 電子發燒友App
電子發燒友App


動機和背景
IPLFS是一個避免文件系統層垃圾回收的日志結構文件系統。作者發現,日志結構文件系統的僅追加寫入方式會帶來不可避免的文件系統層次垃圾回收。十數年來,學界已經提出多種緩解垃圾回收開銷的方式,包括空閑時段垃圾回收、預先垃圾回收、選擇最合適的回收段算法等。
與此同時,SSD的設備端垃圾回收同樣給存儲系統帶來可觀的帶寬下降和延遲。當日志結構文件系統和SSD一起使用時,兩端的垃圾回收開銷可能會疊加影響。為了解決這種問題,大多數工作提出讓主機端直接管理閃存頁,以解決設備端垃圾回收開銷,比如最近的ZNS技術等。
而作者發現,隨著計算機系統的發展,大多數組件,比如CPU、內存等都已經支持虛擬化技術,而存儲設備則不支持虛擬化。因此作者提出,可以將SSD的LBA和PBA分離,實現SSD的地址虛擬化,從而避免文件系統垃圾回收。
IPLFS的設計與實現
IPLFS的設計目標是在保持日志結構文件系統僅追加更新特性的同時,完全取消文件系統層垃圾回收。IPLFS的設計共有三個重點:多區域分區布局、無GC的元數據設計、全新的丟棄映射和丟棄日志。
多區域分區布局
為了減小LBA映射表的大小,IPLFS把整個LBA地址空間分為7個大小相同的區域,分別是一個用于存儲超級塊、節點映射表等數據的IPLFS元數據區,和6個對應存儲F2FS不同熱度、不同類型數據的段的數據區。在地址空間使用上,IPLFS使用最高的3比特作為區域標識符,剩余58位用來作為地址使用,因此每個區域可以保存258個塊,共計1ZB。
元數據設計
元數據的設計要求最小化原始F2FS元數據的盤上數據修改。由于IPLFLS不再需要文件系統垃圾回收,同時由于地址空間過大,因此IPLFS僅移除了F2FS中用于垃圾回收和塊丟棄的兩個元數據:反向映射表和塊分配映射位圖。
而IPLFS仍舊保留了節點分配表NAT,而NAT的大小決定了文件系統中文件數量的上限,因此NAT的大小不再是傳統的由LBA大小決定,而修改為由PBA大小決定。被移除的分配映射表和反向映射信息由全新的丟棄映射位圖和丟棄日志取代。
丟棄無效塊
F2FS使用塊分配位圖有兩個原因:一是代表每個段空間利用率,二是追蹤最新無效的文件系統塊。而在IPLFS中,空間利用率不再重要,而被無效的塊仍然需要追蹤。IPLFS使用使用丟棄映射位圖取代了F2FS的塊分配位圖,用于表征自最后一個檢查點后無效的塊,每個位圖表示一個分區,每個分區包括一個或多個段。一個丟棄映射位圖包括分區的起始地址和映射位圖兩部分。
