 回顧FPGA的三個時代分析和可編程介紹的分析
回顧FPGA的三個時代分析和可編程介紹的分析
來源:本文由半導體行業觀察翻譯自IEEE Fellow Stephen M. (Steve) Trimberger寫的文章Three Ages of FPGAs: A Retrospective on the First Thirty Years of FPGA Technology,謝謝。
自引入以來,現場可編程門陣列(FPGA)的容量增加了10000倍以上, 性能增加了100倍. 單位功能的成本和功耗都減少了超過1000倍. 這些進步是由工藝縮放技術所推動的, 但是 FPGA 的故事比簡單縮放技術的更復雜. 摩爾定律的數量效應推動了FPGA在體系結構、應用和方法方面發生質的變化. 因此, FPGA 已經經歷了幾個不同的發展階段. 本文分別總結了發明、擴張、累積這三個階段, 并討論了它們的驅動壓力和基本特征. 本文最后展望了未來的FPGA階段.
Xilinx 在1984年引入了第一個現場可編程門陣列(FPGAs), 盡管直到Actel在1988年普及這個術語它們才被稱為FPGAs. 在接下來的30年里,我們稱之為FPGA的設備的容量增加了1萬多倍,速度增加了100倍. 單位功能的成本和能耗降低了1000倍以上(見圖1).

圖1 Xilinx FPGA屬性相對于1988年。容量指邏輯細胞計數。速度指可編程織物的同功能性能。價格指每個邏輯單元。能量指每個邏輯單元。價格和能量按一萬倍放大。數據來源: Xilinx發表的數據。
這些進步在很大程度上是由工藝技術驅動的, 隨半導體的擴展, 很容易把 FPGA 的進化看成是一個簡單的容量發展. 這種看法太簡單了。FPGA 進展的真實故事要有趣得多。
自其引入以來, FPGA 設備經過幾個不同的發展階段已取得進展. 每個階段都受到工藝技術機會和應用程序需求的驅動。這些驅動壓力引起設備特性和工具的可觀察變化。在本文中, 我們回顧了FPGA的三階段. 每個階段長達8年, 并且每一段在回顧中都很明顯。
三個階段分別是:
1)發明階段, 1984–1991;
2)擴張階段, 1992–1999;
3)累積階段, 2000–2007.
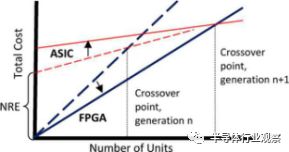
圖2. FPGA與ASIC交叉點。 圖表顯示總成本與單位數量。 FPGA線條較暗,從左下角開始。 隨著下一個工藝節點的采用(從較早節點的虛線箭頭到稍后節點的實線箭頭),由垂直虛線表示的交叉點變大。
二、前言: 關于FPGA的重大問題有哪些?
A.FPGA VS ASIC
20世紀80年代,專用集成電路(ASIC)公司為電子市場帶來了一個驚人的產品:定制集成電路。 到20世紀80年代中期,有數十家公司在銷售ASIC,在激烈的競爭中,成本低,容量大,速度快的技術更具受青睞。 當FPGA出現的時候,它在所有這幾個方面上都并不突出,但卻一枝獨秀。這是為什么?
ASIC的功能是由自定義掩模工具決定的。ASIC的客戶為這些掩模工具支付了前期的一次性工程(NRE)費用。由于沒有定制的工具,FPGA降低了預付成本和建立定制數字邏輯的風險。通過制造一種可以被成百上千的客戶使用的自定義硅設備,FPGA供應商可以有效地平攤所有客戶的NRE成本,從而不會對任何一個客戶收取任何費用,又同時增加了每個客戶的單位芯片成本。
前期的NRE成本確保了FPGA在某些數量上比ASIC更具成本效益。FPGA供應商在他們的“交叉點”上吹噓這個數字,這個數字證明了ASIC的更高的NRE開銷。 在圖2中,圖線顯示了購買數量單位的總成本。 ASIC具有NRE的初始成本,并且每個后續單元將其單位成本增加到總數。 FPGA沒有NRE電荷,但是每個單元的成本都比功能相當的ASIC要高,因此斜率更陡峭。 兩條線在交叉點相遇。 如果所需的單元數量少于此數量,則FPGA解決方案便宜; 超過該數量的單位表明ASIC具有較低的總體成本。
由于NRE成本占ASIC總體擁有成本的很大一部分,所以FPGA每單位成本超過ASIC成本的優勢隨著時間的推移而減少。 圖2中的虛線表示某個工藝節點的總成本。 實線表示下一個工藝節點的情況,NRE成本增加,但是每個芯片的成本較低。 FPGA和ASIC都利用低成本制造,而ASIC NRE收費繼續攀升,推高交叉點。 最終,交叉點變得如此之高,以至于大多數客戶,單元的數量已經不再適用于ASIC。 定制芯片只保證非常高的性能或很高的體積; 所有其他人可以使用可編程解決方案。
摩爾定律最終將推動FPGA能力覆蓋ASIC要求,這是對可編程邏輯業務的一個基本早期認識。如今,器件成本在性能,上市時間,功耗,I / O容量以及其他功能方面都不如FPGA。許多ASIC客戶使用較老的工藝技術,降低了NRE成本,但降低了單芯片成本優勢。
