 簡要概述三維重建3Dreconstruction技術
簡要概述三維重建3Dreconstruction技術
三維重建的英文術語名稱是3D Reconstruction.
三維重建是指對三維物體建立適合計算機表示和處理的數學模型,是在計算機環境下對其進行處理、操作和分析其性質的基礎,也是在計算機中建立表達客觀世界的虛擬現實的關鍵技術。
三維重建的步驟
(1) 圖像獲取:在進行圖像處理之前,先要用攝像機獲取三維物體的二維圖像。光照條件、相機的幾何特性等對后續的圖像處理造成很大的影響。
(2)攝像機標定:通過攝像機標定來建立有效的成像模型,求解出攝像機的內外參數,這樣就可以結合圖像的匹配結果得到空間中的三維點坐標,從而達到進行三維重建的目的。
(3)特征提取:特征主要包括特征點、特征線和區域。大多數情況下都是以特征點為匹配基元,特征點以何種形式提取與用何種匹配策略緊密聯系。因此在進行特征點的提取時需要先確定用哪種匹配方法。
特征點提取算法可以總結為:基于方向導數的方法,基于圖像亮度對比關系的方法,基于數學形態學的方法三種。
(4)立體匹配:立體匹配是指根據所提取的特征來建立圖像對之間的一種對應關系,也就是將同一物理空間點在兩幅不同圖像中的成像點進行一一對應起來。在進行匹配時要注意場景中一些因素的干擾,比如光照條件、噪聲干擾、景物幾何形狀畸變、表面物理特性以及攝像機機特性等諸多變化因素。
(5)三維重建:有了比較精確的匹配結果,結合攝像機標定的內外參數,就可以恢復出三維場景信息。由于三維重建精度受匹配精度,攝像機的內外參數誤差等因素的影響,因此首先需要做好前面幾個步驟的工作,使得各個環節的精度高,誤差小,這樣才能設計出一個比較精確的立體視覺系統。
基于視覺的三維重建,指的是通過攝像機獲取場景物體的數據圖像,并對此圖像進行分析處理,再結合計算機視覺知識推導出現實環境中物體的三維信息。
1. 相關概念
(1)彩色圖像與深度圖像
彩色圖像也叫作RGB圖像,R、G、B三個分量對應于紅、綠、藍三個通道的顏色,它們的疊加組成了圖像像素的不同灰度級。RGB顏色空間是構成多彩現實世界的基礎。深度圖像又被稱為距離圖像,與灰度圖像中像素點存儲亮度值不同,其像素點存儲的是該點到相機的距離,即深度值。圖2-1表示深度圖像與灰度圖像之間的關系。
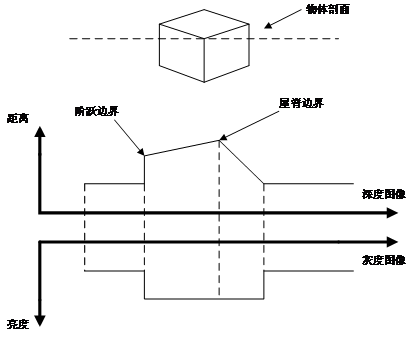
圖2-1 深度圖像與灰度圖像
Fig.2-1 The depth image and gray image
深度值指的目標物體與測量器材之間的距離。由于深度值的大小只與距離有關,而與環境、光線、方向等因素無關,所以深度圖像能夠真實準確的體現景物的幾何深度信息。通過建立物體的空間模型,能夠為深層次的計算機視覺應用提供更堅實的基礎。
圖2-2 人物的彩色圖像與深度圖像
Fig.2-2 Color image and depth image of the characters
(2)PCL
PCL(Point Cloud Library,點云庫)是由斯坦福大學的Dr.Radu等學者基于ROS(Robot Operating System,機器人操作系統)下開發與維護的開源項目,最初被用來輔助機器人傳感、認知和驅動等領域的開發。2011年PCL正式向公眾開放。隨著對三維點云算法的加入與擴充,PCL逐步發展為免費、開源、大規模、跨平臺的C++編程庫。
