本篇簡單介紹了如何使用SQLite的C語言API中最基礎的幾個函數,實現對數據庫的讀寫,后續再介紹其它常用的C語言API函數的用法。
2022-09-25 08:52:32 1126
1126 
將模型稱為 “視覺語言” 模型是什么意思?一個結合了視覺和語言模態的模型?但這到底是什么意思呢?
2023-03-03 09:49:37664 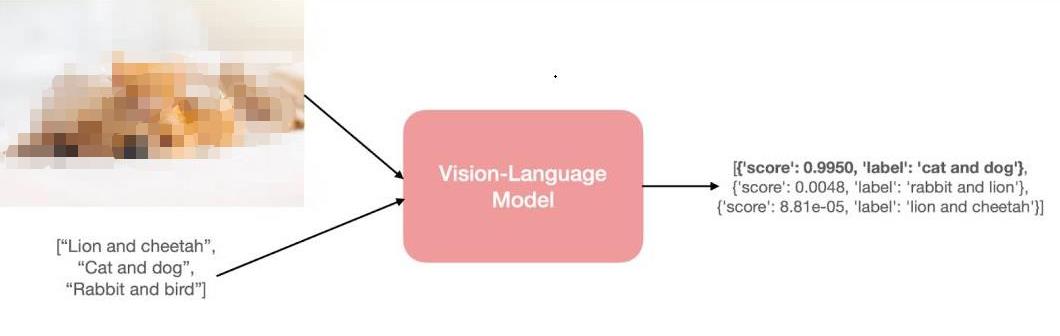
大型語言模型的出現極大地推動了自然語言處理領域的進步,但同時也存在一些局限性,比如模型可能會產生看似合理但實際上是錯誤或虛假的內容,這一現象被稱為幻覺(hallucination)。幻覺的存在使得
2023-08-15 09:33:451090 
最新研究揭示,盡管大語言模型LLMs在語言理解上表現出色,但在邏輯推理方面仍有待提高。為此,研究者們推出了GLoRE,一個全新的邏輯推理評估基準,包含12個數據集,覆蓋三大任務類型。
2023-11-23 15:05:16472 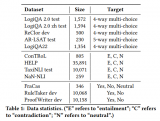
在大型語言模型(LLMs)的應用中,提示工程(Prompt Engineering)是一種關鍵技術,用于引導模型生成特定輸出或執行特定任務。通過精心設計的提示,可以顯著提高LLMs的性能和適用性。本文將介紹提示工程的主要方法和技巧,包括少樣本提示、提示壓縮和提示生成。
2023-12-13 14:21:47273 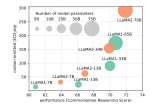
NVIDIA NeMo 大型語言模型(LLM)服務幫助開發者定制大規模語言模型;NVIDIA BioNeMo 服務幫助研究人員生成和預測分子、蛋白質及 DNA ? 美國加利福尼亞州圣克拉拉
2022-09-21 15:24:52433 
電子發燒友網報道(文/李彎彎)大語言模型(LLM)是基于海量文本數據訓練的深度學習模型。它不僅能夠生成自然語言文本,還能夠深入理解文本含義,處理各種自然語言任務,如文本摘要、問答、翻譯
2024-01-02 09:28:331267 ,最終為降低頂事件發生概率提供有效的改進途徑。研究案例采用該定量模型,以文件破壞重大風險作為故障樹頂事件,得出其概率和底事件概率重要度,找出了引起安全問題的存儲風險,從而有效地保證軟件開發過程
2010-04-24 09:54:02
的問題,而對于不同地址的訪問并不是緩存一致性協議所要考慮的問題。存儲一致性問題在任何具有或不具有高速緩存的系統中都存在,雖然高速緩存的存在有可能進一步加劇存儲一致性問題。存儲器模型(memory model
2022-04-11 15:42:37
關于數據庫,只要知道簡單的SQL語言,就可以輕松的進行操作。有些復雜的測試數據,非常適合用數據庫存儲。附件是我編寫的吉時利2400測***曲線的例子,標準件的波形圖保存在了數據庫中。通過此例程,可以掌握簡單的數據庫操作。
2018-12-10 21:23:10
傳輸數據。與逐字節數據傳輸模型不同,讀/寫數據模型可以處理數據塊;c)使用緩沖隊列傳輸模型——允許客戶端對數據傳輸進行隊列處理。考慮到前面提到的每個模型的最佳應用是什么?在第一種方法中,我嘗試使用第一個
2020-04-23 13:56:48
請問一下,我在做tdms數據存儲練習的時候,搭建的模型如下,只有一個組(嘗試),組里面有兩個通道,模型如下,但最終用excel表格打開數據文件,卻只有一個通道(第一組),請問這是怎么回事呢?我搭的模型有問題嗎?
