 電子發燒友App
電子發燒友App


概述
Flash名稱的由來,Flash的擦除操作是以block塊為單位的,與此相對應的是其他很多存儲設備,是以bit位為最小讀取/寫入的單位,Flash是一次性地擦除整個塊:在發送一個擦除命令后,一次性地將一個block,常見的塊的大小是128KB/256KB,全部擦除為1,也就是里面的內容全部都是0xFF了,由于是一下子就擦除了,相對來說,擦除用的時間很短,可以用一閃而過來形容,所以,叫做Flash Memory。所以一般將Flash翻譯為 (快速)閃存。
NAND Flash 在嵌入式系統中有著廣泛的應用,負載平均和壞塊管理是與之相關的兩個核心議題。Uboot 和 Linux 系統對 NAND 的操作都封裝了對這兩個問題的處理方法。本文首先講述Nandflash基礎知識,然后介紹現有的幾類壞塊管理(BBM)方法,通過分析典型嵌入式系統的 NAND 存儲表,指出了輕量級管理方法的優勢所在,分析了當前廣泛使用的輕量級管理方法,指出其缺陷所在并詳細說明了改進方法。
基礎知識
Flash的硬件實現機制
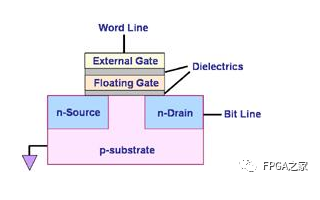
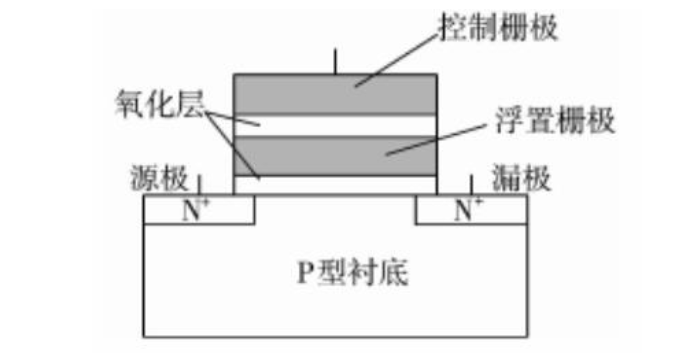
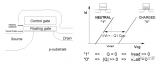
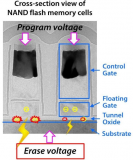
Flash的內部存儲是MOSFET,里面有個懸浮門(Floating Gate),是真正存儲數據的單元。
在Flash之前,紫外線可擦除(uv-erasable)的EPROM,就已經采用了Floating Gate存儲數據這一技術了。
典型的Flash內存物理結構
?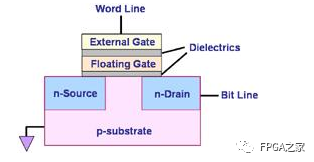
數據在Flash內存單元中是以電荷(electrical charge) 形式存儲的。存儲電荷的多少,取決于圖中的外部門(external gate)所被施加的電壓,其控制了是向存儲單元中沖入電荷還是使其釋放電荷。而數據的表示,以所存儲的電荷的電壓是否超過一個特定的閾值Vth來表示,因此,Flash的存儲單元的默認值,不是0(其他常見的存儲設備,比如硬盤燈,默認值為0),而是1,而如果將電荷釋放掉,電壓降低到一定程度,表述數字0。
NandFlash的簡介
Nand flash成本相對低,說白了就是便宜,缺點是使用中數據讀寫容易出錯,所以一般都需要有對應的軟件或者硬件的數據校驗算法,統稱為ECC。但優點是,相對來說容量比較大,現在常見的Nand Flash都是1GB,2GB,更大的8GB的都有了,相對來說,價格便宜,因此適合用來存儲大量的數據。其在嵌入式系統中的作用,相當于PC上的硬盤,用于存儲大量數據。
SLC和MLC
Nand Flash按照內部存儲數據單元的電壓的不同層次,也就是單個內存單元中,是存儲1位數據,還是多位數據,可以分為SLC和MLC。那么軟件如何識別系統上使用過的SLC還是MLC呢?Nand Flash設計中,有個命令叫做Read ID,讀取ID,讀取好幾個字節,一般最少是4個,新的芯片,支持5個甚至更多,從這些字節中,可以解析出很多相關的信息,比如此Nand Flash內部是幾個芯片(chip)所組成的,每個chip包含了幾片(Plane),每一片中的頁大小,塊大小,等等。在這些信息中,其中有一個,就是識別此flash是SLC還是MLC。
?oob / Redundant Area / Spare Area