FPGA不僅消除了前期掩蔽費用并降低庫存成本,而且通過消除整個類別的設計問題也降低了設計成本。這些設計問題包括晶體管級設計,測試,信號完整性,串擾,I / O設計和時鐘分配。
與低前期成本和簡單設計一樣重要的是,主要的FPGA優勢是即時可用性和降低的故障可見性。盡管大量的仿真時,ASIC第一次似乎很少是正確的。隨著晶圓制造周轉時間在幾個星期或幾個月內,芯片重新調整對時間安排造成重大影響,而且隨著掩膜成本的上升,芯片重新調整對公司日益增長的水平而言是顯而易見的。錯誤的高成本要求廣泛的芯片驗證。由于FPGA可以在幾分鐘內完成重做,因此FPGA設計不會因為錯誤而延誤數周。因此,驗證不一定要徹底。 “自我模仿”,俗稱“下載試用”,可以代替大量的模擬。
最后看一下ASIC生產風險:ASIC公司只有在客戶的設計投入生產時才賺錢。 在20世紀80年代,由于開發過程中需求的變化,產品故障或完全設計錯誤,只有三分之一的設計實際投入生產。 三分之二的設計損失了錢。 這些損失不僅由ASIC客戶承擔,還由ASIC供應商承擔,這些供應商的NRE收費很少包括他們的實際成本,從未在快速貶值的制造設施中彌補失去機會的成本。 另一方面,可編程邏輯公司和客戶仍然可以小批量賺錢,并且可以快速糾正小的錯誤,而不需要昂貴的掩模。
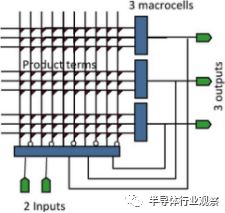
圖3.通用PAL架構。
B. FPGA VS PAL
可編程邏輯在FPGA之前就已經建立起來了。在20世紀80年代早期,EPROM編程的可編程陣列邏輯(PAL)已經開辟了一個市場。但是,FPGA具有體系結構優勢。為了理解FPGA的優勢,我們首先看看這些早期的80年代器件的簡單可編程邏輯結構。一個PAL設備,如圖3所示,由一個兩級邏輯結構組成。顯示輸入在底部。在左邊,一個可編程和陣列產生產品條款,以及輸入和它們的反轉的任何組合。右側塊中的固定或門完成宏單元產品術語的組合邏輯功能。每個宏單元輸出是芯片的輸出。宏單元中的可選寄存器并反饋到和陣列的輸入使得實現非常靈活的狀態機成為可能。
不是每一個功能都可以通過PAL的宏單元陣列實現一次,但是幾乎所有的常用功能都可以,而那些不可能通過陣列實現的功能。無論執行的功能還是位于陣列中的位置,通過PAL陣列的延遲都是相同的。 PAL具有簡單的擬合軟件,可將邏輯快速映射到陣列中的任意位置,而不會影響性能。 PAL適配軟件可以從獨立的EDA供應商處獲得,使IC制造商可以輕松地將PAL添加到他們的產品線中。
從制造的角度來看,PAL是非常有效的。 PAL結構與EPROM存儲器陣列非常相似,其中晶體管被密集地包裝以產生有效的實現。 PAL與存儲器非常相似,許多存儲器制造商能夠用PAL來擴展他們的產品線。當周期性內存業務出現停滯時,內存廠商進入可編程邏輯業務。
當考慮縮放時,PAL的架構問題是顯而易見的。在和陣列中的可編程點的數量隨著輸入數量的平方(更確切地說,輸入乘以乘積項)的平方增長。工藝縮放以收縮因數的平方來提供更多的晶體管。然而,陣列中的二次增加限制了PAL僅通過收縮因數線性增長邏輯。 PAL輸入和產品期限也很重,所以延遲隨著尺寸的增加而迅速增長。像任何這種類型的存儲器,PAL都具有跨越整個芯片的字線和位線。隨著每一代,所編程的晶體管的驅動與負載的比例下降。更多的投入或產品條款增加了這些線路的負載。增加晶體管尺寸以降低電阻也提高了總電容。為了保持速度,耗電量急劇上升。大型PAL在區域和性能上都是不切實際的。作為回應,在20世紀80年代,Altera率先推出了復雜可編程邏輯器件(CPLD),由多個PAL型塊組成,其中較小的交叉開關連接。但FPGA具有更具可擴展性的解決方案。
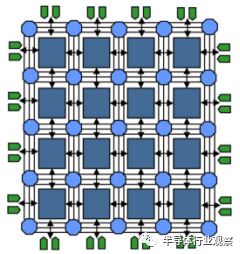
圖4.通用陣列FPGA架構。 4 4陣列,每行和每列有三條接線軌跡。 開關位于交叉點的圓上。 設備輸入和輸出分布在陣列周圍。
FPGA的創新是消除了提供可編程性的數組和陣列。相反,配置存儲器單元分布在陣列周圍以控制功能和布線。這種改變放棄了PAL結構的類似存儲器陣列的效率,有利于架構的可擴展性。如圖4所示,FPGA的架構由一系列可編程邏輯塊組成,并與現場可編程開關互連。 FPGA的容量和性能不再受到陣列的二次增長和布線布局的限制。并不是每一個功能都是芯片的輸出,所以容量可以隨著摩爾定律而增長。
?FPGA架構看起來不像內存。 設計和制造與內存非常不同。
?邏輯塊較小。 不能保證一個單一的功能可以融入其中。 因此,提前確定將有多少邏輯適合FPGA是很困難的。
?FPGA的性能取決于邏輯放置在FPGA中的位置。 FPGA需要布局和布線,所以完成的設計的性能不容易事先預測。
?需要使用復雜的EDA軟件來將設計融入FPGA。
隨著陣列和陣列的消除,FPGA架構師可以自由構建任何邏輯模塊和任何互連模式。 FPGA架構師可以定義全新的邏輯實現模型,而不是基于晶體管或門,而是基于自定義功能單元。 延遲模型不需要基于金屬線,而是基于節點和開關。 這個架構自由迎來了FPGA的第一個階段,即發明階段。