2015-01-21 20:18:23
如圖,daq助手運行沒問題,單獨接一個波形圖的時候圖像和助手設置里面的一樣。但是接到存儲數據(右下角那堆)那部分的時候就發現有問題了,只能存100個數據,而且連續運行會出現錯誤數據,也是一百個這樣
2015-02-14 17:35:05
多種形式和任務。這個階段是從語言模型向對話模型轉變的關鍵,其核心難點在于如何構建訓練數據,包括訓練數據內部多個任務之間的關系、訓練數據與預訓練之間的關系及訓練數據的規模。
獎勵建模階段的目標是構建一個文本
2024-03-11 15:16:39
一個串口數據處理的VI程序,(串口通訊的數據可見20131112.dat文件), 實現對數據文件中的讀取、驗證、分析處理、顯示(數據需取絕對值---去除最高位的符號位即可,以十進制數的形式和曲線形式顯示)、存儲等。利用LabVIEW的強大信號分析處理功能,開發一套操作簡便的數據信息分析系統。
2013-11-29 12:01:13
。 3.大型應用監控系統 一般來說,大型監控系統都能達到一千點以上,最典型的案例就是平安城市。這類應用的最大特點就是系統龐大、復雜、數據量大,大部分都會采用分級存儲、中心集中備份的策略,對數據的存儲
2012-12-12 15:46:47
目錄:一、五大內存分區二、C語言程序的存儲區域三、C語言程序的段四、在C語言的程序中,對變量的使用還有以下注意五、程序中段的使用六、const的使用七、單片機C語言中的data、idata
2021-11-30 06:48:47
自然語言處理——53 語言模型(數據平滑)
2020-04-16 11:11:25
針對用戶對遠程數據存儲與異地數據備份的需求增加,提出一種基于IPv6協議的Internet存儲服務模型。設計應用層的Internet存儲訪問協議,結合IPv6協議的安全性特點設計安全存儲模型
2009-04-13 09:13:40 15
15 可以計算以2,10,e為底的對數
# 進行對數運算的IP核,可以計算以2,10,e為底的對數,最高可輸入24bit寬度的數據。# 由AHDL語言寫成,可在MaxplusII和QuartusII中使用,源代
2009-06-14 09:27:3453 提出了一個適用于入侵檢測系統的通用數據模型,并分析了該模型的存儲結構及其在入侵檢測領域中的應用。該模型用基特征和類特征的自然連接表示一類事件,采用二元存儲結
2009-06-29 08:20:4313 結合對象存儲的特點,提出基于QoS 的存儲系統模型。該模型將遷移任務劃分為細粒度的遷移請求,使對象存儲設備在實現數據遷移的同時能響應I/O 請求。元數據服務器按相同的
2009-10-07 11:56:599 C語言之自然對數的底e的計算,很好的C語言資料,快來學習吧。
2016-04-22 17:45:550 C語言教程之自然對數的底e的計算,很好的C語言資料,快來學習吧。
2016-04-22 17:45:550 C語言教程之對數組進行升序和降序排序,很好的C語言資料,快來學習吧。
2016-04-25 16:09:480 大型網絡異常數據庫的快速數據定位模型仿真_朱保鋒
2017-01-03 18:00:370 數據流編程模型將程序的計算與通信分離,暴露了應用程序潛在的并行性并簡化了編程難度。分布式計算框架利用廉價PC構建多核集群解決了大規模并行計算問題,但多核集群層次性存儲結構和處理單元對數據流程序的性能
2017-11-23 15:48:593 為了實現在線海量數據的高效存儲與訪問,在內存云分級存儲架構下,提出一種基于數據重要性的遷移模型( MMDS)。首先,通過數據本身的大小、時間重要性、用戶訪問總量等因素對數據本身的重要性進行計算;其次
2017-12-27 16:54:331 自然語言處理常用模型使用方法一、N元模型二、馬爾可夫模型以及隱馬爾可夫模型及目前常用的自然語言處理開源項目/開發包有哪些?