PCL框架包括很多先進的算法和典型的數據結構,如濾波、分割、配準、識別、追蹤、可視化、模型擬合、表面重建等諸多功能。能夠在各種操作系統和大部分嵌入式系統上運行,具有較強的軟件可移植性。鑒于PCL的應用范圍非常廣,專家學者們對點云庫的更新維護也非常及時。PCL的發展時至今日,已經來到了1.7.0版本。相較于早期的版本,加入了更多新鮮、實用、有趣的功能,為點云數據的利用提供了模塊化、標準化的解決方案。再通過諸如圖形處理器、共享存儲并行編程、統一計算設備架構等領先的高性能技術,提升PCL相關進程的速率,實現實時性的應用開發。
在算法方面,PCL是一套包括數據濾波、點云配準、表面生成、圖像分割和定位搜索等一系列處理點云數據的算法。基于不同類型區分每一套算法,以此把整合所有三維重建流水線功能,保證每套算法的緊湊性、可重用性與可執行性。例如PCL中實現管道運算的接口流程:
①創建處理對象,例如濾波、特征估計、圖像分割等;
②通過setInputCloud輸入初始點云數據,進入處理模塊;
③設置算法相關參數;
④調用不同功能的函數實現運算,并輸出結果。
為了實現模塊化的應用與開發,PCL被細分成多組獨立的代碼集合。因此便可方便快捷的應用于嵌入式系統中,實現可移植的單獨編譯。如下列舉了部分常用的算法模塊:
libpcl I/O:完成數據的輸入、輸出過程,如點云數據的讀寫;
libpcl filters:完成數據采樣、特征提取、參數擬合等過程;
libpcl register:完成深度圖像的配準過程,例如迭代最近點算法;
libpcl surface:完成三維模型的表面生成過程,包括三角網格化、表面平滑等。
此類常用的算法模塊均具有回歸測試功能,以確保使用過程中沒有引進錯誤。測試一般由專門的機構負責編寫用例庫。檢測到回歸錯誤時,會立即將消息反饋給相應的作者。因此能提升PCL和整個系統的安全穩定性。
(3)點云數據
如圖2-3所示,展示了典型的點云數據(Point Cloud Data,PCD)模型。
圖2-3 點云數據及其放大效果
點云數據通常出現在逆向工程中,是由測距設備獲取的物體表面的信息集合。其掃描資料以點的形式進行記錄,這些點既可以是三維坐標,也可以是顏色或者光照強度等信息。通常所使用的點云數據一般包括點坐標精度、空間分辨率和表面法向量等內容。點云一般以PCD格式進行保存,這種格式的點云數據可操作性較強,同時能夠提高點云配準融合的速度。本文研究的點云數據為非結構化的散亂點云,屬于三維重建特有的點云特點。
(4)坐標系
在三維空間中,所有的點必須以坐標的形式來表示,并且可以在不同的坐標系之間進行轉換。首先介紹基本坐標系的概念、計算及相互關系。
①圖像坐標系
圖像坐標系分為像素和物理兩個坐標系種類。數字圖像的信息以矩陣形式存儲,即一副像素的圖像數據存儲在維矩陣中。圖像像素坐標系以為原點、以像素為基本單位,U、V分別為水平、垂直方向軸。圖像物理坐標系以攝像機光軸與圖像平面的交點作為原點、以米或毫米為基本單位,其X、Y軸分別與U、V軸平行。圖2-4展示的是兩種坐標系之間的位置關系:
