 電子發(fā)燒友App
電子發(fā)燒友App


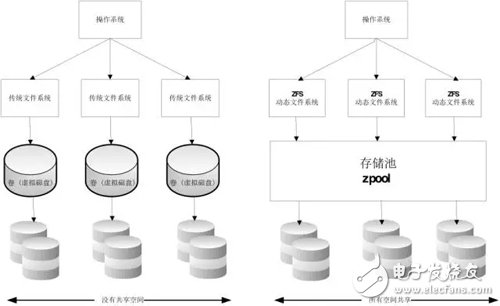
Docker最開始采用AUFS作為文件系統(tǒng),也得益于AUFS分層的概念,實現(xiàn)了多個Container可以共享同一個image。但由于AUFS未并入Linux內(nèi)核,且只支持Ubuntu,考慮到兼容性問題,在Docker 0.7版本中引入了存儲驅(qū)動, 目前,Docker支持AUFS、Btrfs、Device mapper、OverlayFS、ZFS五種存儲驅(qū)動。就如Docker官網(wǎng)上說的,沒有單一的驅(qū)動適合所有的應(yīng)用場景,要根據(jù)不同的場景選擇合適的存儲驅(qū)動,才能有效的提高Docker的性能。如何選擇適合的存儲驅(qū)動,要先了解存儲驅(qū)動原理才能更好的判斷,本文介紹一下Docker五種存儲驅(qū)動原理詳解及應(yīng)用場景及IO性能測試的對比。在講原理前,先講一下寫時復(fù)制和寫時分配兩個技術(shù)。
一、原理說明
寫時復(fù)制(CoW)
所有驅(qū)動都用到的技術(shù)——寫時復(fù)制(CoW)。CoW就是copy-on-write,表示只在需要寫時才去復(fù)制,這個是針對已有文件的修改場景。比如基于一個image啟動多個Container,如果為每個Container都去分配一個image一樣的文件系統(tǒng),那么將會占用大量的磁盤空間。而CoW技術(shù)可以讓所有的容器共享image的文件系統(tǒng),所有數(shù)據(jù)都從image中讀取,只有當要對文件進行寫操作時,才從image里把要寫的文件復(fù)制到自己的文件系統(tǒng)進行修改。所以無論有多少個容器共享同一個image,所做的寫操作都是對從image中復(fù)制到自己的文件系統(tǒng)中的復(fù)本上進行,并不會修改image的源文件,且多個容器操作同一個文件,會在每個容器的文件系統(tǒng)里生成一個復(fù)本,每個容器修改的都是自己的復(fù)本,相互隔離,相互不影響。使用CoW可以有效的提高磁盤的利用率。
用時分配(allocate-on-demand)
而寫時分配是用在原本沒有這個文件的場景,只有在要新寫入一個文件時才分配空間,這樣可以提高存儲資源的利用率。比如啟動一個容器,并不會為這個容器預(yù)分配一些磁盤空間,而是當有新文件寫入時,才按需分配新空間。
AUFS
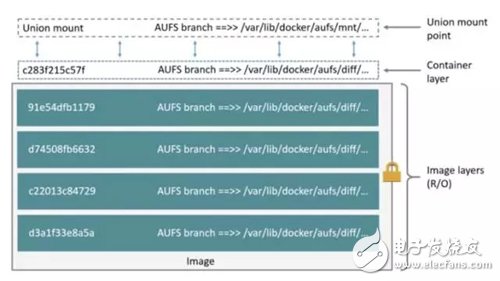