三、發明階段 1984~1991
首款FPGA,即賽靈思XC2064,只包含64 個邏輯模塊,每個模塊含有兩個3輸入查找表 (LUT) 和一個寄存器。按照現在的計算,該器件有 64 個邏輯單元——不足 1000 個邏輯門。盡管容量很小,XC2064 晶片的尺寸卻非常大,比當時的微處理器還要大;而且采用 2.5 微米工藝技術勉強能制造出這種器件。
每功能的晶片尺寸和成本至關重要。XC2064 只有 64 個觸發器,但由于晶片太大,成本高達數百美元。產量對大晶片來說是超線性的,因此晶片尺寸增加 5% 就會讓成本翻一倍,讓良率降至零,同時也導致初期的賽靈思無產品可賣。成本控制不僅僅是成本優化的問題;更是牽扯到公司生存問題。
在成本壓力下,FPGA 架構師尋求通過架構和工藝創新來盡可能提高 FPGA 設計效率。盡管基于 SRAM 的 FPGA 是可重編程的,但是片上 SRAM 占據了FPGA 大部分的晶片面積。基于反熔絲的 FPGA 以犧牲可重編程能力為代價,避免了 SRAM 存儲系統片上占位面積過大問題。
在20世紀80年代,賽靈思的四輸入LUT架構被認為是“粗粒度”的。四輸入功能被視為邏輯設計中的“甜蜜點”,但網表分析表明許多LUT配置未被使用。而且,許多LUT沒有使用投入。為了提高效率,FPGA架構師希望能夠消除邏輯塊中的浪費。幾家公司實現了包含固定功能的更細粒度的體系結構,以消除邏輯單元浪費。 Algotronix CAL使用一個固定MUX功能實現雙輸入LUT 。 Concurrent公司(后來的Atmel)和他們的被許可人IBM公司使用了一種小型單元,包括雙輸入nand和異或門和CL器件中的一個寄存器。皮爾金頓將其架構作為邏輯塊作為邏輯塊。他們授權Plessey(ERA系列),Toshiba(TC系列)和Motorola(MPA系列)使用基于nand-cell的SRAM編程設備。細粒度架構的極限是交叉點CLi FPGA,其中各個晶體管通過反熔絲可編程連接相互連接。
早期的FPGA架構師指出,高效的互聯體系結構應該遵守集成電路的二維性。 PAL的長而慢的線被相鄰塊之間的短連接代替,這些短連接可以根據需要通過編程串聯在一起以形成更長的路由路徑。最初,簡單的傳輸晶體管將信號引導通過互連段到相鄰的塊。接線效率高,因為沒有未使用的導線部分。這些優化極大地縮小了互連區域,并使FPGA成為可能。與此同時,由于大電容和通過晶體管開關網絡分布的串聯電阻,通過FPGA布線增加了信號延遲和延遲不確定性。由于互連線和交換機增加了尺寸,但不是(計費)邏輯,所以FPGA架構師不愿增加太多。早期的FPGA非常難以使用,因為它們缺乏互連。
四、發明階段回顧
在發明階段,FPGA很小,所以設計問題很小。雖然他們是可取的,綜合甚至自動布局和路由不被認為是必不可少的。許多人認為,即使在當時的個人電腦上嘗試設計自動化也是不切實際的,因為在大型計算機上ASIC的布局和布線正在進行。手動設計,無論是邏輯的還是物理的,都是可接受的,因為問題的規模很小。手工設計往往是必要的,因為芯片上的路由資源有限。
完全不同的體系結構排除了ASIC業務中可用的通用FPGA設計工具。 FPGA供應商為其設備增加了EDA開發的負擔。隨著FPGA供應商嘗試并改進其架構,這最終被認為是一個優勢。過去十年的PAL制造商依靠外部工具供應商提供軟件來將設計映射到他們的PAL中。因此,PAL供應商僅限于工具供應商支持的架構,導致商品化,低利潤率和缺乏創新。在FPGA架構蓬勃發展的同時,PLD架構被扼殺。
強制性軟件開發的另一個優勢是,FPGA客戶不需要從第三方EDA公司購買工具,這會增加NRE成本。正如他們對NRE收費一樣,FPGA供應商將他們的工具開發成本分攤到他們的硅定價中,從而使他們的設備的前期成本非常低。無論如何,EDA公司對FPGA工具的興趣不大,因為市場分散,數量少,銷售價格低廉,而且需要在動力不足的電腦上運行。
在發明階段,FPGA比用戶想要投入的應用要小得多。因此,多FPGA系統變得流行起來,自動化的多芯片分區軟件被確定為FPGA設計套件的重要組成部分。
圖5. FPGA架構系譜樹
五、FPGA回顧
發明的階段以在FPGA業務中的殘酷耗損而告終。 第三節和在圖5的FPGA族譜里大部分的公司或產品名稱,一個現代讀者可能不會不知道。 許多公司消失了。 其他人在退出FPGA業務時悄然出售資產。 這種損耗的原因不僅僅是正常的市場動態。 技術發生了重大變化,那些沒有利用這些變化的公司就無法進行競爭。 由于摩爾定律引起的數量變化導致了使用半導體技術構建的FPGA的質變。 這些變化是擴張階段的特征。
六、擴張階段 1992~1999
