 關于Zen 2核心性能分析和應用
關于Zen 2核心性能分析和應用
在過去的一個月里,AMD發布了許多公告。AMD正在準備推出他們的第三代Ryzen臺式機處理器。這些處理器將利用AMD最新的微架構Zen 2,采用臺積電領先的7nm工藝制造。
我們先來看看核心的微架構改進。
Zen 2
新芯片的核心是Zen 2。這一核心將用于AMD的移動APU、高性能臺式機處理器和數據中心芯片。
Zen 2是繼Zen之后的下一個主要微架構。隨著Zen 2的推出,AMD承諾分別基于Cinebench 1T和Spec2006進行13-15%的IPC改進。要了解他們如何能夠獲得IPC提升帶來的性能改進,我們需要仔細研究最基本的微架構的變化。
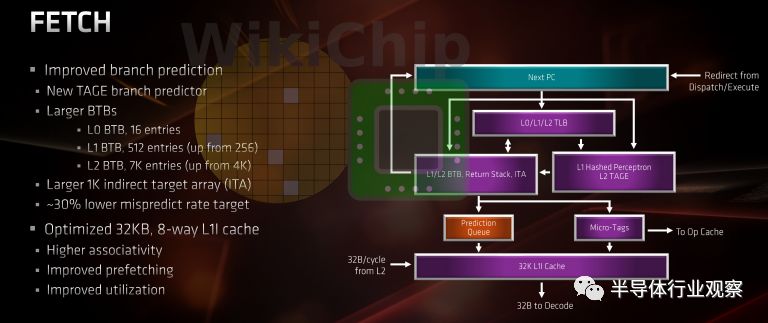
流水線前端
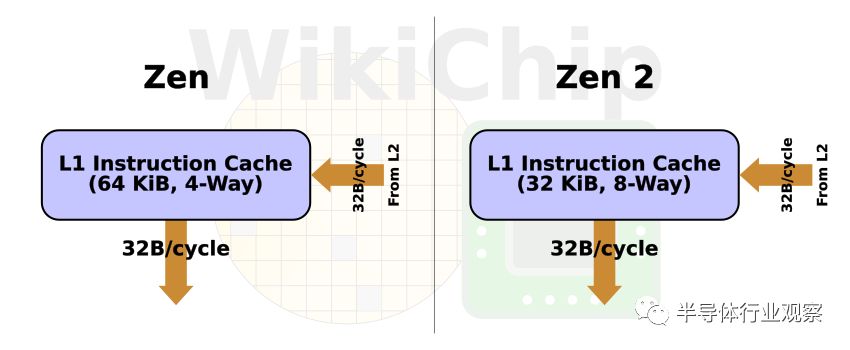
前端的很大一部分已經進行了重新設計。在沒有條件跳轉指令的典型情況下,從下一個64B塊的地址開始從第一級高速緩存提取指令。Zen最初提供了一個64 KB L1緩存。它由4路256組(4 ways of 256 sets)組成。Zen 2對L1進行了大改。組關聯結構已經變為8路64組(8 ways of 64 sets),緩存大小減小到32 KB。如果沒有AMD的更多細節,我們很難描述其他變化,更高的關聯性也應該降低未命中率。AMD指出,通過減小指令緩存的大小,并利用節省下來的cache部分來實現一些其他組件,特別是BPU和OC,它們能夠使得整體CPU從同等面積下的電路獲得更高性能。順便說一下,從處理器架構組成的角度來看,Zen 2現在和英特爾的Skylake和Sunny Cove是類似的。值得注意的是,一級指令高速緩存的TLB大小保持不變。它仍然是全相聯型,深度為64條表項的buffer區,能夠存儲4 KB、2 MB和1 GB頁面。
緩存行大小仍保持64字節,CPU每個周期可以獲取32個字節。在不太常見的緩存未命中的情況下,L1將為未命中所在的行產生填充的地址請求。每個周期最多32個字節可以從系統共享的L2傳輸到指令高速緩存。
與取指操作產生的填充緩存行請求的同時,分支預測器和預取指器也可以發出其他操作的請求。這一點對于整個系統很重要,因為預取器能夠利用指令的空間局部性以避免流水線停頓。這也是AMD在Zen2的另一努力改進之處。
也許是當下最好的預測器?