2017-12-28 15:42:305382 
如今有許多企業存儲討論的重點是將數據轉移到公共云上進行歸檔,因為進入的成本并不高,尤其是在需要即時容量的情況下。但是,一旦企業采用公共云,可能會出現這樣的情況,需要將數據遷移回本地部署的數據中心,以實現逆向云存儲戰略。
2018-06-14 09:01:293012 數據先要通過存儲層存儲下來,然后根據數據需求和目標來建立相應的數據模型和數據分析指標體系對數據進行分析產生價值。
2020-03-27 10:06:101017 伴隨著傳統企業數字化、智能化的腳步,數據中心的技術也同樣在不斷更新,無論是計算能力、存儲能力還是信息交互能力都在向前演進,大型數據中心憑借其強大運算能力、存儲能力備受廣大企業的歡迎。 不過,大型
2020-12-22 10:37:592199 在存儲的快速發展過程中,不同的廠商對云存儲提供了不同的結構模型,在這里,我們介紹一個比較有代表性的云存儲結構模型。
2020-12-25 11:23:263537 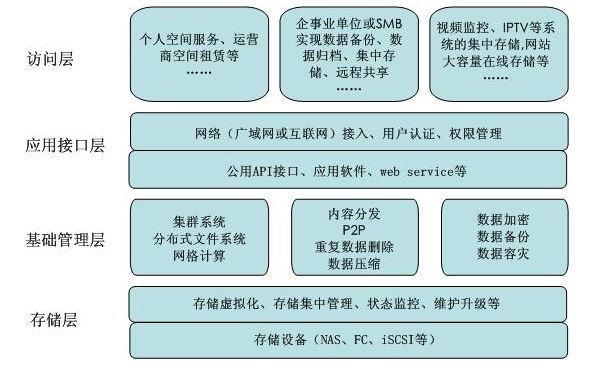
12月29日,華為針對數據存儲兩大業界難題,發布了2021年奧林帕斯懸紅,獎勵全球在數據存儲領域取得突破性貢獻的科研工作者。 在12月29日舉辦的2020全球數據存儲教授論壇上,華為針對數據存儲兩大
2020-12-30 13:39:092052 Python官方文檔說法是“Python數據模型”,大多數Python書籍作者說法是“Python對象模型”,它們是一個意思,表示“計算機編程語言中對象的屬性”。這句話有點抽象,只要知道對象是Python對數據的抽象,在Python中萬物皆對象就可以了。
2021-02-10 15:59:002278 
深度學習模型應用于自然語言處理任務時依賴大型、高質量的人工標注數據集。為降低深度學習模型對大型數據集的依賴,提出一種基于BERT的中文科技自然語言處理預訓練模型 ALICE。通過對遮罩語言模型進行
2021-05-07 10:08:1614 云存儲中的數據可能會遭受非法竊取或篡改,從而使用戶數據的機密性面臨威脅。為了更加安全、高效地存儲海量數據,提出一種攴持索引、可追溯、可驗證的云存儲與區塊鏈結合的存儲模型CBaS( Cloud
2021-05-10 16:07:357 NVIDIA為全球企業開發和部署大型語言模型打開了一扇新的大門——使這些企業能夠建立他們自己的、特定領域的聊天機器人、個人助理和其他AI應用程序,并能夠以前所未有的水平理解語言中的微妙和細微差別
2021-11-12 14:30:071327 目錄:一、五大內存分區二、C語言程序的存儲區域三、C語言程序的段四、在C語言的程序中,對變量的使用還有以下注意五、程序中段的使用六、const的使用七、單片機C語言中的data、idata
2021-11-20 20:36:0912 Keil中 數據的存儲code、data、idata、pdata、xdata、pdata模型選擇SMALL COMPACT LARGE
2021-12-05 11:36:055 浪潮存儲基于“云存智用 運籌新數據”的理念,不斷技術創新,將智能壓縮技術適配到存儲平臺,打造敏捷高效的存儲產品,在保障性能無損的情況下,提升數據存儲的效率,提高了存儲空間利用率,降低數據存儲成本,讓用戶能輕松應對數字經濟時代的海量數據的挑戰。