到了20世紀90年代,摩爾定律繼續快速前進,晶體管數量每兩年增加一倍。由于開創無晶圓廠商業模式,FPGA創業公司在二十世紀九十年代初通常無法獲得領先的硅技術。結果,FPGA開始落后于工藝引入曲線。在20世紀90年代,隨著代工廠意識到使用FPGA作為過程驅動器應用的價值,他們成為了過程領導者。一旦能夠用新技術生產晶體管和導線,代工廠就能夠構建SRAM FPGA。 FPGA廠商出售他們巨大的設備,而代工廠改進他們的流程。新一代硅片的可用晶體管數量增加了一倍,這使可能最大的FPGA尺寸增加了一倍,而每個功能的成本也降低了一半。比簡單的晶體管縮放更重要的是,引入化學機械拋光(CMP)允許鑄造廠堆疊更多的金屬層。由于昂貴的(不可消耗的)互連的成本比晶體管的成本下降得更快,FPGA供應商積極地增加了設備上的互連以適應更大的容量(參見圖6),這對于ASIC來說是有價值的。這個快速的改進過程有以下幾個效果。
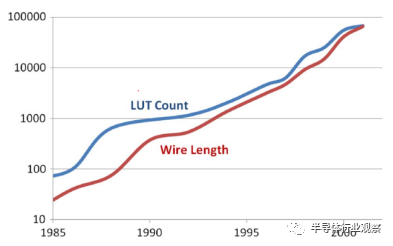
圖6. FPGA LUT和互連導線的增長導線長度,以數百萬個晶體管間距進行測量。
A.區域變得珍貴
在20世紀90年代中期沒有人加入FPGA行業,他們認為成本不重要,或者地區不重要。但是,那些在20世紀80年代經歷過產品開發痛苦的人當然看到了差異。在20世紀80年代,晶體管的效率是必要的,以便交付任何產品。在20世紀90年代,這僅僅是一個產品定義的問題。面積仍然是重要的,但現在它可以被交易的性能,功能和易用性。所得到的器件的硅片效率較低。在幾年前的發明階段,這是不可想象的。
B.設計自動化變得必不可少
在擴展階段,FPGA器件容量隨著成本的下降而迅速增長。 FPGA應用程序對于手動設計而言變得太大。 1992年,旗艦產品Xilinx XC4010交付了一個(聲稱)最多10000個門。到1999年,Virtex XCV1000被評為一百萬。在20世紀90年代早期,在擴張階段開始時,自動布局和路由是首選的,但不是完全可信的。到20世紀90年代末,自動化綜合,布局布線,是設計過程中需要采取的步驟。沒有自動化,設計的努力就會太棒了。現在,FPGA公司的壽命取決于設計自動化工具的目標設備的能力。那些控制他們軟件的FPGA公司控制著他們的未來。
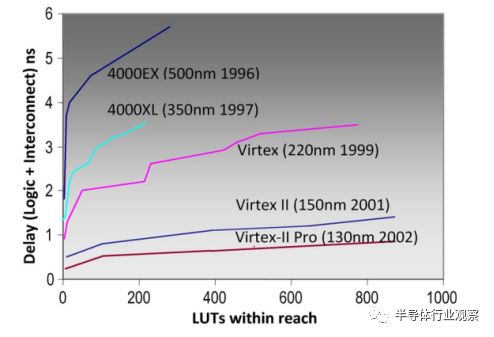
圖7.更長線長分段性能縮放。
來自工藝縮放的更便宜的金屬導致更多可編程的互連線,使得自動化的放置工具可以以較不精確的放置成功。自動化設計工具需要自動化友好型架構,具有常規和豐富的互連資源的架構,以簡化算法決策。更便宜的電線也承認了更長的電線分割,跨越多個邏輯塊的互連線。跨越多個塊的電線有效地使物理距離邏輯更接近邏輯,從而提高性能。圖7中的圖表顯示了來自工藝技術和互連范圍組合的大的性能收益。過程縮放本身會降低曲線,但保持形狀;更長的分割平坦了曲線。較長的分段互連簡化了布局,因為采用較長的互連,將兩個模塊精確對齊以將其與高性能路徑連接起來并不是必須的。
另一方面,當線段的整個長度未被使用時,金屬跡線的部分被有效地浪費。許多硅片效率的發明架構是以布線效率為基礎的,其特點是短線可以消除浪費。通常,他們嚴格遵循物理硅的二維限制,從而使這些FPGA成為“蜂窩”標簽。在擴展階段,更長的線分割是可能的,因為廢金屬的成本現在是可以接受的。由最鄰近連接主導的體系結構無法與利用較長線分割的體系結構的性能或易于自動化相匹配。
類似的效率轉變應用于邏輯塊。在發明階段,小的簡單的邏輯塊是有吸引力的,因為它們的邏輯延遲很短,并且因為在未使用或部分使用時浪費很少。當一個三輸入函數在其中被實例化時,四輸入LUT中的一半配置存儲器單元被浪費了。聰明的設計人員可以手動將復雜的邏輯結構映射到最小數量的細粒度邏輯塊,但自動化工具并不成功。對于更大的功能,連接幾個小塊的需求對互連提出了更高的要求。在擴張階段,不僅有更多的邏輯塊,而且塊本身變得更加復雜。
許多具有不規則邏輯塊和稀疏互連的高效發明架構難以自動布局和布線。在發明階段,這不是一個嚴重的問題,因為設備足夠小,手工設計是實用的。但擴張階段的許多設備和公司都面臨著過高的面積效率。基于最小化邏輯浪費的細粒度體系結構(如Pilkington nand-gate模塊,Algotronix / Xilinx 6200多路復用器2LUT模塊,交叉點晶體管模塊)簡直就不存在了。通過互連來實現其效率的架構也已經死亡。這些包括所有最近鄰居基于網格的架構。擴展階段也注定了時間復用設備,因為只需要等待下一代處理,相當的容量擴展就可以避免復雜性和性能的損失。 FPGA業務中的幸存者是那些利用工藝技術進步實現自動化的公司。 Altera首先將CPLD的長距離連接引入Altera FLEX架構。 FLEX比其他被短導線占主導地位的FPGA的自動化程度更高。它取得了快速的成功。 20世紀90年代中期,美國電話電報公司(AT&T)/朗訊(Lucent)發布了ORCA ,賽靈思公司在擴大XC4000互連數量和長度的同時擴大了設備規模。擴張階段由此確立。