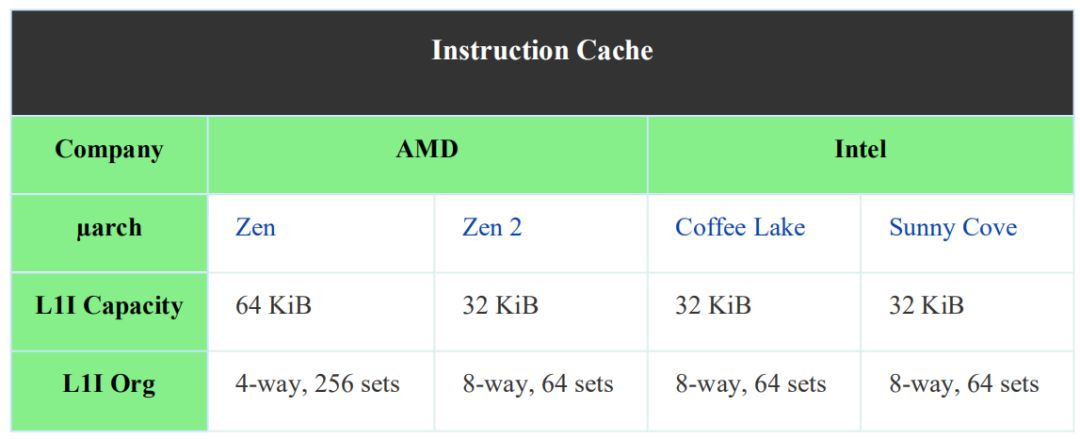
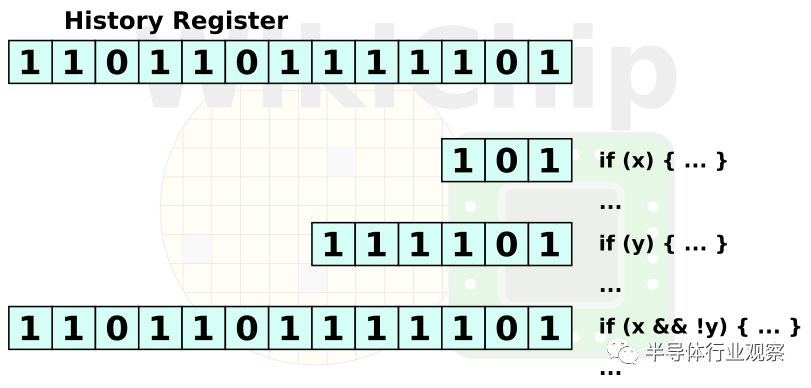
分支預測單元的作用是預測條件分支(跳轉)的目標地址。換句話說,判斷它是否跳轉。這里的基本思想是通過對指令流路徑的預判斷執行,而不是停滯流水線直到跳轉指令得到確切執行結果,所產生的長周期浪費。然而,這種預測必須得正確和巧妙地執行,錯誤的預測會導致更多的執行時間上浪費。當發生跳轉時,將其跳轉狀態存儲在BTB中,或不采用以便于對后續的分支指令進行跳或不跳的結果預測。諸如Zen之類的現代微處理器通過不僅將最后一個分支的歷史狀態而且是最后幾個分支的歷史狀態存儲在全局歷史寄存器GHR中,以便分析跳轉指令之間的相關性(例如,前一個分支指令發生跳轉,那么下一個分支指令也很有可能發生跳轉)。
Zen所采用的BTB是一個三級緩存結構——每級緩存都具有更高的容量,但代價是更長的延遲。與前幾代Zen結構相比,Zen 2的BTB保持結構不變,但幾乎將第二級和第三級BTB中的表項數量增加了一倍,分別從256和4K增加到512和7K。
另外,在Zen架構中,第一級L0 BTB中的查找是零延遲查找,而第一級產生的結果表在L1和L2 BTB中查找時會分別產生1個和4個時鐘周期的流水線空泡操作。目前還不清楚Zen 2是否改善了這一缺陷。
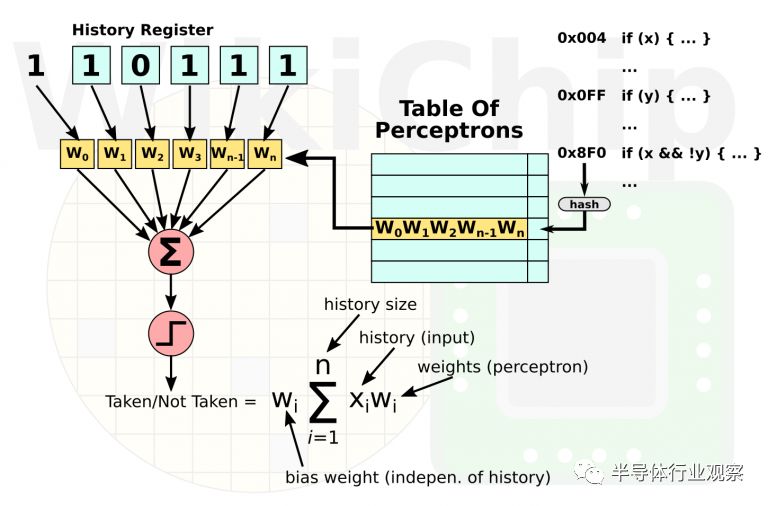
Zen采用了一種基于哈希結構的神經網絡動態預測器。借著人工智能的風頭,營銷人員喜歡將其稱為神經網絡結構的預測器。神經網絡是最簡單的機器學習形式,與其他一些機器學習算法相比,神經網絡本身更易于實現硬件。它們往往也比gshare之類的預測器更準確,但它們的實現確實更復雜。Zen上的具體實現尚不清楚,但我們至少可以描述一個簡單的實現是什么樣子的。當處理器遇到條件分支時,它的地址用于從在神經網絡中查找感知器節點。對于我們來說,感知器只不過是權重向量。這些權重表示歷史分支的結果與預測的分支之間的相關性。例如,考慮以下三種模式:“TTN”、“NTN”和“NNN”。如果這三個模式都導致下一個分支沒跳轉,那么或許我們可以說前兩個分支之間沒有相關性,并為它們分配很小的權重。