 電子發燒友App
電子發燒友App


?
如何利用神經網絡預測閃存尾端延遲的發生
由于用戶對低且穩定的延遲(微秒級)的需求越來越大,人們對SSD的百分比延遲越來越關心,即SSD有99%的概率可以提供低且穩定的延遲,但有1%的概率產生幾倍于正常情況的延遲,而這1%的高延遲被稱為尾端延遲。尾端延遲有什么影響?如何降低尾端延遲的影響?如何在存儲環境下利用神經網絡?這些疑問,本文將一一解答。
尾端延遲與Hedged Request
百分比延遲
????也許你已經查了維基百科中”百分比延遲“的定義,但我想對大多數人而言有點晦澀難懂,下面我將舉一個簡單的例子以幫助你理解。
????首先,我們先列舉出一系列收集到的延遲:
23,20,21,20,23,20,45,21,25,25
????對它們排序:
20,20,20,21,21,23,23,25,25,45
????接下來可以選擇前x%的延遲,例如假設我們想要得到50th百分比延遲,則選擇前5個延遲:
20,20,20,21,21
????然后選擇這一組延遲中最大的那個——即21——就是這一組延遲中的50th百分比延遲(也可以寫作p50),同理,p90是25。
尾端延遲
????尾端延遲就是百分比延遲中末尾的(通常p99之后)那些延遲。看起來尾端延遲占比并不多,但當系統處理的請求達到10^6個數量級,可能足足有104個請求處理延遲遠高于正常情況——你不會想成為那不幸的1%,對嗎?
????分析SSD的內部行為后,本文作者認為尾端延遲的產生源自SSD內部日益復雜的內部活動,如垃圾回收、負載均衡等,和用戶請求的沖突。為了降低尾端延遲或者降低尾端延遲的影響,業界提出的方案分為兩大類:
白盒子方案
此時SSD內部的行為可知,通過改進SSD內部架構來降低尾端延遲。這種方式無疑是直接而強有效的,但是不利于推廣到市場。
灰盒子方案
此時不需要修改SSD的內部架構,但是需要修改上層的軟件棧。
黑盒子方案
以各種預測為代表,既不需要修改上層軟件棧,也不需要修改SSD內部架構,是目前最流行的解決方案。其中一個經典的方案是Hedged Request,它的原理和應用環境將在下文中介紹。
Hedged Request
????為了保證數據安全、實現負載均衡,現代的存儲系統通常存在一定冗余,而多個不同的SSD的內部行為同時和用戶請求產生沖突的概率非常低。基于這樣的思考,Hedged ?Request將一個請求發給一個SSD后,若等待請求完成的時間超過了閾值,則重發請求到另一個可用的SSD。如下圖所示:
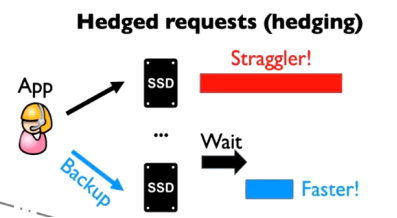
????然而,傳統Hedged Request中,快SSD需要等待一段時間(等待慢SSD處理的時間超過閾值)后才能處理請求,對于微秒級SSD而言,這個等待時間是致命的。如果可以學習SSD的特征,預測將要變慢的SSD而及時將請求重發到快SSD中,則可以節約出等待的時間,從而降低閃存組的尾端延遲——這就是LinnOS完成的工作,如下圖所示,用戶發送請求后,若經過LinnOS網絡預測得知該SSD將變慢,則提前告知用戶重發請求,隨后請求將被送到下一個SSD,減少了Hedged Request中的等待時間。
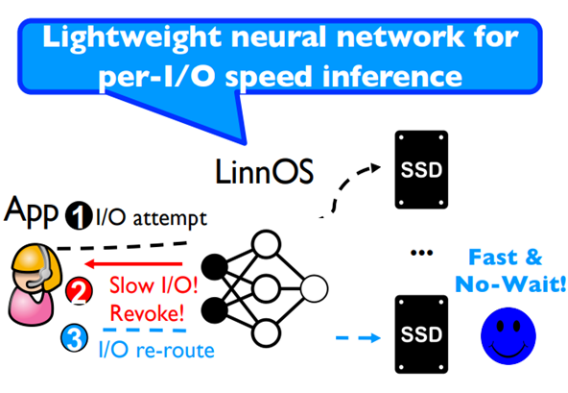
LinnOS的三大挑戰
????設計LinnOS存在三大挑戰,接下來將一一闡述。
對用戶輸出什么結果?