每一個頁,對應還有一塊區域,叫做空閑區域(spare area)/冗余區域(redundant area),而Linux系統中,一般叫做OOB(Out Of Band),這個區域,是最初基于Nand Flash的硬件特性:數據在讀寫時候相對容易錯誤,所以為了保證數據的正確性,必須要有對應的檢測和糾錯機制,此機制被叫做EDC(Error Detection Code)/ECC(Error Code Correction, 或者 Error Checking and Correcting),所以設計了多余的區域,用于放置數據的校驗值。
Oob的讀寫操作,一般是隨著頁的操作一起完成的,即讀寫頁的時候,對應地就讀寫了oob。
關于oob具體用途,總結起來有:
標記是否是壞快
存儲ECC數據
存儲一些和文件系統相關的數據。如jffs2就會用到這些空間存儲一些特定信息,而yaffs2文件系統,會在oob中,存放很多和自己文件系統相關的信息。
Bad Block Management壞塊管理
Nand Flash由于其物理特性,只有有限的擦寫次數,超過那個次數,基本上就是壞了。在使用過程中,有些Nand Flash的block會出現被用壞了,當發現了,要及時將此block標注為壞塊,不再使用。于此相關的管理工作,屬于Nand Flash的壞塊管理的一部分工作。
Wear-Leveling負載平衡
Nand Flash的block管理,還包括負載平衡。
正是由于Nand Flash的block,都是有一定壽命限制的,所以如果你每次都往同一個block擦除然后寫入數據,那么那個block就很容易被用壞了,所以我們要去管理一下,將這么多次的對同一個block的操作,平均分布到其他一些block上面,使得在block的使用上,相對較平均,這樣相對來說,可以更能充分利用Nand Flash。
?ECC錯誤校驗碼
Nand Flash物理特性上使得其數據讀寫過程中會發生一定幾率的錯誤,所以要有個對應的錯誤檢測和糾正的機制,于是才有此ECC,用于數據錯誤的檢測與糾正。Nand Flash的ECC,常見的算法有海明碼和BCH,這類算法的實現,可以是軟件也可以是硬件。不同系統,根據自己的需求,采用對應的軟件或者是硬件。
相對來說,硬件實現這類ECC算法,肯定要比軟件速度要快,但是多加了對應的硬件部分,所以成本相對要高些。如果系統對于性能要求不是很高,那么可以采用軟件實現這類ECC算法,但是由于增加了數據讀取和寫入前后要做的數據錯誤檢測和糾錯,所以性能相對要降低一些,即Nand Flash的讀取和寫入速度相對會有所影響。
其中,Linux中的軟件實現ECC算法,即NAND_ECC_SOFT模式,就是用的對應的海明碼。
而對于目前常見的MLC的Nand Flash來說,由于容量比較大,動輒2GB,4GB,8GB等,常用BCH算法。BCH算法,相對來說,算法比較復雜。
筆者由于水平有限,目前仍未完全搞懂BCH算法的原理。
BCH算法,通常是由對應的Nand Flash的Controller中,包含對應的硬件BCH ECC模塊,實現了BCH算法,而作為軟件方面,需要在讀取數據后,寫入數據之前,分別操作對應BCH相關的寄存器,設置成BCH模式,然后讀取對應的BCH狀態寄存器,得知是否有錯誤,和生成的BCH校驗碼,用于寫入。
其具體代碼是如何操作這些寄存器的,由于是和具體的硬件,具體的nand flash的controller不同而不同,無法用同一的代碼。如果你是nand flash驅動開發者,自然會得到對應的起nand flash的controller部分的datasheet,按照手冊說明,去操作即可。