先前分支的結果是從全局歷史寄存器中獲取的。寄存器中的各個位用作輸入。輸出值是計算出的權重和先前分支歷史的乘積。在這種情況下,負輸出可能意味著不跳轉,而其他值可能被預測為跳轉。值得一提的是,分支歷史之外的其他輸入也可以用于推理相關性,盡管不知道是否有現實世界的實現利用了這一想法。Zen的實現可能要復雜得多,或許是對不同類型的歷史狀態進行采樣。盡管如此,它的工作方式仍然是一樣的。
鑒于Zen流水線的長度和寬度,錯誤的預測可能導致需要沖刷掉超過100個周期的指令槽延遲。這直接導致性能的損失。Zen 2保留了哈希神經網絡預測器,但增加了第二層新的TAGE預測器。這個預測器是由Andre Seznec在2006年首次提出的,它是對Michaud的PPM類預測器的改進。TAGE預報器贏得了上一屆分支預測(CBP)大賽(2006-2016)的全部四項冠軍。TAGE的理念是,程序中的不同分支需要不同的歷史(狀態)長度。換句話說,對于某些分支,非常小的歷史記錄效果最好。例如1位預測器:如果某一分支以前采用過,它將再次采用。不同的分支可能依賴于先前的分支,因此需要更長的多位歷史以充分預測它是否將被采用。標記幾何歷史長度(TAGE)預測器由多個全局歷史查找表組成,這些表使用不同長度的全局歷史寄存器索引,以便涵蓋所有這些情況。寄存器使用的長度形成了幾何級數,因此得名。
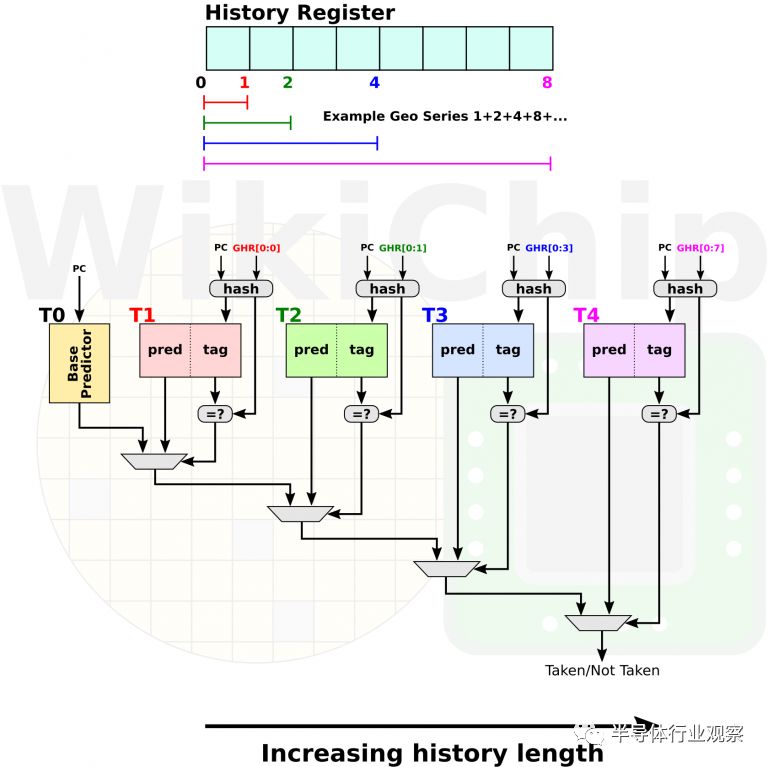
使用TAGE預測器的想法是,它試圖找出哪個分支的歷史數量最適合哪個分支,將最長的歷史優先于較短的歷史。
這種多預測器方案類似于BTB的分層。第一級預測器是感知器,用于快速查找(例如,單周期分辨率)。第二級TAGE預測器是一個復雜的預測器,需要很多周期才能完成,因此必須在簡單預測器之上分層。換句話說,L2預測器速度較慢,但(精度)更好,因此用于對較快和較不準確預測器的結果進行雙重檢查。如果L2預測器與L1預測器不同,則當TAGE預測器覆蓋感知器預測器時,會發生少量刷新,提取返回并使用L2預測,因為L2預測器被認為是更準確的預測。
