 單v100 GPU,4小時搜索到一個魯棒的網絡結構
單v100 GPU,4小時搜索到一個魯棒的網絡結構
NAS最近也很火,正好看到了這篇論文,解讀一下,這篇論文是基于DAG(directed acyclic graph)的,DAG包含了上億的 sub-graphs, 為了防止全部遍歷這些模型,這篇論文設計了一種全新的采樣器,這種采樣器叫做Gradient-based search suing differential Architecture Sampler(GDAS),該采樣器可以自行學習和優化,在這個的基礎上,在CIFAR-10上通過4 GPU hours就能找到一個最優的網絡結構。

目前主流的NAS一般是基于進化算法(EA)和強化學習(RL)來做的。EA通過權衡validation accuracy來決定是否需要移除一個模型,RL則是validation accuracy作為獎勵來優化模型生成。作者認為這兩種方法都很消耗計算資源。作者這篇論文中設計的GDAS方法可以在一個單v100 GPU上,用四小時搜索到一個優秀模型。
GDAS
這個采用了搜索robust neural cell來替代搜索整個網絡。如下圖,不同的操作(操作用箭頭表示)會計算出不同的中間結果(中間結果用cycle表示),前面的中間結果會加起來闖到后面。
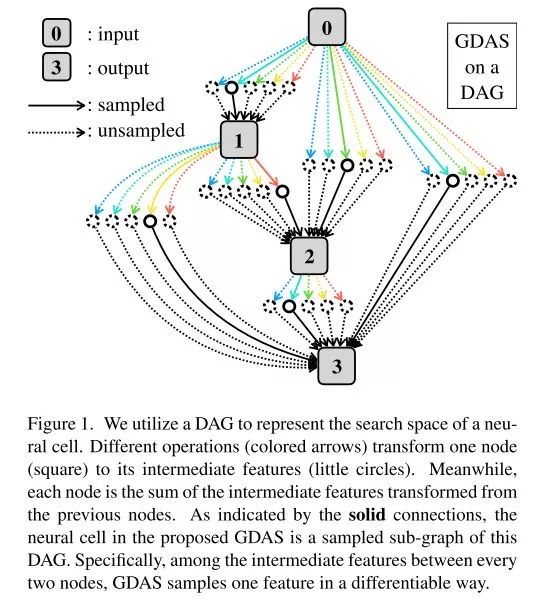
在優化速度上,傳統的DAG存在一些問題:基于RL和EA的方法,需要獲得反饋都需要很長一段時間。而這篇論文提出的GDAS方法能夠利用梯度下降去做優化,具體怎么梯的下面會說到。此外,使用GDAS的方法可以sample出sub-graph,這意味著計算量要比DAG的方法小很多。
絕大多數的NAS方法可以歸為兩類:Macro search和micro search
Macro search
顧名思義,實際上算法的目的是想要發現一個完整的網絡結構。因此多會采用強化學習的方式。現有的方法很多都是使用Q-learning的方法來學習的。那么會存在的問題是,需要搜索的網絡數量會呈指數級增長。最后導致的結果就是網絡會更淺。
Micro Search
這種不是搜索整個神經網絡,而是搜索neural cells的方式。找到指定的neural cells后,再去堆疊。這種設計方式雖然能夠設計更深的網絡,但是依舊要消耗很長時間,比如100GPU days,超長。這篇文章就是在消耗上面做優化。
算法原理
DAG的搜索空間
前面也說了DAG是通過搜索所謂的neural cell而不是搜索整個網絡。每個cell由多個節點和節點間的激活函數構成。節點我們用來表示,節點的計算如下圖。每個節點有其余兩個節點(下面公式中的節點i和節點j)來生成,而中間會從一個函數集合中去sample函數出來, 這個F數據集的組成是1)恒等映射 2)歸零 3)3x3 depthwise分離卷積 4)3x3 dilated depthwise 分離卷積 5)5x5 depthwise分離卷積 6)5x5 dilated depthwise 分離卷積。7)3x3平均池化 8) 3 x 3 最大池化。
那么生成節點I后,再去生成對應的cell。我們將cell的節點數記為B,以B=4為例,該cell實際上會包括7個節點,是前面兩層的cell的輸出(實際上也就是上面公式中的k和j),而則是我們(1)中計算出來的結果。也就是該cell的output tensor實際上是四個節點的output的聯結。
將cell組裝為網絡