2022-04-08 09:27:426081 
由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:271173 NVIDIA NeMo 大型語言模型(LLM)服務幫助開發者定制大規模語言模型;NVIDIA BioNeMo 服務幫助研究人員生成和預測分子、蛋白質及 DNA
2022-09-22 10:42:29742 韓國先進的移動運營商構建包含數百億個參數的大型語言模型,并使用 NVIDIA DGX SuperPOD 平臺和 NeMo Megatron 框架訓練該模型。
2022-09-27 09:24:30914 隨著大型語言模型( LLM )的規模和復雜性不斷增長, NVIDIA 今天宣布更新 NeMo Megatron 框架,提供高達 30% 的訓練速度。
2022-10-10 15:39:42642 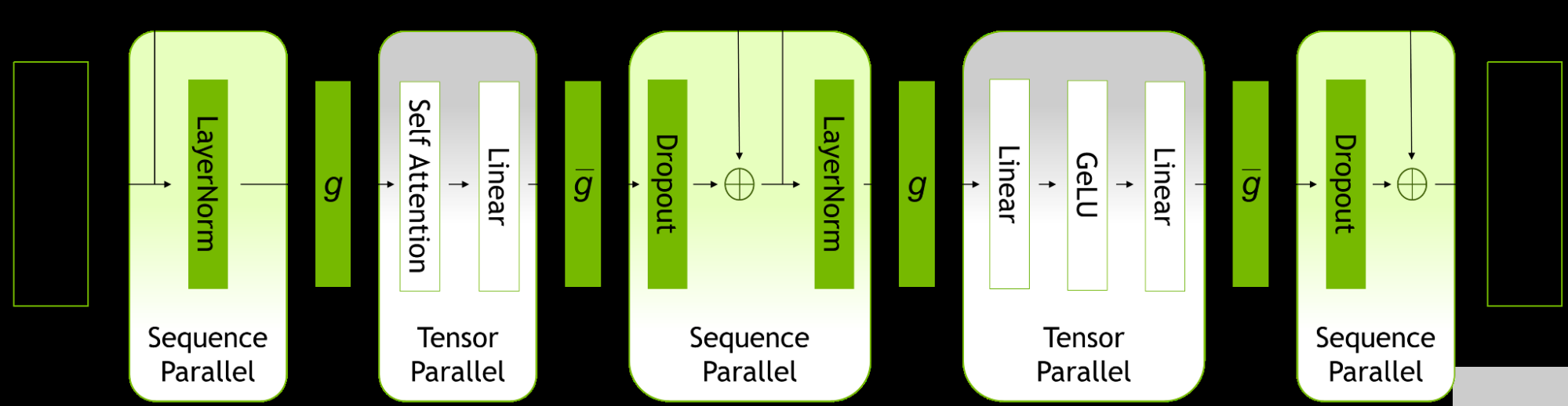
的 COVID-19 研究。一位決賽入圍選手教會了大型語言模型(LLMs)一種新的語言——基因序列,使這些模型能夠提供基因組學、流行病學和蛋白質工程方面的洞察。 這項開創性的成果發表于 10 月,是由來自美國阿貢國家實驗室、NVIDIA、芝加哥大學等組織機構的二
2022-11-16 21:40:02395 。 這一聯合團隊的研究指出,經過基因組學訓練的大型語言模型(LLM)可將應用擴展到大量基因組學任務。 該團隊使用 NVIDIA 的超級計算機 Cambridge-1 來訓練參數規模從 500M 到 2.5B 不等的各種大型語言模型(LLM)。這些模型在各種基因組數據集上進行了訓練,以探
2023-01-17 01:05:04443 BigCode 是一個開放的科學合作組織,致力于開發大型語言模型。近日他們開源了一個名為 SantaCoder 的語言模型,該模型擁有 11 億個參數
2023-01-17 14:29:53692 索引是一個數據庫,用于存儲爬蟲發現的信息。在索引層中進行了大量預處理,以最大限度地減少必須搜索的數據量。這最大限度地減少了延遲并最大限度地提高了搜索相關性。
2023-02-21 14:28:33719 最近,人們對大型語言模型所展示的強大能力(例如思維鏈 ^[2]^ 、便簽本 ^[3]^ )產生了極大的興趣,并開展了許多工作。我們將之統稱為大模型的突現能力 ^[4]^ ,這些能力可能只存在于大型模型
2023-02-22 11:16:05674 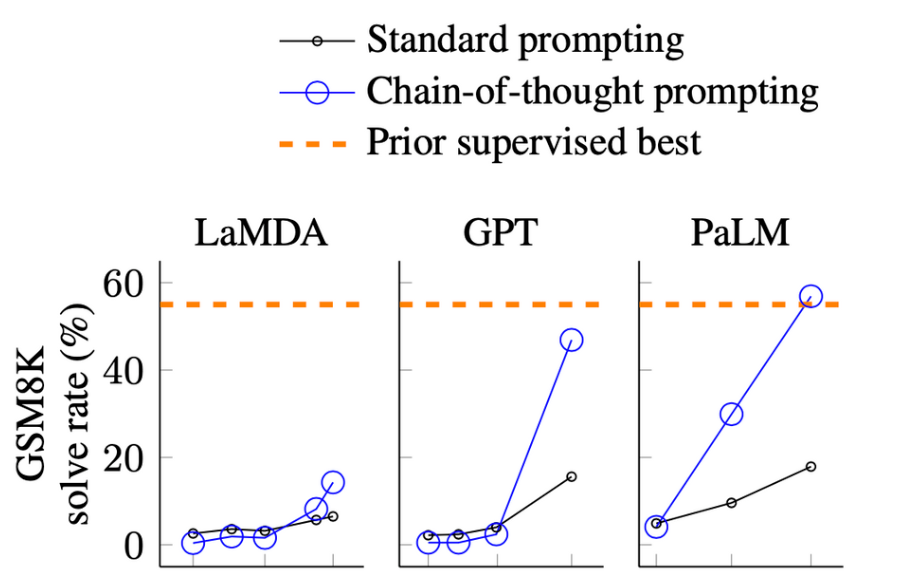
通過大規模數據集訓練來學習識別、總結、翻譯、預測和生成文本及其他內容。 大型語言模型是 Transformer 模型最成功的應用之一。它們不僅將人類的語言教給 AI,還可以幫助 AI 理解蛋白質、編寫軟件代碼等等。 除了加速翻譯軟件、聊天機器人
2023-02-23 19:50:043876 大型語言模型能識別、總結、翻譯、預測和生成文本及其他內容。
2023-03-08 13:57:006986 和運行自定義大型語言模型和生成式AI模型,這些模型專為企業所在領域的特定任務而創建,并且在專有數據上訓練。 ? Getty Images、Morningstar、Quantiphi、Shutterstock公