除了使用TAGE預測器以外,AMD沒有透露更多的內容。值得指出的是,至少就字面而言,TAGE預測器不再被認為是最好的預測器。之后,Seznec在TAGE預測器上進行了改進,增加了統計校正器(TAGE-SC),后來又增加了循環預測器(TAGE-SC-L)。替代方案包括BATAGE預測器。盡管如此,我們得到的結論是,有更多的機會找到更好的分支預測器,這是一個非常活躍的研究領域。
AMD表示,與之前的與前幾代所采用的神經網絡相比,新的分支預測單元顯示出的預測的誤差率比前幾代產品下降30%。因為現代微處理器的預測精確度高達90%。與在Zen中的實現相比,這種錯誤預測率的大幅降低將直觀得轉化為IPC方面的提升。事實上,如此大的改進也是Zen2所宣稱的重大改進的最主要體現。
改變現狀
關于AMD的這一代芯片,我們注意到的一件事是現狀的變化。從歷史上看,英特爾在設計最先進、性能最好的預測器方面投入了大量資源。另一方面,AMD往往落后于一個“足夠好”的更保守的預測器。隨著Zen的成功,Zen 2的情況變得有所不同。雖然AMD正在摘取所有唾手可得的成果,但它們現在正直接瞄準英特爾,而英特爾一直擁有無可爭辯的領先優勢。換句話說,AMD似乎對他們目前的核心設計充滿信心,可以騰出更多的資源來解決次要的缺陷。
OC模式改進
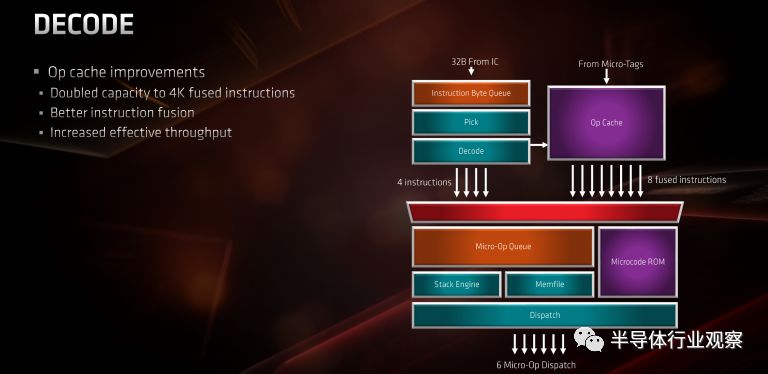
Zen 2和Zen一樣,有兩種主要的操作模式:IC(指令緩存)模式和OC(Marco-op宏指令緩存)模式。對于熟悉英特爾術語的人來說,這些術語類似于英特爾的DSB和MITE路徑。在Zen 2中,IC模式路徑本身基本保持不變,本文不再討論。另一方面,OC模式得到了增強。
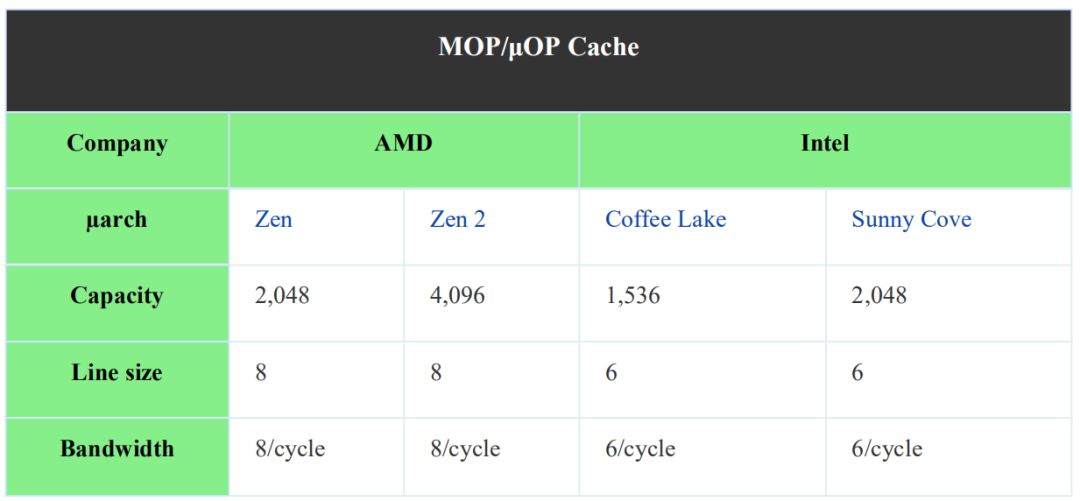
當指令被解碼時,它們被存儲在Op緩存中。與L1緩存一樣,OC也對64字節的緩存行進行(緩存)操作。這使你能夠在每個表項中存儲多達8個宏指令(不用說,64b imm/etc將占用兩個延遲槽)。在Zen中,OC被組織為8路32組(8 ways with 32 sets),這意味著總容量可達2048 MOP。在Zen 2中,AMD將容量翻了一番,達到4096 MOP。據推測,這是通過將組的數量增加一倍來實現的。順便說一下,啟用SMT(現場多線程操作)后,每個線程的容量只有原來的一半。這意味著在Zen 2上,每個線程的有效容量都等于Zen 1的整個OP緩存。
