于制造商C的DIMM,無論是默認的風險CE指標,還是其與DIMM零件編號信息的簡單組合,在UE預測中的表現均不準確。但是,在給定銀行故障指示器就位的前提下,將DIMM部件號和風險CE指示器結合在一起提高了精度。

相比之下,去除其中的任何一個都表現得不夠好。(注意,在分析單個規則的性能時,使用特定DIMM制造商的所有數據,而不是交叉驗證中的測試數據。)實際上,對于制造商C的DIMM,在所有的交叉驗證運行中,只學習到了零件編號為C1的DIMM特有的規則。對于其他部件編號的DIMM,數據非常稀疏,即使我們已經在10折交叉驗證中使用了90 %的數據進行訓練,也無法識別出置信度高于θ confidence的可靠的UE預測規則。
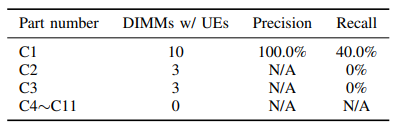
表中給出了不同DIMM部件編號的預測結果,可以看出,對于部分部件編號為C1的DIMM,由于成功識別了UE易發故障,UE預測具有很高的精度( 100 %精度)。該預測覆蓋了相當一部分( 40 %召回率)的零件編號的DIMM,但沒有覆蓋其他零件編號的DIMM。這表明識別出的UE易發故障是特定于某個DIMM部件號的。
4、Importance of Generalization across Different Part Numbers:
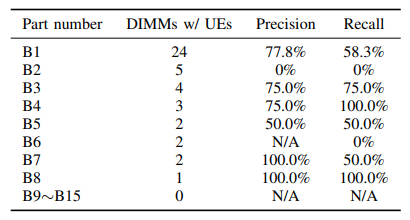
雖然有時DIMM零件編號信息很重要,但在某些情況下,在規則的前提下使零件編號可選,從而允許在同一制造商的不同零件編號之間進行泛化。對于廠商B的DIMM,在10折交叉驗證學習到的規則的前提條件中,只看到DIMM零件編號B1的存在。然后將預測結果分解為表中不同的DIMM零件編號。雖然部分編號B3、B4、B5、B7和B8不在學習到的規則的前置條件中,但是一些更通用的規則提供了不錯的性能。這表明UE易發故障可以通用于某個DIMM制造商。
編輯:黃飛
?

















 工商網監
工商網監
評論