2023-03-22 13:45:40261 
能夠構建、完善和運行自定義大型語言模型和生成式 AI 模型,這些模型專為企業所在領域的特定任務而創建,并且在專有數據上訓練。 Getty Images、Morningstar、Quantiphi、Shutterst
2023-03-23 06:50:04365 NVIDIA NeMo 服務幫助企業將大型語言模型與其專有數據相結合,賦能智能聊天機器人、客戶服務等更多應用。 如今的大型語言模型知識淵博,但它們的工作方式有點像時間膠囊——所收集的信息僅限于第一次
2023-03-25 09:10:03274 能夠構建、完善和運行自定義大型語言模型和生成式 AI 模型,這些模型專為企業所在領域的特定任務而創建,并且在專有數據上訓練。 Getty Images、Morningstar、Quantiphi、Shutterst
2023-03-25 15:20:04285 對于任何沒有額外微調和強化學習的預訓練大型語言模型來說,用戶得到的回應質量可能參差不齊,并且可能包括冒犯性的語言和觀點。這有望隨著規模、更好的數據、社區反饋和優化而得到改善。
2023-04-24 10:07:062167 
GPT是基于Transformer架構的大語言模型,近年迭代演進迅速。構建語言模型是自然語言處理中最基本和最重要的任務之一。GPT是基于Transformer架構衍生出的生成式預訓練的單向語言模型,通過對大 量語料數據進行無監督學習
2023-04-28 10:01:59584 
近來NLP領域由于語言模型的發展取得了顛覆性的進展,擴大語言模型的規模帶來了一系列的性能提升,然而單單是擴大模型規模對于一些具有挑戰性的任務來說是不夠的
2023-05-10 11:13:171377 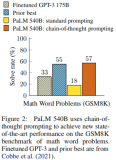
大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推理能力,但其只能處理文本數據。
2023-05-10 16:53:15700 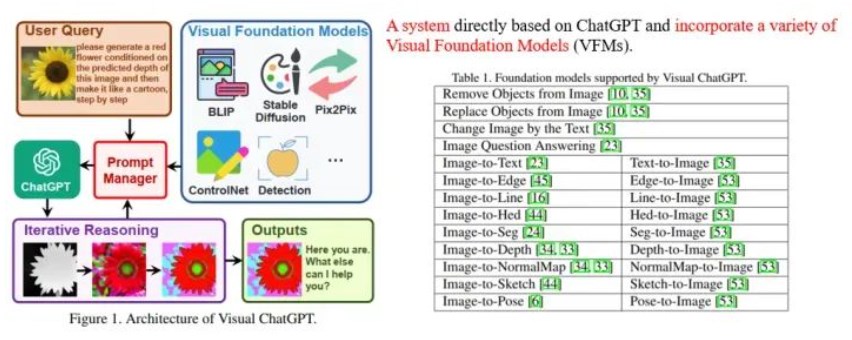
? 大型語言模型能否捕捉到它們所處理和生成的文本中的語義信息?這一問題在計算機科學和自然語言處理領域一直存在爭議。然而,MIT的一項新研究表明,僅基于文本形式訓練、用于預測下一個token的語言模型
2023-05-25 11:34:11434 
近日,IBM 存儲推出了基于其閃存產品 IBM FlashSystem 的新能力,幫助企業高效應對數據安全威脅。
2023-05-25 16:35:02829 ChatGPT 在 2022 年年底的橫空出世,引發了各行各業對生成式人工智能、大型語言模型和基礎模型的廣泛關注和討論,人工智能發展的“質變時刻”正在加速到來。作為人工智能應用的“三駕馬車
2023-05-25 16:36:22723 
大型語言模型研究的發展有三條技術路線:Bert 模式、GPT 模式、混合模式。其中國內大多采用混合模式, 多數主流大型語言模型走的是 GPT 技術路線,直到 2022 年底在 GPT-3.5 的基礎上產生了 ChatGPT。
2023-06-09 12:34:533158 