剛剛上面的這種叫做normal cell,作者還設計了一個reduction cell, 用于下采樣。這個reduction cell就是手動設計的了,沒有像normal cell那樣復雜。normal cell 的步長為1,reduction cell步長為2, 最后的網絡實際上就是由這些cell組裝起來的。如下圖:
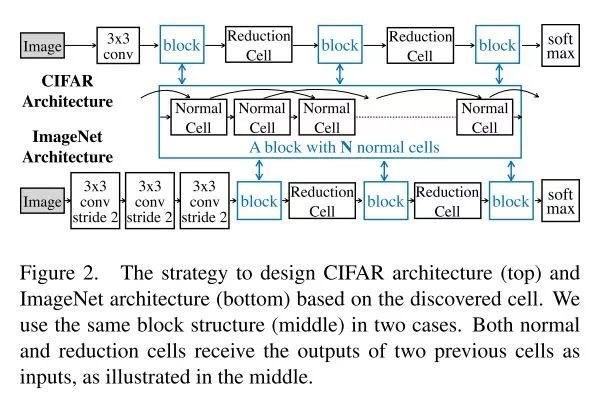
搜索模型參數
搭建的工作如上面所示,好像也還好,就像搭積木,這篇論文我覺得創新的地方在于它的搜索方法,特別是通過梯度下降的方式來更新參數,很棒。具體的搜索參數環節,它是這么做的:
首先我們的優化目標和手工設計的網絡別無二致,都是最大釋然估計:
而上式中的Pr,實際上可寫成:
這個實際上是node i和node j的函數分布,k則是F的基數。而Node可以表示為:
是從中sample出來的,而
這個實際上是node i和node j的函數分布,k則是F的基數。而Node可以表示為:
其中是從離散分布中間sample出來的函數。這里問題來了,如果直接去優化Pr,這里由于I是來自于一個離散分布,沒法對離散分布使用梯度下降方法。這里,作者使用了Gumbel-Max trick來解決離散分布中采樣不可微的問題,具體可以看這個問題下的回答
如何理解Gumbel-Max trick?
TL;DR: Gumbel Trick 是一種從離散分布取樣的方法,它的形式可以允許我們定義一種可微分的,離散分布的近似取樣,這種取樣方式不像「干脆以各類概率值的概率向量替代取樣」這么粗糙,也不像直接取樣一樣不可導(因此沒辦法應對可能的 bp )。
于是這里將這個離散分布不可微的問題做了轉移,同時對應的優化目標變為:
這里有個的參數,可以控制的相似程度。注意在前向傳播中我們使用的是等式(5), 而在反向傳播中,使用的是等式(7)。結合以上內容,我們模型的loss是:
我們將最后學習到的網絡結構稱為A,每一個節點由前面T個節點連接而來,在CNN中,我們把T設為2, 在RNN中,T設為1
在參數上,作者使用了SGD,學習率從0.025逐漸降到1e-3,使用的是cosine schedule。具體的參數和function F 設計上,可以去看看原論文。
總的來說,我覺得這篇論文最大的創新點是使用Gumbel-Max trick來使得搜索過程可微分,當然它中間也使用了一些手動設計的模塊(如reduction cell),所以速度會比其余的NAS更快,之前我也沒有接觸過NAS, 看完這篇論文后對現在的NAS常用的方法以及未來NAS發展的趨勢還是有了更深的理解,推薦看看原文。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
gpu
+關注
關注
28文章
4703瀏覽量
128728 -
強化學習
+關注
關注
4文章
266瀏覽量
11220
原文標題:單v100 GPU,4小時搜索到一個魯棒的網絡結構
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
DVB-H網絡結構
特斯拉V100 Nvlink是否支持v100卡的nvlink變種的GPU直通?
神經網絡結構搜索有什么優勢?
備貨Hi3519A V100 4K智能IP攝像頭SoC使用手冊分享
環形網絡,環形網絡結構是什么?
魯棒性是什么意思_Robust為什么翻譯成魯棒性


基于YOLO-V5的網絡結構及實現行人社交距離風險提示
物聯網行業通用主板—卓越V100






 工商網監
工商網監
評論