當文件系統標識一個塊無效,則設置對應的丟棄映射表的無效位,多個丟棄映射表使用哈希表組織為一組,使用段編號作為鍵。當塊被無效時,IPLFS搜索哈希表并查找對應丟棄映射位圖,若找到則更新位圖;若更新位圖不存在則分配一個新的丟棄映射位圖并更新,之后將新的位圖插入哈希表。
段的大小和文件系統性能存在trade-off。段大小越大,丟棄映射位圖越大。段越小則哈希表中的丟棄映射位圖條目越多,查詢延遲升高。實驗表明,最佳段大小為1GB,同時平衡性能和內存壓力。
在每個檢查點觸發時,IPLFS掃描哈希表,對每個丟棄映射位圖構造丟棄指令,之后移除對應丟棄映射位圖。IPLFS會定期提交丟棄指令。IPLFS單獨開啟一個線程用于分發丟棄指令,每次喚醒最多下發16條丟棄指令,IPLFS的丟棄指令分發相較F2FS更加激進,無論是否存在等待中的IO,均下發丟棄指令;而F2FS需要等待直到文件系統中無等待中的IO存在再下發丟棄指令。在實驗中發現發現激進的下發策略獲得了更好的基準測試表現,因為這樣做使得SSD的GC更加高效,避免了寫放大。
丟棄日志
由于缺乏塊分配位圖,IPLFS難以感知存儲空間泄露,即flash頁存儲了無效的FS塊,但是FS從不回收這些頁。如系統崩潰時為下發的丟棄指令。F2FS中恢復程序會根據恢復的塊分配位圖重建丟棄指令。為了解決這個問題,IPLFS使用了丟棄日志。丟棄日志在下發丟棄指令前建立丟棄指令檢查點,保證丟棄指令再下發到設備前被持久化。在檢查點包中建立丟棄日志區保存丟棄日志。在每個檢查點,IPLFS檢查丟棄映射表并創建丟棄指令,IPLFS在丟棄日志區記錄丟棄指令的信息(起始LBA、長度),之后將日志同步落盤,檢查點后,IPLFS喚醒丟棄線程提交丟棄指令。
重建丟棄指令分為兩個階段,首先是回滾恢復,恢復模塊讀取最近的檢查點包,重建丟棄指令;之后是前滾恢復,前滾恢復時識別在最近檢查點后被寫入文件,對比節點塊,對比前滾恢復階段的節點塊和檢查點時的節點快,識別修改記錄,針對新分配的節點塊更新文件映射表。
中間映射表設計
為了解決過大的LBA占用過多SSD映射資源的問題,IPLFS在OpenSSD平臺重新設計了中間映射表。首先,中間映射表采用LBA充足映射方式,作者稱之為間隔映射,設計和Interval tree類似,樹高限制為3,通過增加根節點扇出的方式增加映射節點,以此降低地址轉換相關內存開銷。間隔映射以分區數組的形式組織存儲區域。每個分區都是一個映射段數組,每個分區對應16GB,而每個段對應16MB;間隔映射樹的根節點保存一組分區節點隊列,每個節點維護單個分區的數據。一個分區節點維護1024個映射表節點作為子節點,每個映射表節點維護一個段的LBA-PBA映射。