不過,額外說明一下的是,關于BCH算法,往往是要從專門的做軟件算法的廠家購買的,但是Micron之前在網上放出一個免費版本的BCH算法。
位反轉
Nand Flash的位反轉現象,主要是由以下一些原因/效應所導致:
漂移效應(Drifting Effects)
漂移效應指的是,Nand Flash中cell的電壓值,慢慢地變了,變的和原始值不一樣了。
編程干擾所產生的錯誤(Program-Disturb Errors)
此現象有時候也叫做,過度編程效應(over-program effect)。
對于某個頁面的編程操作,即寫操作,引起非相關的其他的頁面的某個位跳變了。
讀操作干擾產生的錯誤(Read-Disturb Errors)
此效應是,對一個頁進行數據讀取操作,卻使得對應的某個位的數據,產生了永久性的變化,即Nand Flash上的該位的值變了。
對應位反轉的類型,Nand Flash位反轉的類型和解決辦法,有兩種:
一種是nand flash物理上的數據存儲的單元上的數據,是正確的,只是在讀取此數據出來的數據中的某位,發生變化,出現了位反轉,即讀取出來的數據中,某位錯了,本來是0變成1,或者本來是1變成0了。此處可以成為軟件上位反轉。此數據位的錯誤,當然可以通過一定的校驗算法檢測并糾正。
另外一種,就是nand flash中的物理存儲單元中,對應的某個位,物理上發生了變化,原來是1的,變成了0,或原來是0的,變成了1,發生了物理上的位的數據變化。此處可以成為硬件上的位反轉。此錯誤,由于是物理上發生的,雖然讀取出來的數據的錯誤,可以通過軟件或硬件去檢測并糾正過來,但是物理上真正發生的位的變化,則沒辦法改變了。不過個人理解,好像也是可以通過擦除Erase整個數據塊Block的方式去擦除此錯誤,不過在之后的Nand Flash的使用過程中,估計此位還是很可能繼續發生同樣的硬件的位反轉的錯誤。
以上兩種類型的位反轉,其實對于從Nand Flash讀取出來的數據來說,解決其中的錯誤的位的方法,都是一樣的,即通過一定的校驗算法,常稱為ECC,去檢測出來,或檢測并糾正錯誤。
如果只是單獨檢測錯誤,那么如果發現數據有誤,那么再重新讀取一次即可。
實際中更多的做法是,ECC校驗發現有錯誤,會有對應的算法去找出哪位錯誤并且糾正過來。
其中對錯誤的檢測和糾正,具體的實現方式,有軟件算法,也有硬件實現,即硬件Nand Flash的控制器controller本身包含對應的硬件模塊以實現數據的校驗和糾錯的。
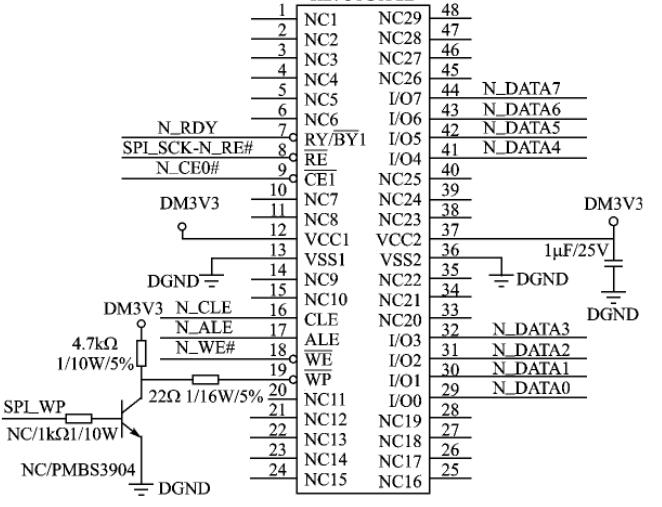
Nand Flash引腳功能的中文說明
| 引腳名稱 | 引腳功能 |
|---|---|
| I/O0 ~ I/O7 | 用于輸入地址/數據/命令,輸出數據 |
| CLE | Command Latch Enable,命令鎖存使能,在輸入命令之前,要先在模式寄存器中,設置CLE使能 |
| ALE | Address Latch Enable,地址鎖存使能,在輸入地址之前,要先在模式寄存器中,設置ALE使能 |
| CE# | Chip Enable,芯片使能,在操作Nand Flash之前,要先選中此芯片,才能操作 |
| RE# | Read Enable,讀使能,在讀取數據之前,要先使CE#有效。 |
| WE# | Write Enable,寫使能, 在寫取數據之前,要先使WE#有效 |
| WP# | Write Protect,寫保護 |