近年來,像 GPT-4 這樣的大型語言模型 (LLM) 因其在自然語言理解和生成方面的驚人能力而受到廣泛關注。但是,要根據特定任務或領域定制LLM,定制培訓是必要的。本文提供了有關自定義訓練 LLM 的詳細分步指南,其中包含代碼示例和示例。
2023-06-12 09:35:431781 他預計,深度學習和大型語言模型會繼續發展:這個領域的未來可能會有一小部分重大突破,加之許多細微改進,所有這些都將融入到一個龐大而復雜的工程體系。他還給出了一些有趣、可執行的思想實驗。
2023-06-12 16:38:48262 本文旨在更好地理解基于 Transformer 的大型語言模型(LLM)的內部機制,以提高它們的可靠性和可解釋性。 隨著大型語言模型(LLM)在使用和部署方面的不斷增加,打開黑箱并了解它們的內部
2023-06-25 15:08:49987 
?? 大型語言模型(LLM) 是一種深度學習算法,可以通過大規模數據集訓練來學習識別、總結、翻譯、預測和生成文本及其他內容。大語言模型(LLM)代表著 AI 領域的重大進步,并有望通過習得的知識改變
2023-07-05 10:27:351460 簡單來說,語言模型能夠以某種方式生成文本。它的應用十分廣泛,例如,可以用語言模型進行情感分析、標記有害內容、回答問題、概述文檔等等。但理論上,語言模型的潛力遠超以上常見任務。
2023-07-14 11:45:40454 
7月14日,華為發布大模型時代AI存儲新品, 為基礎模型訓練、行業模型訓練,細分場景模型訓練推理提供存儲最優解,釋放AI新動能。 企業在開發及實施大模型應用過程中,面臨四大挑戰: ● 首先,數據
2023-07-14 15:20:02475 
來源: DeepHub IMBA 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數據集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創意內容。 今年開始
2023-07-28 12:20:02440 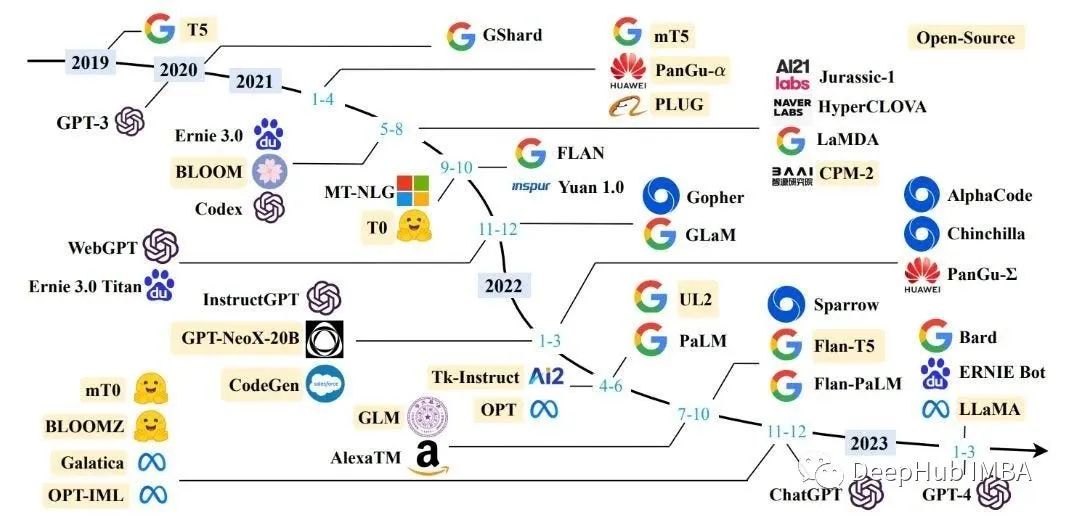
近日,美智庫蘭德公司高級工程師克里斯托弗·莫頓(Christopher Mouton)在C4ISRNET網站撰文,分析ChatGPT等大型語言模型的出現給國家安全帶來的新風險。主要觀點如下:
2023-08-04 11:44:53304 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數據集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創意內容。今年開始,人們對開源LLM越來越感興趣。這些模型
2023-08-01 00:21:27554 
對話文本數據,作為人類交流的生動表現,正成為訓練大型模型的寶貴資源。這些數據不僅蘊含了豐富的語言特點和人類交流方式,更在模型訓練中發揮著重要的意義,從而為其賦予更強大的智能和更自然的交流能力。 大型模型
2023-08-14 10:11:11368 。 大型模型,特別是基于深度學習的預訓練語言模型,如GPT-3.5,依賴于大規模的文本數據來進行訓練。這些模型之所以強大,源于它們從這些數據中學習到的語義、關聯和結構。文本數據中蘊含著豐富的知識、思想和信息,通過模型的