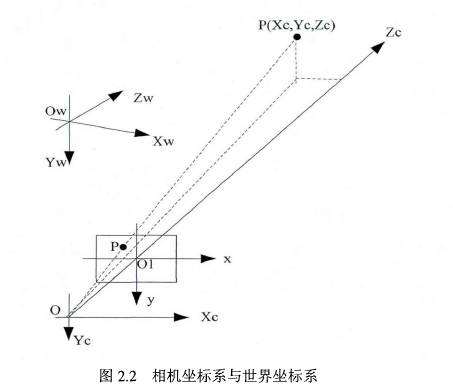
圖2-4 圖像像素坐標系與物理坐標系
Fig.2-4 Image pixel coordinate system and physical coordinate system
令U-V坐標系下的坐標點(u0,v0),與代表像素點在X軸與Y軸上的物理尺寸。那么圖像中的所有像素點在U-V坐標系與在X-Y坐標系下的坐標間有著如式(2-1)表示的關系:
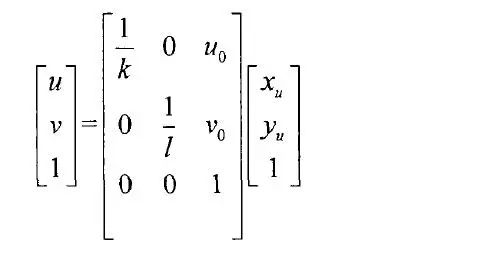
其中指的是圖像坐標系的坐標軸傾斜相交而形成的傾斜因子(Skew Factor)。
②攝像機坐標系
攝像機坐標系由攝像機的光心及三條、、軸所構成。它的、軸對應平行于圖像物理坐標系中的、軸,軸為攝像機的光軸,并與由原點、、軸所組成的平面垂直。如圖2-5所示:
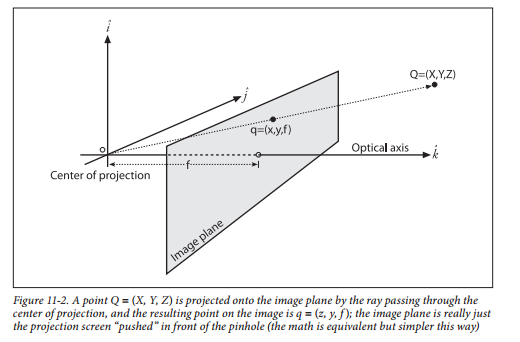
圖2-5攝像機坐標系
令攝像機的焦距是f,則圖像物理坐標系中的點與攝像機坐標系中的點的關系為:
③世界坐標系
考慮到攝像機位置具有不確定性,因此有必要采用世界坐標系來統一攝像機和物體的坐標關系。世界坐標系由原點及、、三條軸組成。世界坐標與攝像機坐標間有著(2-3)所表達的轉換關系:


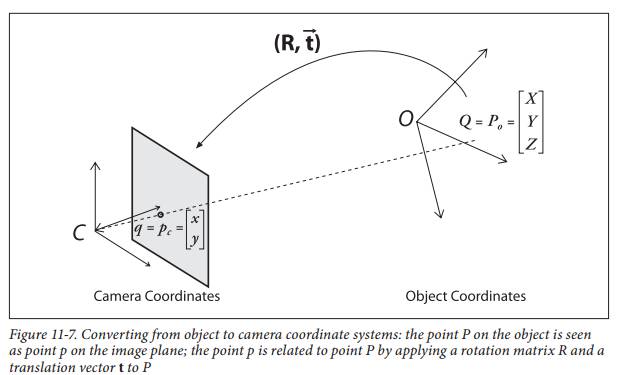
( 23 )
其中,是旋轉矩陣,代表攝像機在世界坐標系下的指向;是平移向量,代表了攝像機的位置。
2.三維重建流程
本文使用Kinect采集景物的點云數據,經過深度圖像增強、點云計算與配準、數據融合、表面生成等步驟,完成對景物的三維重建。
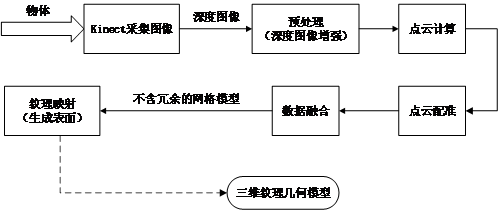
圖2-6 基于深度傳感器的三維重建流程圖
Fig.2-6 Flow chart of 3D reconstruction based on depth sensor
圖2-6顯示的流程表明,對獲取到的每一幀深度圖像均進行前六步操作,直到處理完若干幀。最后完成紋理映射。下面對每個步驟作詳細的說明。
2.1 深度圖像的獲取
景物的深度圖像由Kinect在Windows平臺下拍攝獲取,同時可以獲取其對應的彩色圖像。為了獲取足夠多的圖像,需要變換不同的角度來拍攝同一景物,以保證包含景物的全部信息。具體方案既可以是固定Kinect傳感器來拍攝旋轉平臺上的物體;也可以是旋轉Kinect傳感器來拍攝固定的物體。價格低廉、操作簡單的深度傳感器設備能夠獲取實時的景物深度圖像,極大的方便了人們的應用。
2.2 預處理
受到設備分辨率等限制,它的深度信息也存在著許多缺點。為了更好的促進后續基于深度圖像的應用,必須對深度圖像進行去噪和修復等圖像增強過程。作為本文的重點問題,具體的處理方法將在第四章進行詳細的解釋說明。
2.3 點云計算
經過預處理后的深度圖像具有二維信息,像素點的值是深度信息,表示物體表面到Kinect傳感器之間的直線距離,以毫米為單位。以攝像機成像原理為基礎,可以計算出世界坐標系與圖像像素坐標系之間具有下式的轉換關系:
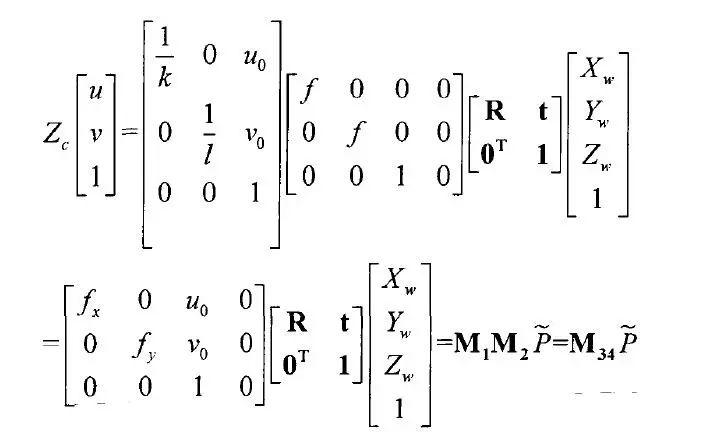

則k值只與有關,而等參數只與攝像機的內部構造有關,所以稱為像機的內參數矩陣。以攝像機作為世界坐標系,即,則深度值即為世界坐標系中的值,與之對應的圖像坐標就是圖像平面的點。
2.4 點云配準
對于多幀通過不同角度拍攝的景物圖像,各幀之間包含一定的公共部分。為了利用深度圖像進行三維重建,需要對圖像進行分析,求解各幀之間的變換參數。深度圖像的配準是以場景的公共部分為基準,把不同時間、角度、照度獲取的多幀圖像疊加匹配到統一的坐標系中。計算出相應的平移向量與旋轉矩陣,同時消除冗余信息。點云配準除了會制約三維重建的速度,也會影響到最終模型的精細程度和全局效果。因此必須提升點云配準算法的性能。
三維深度信息的配準按不同的圖像輸入條件與重建輸出需求被分為:粗糙配準、精細配準和全局配準等三類方法。
(1)粗糙配準(Coarse Registration)
粗糙配準研究的是多幀從不同角度采集的深度圖像。首先提取兩幀圖像之間的特征點,這種特征點可以是直線、拐點、曲線曲率等顯式特征,也可以是自定義的符號、旋轉圖形、軸心等類型的特征。
隨后根據特征方程實現初步的配準。粗糙配準后的點云和目標點云將處于同一尺度(像素采樣間隔)與參考坐標系內,通過自動記錄坐標,得到粗匹配初始值。
(2)精細配準(Fine Registration)
精細配準是一種更深層次的配準方法。經過前一步粗配準,得到了變換估計值。將此值作為初始值,在經過不斷收斂與迭代的精細配準后,達到更加精準的效果。以經典的由Besl和Mckay[49]提出的ICP(Iterative Closest Point,迭代最近點)算法為例,該算法首先計算初始點云上所有點與目標點云的距離,保證這些點和目標點云的最近點相互對應,同時構造殘差平方和的目標函數。
基于最小二乘法對誤差函數進行最小化處理,經過反復迭代,直到均方誤差小于設定的閾值。ICP算法能夠獲得精正確無誤的配準結果,對自由形態曲面配準問題具有重要意義。另外還有如SAA(Simulate Anneal Arithmetic,模擬退火)算法、GA(Genetic Algorithm,遺傳)算法等也有各自的特點與使用范疇。
(3)全局配準(Global Registration)
全局配準是使用整幅圖像直接計算轉換矩陣。通過對兩幀精細配準結果,按照一定的順序或一次性的進行多幀圖像的配準。這兩種配準方式分別稱為序列配準(Sequential Registration)和同步配準(Simultaneous Registration)。
配準過程中,匹配誤差被均勻的分散到各個視角的多幀圖像中,達到削減多次迭代引起的累積誤差的效果。值得注意的是,雖然全局配準可以減小誤差,但是其消耗了較大的內存存儲空間,大幅度提升了算法的時間復雜度。
2.5 數據融合
經過配準后的深度信息仍為空間中散亂無序的點云數據,僅能展現景物的部分信息。因此必須對點云數據進行融合處理,以獲得更加精細的重建模型。以Kinect傳感器的初始位置為原點構造體積網格,網格把點云空間分割成極多的細小立方體,這種立方體叫做體素(Voxel)。通過為所有體素賦予SDF(Signed Distance Field,有效距離場)值,來隱式的模擬表面。