| R/B# | Ready/Busy Output,就緒/忙,主要用于在發送完編程/擦除命令后,檢測這些操作是否完成,忙,表示編程/擦除操作仍在進行中,就緒表示操作完成 |
| Vcc | Power,電源 |
| Vss | Ground,接地 |
| N.C | Non-Connection,未定義,未連接 |
| ? | 在數據手冊中,你常會看到,對于一個引腳定義,有些字母上面帶一橫杠的,那是說明此引腳/信號是低電平有效,比如你上面看到的RE頭上有個橫線,就是說明,此RE是低電平有效,此外,為了書寫方便,在字母后面加“#”,也是表示低電平有效,比如我上面寫的CE#;如果字母頭上啥都沒有,就是默認的高電平有效,比如上面的CLE,就是高電平有效。 |
Nand Flash的一些typical特性
頁擦除時間是200us,有些慢的有800us
塊擦除時間是1.5ms
頁數據讀取到數據寄存器的時間一般是20us
串行訪問(Serial access)讀取一個數據的時間是25ns,而一些舊的Nand Flash是30ns,甚至是50ns
輸入輸出端口是地址和數據以及命令一起multiplex復用的
Nand Flash的編程/擦除的壽命:即,最多允許10萬次的編程/擦除,達到和接近于之前常見的Nor Flash,幾乎是同樣的使用壽命了。
封裝形式:48引腳的TSOP1封裝 或 52引腳的ULGA封裝
Nand Flash控制器與Nand Flash芯片
我們寫驅動,是寫Nand Flash 控制器的驅動,而不是Nand Flash 芯片的驅動,因為獨立的Nand Flash芯片,一般來說,是很少直接拿來用的,多數都是硬件上有對應的硬件的Nand Flash的控制器,去操作和控制Nand Flash,包括提供時鐘信號,提供硬件ECC校驗等等功能,我們所寫的驅動軟件,是去操作Nand Flash的控制器
然后由控制器去操作Nand Flash芯片,實現我們所要的功能。
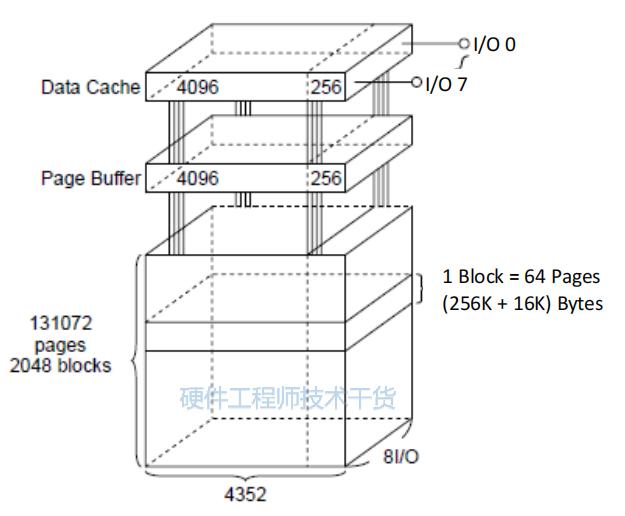
由于Nand Flash讀取和編程操作來說,一般最小單位是頁,所以Nand Flash在硬件設計時候,就考慮到這一特性,對于每一片(Plane),都有一個對應的區域專門用于存放,將要寫入到物理存儲單元中去的或者剛從存儲單元中讀取出來的,一頁的數據,這個數據緩存區,本質上就是一個緩存buffer,但是只是此處datasheet里面把其叫做頁寄存器page register而已,實際將其理解為頁緩存,更貼切原意。
而正是因為有些人不了解此內部結構,才容易產生之前遇到的某人的誤解,以為內存里面的數據,通過Nand Flash的FIFO,寫入到Nand Flash里面去,就以為立刻實現了實際數據寫入到物理存儲單元中了,而實際上只是寫到了這個頁緩存中,只有當你再發送了對應的編程第二階段的確認命令,即0x10,之后,實際的編程動作才開始,才開始把頁緩存中的數據,一點點寫到物理存儲單元中去。
數據的流向如圖
壞塊的標記
具體標記的地方是,對于現在常見的頁大小為2K的Nand Flash,是塊中第一個頁的oob起始位置的第1個字節(舊的小頁面,pagesize是512B甚至256B的Nand Flash,壞塊標記是第6個字節),如果不是0xFF,就說明是壞塊。相對應的是,所有正常的塊,好的塊,里面所有數據都是0xFF的。
對于壞塊的標記,本質上,也只是對應的flash上的某些字節的數據是非0xFF而已,所以,只要是數據,就是可以讀取和寫入的。也就意味著,可以寫入其他值,也就把這個壞塊標記信息破壞了。對于出廠時的壞塊,一般是不建議將標記好的信息擦除掉的。
uboot中有個命令是
?