AUFS(AnotherUnionFS)是一種Union FS,是文件級的存儲驅(qū)動。AUFS能透明覆蓋一或多個現(xiàn)有文件系統(tǒng)的層狀文件系統(tǒng),把多層合并成文件系統(tǒng)的單層表示。簡單來說就是支持將不同目錄掛載到同一個虛擬文件系統(tǒng)下的文件系統(tǒng)。這種文件系統(tǒng)可以一層一層地疊加修改文件。無論底下有多少層都是只讀的,只有最上層的文件系統(tǒng)是可寫的。當需要修改一個文件時,AUFS創(chuàng)建該文件的一個副本,使用CoW將文件從只讀層復(fù)制到可寫層進行修改,結(jié)果也保存在可寫層。在Docker中,底下的只讀層就是image,可寫層就是Container。結(jié)構(gòu)如下圖所示:
Overlay
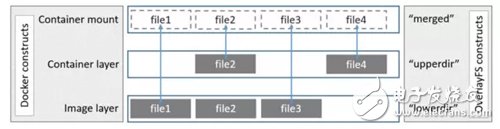
Overlay是Linux內(nèi)核3.18后支持的,也是一種Union FS,和AUFS的多層不同的是Overlay只有兩層:一個upper文件系統(tǒng)和一個lower文件系統(tǒng),分別代表Docker的鏡像層和容器層。當需要修改一個文件時,使用CoW將文件從只讀的lower復(fù)制到可寫的upper進行修改,結(jié)果也保存在lower層。在Docker中,底下的只讀層就是image,可寫層就是Container。結(jié)構(gòu)如下圖所示:
Device mapper
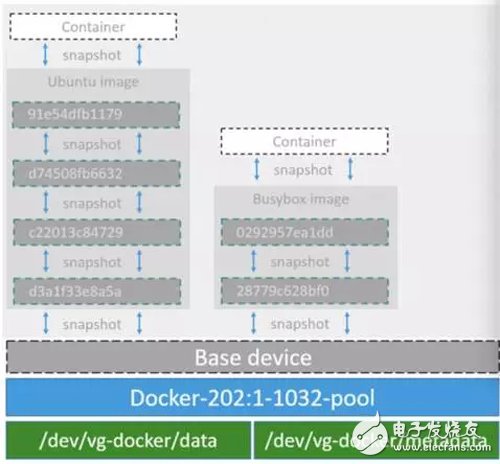
Device mapper是Linux內(nèi)核2.6.9后支持的,提供的一種從邏輯設(shè)備到物理設(shè)備的映射框架機制,在該機制下,用戶可以很方便的根據(jù)自己的需要制定實現(xiàn)存儲資源的管理策略。前面講的AUFS和OverlayFS都是文件級存儲,而Device mapper是塊級存儲,所有的操作都是直接對塊進行操作,而不是文件。Device mapper驅(qū)動會先在塊設(shè)備上創(chuàng)建一個資源池,然后在資源池上創(chuàng)建一個帶有文件系統(tǒng)的基本設(shè)備,所有鏡像都是這個基本設(shè)備的快照,而容器則是鏡像的快照。所以在容器里看到文件系統(tǒng)是資源池上基本設(shè)備的文件系統(tǒng)的快照,并不有為容器分配空間。當要寫入一個新文件時,在容器的鏡像內(nèi)為其分配新的塊并寫入數(shù)據(jù),這個叫用時分配。當要修改已有文件時,再使用CoW為容器快照分配塊空間,將要修改的數(shù)據(jù)復(fù)制到在容器快照中新的塊里再進行修改。Device mapper 驅(qū)動默認會創(chuàng)建一個100G的文件包含鏡像和容器。每一個容器被限制在10G大小的卷內(nèi),可以自己配置調(diào)整。結(jié)構(gòu)如下圖所示:
Btrfs