C.作為選擇技術的SRAM的出現
摩爾定律快速發展的一個方面就是需要站在過程技術的最前沿。將容量加倍和邏輯成本減半的最簡單方法是針對下一個工藝技術節點。這迫使FPGA廠商采用領先的工藝技術。采用新技術難以實現的技術的FPGA公司在結構上處于劣勢。非易失性可編程技術如EPROM,Flash和反熔絲就是這種情況。當一種新的工藝技術可用時,可用的第一個組件是晶體管和電線,這是電子電路的基本組成部分。基于靜態內存的設備可以立即使用新的更密集的進程。對于特定的技術節點,防偽設備被精確地推廣為更高效,但需要數月或數年的時間才能確定新節點上的反熔絲。在反熔絲被證實的時候,SRAM FPGA已經開始在下一個節點上交付。防偽技術無法跟上技術發展的步伐,所以為了維持產品的平價,它們的效率要比SRAM高一倍。
防偽裝置有第二個缺點:缺乏重新編程能力。隨著客戶習慣于“易失性”SRAM FPGA,他們開始體會到系統內可編程性和硬件現場更新的優勢。相比之下,一次性可編程設備需要進行物理處理才能更新或修復設計錯誤。反熔絲設備的替代品是一個廣泛的類似ASIC的驗證階段,這削弱了FPGA的價值。
摩爾定律在擴張階段的快速發展將反熔絲和閃存FPGA降級為利基產品。
D. LUT作為選擇邏輯單元的出現
雖然在擴張時期被記錄下來的低效率,但有幾個原因,LUT仍然存在并占據主導地位。首先,基于LUT的體系結構是綜合工具的簡單目標。這個說法在20世紀90年代中期會有爭議,當時綜合供應商抱怨FPGA不是“合成友好的”。這種觀點產生是因為綜合工具最初是針對ASIC設計的。他們的技術映射者期望一個小型庫,其中每個單元被描述為一個帶有逆變器的網絡。由于LUT實現了22n個輸入組合中的任何一個,所以完整的庫將是巨大的。 ASIC技術映射工作者在基于LUT的FPGA上做了apoor工作。但到了20世紀90年代中期,有針對性的LUT映射器利用了將任意函數映射到LUT中的簡單性。
LUT具有隱藏的效率。 LUT是一個內存,并且存儲器在硅片中有效地布局。 LUT還可以節省互連。 FPGA可編程互連在面積和延遲方面是昂貴的。 FPGA互連不像ASIC那樣簡單的金屬線,而是包含緩沖區,路由多路復用器和存儲單元來控制它們。因此,更多的邏輯成本實際上是在互連。由于LUT實現了其輸入的任何功能,因此自動化工具只需要在LUT中將所需的信號一起發送,以淘汰這些輸入的功能。沒有必要為了創建一小組輸入的所需功能而使得多級LUT成為可能。 LUT輸入引腳是可任意交換的,所以路由器不需要針對特定的引腳。結果,基于LUT的邏輯減少了實現功能所需的互連數量。通過良好的綜合,來自未使用的LUT功能的浪費小于來自減少的互連要求的節省。
分布式存儲單元編程允許架構自由,并使FPGA供應商幾乎可以普遍獲得工藝技術。用于邏輯實現的LUT減輕了互連的負擔。 Xilinx衍生的基于LUT的體系結構出現在賽靈思的第二個來源:Monolithic Memories,AMD和AT&T。在擴展階段,其他公司,特別是Altera和AT&T / Lucent也采用了存儲單元和LUT架構。
七、插曲:FPGA 鐘形容量曲線
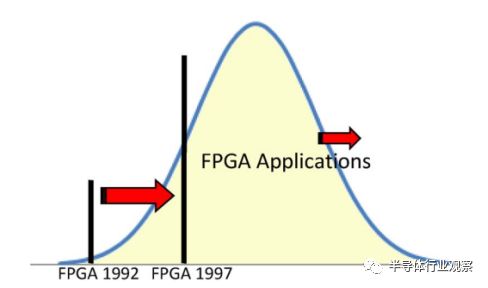
圖8. FPGA市場的增長
圖8中的鐘形曲線表示ASIC應用程序的大小分布的直方圖。某個時候的FPGA容量是X軸上的一個點,用豎條表示。條形圖左側的所有應用程序都是可以由FPGA來處理的應用程序,因此FPGA的可尋址市場是條形圖左側曲線下方的陰影區域。在擴展階段,摩爾定律的FPGA容量增加了,所以吧移到了右邊。當然,應用程序的整個鐘形曲線也向右移動,但應用程序大小的增長速度比FPGA容量增長要慢。結果,代表FPGA的條形圖相對于設計的分布迅速地移動。由于FPGA解決了曲線的低端問題,因此即使可用容量略有增加,也承認了大量的新應用。在擴展階段,FPGA容量覆蓋了現有設計的不斷增長的一小部分,并逐漸成為解決大部分ASIC應用的技術。
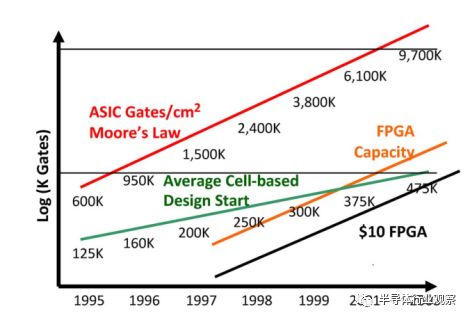
圖9.設計差距 來源:Synopsys,Gartner,VLSI Technology,Xilinx。
從1990年代后期在EDA供應商中流行的“設計差距”幻燈片中也可以看出這種增加的適用性(圖9)。按照摩爾定律,ASIC和FPGA的容量在增長:ASIC以每年59%的速度增長,FPGA以每年48%的速度增長。觀察到的平均ASIC設計開始增長速度要慢得多,每年只有25%。因此,FPGA容量在2000年達到了平均的ASIC設計規模,但是對于一個大的(昂貴的)FPGA。但到了2004年,預計10美元的FPGA將滿足ASIC的平均要求。在二十一世紀初,這個交叉點進一步發展,因為FPGA解決了ASIC市場的低端問題,而這些小型設計成為了FPGA設計。平均ASIC設計尺寸計算中不再包含小型設計,從而在新的千年中平均ASIC設計尺寸大幅增加。今天,由于FPGA幾乎成功吸收了ASIC業務的整個低端市場,所以平均ASIC比圖9所顯示的要大得多。