nand scrub
?
就可以將塊中所有的內容都擦除了,包括壞塊標記,不論是出廠時的,還是后來使用過程中出現而新標記的。
?
nand erase
?
只擦除好的塊,對于已經標記壞塊的塊,不要輕易擦除掉,否則就很難區分哪些是出廠時就壞的,哪些是后來使用過程中用壞的了。
NAND 壞塊管理方法分類
目前,NAND 壞塊管理方法可分為如下幾類:
基于 FTL 芯片的壞塊管理
它使用一個額外的 FTL (Flash Translation Layer)芯片對 NAND 進行管理,對外部屏蔽了壞塊信息,U 盤、SD 卡、MMC 卡以及固態硬盤都使用這種管理方法。這種方式簡化了 NAND 操作,但也使壞塊信息對外部而言不可見,如果系統中出現了可能和壞塊相關的問題,定位和調試變得困難,另外,FTL 芯片也需要額外的硬件成本。
基于NAND 文件系統的壞塊管理
JFFS2、 YAFFS2、 FlashFx 這些專門針對 NAND 的文件系統可以對壞塊進行管理。
NAND 管理中間件
有一些中間件(Middleware)專門用于 NAND 管理,比如 UBI。
輕量級 NAND 壞塊管理
對 NAND 進行管理的硬件或軟件模塊,不僅提供壞塊管理,同時也支持對 NAND 的擦寫操作進行負載平均。而輕量級的壞塊管理只專注于壞塊,并不提供擦寫負載平均的支持,而且,它也不依賴于任何第三方的庫。因此,輕量級的壞塊管理方式降低了系統的復雜度,而且免去了加載文件系統或初始化中間件的時間,在嵌入式系統中有著廣泛的應用。
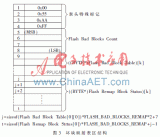
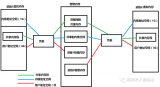
圖 1 展示了幾種典型的嵌入式系統中 NAND 內部的內容布局。如果需要頻繁地對 NAND 寫入各種數據,最好使用 NAND 文件系統或者 NAND 管理中間件對需要寫入的區域進行管理。而那些很少需要更新的區域,比如 bootloader、VPD 和 Kernel,只需進行輕量級的壞塊管理,不需要進行負載平均。很多的嵌入式系統中,需要寫入 NAND 的數據量很少,頻度也較低,比如路由器、打印機、PLC ?等,這些系統完全可以僅使用輕量級的壞塊管理方式。
典型嵌入式系統的 Nand Memory MaP
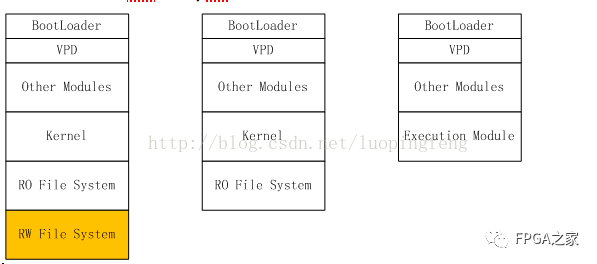
Uboot 的輕量級壞塊管理方法
NAND 壞塊管理都是基于壞塊表(BBT)的,通過這張表來標識系統中的所有壞塊。所以,不同的管理方法之間的差異可以通過以下幾個問題來找到答案。
如何初始化和讀取壞塊表?