Btrfs被稱為下一代寫時復(fù)制文件系統(tǒng),并入Linux內(nèi)核,也是文件級級存儲,但可以像Device mapper一直接操作底層設(shè)備。Btrfs把文件系統(tǒng)的一部分配置為一個完整的子文件系統(tǒng),稱之為subvolume 。那么采用 subvolume,一個大的文件系統(tǒng)可以被劃分為多個子文件系統(tǒng),這些子文件系統(tǒng)共享底層的設(shè)備空間,在需要磁盤空間時便從底層設(shè)備中分配,類似應(yīng)用程序調(diào)用 malloc()分配內(nèi)存一樣。為了靈活利用設(shè)備空間,Btrfs 將磁盤空間劃分為多個chunk 。每個chunk可以使用不同的磁盤空間分配策略。比如某些chunk只存放metadata,某些chunk只存放數(shù)據(jù)。這種模型有很多優(yōu)點,比如Btrfs支持動態(tài)添加設(shè)備。用戶在系統(tǒng)中增加新的磁盤之后,可以使用Btrfs的命令將該設(shè)備添加到文件系統(tǒng)中。Btrfs把一個大的文件系統(tǒng)當成一個資源池,配置成多個完整的子文件系統(tǒng),還可以往資源池里加新的子文件系統(tǒng),而基礎(chǔ)鏡像則是子文件系統(tǒng)的快照,每個子鏡像和容器都有自己的快照,這些快照則都是subvolume的快照。
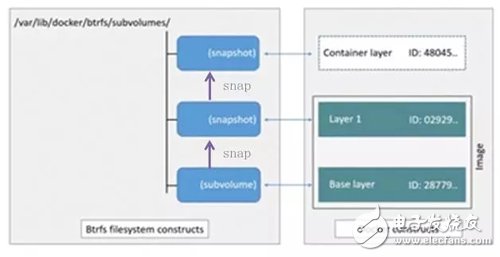
當寫入一個新文件時,為在容器的快照里為其分配一個新的數(shù)據(jù)塊,文件寫在這個空間里,這個叫用時分配。而當要修改已有文件時,使用CoW復(fù)制分配一個新的原始數(shù)據(jù)和快照,在這個新分配的空間變更數(shù)據(jù),變結(jié)束再更新相關(guān)的數(shù)據(jù)結(jié)構(gòu)指向新子文件系統(tǒng)和快照,原來的原始數(shù)據(jù)和快照沒有指針指向,被覆蓋。
ZFS
ZFS 文件系統(tǒng)是一個革命性的全新的文件系統(tǒng),它從根本上改變了文件系統(tǒng)的管理方式,ZFS 完全拋棄了“卷管理”,不再創(chuàng)建虛擬的卷,而是把所有設(shè)備集中到一個存儲池中來進行管理,用“存儲池”的概念來管理物理存儲空間。過去,文件系統(tǒng)都是構(gòu)建在物理設(shè)備之上的。為了管理這些物理設(shè)備,并為數(shù)據(jù)提供冗余,“卷管理”的概念提供了一個單設(shè)備的映像。而ZFS創(chuàng)建在虛擬的,被稱為“zpools”的存儲池之上。每個存儲池由若干虛擬設(shè)備(virtual devices,vdevs)組成。這些虛擬設(shè)備可以是原始磁盤,也可能是一個RAID1鏡像設(shè)備,或是非標準RAID等級的多磁盤組。于是zpool上的文件系統(tǒng)可以使用這些虛擬設(shè)備的總存儲容量。