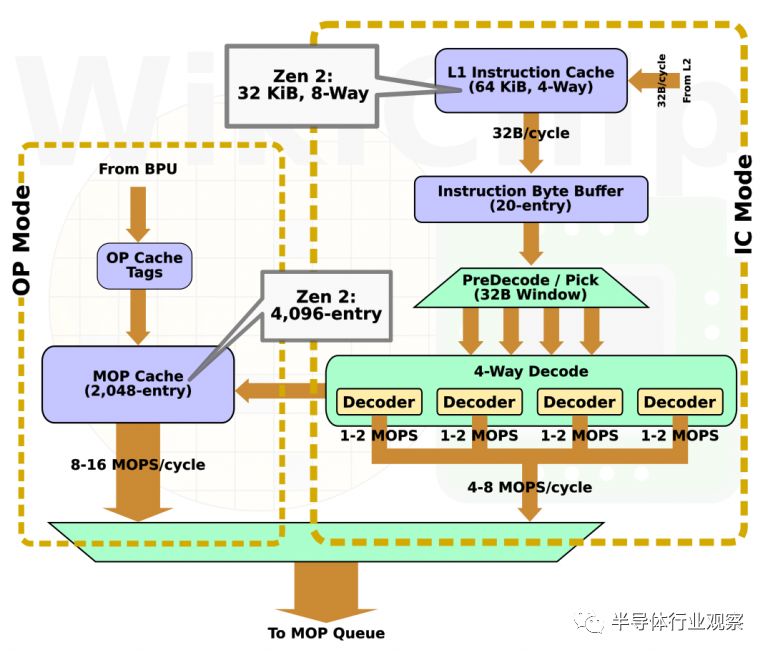
一旦在OC模式下操作,流水線將保持在這種模式,直到讀取地址發生未命中為止。在OC模式下,前端的其余部分為時鐘門控。假設所有其他條件都相同,較大的OC應允許Zen 2保持在OC模式以獲得更長的指令流,從而提高IPC吞吐量,同時降低前端的功耗。與Zen一樣,OC模式能夠在每個周期向后端發送多達8條指令,是IC模式帶寬的兩倍。值得注意的是,由于重新排序緩沖區仍然只能處理每個周期最多6個MOP,因此OP緩存上的更高吞吐量僅有助于確保op發射隊列保持填充狀態。
(流水線)后端
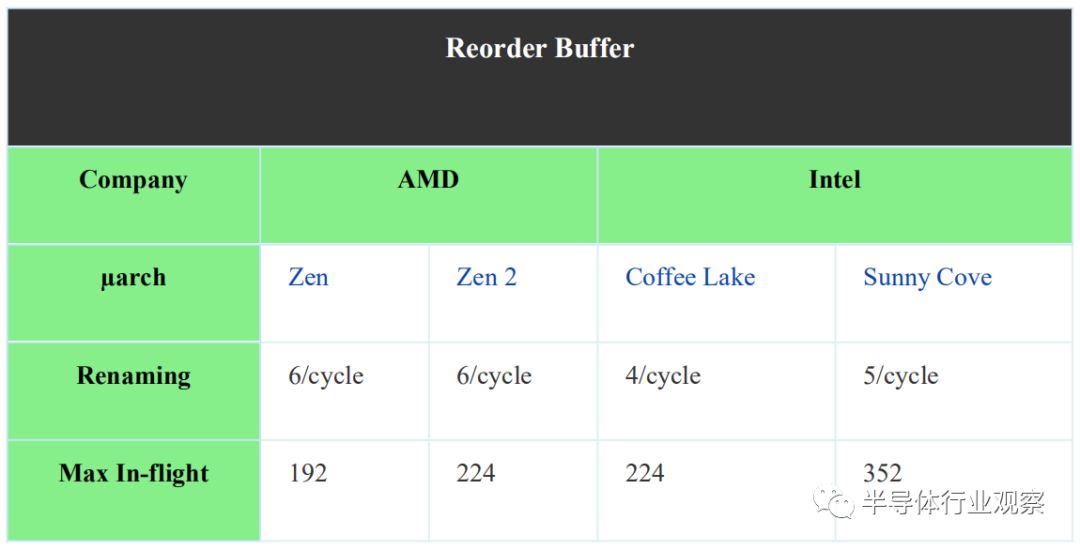
由流水線的分派端開始,宏指令被發送到整數單元或浮點單元。RCU(在其他設計中也稱為ROB)負責跟蹤所有未完成的指令。在Zen和Zen 2中,RCU都執行完整的宏指令,每個周期最多可以寄存器重命名6個MOP,可以退休和提交8個MOP。Zen上的重新排序緩沖區能夠跟蹤正在進行的192個宏指令。(ROB)這在Zen 2上增加了大約15%,達到了224個。與Skylake上的重新排序緩沖區大小相同。
與Bulldozer一樣,Zen和Zen 2都有三種指令分類類型:FastPath Single、FastPath Double和VectorPath(又名Microcode)。FastPath Single表示一條指令由一個宏指令組成,而FastPath Double表示一條指令由兩個宏指令組成。VectorPath意味著兩個以上的宏指令(例如REP MOV)。當宏指令到達調度器時,在寄存器重命名/映射之后,宏指令被分解為微指令。一般來說,自Zen以來,大多數指令都是轉化為FastPath Single密集宏操作。隨著AVX2的變化,這一點看起來更加真實。
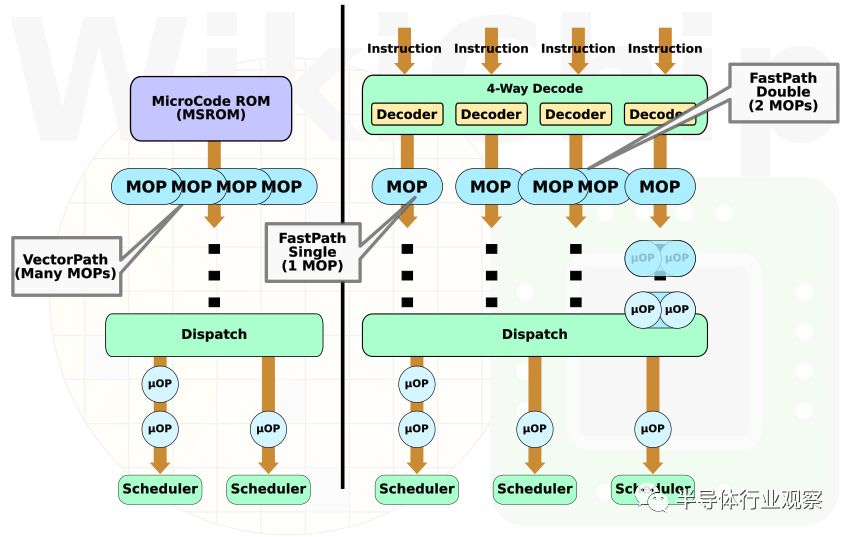