產生新的壞塊時,如何標記并更新壞塊表?
如何保存壞塊表?是否有保存時斷電保護機制?
對 NAND 寫入數據時,如果當前塊是壞塊,如何找到可替換的好塊?
Uboot 是目前使用最為廣泛的 bootloader,它提供了兩種輕量級壞塊管理方法,可稱之為基本型和改進型。通過下表,我們可以看到兩者的差異。
?Uboot 的兩種壞塊管理方法對比
| ? | 基本型 | 改進型 |
|---|---|---|
| 初始化、讀取 BBT | 系統每次初始化時,掃描整個 NAND,讀取所有塊的出廠壞塊標志,建立 BBT,占用較多啟動時間。 | 系統第一次初始化時,掃描整清單 1. BBM 頭信個 NAND 建立 BBT。之后每次初始化時,掃描 BBT 所在區域,如果發現當前塊的簽名和壞塊表的簽名(一個特定的字符串)相符,就讀取當前塊的數據作為 BBT。 |
| 更新 BBT | 擦寫操作產生新的壞塊時,更新內存中的 BBT,同時將壞塊的出廠壞塊標記從 0xFF 改為 0x00。擦寫出錯后仍然對壞塊進行操作—更改出廠壞塊標記,存在安全風險。而且,也無法區分哪些是出廠壞塊,哪些是使用過程中產生的壞塊。 | 擦寫操作產生新的壞塊時,更新內存中的 BBT,同時將更新后的 BBT 立刻寫入 NAND 或其他 NVRAM 中。 |
| 保存 BBT | 不保存 | 在 NAND 或其他 NVRAM 中保存一份,無掉電保護機制。 |
| 壞塊替換方法 | 如果當前塊是壞塊,將數據寫入下一個塊。 | 如果當前塊是壞塊,將數據寫入下一個塊。 |
雖然 uboot 的改進型壞塊管理方法的做了一些改進,但它仍然有三個主要的缺點。
出現壞塊,則將數據順序寫入下一個好塊。如果 NAND 中存放了多個軟件模塊,則每個模塊都需要預留一個較大的空間作為備用的好塊,這會浪費較多的 NAND 空間。通常,每個模塊預留的備用好塊數為 NAND 芯片所允許的最大壞塊數,該值因不同的芯片而有所不同,典型值為 20 或 80。假設 NAND 是大頁類型,總共有 N 個模塊,則總共需要預留的空間大小為 N*80*128KB。
讀取 BBT 時僅檢查簽名,沒有對 BBT 的數據做校驗。
沒有掉電保護機制。如果在保存 BBT 時斷電,BBT 將丟失。
改進的輕量級壞塊管理方法
針對現有管理方法的缺陷,本文提出了一種更加安全高效的管理方法,將從以下三個方面闡述其實現原理。
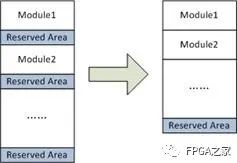
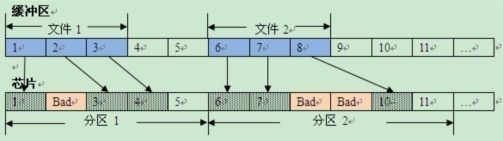
共用好塊池機制
首先,使用一個統一的備用好塊池,為所有存放在 NAND 中的模塊提供可替換的好塊。這樣,就不需要在每個模塊后面放置一個保留區,提高了 NAND 的空間利用率。
共用好塊池示意圖
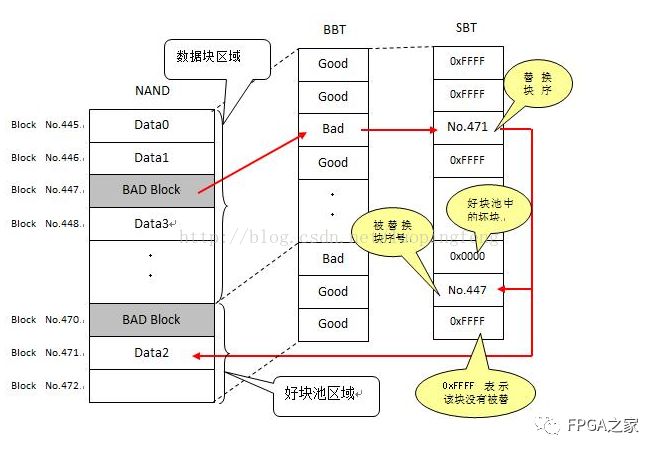