2023-08-14 10:06:23328 近日,清華大學新聞與傳播學院發布了《大語言模型綜合性能評估報告》,該報告對目前市場上的7個大型語言模型進行了全面的綜合評估。近年,大語言模型以其強大的自然語言處理能力,成為AI領域的一大熱點。它們
2023-08-10 08:32:01607 今天,Meta發布了Code Llama,一款可以使用文本提示生成代碼的大型語言模型(LLM)。
2023-08-25 09:06:57885 
,大型語言模型(Large Language Models,LLM)徹底改變了自然語言處理領域,使機器能夠生成類似人類的文本并進行有意義的對話。這些模型,例如OpenAI的GPT,擁有驚人的語言理解和生成能力。它們可以被用于廣泛的自然語言處理任務,包括文本生成、翻譯、自動摘要、情緒分析等
2023-09-04 16:55:25345 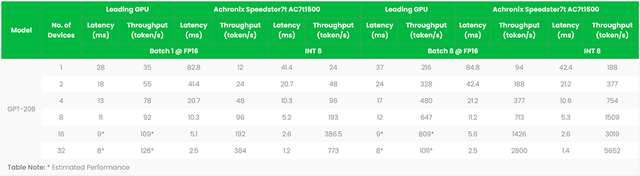
騰訊發布混元大語言模型 騰訊全球數字生態大會上騰訊正式發布了混元大語言模型,參數規模超千億,預訓練語料超2萬億tokens。 作為騰訊自研的通用大語言模型,混元大語言模型具有中文創作能力、任務執行
2023-09-07 10:23:54815 構建高質量的大語言模型數據集是訓練強大自然語言處理模型的關鍵一步。以下是一些關鍵步驟和考慮因素,有助于創建具有多樣性、準確性和時效性的數據集: 數據收集:數據集的首要任務是收集大量文本數據。這可
2023-09-11 17:00:04548 大語言模型涉及數據的通常有有多個階段(Aligning language models to follow instructions [1] ):pre-train、sft(supervised
2023-09-19 10:00:06506 
隨著各大公司爭相加入人工智能的潮流,芯片和人才供不應求。初創公司SambaNova(https://sambanova.ai/)聲稱,其新處理器可以幫助公司在幾天內建立并運行自己的大型語言模型
2023-09-27 16:10:51304 AI大模型將AI帶入新的發展階段。AI大模型需要更高效的海量原始數據收集和預處理,更高性能的訓練數據加載和模型數據保存,以及更加及時和精準的行業推理知識庫。以近存計算、向量存儲為代表的AI數據新范式正在蓬勃發展。
2023-10-23 11:26:09325 
Transformer 架構的問世標志著現代語言大模型時代的開啟。自 2018 年以來,各類語言大模型層出不窮。
2023-10-24 11:42:05337 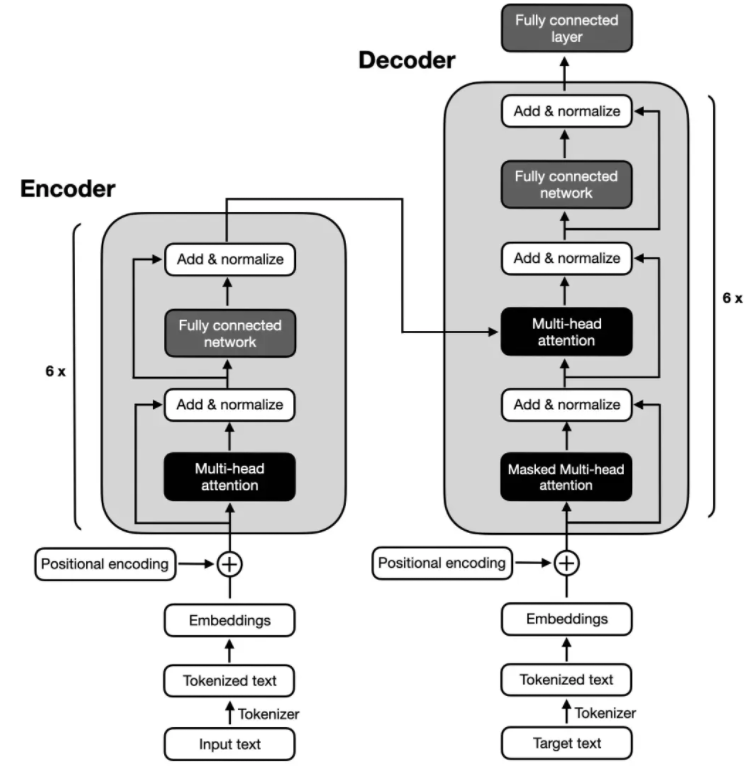
求解大型COMSOL模型需要多少內存? COMSOL是一種非常強大的跨學科有限元分析軟件,可以用于解決各種復雜的問題,包括流體力學、電磁學、熱傳遞、結構力學等。但是,在處理大型模型時,COMSOL
2023-10-29 11:35:24875 適應各種各樣的任務,而無需進一步的訓練。 這就引出了一個問題: 時間序列的基礎模型能像自然語言處理那樣存在嗎? 一個預先訓練了大量時間序列數據的大型模型,是否有可能在未見過的數據上產生準確的預測? 通過