作者注:自從引入Zen以來,AMD不再努力消除x86指令、宏操作和微操作之間的歧義。此外,再加上充滿錯誤的手冊,這使得正確描述流水線變得極其困難。盡管如此,WikiChip仍然堅持描述盡可能精確的實現模型。
整數(單元)
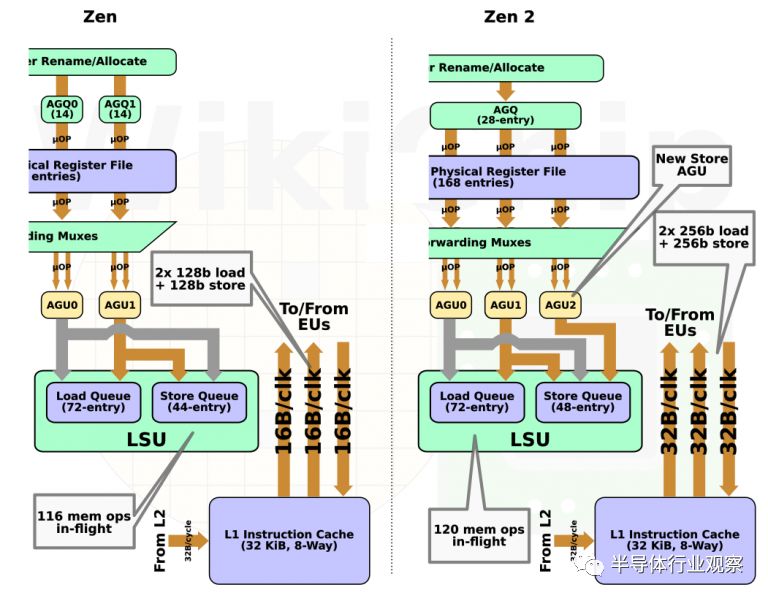
從分派開始,每個周期最多可以將6個MOPS調度到整數執行單元。在這里,MOP被分解為組成它們的微操作。例如,FastPath Single指令(例如從內存做加法reg,[mem])將被分解為2個微操作:加載和加法。一般來說,μops可以分為ALU和訪存讀/寫兩種類型。μops將根據其類別發送到適當的調度器。像Zen一樣,Zen 2有4個ALU調度器。這些調度器現在有兩個更深的表項,這意味著它們可以略微更深地排隊進入亂序執行窗口。理論上,從早期操作數可用性中提取一些額外并行性的可能性很小。讀寫μops將在AGU調度器中排隊。在Zen中,有兩個AGU調度器,每個調度器的深度為14個表項。在Zen 2中,這些調度器被合并成一個包含28個條目的大型調度器。如你所見,盡管他們選擇添加另一個AGU,但條目總數并沒有改變。
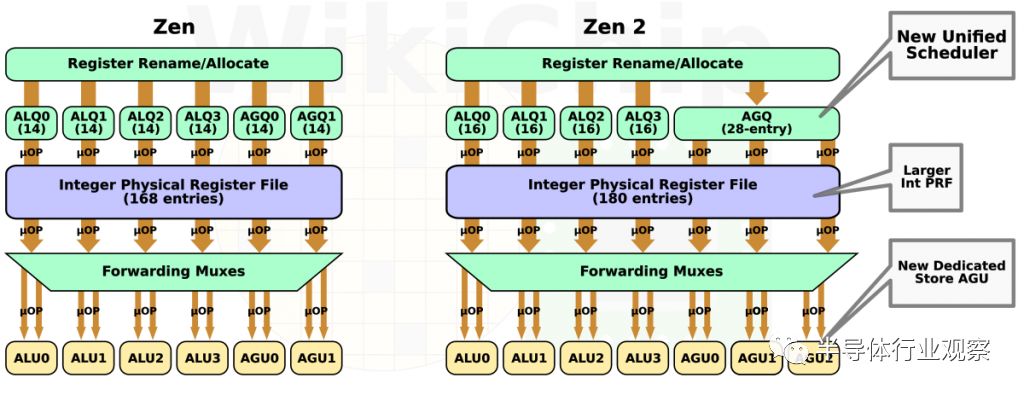
調度器將μops排隊,同時跟蹤相關性和操作數是否準備好。一旦準備就緒,就會發送μops以供執行。每個調度器每個周期每個流水線可以發送一個μop。就像在Zen中一樣,有4個ALU。Zen 2引入了另一個AGU,所以現在有3個。我們將在后面的一節中對此進行詳細討論。
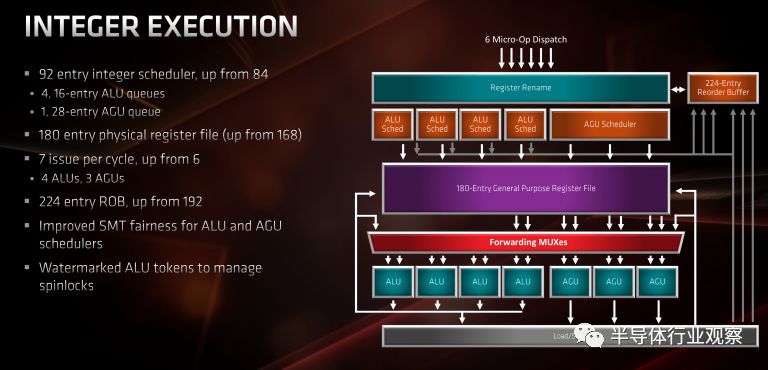
浮點(單元)
從流水線分派開始,每個周期最多可以向浮點單元發送4個MOP。這里MOP被分解為組成它們的微操作,這些微操作在非調度等待緩沖器處排隊,該緩沖器可以提前啟動存儲器請求。最后,μops在36條目調度隊列中排隊等待執行。大多數浮點單元都沒有改變,包括調度器、它們的大小和執行流水線(級數)。仍然是4條并行的執行線。
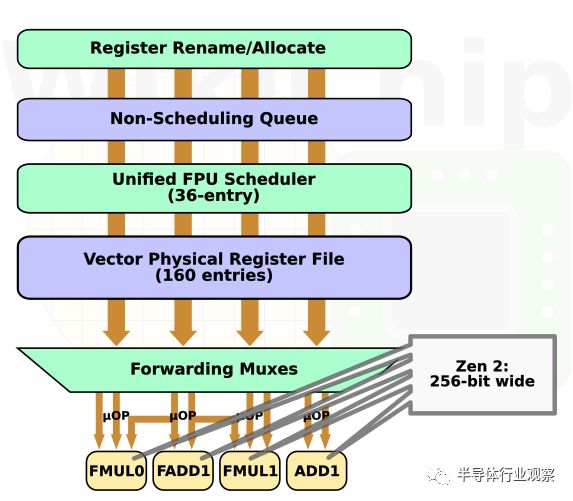