八、擴張階段回顧
通過擴張階段,摩爾定律迅速提高了FPGA的容量,導致了對設計自動化的需求,并允許更長的互連分段。過于高效的架構,無法有效自動化簡單地消失。 SRAM器件首先開發新的工藝技術并主導業務。由于FPGA器件容量的增長速度超過了應用的需求,FPGA正在侵蝕ASIC領域。用戶不再要求使用多FPGA分區軟件:設計有時適合于現有的FPGA。
隨著FPGA越來越流行,EDA公司開始為他們提供工具。然而,EDA公司的提議被懷疑。 FPGA退伍軍人已經看到PLD供應商如何通過交出軟件而失去對其創新的控制。他們拒絕讓這種情況發生在FPGA領域。此外,主要的FPGA公司擔心客戶可能會依賴外部EDA公司的工具。如果發生這種情況,EDA公司可以通過軟件工具價格有效地提升FPGA NRE。這將削弱FPGA的價值主張,將交叉點轉回到較低的交易量。一些重要的FPGA-EDA聯盟是在合成域V中由定義體系結構的物理設計工具進行的。盡管聯盟,FPGA公司保持競爭力的項目,以防止依賴的可能性。在擴展階段,FPGA供應商發現自己與ASIC技術和EDA技術競爭。
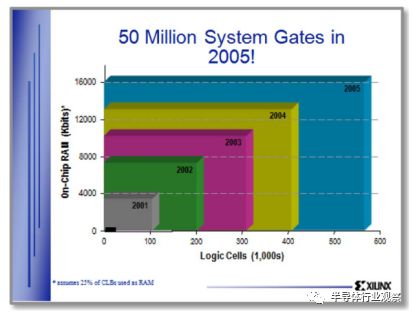
圖10. 賽靈思市場營銷,圖片由Xilinx提供。
九、插曲:XILINX的市場
到20世紀90年代后期,擴展階段在FPGA業務中得到了很好的理解。 FPGA供應商正在積極尋求處理技術,以解決其尺寸,性能和容量問題。 每一代新工藝都帶來了許多新的應用。 圖10中的幻燈片摘自2000年Xilinx市場推廣演示。當時可用的最大的FPGA Virtex 1000被描述為左下角的小黑色矩形。 幻燈片顯示,擴張階段將繼續有增無減,在接下來的五年里,把城門數量增加到5000萬。 盡管摩爾定律堅定不移,但這并沒有發生。 在下面的章節中,我們將研究真正發生的事情和原因。
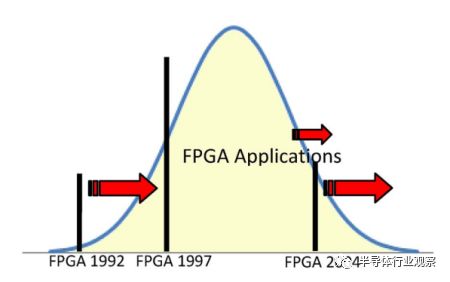
圖11. FPGA可尋址市場的增長正在縮小。
十、累積階段, 2000–2007.
在新千年的開始,FPGA是數字系統的通用組件。容量和設計規模不斷擴大,FPGA在數據通信行業中發現了巨大的市場。二十一世紀初的網絡泡沫造成了對低成本的需求。硅片制造的成本和復雜性日益增加,消除了“臨時”的ASIC用戶。定制芯片對于一個小團隊來說成功執行風險太大了。當他們看到他們可以將他們的問題融入到FPGA中時,他們就成了FPGA的客戶。
就像在擴張階段一樣,摩爾定律的必然步伐使FPGA變得更大。現在他們比典型的問題大。有能力比所需要的要多,沒有什么不好的,但是也沒有什么特別的美德。結果,客戶不愿意為最大的FPGA支付高額的費用。
僅僅增加產能也不足以保證市場的增長。再看圖11,FPGA鐘形曲線。由于FPGA容量通過了平均設計尺寸,鐘形曲線的峰值,容量的增加承認逐漸減少的應用。幾乎可以保證在擴張時期獲得成功的產品的尺寸,在接下來的幾年里,吸引越來越少的新客戶。
FPGA供應商通過兩種方式解決了這一挑戰。對于低端市場,他們重新關注效率,并生產低容量,低性能的“低成本”FPGA產品系列:Xilinx的Spartan,Altera的Cyclone和Lattice的EC / ECP。
對于高端市場,FPGA供應商希望能夠讓客戶更容易地填滿他們寬敞的FPGA。他們為重要功能制作了軟邏輯(IP)庫。這些軟邏輯功能中最值得注意的是微處理器(Xilinx MicroBlaze和Altera Nios),存儲器控制器和各種通信協議棧。在以太網MAC在Virtex-4的晶體管上實現之前,它是作為Virtex-II的軟核心在LUT中實現的。 IP組件的標準接口消耗了額外的LUT,但與節省設計工作量相比,效率不高。
大型的FPGA比一般的ASIC設計更大。到2000年代中期,只有ASIC仿真器需要多芯片分區器。更多的客戶有興趣在一個單一的FPGA上聚合多個可能不相關的組件。賽靈思推出了“互聯網可重構邏輯”和FPGA區域劃分,允許功能單元動態插入可編程邏輯資源的一個子集。
設計的特點在2000年代發生了變化。大型FPGA承認大型設計是完整的子系統。 FPGA用戶不再只是簡單地實現邏輯;他們需要他們的FPGA設計來遵守系統標準。這些標準主要是信號和協議的通信標準,用于連接外部組件或在內部組件之間通信。由于FPGA在計算密集型應用中的作用越來越大,處理標準也開始適用。隨著FPGA成長為客戶整體系統邏輯的一小部分,其成本和功耗也相應增長。這些問題比擴張階段變得更為重要。