下面看一下在Docker里ZFS的使用。首先從zpool里分配一個ZFS文件系統(tǒng)給鏡像的基礎(chǔ)層,而其他鏡像層則是這個ZFS文件系統(tǒng)快照的克隆,快照是只讀的,而克隆是可寫的,當容器啟動時則在鏡像的最頂層生成一個可寫層。如下圖所示:
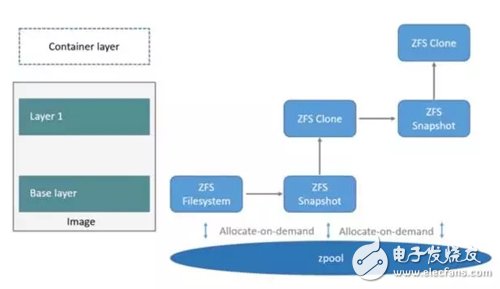
當要寫一個新文件時,使用按需分配,一個新的數(shù)據(jù)快從zpool里生成,新的數(shù)據(jù)寫入這個塊,而這個新空間存于容器(ZFS的克隆)里。
當要修改一個已存在的文件時,使用寫時復(fù)制,分配一個新空間并把原始數(shù)據(jù)復(fù)制到新空間完成修改。
二、存儲驅(qū)動的對比及適應(yīng)場景
AUFS VS Overlay
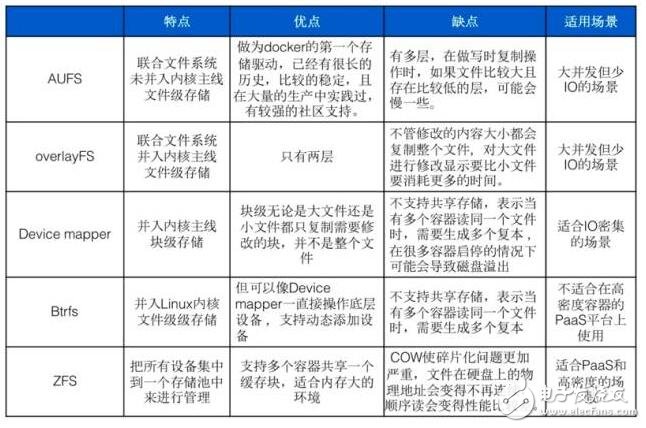
AUFS和Overlay都是聯(lián)合文件系統(tǒng),但AUFS有多層,而Overlay只有兩層,所以在做寫時復(fù)制操作時,如果文件比較大且存在比較低的層,則AUSF可能會慢一些。而且Overlay并入了linux kernel mainline,AUFS沒有,所以可能會比AUFS快。但Overlay還太年輕,要謹慎在生產(chǎn)使用。而AUFS做為docker的第一個存儲驅(qū)動,已經(jīng)有很長的歷史,比較的穩(wěn)定,且在大量的生產(chǎn)中實踐過,有較強的社區(qū)支持。目前開源的DC/OS指定使用Overlay。
Overlay VS Device mapper
Overlay是文件級存儲,Device mapper是塊級存儲,當文件特別大而修改的內(nèi)容很小,Overlay不管修改的內(nèi)容大小都會復(fù)制整個文件,對大文件進行修改顯示要比小文件要消耗更多的時間,而塊級無論是大文件還是小文件都只復(fù)制需要修改的塊,并不是整個文件,在這種場景下,顯然device mapper要快一些。因為塊級的是直接訪問邏輯盤,適合IO密集的場景。而對于程序內(nèi)部復(fù)雜,大并發(fā)但少IO的場景,Overlay的性能相對要強一些。
Device mapper VS Btrfs Driver VS ZFS
Device mapper和Btrfs都是直接對塊操作,都不支持共享存儲,表示當有多個容器讀同一個文件時,需要生活多個復(fù)本,所以這種存儲驅(qū)動不適合在高密度容器的PaaS平臺上使用。而且在很多容器啟停的情況下可能會導(dǎo)致磁盤溢出,造成主機不能工作。Device mapper不建議在生產(chǎn)使用。Btrfs在docker build可以很高效。