Zen 2最大的變化是流水線的寬度。Zen、Zen+和Zen 2都支持FMA和AVX2。在Zen 2之前,256位指令被解碼為FastPath Double,產生兩個MOP,每個最終都被分解成兩個μop。這不僅消耗了額外的資源,而且意味著256位向量的吞吐量是128位向量的吞吐量的一半。Zen 2拓寬了整個FPU數據路徑。現在每個流水線都是256位寬。這大概意味著所有那些256位指令都將解碼為FastPath Single,生成單個MOP并提高整個有效吞吐量。熟悉英特爾AVX2的人會知道,對于AVX2繁重的工作負載,當處于turbo模式時,由于功耗較高,AVX2失調設置,avx指令集在跑分時會主動降頻做的設置將會啟動。Zen 2本身沒有類似的偏移,但你可能會注意到,作為AMD Precision Boost 2的一部分的節流,它控制著溫度和電流,并確保平臺功率不會過高。

值得一提的是,現在兩個FMA單元都是256位寬,每個Zen 2內核的總FLOP是16個雙精度FLOP /周期。這意味著他們已經與Haswell、Broadwell,以及所有英特爾主流客戶端處理器達到了同等水平。但是,Cascade Lake每個周期能夠進行32次雙精度浮點運算。
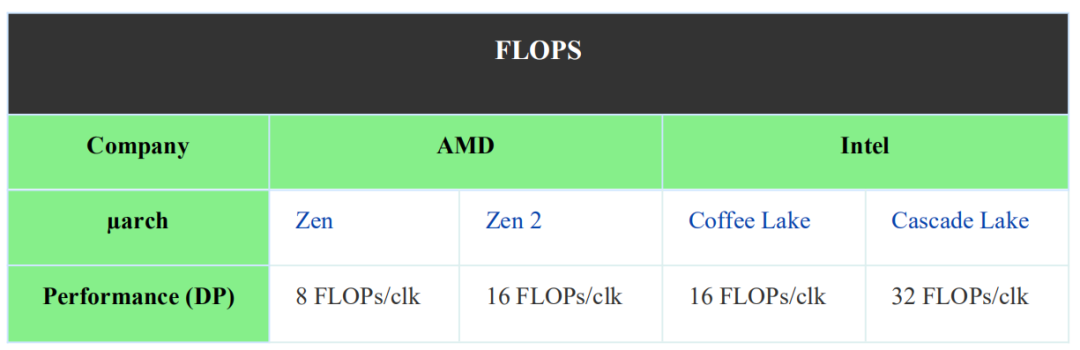
請注意,目前AMD不支持AVX512。然而,AMD擴展整個浮點單元為方便地支持AVX512作為FastPath Double鋪平了道路,就像他們最初對AVX2所做的那樣。雖然并非所有這些都是微不足道的補充,但是期望第一個實現使用較窄的流水線(例如256位)實現并非不合理。就像在Zen和Zen+上實現AVX2一樣,以一半的吞吐量運行。
內存子系統
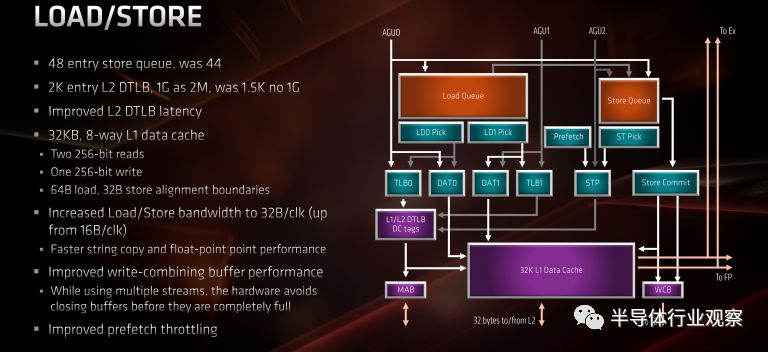
內存子系統在Zen 2上得到了增強。L2數據TLB現在增加了512個條目,并且通過2M頁表粉碎(2M page smashing)對1G頁面有了新的支持。AMD表示,他們能夠從L2 TLB訪問中節省一些周期。
在整數集群方面,AMD增加了一個新的AGU單元。與其他兩個單元不同的是,這個單元專門用于存儲。換句話說,加載μops可以在AGU0和AGU1上執行,而存儲可以發送到三個單元中的任何一個。