為了實現共用好塊池,需要建立一個從壞塊到好塊的映射,所以,除了 BBT 之外,還需定義一個替換表(SBT)。這樣一來,當讀第 i 個塊的數據時,如果發現 BBT 中記錄該塊為壞塊,就去 SBT 中查詢其替換塊;如果寫第 i 個塊出錯,需要在 BBT 中標記該塊為壞塊,同時從好塊池中獲取一個新的好塊,假設其序號為 j,然后將此好塊的序號 j 寫入 SBT 中的第 i 個字節,而且 SBT ?的第 j 個字節寫序號 i。SBT 中的這種雙向映射可確保數據的可靠性。此外,好塊池中的塊也有可能成為壞塊,如果掃描時發現是壞塊,則將 SBT 中的對應位置標記為 0x00,如果是在寫的過程中出錯,則除了在 SBT 對應位置標記 0x00 之外,還要更新雙向映射數據。
?BBT/SBT 映射示意圖
安全的 BBT/SBT 數據校驗機制
傳統方法僅檢查 BBT 所在塊的簽名,將讀到的前幾個字節和一個特征字符串進行比較,如果一致,就認為當前塊的數據為 BBT,然后讀取接下來的 BBT 數據,但并不對 BBT 的數據做校驗。如果 BBT 保存在 NAND 中,數據的有效性是可以得到驗證的,因為 NAND 控制器或驅動一般都會對數據做 ECC 校驗。但是,大多數控制器使用的 ECC 算法也僅僅能糾正一個 bit、發現 2 兩個? bit 的錯誤。如果 BBT 保存在其他的沒有 ECC 校驗機制的存儲體中,比如 NOR Flash,沒有對 BBT 的數據進行校驗顯然是不安全的。
為了更加可靠和靈活地驗證 BBT/SBT 數據,定義下面這個結構體來描述 BBM 信息。
BBM 頭信息
?
typedef struct {
UINT8 acSignature[4];/* BBM 簽名 */
UINT32 ulBBToffset;/* BBT 偏移 */
UINT32 ulSBToffset;/* SBT 偏移 */
UINT16 usBlockNum;/* BBM 管理的 block 數目 */
UINT16 usSBTstart;/* SBT 所在位置的起始 block 序號 */
UINT16 usSBtop;/* SBT top block */
UINT16 usSBnum;/* SBT number */
UINT32 ulBBTcrc;/* BBT 數據 CRC 校驗碼 */
UINT32 ulSBTcrc;/* SBT 數據 CRC 校驗碼 */
UINT32 ulHeadcrc;/* BBM 頭信息 CRC 校驗碼 */
} BBM_HEAD
?
BBT/SBT 的保存形式
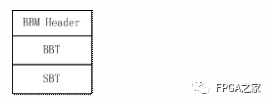
使用三重 CRC 校驗機制,無論 BBT 保存在哪種存儲體中,都可以更加嚴格地驗證數據的有效性。
安全的掉電保存機制
傳統的方法僅保存一份 BBT 數據,如果在寫 BBT 時系統掉電,則 BBT 丟失,系統將可能無法正常啟動或工作。為安全起見,本文所述方法將同時保留三個備份,如果在寫某個備份時掉電,則還有兩個完好的備份。最壞的情況是,如果在寫第一個備份時掉電,則當前最新的一個壞塊信息丟失。
讀取壞塊表時,順序讀取三個備份,如果發現三個備份的數據不一致,用記錄的壞塊數最多的備份為當前的有效備份,同時立刻更新另外兩備份。
總結
本文介紹了NandFlash基礎知識和幾類 NAND 壞塊管理方法,指出了 uboot 的輕量級管理方法的缺陷,提出了一種改進的方法,提高了 NAND 的利用率及壞塊管理的安全性,可對嵌入式開發起到有很好的借鑒作用。
???
?
審核編輯:劉清










 工商網監
工商網監
評論