ZFS最初是為擁有大量內(nèi)存的Salaris服務(wù)器設(shè)計的,所在在使用時對內(nèi)存會有影響,適合內(nèi)存大的環(huán)境。ZFS的COW使碎片化問題更加嚴重,對于順序?qū)懮傻拇笪募绻院箅S機的對其中的一部分進行了更改,那么這個文件在硬盤上的物理地址就變得不再連續(xù),未來的順序讀會變得性能比較差。ZFS支持多個容器共享一個緩存塊,適合PaaS和高密度的用戶場景。
三、IO性能對比
測試工具:IOzone(是一個文件系統(tǒng)的benchmark工具,可以測試不同的操作系統(tǒng)中文件系統(tǒng)的讀寫性能)。
測試場景:從4K到1G文件的順序和隨機IO性能。
測試方法:基于不同的存儲驅(qū)動啟動容器,在容器內(nèi)安裝IOzone,執(zhí)行命令:。
。/iozone -a -n 4k -g 1g -i 0 -i 1 -i 2 -f /root/test.rar -Rb 。/iozone.xls
測試項的定義和解釋
Write:測試向一個新文件寫入的性能。
Re-write:測試向一個已存在的文件寫入的性能。
Read:測試讀一個已存在的文件的性能。
Re-Read:測試讀一個最近讀過的文件的性能。
Random Read:測試讀一個文件中的隨機偏移量的性能。
Random Write:測試寫一個文件中的隨機偏移量的性能。
測試數(shù)據(jù)對比
Write:
Re-write:
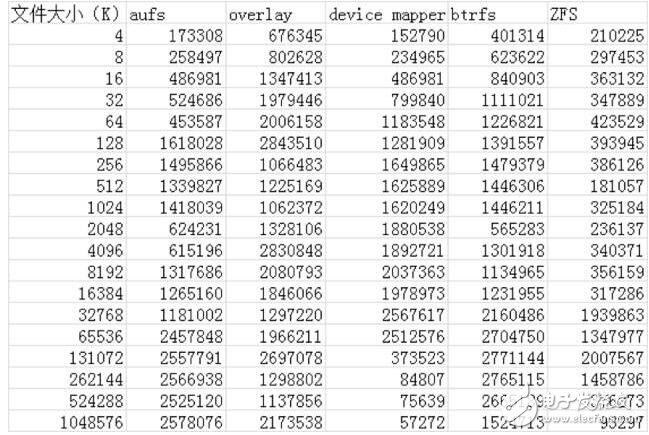
Read:
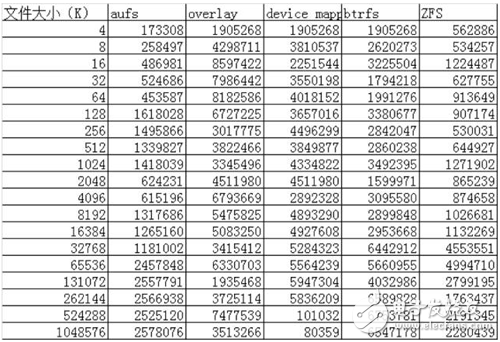
Re-Read:
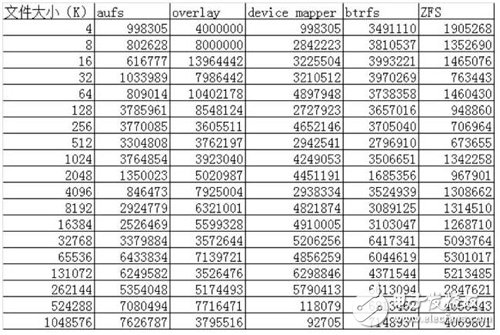
Random Read:
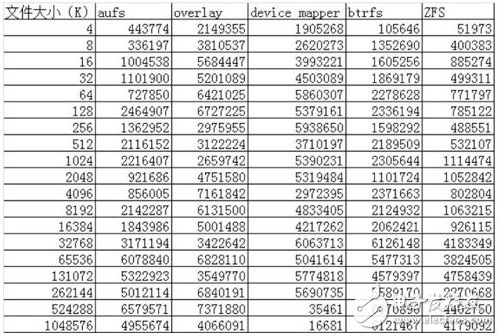
Random Write:
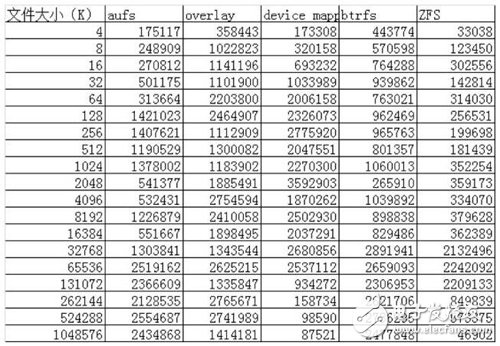
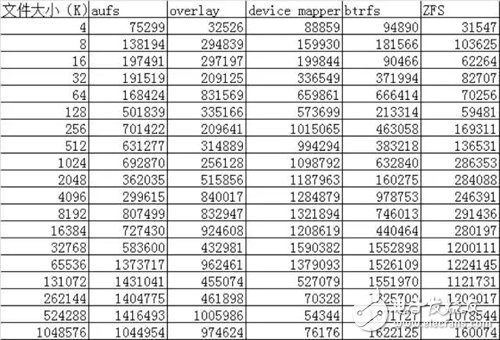
通過以上的性能數(shù)據(jù)可以看到:
AUFS在讀的方面性能相比Overlay要差一些,但在寫的方面性能比Overlay要好。
device mapper在512M以上文件的讀寫性能都非常的差,但在512M以下的文件讀寫性能都比較好。
btrfs在512M以上的文件讀寫性能都非常好,但在512M以下的文件讀寫性能相比其他的存儲驅(qū)動都比較差。
ZFS整體的讀寫性能相比其他的存儲驅(qū)動都要差一些。 簡單的測試了一些數(shù)據(jù),對測試出來的數(shù)據(jù)原理還需要進一步的解析。















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論