更重要的是,為了適應FPU單元的擴展,數據高速緩存的內存帶寬也增加了一倍。Zen有一個雙端口數據緩存。它能夠執行兩次讀取或每個周期執行一次讀取和一次寫入。以前,兩個端口都是128位的。Zen 2現在能夠執行完整的256位訪存讀寫。將帶寬加倍到64字節將對依賴于AVX2或復制/流任務的一類工作負載產生積極影響。請注意,L2帶寬仍為32B,L3也是如此。
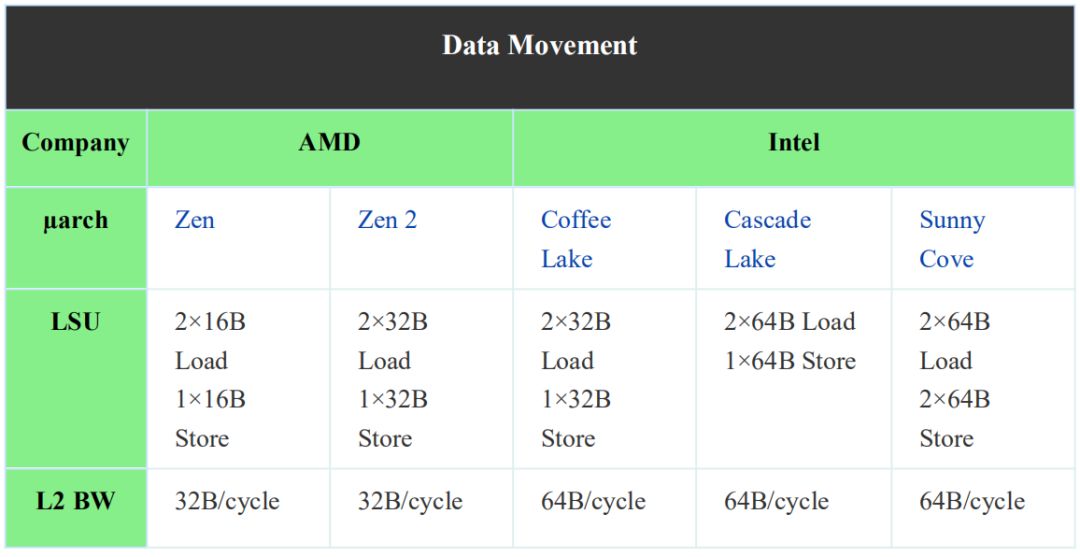
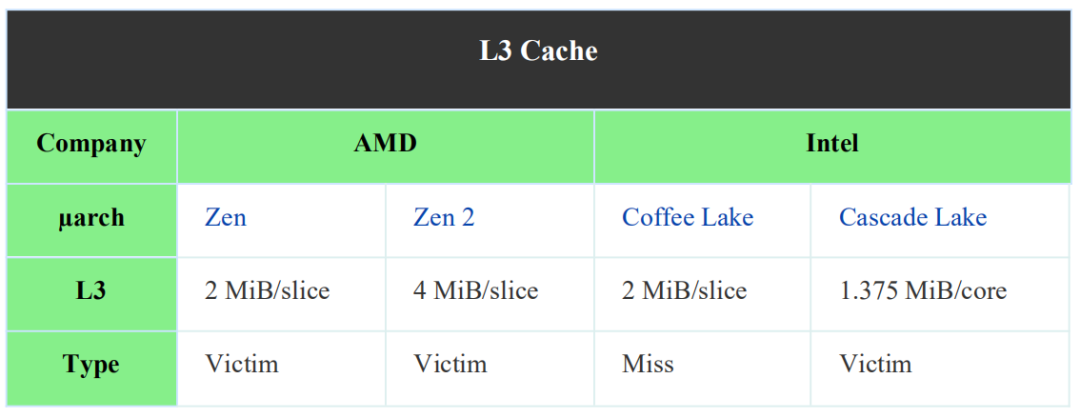
稍微超出核心的話題是三級緩存。L3支持L2緩存的32B/周期帶寬。此緩存是犧牲緩存。它由來自CCX的4個核心中的任何一個的L2victim line填充,L2標簽在L3中被復制。在Zen 2中,AMD將L3的大小增加了一倍,達到每個內核16 MiB-4 MB緩存分片(cache slice)。這對AMD的影響更明顯,原因在于他們的chiplet設計。對于這一點,我們會在未來的文章中討論。
-
處理器
+關注
關注
68文章
19178瀏覽量
229202 -
芯片
+關注
關注
454文章
50460瀏覽量
421980 -
內存
+關注
關注
8文章
3004瀏覽量
73900
發布評論請先 登錄
相關推薦
AMD官方數據:Zen 2 IPC性能提升近30%
主流500系主板 Zen 3處理器超頻實戰測評
AMD談新一代Zen處理器:更高的IPC,更強超頻能力
IMXRT1176 M4核心慢的原因是什么?
AMD展示次世代“Zen”處理器核心性能
曝Zen2架構性能將提升16%
AMD之前就公布Zen2架構的IPC性能變化 比Zen架構提升29%之多
曝Zen 3架構IPC性能將比Zen 2提升10~15%
Zen 3構架迎來大改,三級緩存容量翻倍性能提升
英特爾酷睿i7-1165G7處理器跑分成績公布 單核心性能也有優勢
AMD自爆5nm Zen4:核心數可能增加 架構改進幅度不會遜于Zen3
小米11核心性能首次揭秘:GPU性能升級、單核領先麒麟9000達13.2%
淺談IDC連接器的核心性能指標






 工商網監
工商網監
評論