映射中間層是一塊需要IM樹進行映射的邏輯分區,映射中間層使用其對應邏輯分區的第一個分區的起始LBA和最后一個分區的起始LBA表示。當分區創建時,映射中間層會為IPLFS分區創建6個獨立的IM樹,分別對應IPLFS的6個數據段。
活躍中間層表示的是對應映射中間層中活躍的已使用分區的窗口。活躍分區類似,活躍中間層起始于對應映射中間層中第一個有效分區,結束于對應映射中間層中最后一個有效分區。當活躍中間層表中第一個分區被無效時,其起始分區被更新;當新的分區加到活躍中間層末端時,其結束分區被更新。隨著FS老化,活躍中間層的地址表示窗口向高處移動,當活躍中間層終點移動到接近映射中間層終點時,中間映射表會構造新的根節點和新的映射中間層以更好容納不斷變化的活躍中間層。
評估
IPLFS實現在F2FS(Linux 5.11.0)上,中間映射表使用OpenSSD(230GB ,8通道)實現。測試環境采用PC服務器(I7-4770K)+8GB DRAM配合OpenSSD實現。
文件系統垃圾回收消除效果實驗
首先測試消除文件系統層垃圾回收的前后性能表現,測試方式為:在SSD上構建30GB邏輯空間的F2FS,用4線程隨機寫28GB文件,每2s檢測吞吐量。測試發現,當F2FS開始進行文件系統層垃圾回收時,IO性能下降到之前的以下,如下圖所示。
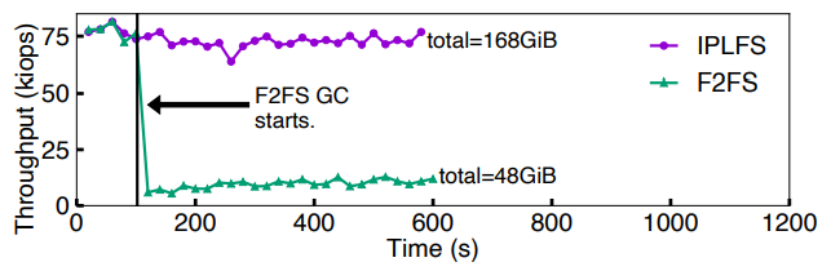
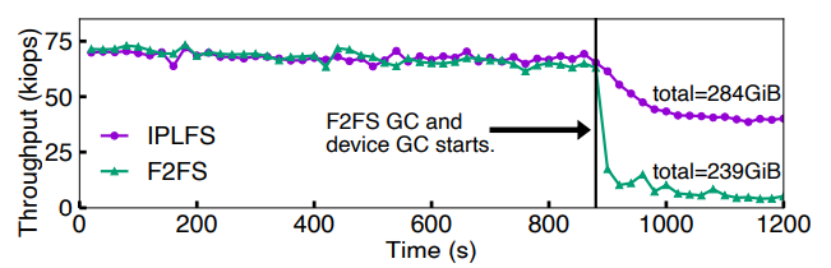
接著作者測試了文件系統層垃圾回收和設備端垃圾回收對性能的影響權重。測試方式為:使用與OpenSSD物理容量相同的邏輯分區大小共230GB,隨機寫210GB的文件。結果表明,當F2FS開始垃圾回收時,吞吐量下降到接近;而IPLFS消除了文件系統層垃圾回收,但是無法消除設備側垃圾回收,當OpenSSD開始設備層垃圾回收時,性能下降60%左右。因此作者認為,文件系統層垃圾回收對性能的影響比設備層垃圾回收更大。
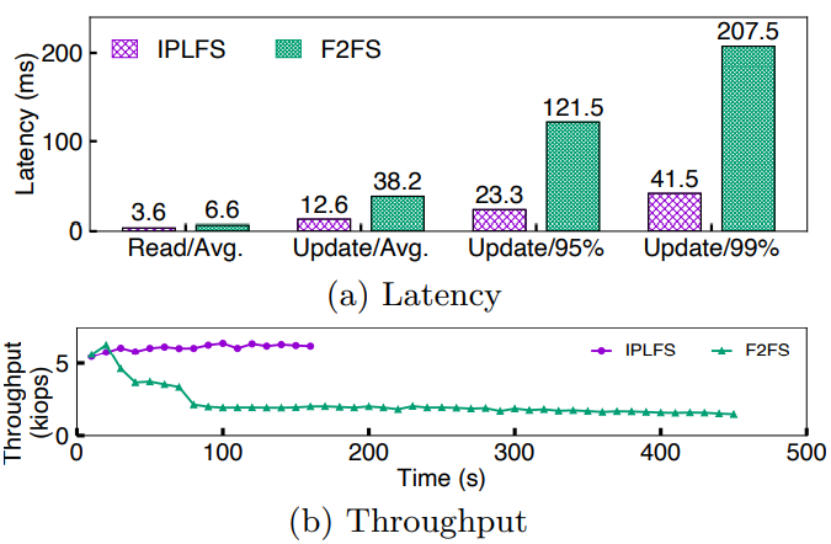