SDF值等于此體素到重建表面的最小距離值。當SDF值大于零,表示該體素在表面前;當SDF小于零時,表示該體素在表面后;當SDF值越接近于零,表示該體素越貼近于場景的真實表面。KinectFusion技術雖然對場景的重建具有高效實時的性能,但是其可重建的空間范圍卻較小,主要體現在消耗了極大的空間用來存取數目繁多的體素。
為了解決體素占用大量空間的問題,Curless[50]等人提出了TSDF (Truncated Signed Distance Field,截斷符號距離場)算法,該方法只存儲距真實表面較近的數層體素,而非所有體素。因此能夠大幅降低KinectFusion的內存消耗,減少模型冗余點。

圖2-7 基于空間體的點云融合
TSDF算法采用柵格立方體代表三維空間,每個柵格中存放的是其到物體表面的距離。TSDF值的正負分別代表被遮擋面與可見面,而表面上的點則經過零點,如圖2-7中左側展示的是柵格立方體中的某個模型。若有另外的模型進入立方體,則按照下式(2-9)與(2-10)實現融合處理。
其中,指的是此時點云到柵格的距離,是柵格的初始距離,是用來對同一個柵格距離值進行融合的權重。如圖2-7中右側所示,兩個權重之和為新的權重。對于KinectFusion算法而言,當前點云的權重值設置為1。
鑒于TSDF算法采用了最小二乘法進行了優化,點云融合時又利用了權重值,所有該算法對點云數據有著明顯的降噪功能。
2.6 表面生成
表面生成的目的是為了構造物體的可視等值面,常用體素級方法直接處理原始灰度體數據。Lorensen[51]提出了經典體素級重建算法:MC(Marching Cube,移動立方體)法。移動立方體法首先將數據場中八個位置相鄰的數據分別存放在一個四面體體元的八個頂點處。對于一個邊界體素上一條棱邊的兩個端點而言,當其值一個大于給定的常數T,另一個小于T時,則這條棱邊上一定有等值面的一個頂點。
然后計算該體元中十二條棱和等值面的交點,并構造體元中的三角面片,所有的三角面片把體元分成了等值面內與等值面外兩塊區域。最后連接此數據場中的所有體元的三角面片,構成等值面。合并所有立方體的等值面便可生成完整的三維表面。
3 性能優化
Kinect等深度傳感器的出現,不僅給娛樂應用帶來了變革,同樣對科學研究提供了新的方向。尤其是在三維重建領域。然而由于三維重建過程涉及到大量密集的點云數據處理,計算量巨大,所以對系統進行相應的性能優化顯得非常的重要。本文采用基于GPU(Graphic Processing Unit,圖形處理器)并行運算功能,以提高整體的運行效率。
NVIDIA公司于1999年提出了GPU概念。在這十幾年間,依靠硬件行業的改革創新,芯片上晶體管數量持續增多,GPU性能以半年翻一番的速度成倍提升。GPU的浮點運算能力遠超CPU上百倍,卻具有非常低的能耗,極具性價比。因GPU不僅廣泛應用于圖形圖像處理中,也在如視頻處理、石油勘探、生物化學、衛星遙感數據分析、氣象預報、數據挖掘等方面嶄露頭角。