遵循標準,降低成本和降低功耗的壓力導致了架構戰略的轉變,從簡單地增加可編程邏輯和乘以摩爾定律,如在擴展階段所做的,到添加專用的邏輯塊。這些模塊包括大存儲器,微處理器,乘法器,靈活的I / O和源同步收發器。由專門設計的晶體管而不是ASIC門構成,它們通常比ASIC的實現效率更高。對于使用它們的應用程序,他們減少了可編程性的面積,性能,功耗和設計工作量。
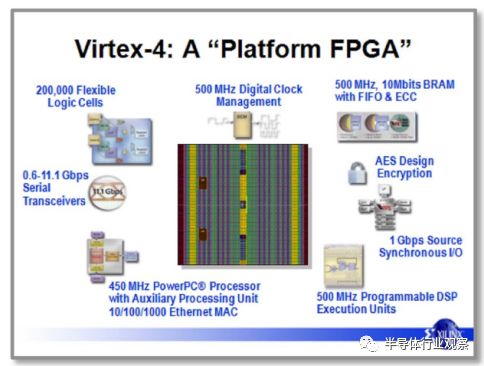
圖12.賽靈思市場營銷 圖片由Xilinx提供。
其結果是“平臺FPGA”,從2005年的賽靈思營銷幻燈片中捕獲到,如圖12所示。與圖10相比較,不再是數百萬門的消息,而是預定義的,性能專用塊。甚至“門”這個詞也從幻燈片中消失了。這個FPGA不僅僅是LUT,觸發器,I / O和可編程路由的集合。它包括乘法器,RAM塊,多個Power-PC微處理器,時鐘管理,千兆速率源同步收發器和位流加密,以保護設計的IP。 FPGA工具不斷增長,以實現這一不斷增長的實施目標。
為了減輕使用新功能和滿足系統標準的負擔,FPGA供應商提供了邏輯發生器,通過將其專用功能和軟邏輯相結合來構建目標功能。軟邏輯的生成器和庫為軟核和強化處理器上的外設提供了CoreConnect,AXI和其他總線的接口。他們還構建了圍繞串行收發器的固定功能物理接口的總線協議邏輯。 Xilinx系統生成器和Altera DSP Builder自動化了DSP系統的大部分組裝,由固定功能和LUT組合而成。為了簡化微處理器系統的創建,賽靈思提供了嵌入式設計套件(EDK),而Altera則發布了其嵌入式系統設計套件(ESDK)。這些功能的演示包括在FPGA處理器上運行的FPGA,在FPGA架構中進行視頻壓縮和解壓縮。
但是,那些不需要固定職能的積累年齡的客戶是什么呢?對于不需要Power-PC處理器,存儲器或乘法器的客戶來說,該塊的面積被浪費了,有效地降低了FPGA的成本和速度。起初,FPGA供應商試圖確保這些功能可以用于邏輯,如果他們不是主要用途的需要。他們提供了“大型LUT映射”軟件,將邏輯移入未使用的RAM塊。賽靈思發布了“超級控制器”,將狀態機映射到Virtex-II Pro中硬化Power-PC的微處理器代碼。但是這些措施最終被認為是不重要的。這表明我們距離發明階段還有多遠,FPGA供應商和客戶都只是接受了浪費的領域。 Xilinx副總裁表示,他將在FPGA上提供四個Power-PC處理器,并不關心客戶是否使用其中任何一個。我們給他們免費的處理器。

表1 FPGA上選定專用邏輯
十一、插曲:所有階段都如此
積累的階段并不是獨一無二的,正如增加設備的能力并不是獨特的擴張階段或獨特的發明階段的建筑創新。 在發明階段,門,路由和三態總線是可用的,而算術,內存和專用I / O出現在擴展階段(表1)。 在FPGA的各個階段都增加了專用的模塊,這充分表明它們將繼續在多樣性和復雜性方面發展。 一般來說,成功的專用功能本質上是通用的,使用可編程LUT和互連的靈活性來定制功能。 嘗試生產針對特定領域或特定應用的FPGA尚未證明是成功的,因為它們失去了FPGA經濟所依賴的批量生產的優勢。 當然,直到“積累階段”才引起了“通信FPGA”的興起。
十二、累積階段回顧
A.應用
“積累階段”中FPGA的最大變化是目標應用程序的變化。 FPGA業務不是從通用的ASIC替代發展而是由通信基礎設施的采用。 像Cisco這樣的公司使用FPGA來定制數據路徑,以便通過交換機和路由器轉發大量的互聯網和打包語音流量。 他們的性能要求消除了標準微處理器和陣列處理器,單位體積在FPGA交叉點內。 新的網絡路由架構和算法可以在FPGA中快速實施并在現場進行更新。 在“積累階段”,通信行業的銷售額迅速增長,超過FPGA業務的一半。
當然,這一成功使得主要FPGA制造商為通信行業定制FPGA。通信專用FPGA集成了高速I / O收發器,數千個專用高性能乘法器,能夠在不犧牲吞吐量的情況下制作大量數據路徑和深度流水線。為了更好地滿足通信應用需求而添加的專用塊和路由減少了可用的通用邏輯區域。到2000年代末,FPGA不像通用數據路由引擎那樣通用ASIC替代。隨著多核處理器和通用圖形處理器單元(GPGPU)的出現,FPGA仍然是高吞吐量,實時計算的首選。同時,FPGA保持其通用性。 FPGA逐位可編程能力確保了它們在包括控制和汽車系統在內的廣泛應用中的持續使用。
B. 摩爾定律
經典的Dennard縮放,同時在成本,容量,功耗和性能方面進行了改進,在2000年代中期結束。 后來的技術世代仍然在容量和成本方面進行了改進。 電力也在不斷改善,但與性能之間有著明顯的折衷。從一個技術節點到下一個技術節點的性能收益是適度的,并且與節能相抵消。 這種效應在圖1中的性能增長放緩中表現得很明顯。這些折衷也推動了功能的積累,因為如在擴展階段那樣簡單地依賴于工藝技術的縮放并不足以改善功率和性能。邏輯強化提供了必要的改進。
我們現在將步入FPGA的下一個階段,那么下一個階段是什么呢?