????需要輸出具體的延遲(如120μs)嗎?雖然這樣更靈活,但是一方面,對用戶而言,120μs或者125μs其實區別不大,另一方面,如此精確的輸出意味著準確率低,并不劃算。那么如果輸出一個延遲范圍,如80~100μs、100~120μs呢?此時準確率稍高了些,但不夠(僅60%-70%),處于區間交界處的延遲往往預測不準確。回顧Hedged Request的原理,其實對用戶而言,知道SSD是”快“或者”慢“就足夠了!所以LinnOS使用簡單的二分類模型。
使用什么信息進行預測?
????看起來一系列信息都和SSD快或慢有關:讀寫請求?請求的塊內偏移?長期的寫入歷史?然而,作者發現這些請求都對提高精確度沒有明顯幫助。首先,由于當前SSD常有內置寫緩存,寫之后的讀延遲常常沒有明顯提高,更為常見的其實是數據從緩存”沖“(flush)入SSD后,讀延遲會更高。其次,一組I/O請求會通過條帶均勻地寫入各個通道或者芯片,它們寫入同一個芯片的概率很低,所以塊內偏移這個特征其實并不重要。最后,GC或者flush通常發生時間短,短期寫入歷史足矣預測。
????因此,可以使用SSD當前I/O隊列長度來預測SSD快或者慢:一個直觀的感受是,當I/O隊列較長時,SSD處理通常比較慢。但是這樣并不能體現SSD的內部活動的發生,因此額外增加了歷史四條請求進入SSD時的隊列長度和完成請求的時間。若某個請求進入SSD時隊列短而完成請求的時間長,意味著SSD內部行為可能和用戶請求沖突了。
如何最小化預測錯誤的影響?
????作者分析發現,若將一個快的SSD預測為慢的從而錯誤地重發了,將帶來微秒級延遲,而若將一個慢的SSD預測為快,將帶來毫秒級延遲,比第一種情況嚴重許多,所以作者在訓練時對第二種情況施加了更加嚴重的懲罰以減少它們的發生。此外,還補充了hedged request以減少預測失敗的損失。
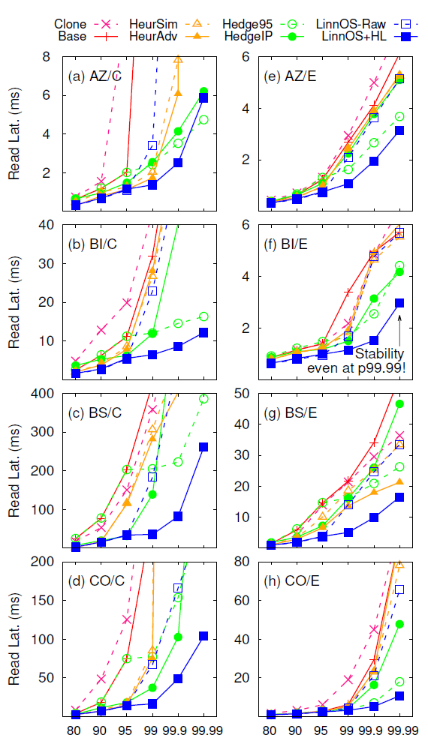
實驗結果與總結
????作者上層使用了不同的軟件產生負載,底層使用同構的消費級SSD陣列或者異構企業級SSD陣列測試它們的表現,以讀延遲為指標展示結果。總共比較了7種不同的方案:
Base:無優化
Clone:同時發送兩份請求,選擇先返回的SSD的結果返回給用戶
Hedge95:等待p95之后重發請求
Hedge IP(inflection point):和上一個相比,使用針對負載優化后的等待時間
HeurSim:隊列較長時重發請求
HeurAdv:隊列較長、且考慮歷史信息(和LinnOS一樣)后決定重發請求
LinnOS-Raw:沒有hedged補償的LinnOS
LinnOS+HL:最終的LinnOS方案
實驗結果如下圖:
審核編輯:劉清









 工商網監
工商網監
評論