最后,作者使用MySQL數據庫和YCSB-A負載測試數據庫操作受文件系統垃圾回收的影響情況。YCSB-A負載包括等量的讀更新操作。從下圖的吞吐量、延遲變化曲線可以看出,開始測試時文件系統達到90%占用率,因此快速觸發文件系統層垃圾回收。IPLFS的平均讀延遲和平均更新延遲僅為F2FS的和。同時作者從實驗結果發現:取消文件系統垃圾回收可以顯著提升尾端延遲表現,IPLFS的95%和99%尾延遲相對F2FS分別降低5.2X和5X,并且IPLFS吞吐量保持穩定。
IPLFS的丟棄策略
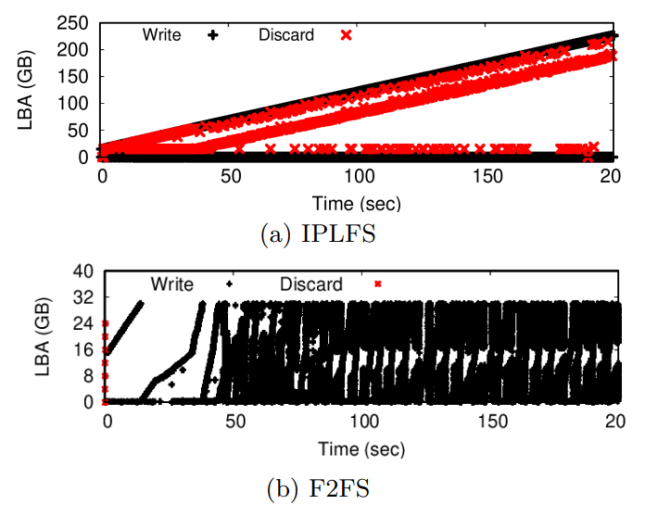
之后進行的測試目的是測試激進的丟棄策略對設備層垃圾回收和應用性能的影響。作者采用Filebench的fileserver負載,創建50個線程,更新/刪除2MB文件。測試發現,在全占用率下,IPLFS的寫放大比F2FS更低,同時吞吐量提升24%。對結果進行分析后,作者認為更激進的丟棄策略節省了FTL在垃圾回收時的遷移數量,因此IPLFS在寫放大和基準測試方面有了顯著改善。通過IO trace分析,作者發現IPLFS比F2FS更頻繁的提交丟棄指令,這是由于F2FS僅在無等待IO時提交丟棄指令。然而在測試中,極少有不存咋等待中IO的情況。
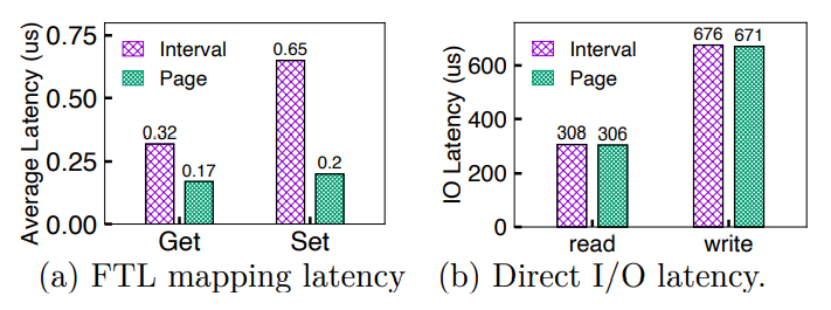
地址轉換開銷測試
首先作者進行了地址轉換延遲的測試,測試方法為使用fio對10GB文件進行4線程隨機寫操作。測試發現,IPLFS的中間映射方式比傳統的頁映射延遲長88%。作者分析這是因為中間映射層在地址轉換時使用的是多索引查找,而當構建新的映射條目時,中間映射層的延遲為頁映射的3.3倍。
之后作者進行了端到端延遲測試,測試發現中間映射層和頁映射在讀寫延遲上幾乎相同,如下圖所示,而這是因為實際訪問中,Nand的訪問延時和設備數據傳輸延時是延遲的主要部分,而FTL中的延遲影響微不足道。
總結
作者提出了一種用于無限分區的日志結構文件系統IPLFS。將文件系統分區大小從物理存儲大小中分離出來,并使得邏輯文件系統的分區大小實際上無限大,這樣就可以使日志結構的文件系統免于回收無效的文件系統塊。為了維護超大邏輯文件系統分區的映射信息,作者開發了中間映射層,只為活躍的LBA區域維護LBA-PBA映射。通過將IPLFS和中間映射層結合在一起,作者成功減輕了日志結構文件系統回收無效塊的開銷。
編輯:黃飛












 工商網監
工商網監
評論