作為GPU的提出者,NVIDIA公司一直致力于GPU性能提升的研究工作,并在2007年推出了CUDA架構。CUDA(Compute Unified Device Architecture,統一計算設備架構)是一種并行計算程序架構。在CUDA的支持下,使用者可以編寫程序以利用NVIDIA系列GPU完成大規模并行計算。GPU在CUDA中被用作通用計算設備,而不只是處理圖像。在CUDA中,將計算機CPU稱為主機(Host),GPU稱為設備(Device)。
主機端和設備端都有程序運行,主機端主要完成程序的流程與串行計算模塊,而設備端則專門處理并行計算。其中,設備端的并行計算過程被記錄在Kernel內核函數中,主機端可以從Kernel函數入口執行并行計算的調用功能。在此過程中,雖然Kernel函數執行同一代碼,但卻處理著不同的數據內容。
Kernel函數采用擴展的C語言來編程,稱為CUDAC語言。需要注意的是,并不是所有的運算都可以采用CUDA并行計算。只有獨立性的計算,如矩陣的加減,因為只涉及到對應下標的元素的加減,不同下標元素毫無關聯,所以適用于并行計算;而對于如階乘的計算則必須對所有數累積相乘,故無法采用并行計算。
CUDA具有線程(Thread)、程序塊(Block)、網格(Grid)三級架構,計算過程一般由單一的網格完成,網格被平均分成多個程序塊,每個程序塊又由多個線程組成,最終由單個線程完成每個基本運算,如圖2-8所示。
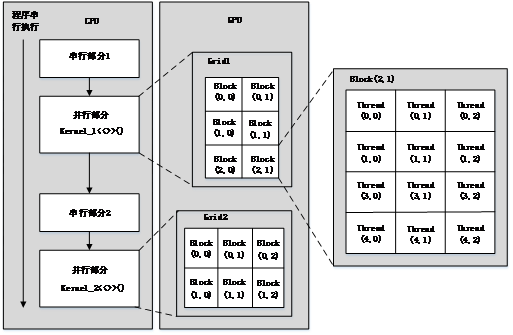
圖2-8 CUDA模型
為了更深入的理解CUDA模型的計算過程,這里以前一章中提到的公式(2-11)為例,計算某點的深度值與三維坐標之間的轉換:
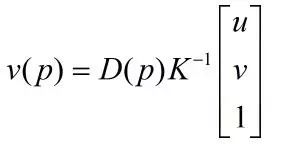
上式中的表示深度值,內參數矩陣是已知量,是該點的坐標。可以發現這個點的轉換過程與其他點轉換過程是相互獨立的,所以整幅圖像中各點的坐標轉換能夠并行執行。這種并行計算可以大幅提升整體計算的速率。例如,利用一個網格來計算一幅像素的深度圖像到三維坐標的轉換,只需要將此網格均分成塊,每塊包括個線程,每個線程分別操作一個像素點,便可以便捷的完成所有的坐標轉換運算。
通過GPU的并行計算,三維重建性能得到了大幅的提升,實現了實時的輸入輸出。對于Kinect在實際生產生活中的應用奠定了基礎。
-
3D
+關注
關注
9文章
2864瀏覽量
107342 -
三維重建
+關注
關注
0文章
26瀏覽量
9904 -
彩色圖像
+關注
關注
0文章
15瀏覽量
7447
發布評論請先 登錄
相關推薦
怎樣去設計一種基于RGB-D相機的三維重建無序抓取系統?
如何去開發一款基于RGB-D相機與機械臂的三維重建無序抓取系統
無人機三維建模的信息
MC三維重建算法的二義性消除研究
基于FPGA的醫學圖像三維重建系統設計與實現
透明物體的三維重建研究綜述

嵌入式雙目視覺系統和三維重建技術研究

NVIDIA Omniverse平臺助力三維重建服務協同發展
深度學習背景下的圖像三維重建技術進展綜述
三維重建:從入門到入土
如何實現整個三維重建過程
基于光學成像的物體三維重建技術研究





 工商網監
工商網監
評論