2023-11-03 10:15:22279 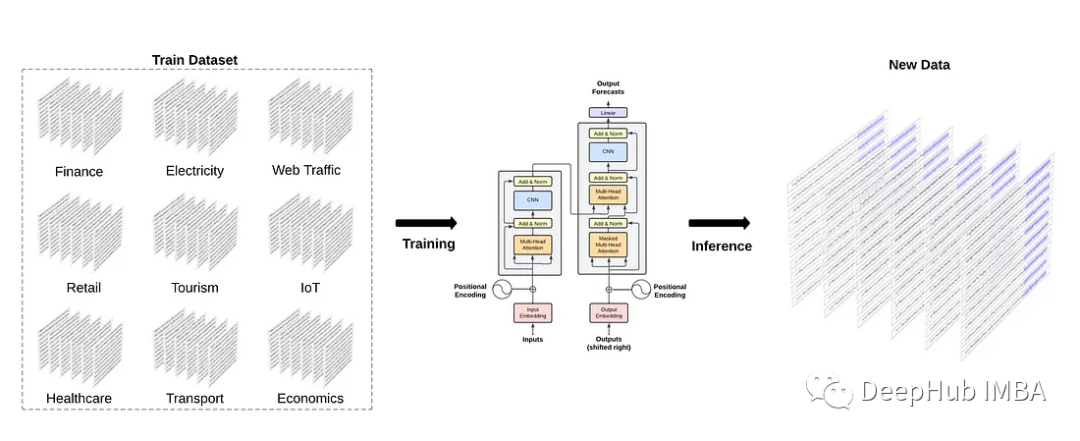
簡介章節講的是比較基礎的,主要介紹了本次要介紹的概念,即檢索(Retrieval)和大語言模型(LLM)
2023-11-15 14:50:36281 
本文基于亞馬遜云科技推出的大語言模型與生成式AI的全家桶:Bedrock對大語言模型進行介紹。大語言模型指的是具有數十億參數(B+)的預訓練語言模型(例如:GPT-3, Bloom, LLaMA)。這種模型可以用于各種自然語言處理任務,如文本生成、機器翻譯和自然語言理解等。
2023-12-04 15:51:46355 隨著人工智能技術的快速發展,大型預訓練模型如GPT-4、BERT等在自然語言處理領域取得了顯著的成功。這些大模型背后的關鍵之一是龐大的數據集,為模型提供了豐富的知識和信息。本文將探討大模型數據集的突破邊界以及未來發展趨勢。
2023-12-06 16:10:44247 大模型在多領域表現卓越,在自然語言理解、學習能力、視覺聽覺識別等領域可以媲美甚至超越人類。提高大模型的創造能力、減少對數據的依賴性、加強隱私保護等將會是大模型迭代的重點。
2023-12-07 10:48:04386 
大規模語言模型(Large Language Models,LLM),也稱大規模語言模型或大型語言模型,是一種由包含數百億以上參數的深度神經網絡構建的語言模型,使用自監督學習方法通過大量無標注
2023-12-07 11:40:431134 
的人工智能模型,旨在理解和生成自然語言文本。這類模型的核心是深度神經網絡,通過大規模的訓練數據和強大的計算能力,使得模型能夠學習到語言的語法、語境和語義等多層次的信息。 大語言模型的發展歷史可以追溯到深度學習的
2023-12-21 17:53:59553 ,帶你發現大語言模型的潛力,解鎖無限可能。 揭秘大語言模型的魔法 在動手操作之前,我們先來揭秘一下大語言模型的魔法。這些模型通過大量的文本數據進行預訓練,使其具備了超強的理解和生成自然語言的能力。搞懂它的構造和培訓過程
2023-12-29 14:18:59276 大型語言模型(LLM)是基于人工智能的先進模型,經過訓練,它可以密切反映人類自然交流的方式處理和生成人類語言。這些模型利用深度學習技術和大量訓練數據來全面理解語言結構、語法、上下文和語義。
2024-01-03 16:05:25438 
隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放,越來越多的開發者將大語言模型納入到他們的項目中。其中一個關鍵的適應步驟是將領域特定的文檔集成到預訓練模型中,這被稱為微調。
2024-01-04 12:32:39228 
韓國互聯網巨頭Kakao最近宣布開發了一種名為“蜜蜂”(Honeybee)的多模態大型語言模型。這種創新模型能夠同時理解和處理圖像和文本數據,為更豐富的交互和查詢響應提供了可能性。
2024-01-19 16:11:20221 大型語言模型(LLM)正在迅速發展,變得更加強大和高效,使人們能夠在廣泛的應用程序中越來越復雜地理解和生成類人文本。
2024-03-17 17:17:08503 
 電子發燒友App
電子發燒友App










 工商網監
工商網監
評論