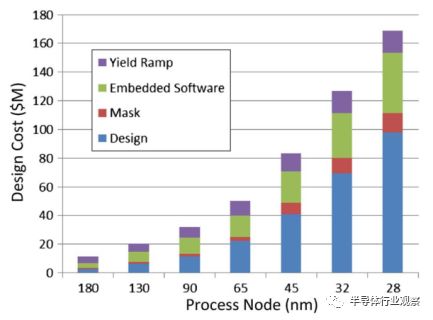
圖13.按全球流程節點估算的芯片設計成本。數據:賽靈思和Gartner,2011。
十三、目前階段:不再是可編程邏輯
在積累階段結束之前,FPGA不是門陣列,而是集成了可編程邏輯的累積模塊集合。他們仍然是可編程的,但不限于可編程邏輯。在累積階段獲得的可編程性的額外維度增加了設計負擔。設計工作是FPGA與ASIC競爭的一個優勢,與新近到來的多核處理器和GPU競爭是一個劣勢。
FPGA開發者繼續承受著壓力。 2008年開始的經濟放緩繼續推動降低成本的愿望。這種壓力不僅體現在降低功能價格的要求上,而且體現在降低使用這些設備的成本的低功耗上。后Dennard縮放處理技術未能實現新工藝技術在過去幾十年中所帶來的成本,容量,性能,功耗和可靠性方面的巨大并發利益。特別需要關注的是權力和績效之間的權衡。怎么辦?
A.應用
在積累階段,20世紀80年代把定制設備推向市場的ASIC公司正悄然消失。當然,定制插座專用ASIC器件仍然存在,但僅限于具有非常大的體積或極端操作要求的設計。 FPGA是否打敗了他們?好吧,部分。在2000年代,ASIC NRE收費對于大多數應用來說太大了。這可以在圖13中看到,其中開發成本以百萬美元繪制在技術節點上。定制設備的開發成本達到幾十億美元。一家將20%的收入用于研發的公司需要從芯片銷售中獲得5億美元的收s入,以此來支付億元的開發成本。 FPGA交叉點達到了數百萬個單位。有很少的芯片可以銷售,特別是微處理器,存儲器和手機處理器。伴隨著另一次經濟衰退,銷售不確定性和新產品收入的長期交易,結果是不可避免的:如果應用程序需求可以通過可編程器件滿足,則可編程邏輯是首選解決方案。 FPGA的優勢從最初的階段起依然在運行:通過共享開發成本降低總體成本。
ASIC并沒有消亡。 ASIC通過以應用特定標準產品(ASSP)片上系統(SoC)器件的形式增加可編程性而存活并擴展。 SoC結合了一系列固定功能模塊和一個微處理器子系統。通常為特定應用領域選擇功能塊,如圖像處理或聯網。微處理器控制數據流,并允許通過編程以及現場更新進行定制。 SoC為硬件解決方案提供了結構,編程微處理器比設計硬件更容易。利用FPGA的優勢,可編程ASSP器件服務于更廣泛的市場,更廣泛地分攤其開發成本。構建ASSP SoC的公司成為無晶圓半導體供應商,能夠滿足高開發成本所需的銷售目標。
隨著ASIC向SoC轉移,可編程邏輯供應商開發了可編程SoC。這絕對不是在數據通信領域如此流行的數據吞吐量引擎,也不是門陣列。可編程系統FPGA是完全可編程的片上系統,包含存儲器,微處理器,模擬接口,片上網絡和可編程邏輯模塊。這種新型FPGA的例子是Xilinx All-Programmable Zynq,Altera SoC FPGA和Actel / Microsemi M1。
B.設計工具
這些新的FPGA具有新的設計要求。最重要的是,它們是軟件可編程的,也是硬件可編程的。微處理器并不是象“積累階段”(Age of Accumulation)那樣將簡單的硬件模塊放入FPGA中,而是包含一個帶有高速緩存,總線,片上網絡和外設的完整環境。捆綁軟件包括操作系統,編譯器和中間件:整個生態系統,而不是一個集成的功能塊。一起編程軟件和硬件增加了設計復雜性。
但這仍然是冰山一角。為了實現替代ASIC或SoC的目標,FPGA繼承了這些器件的系統要求。現代FPGA具有功率控制,如電壓調節和Stratix自適應體偏置。最先進的安全性是必需的,包括Xilinx Zynq SoC和Microsemi SmartFusion中的公鑰加密技術。完整的系統需要混合信號接口來實現真實的接口。這些也監測電壓和溫度。所有這些都需要FPGA成為一個完整的片上系統,一個可信的ASSP SoC器件。因此,FPGA已經發展到邏輯門陣列通常不到面積的一半。一路上,FPGA設計工具已經發展到包含廣泛的設計問題。 FPGA公司的EDA工程師數量與設計工程師的數量相當。
C.工藝技術
盡管在過去的三十年中,工藝規模一直在穩步持續發展,但摩爾定律對FPGA架構的影響在不同的階段是截然不同的。為了在發明階段取得成功,FPGA需要積極的架構和流程創新。
在擴張階段,駕駛摩爾定律是解決不斷增長的市場的最成功的方法。隨著FPGA逐漸成為系統組件,它們被要求滿足這些標準,網絡泡沫破裂要求它們以更低的價格提供這些接口。 FPGA行業依靠工藝技術擴展來滿足其中的許多要求。
自Dennard縮放結束以來,工藝技術的性能收益有限,無法達到功耗目標。每個工藝節點也提供了較少的密度改進。隨著復雜工藝變得越來越昂貴,每個新節點中晶體管數量的增長減慢。一些預測聲稱,每個晶體管的成本將上升。像整個半導體行業一樣,FPGA產業依靠技術擴展來提供改進的產品。如果改進不再來自技術擴展,那么它們從哪里來?
減緩工藝技術改進提高了新型FPGA電路和架構的可行性:回到發明階段。但是這并不像回到1990年那么簡單。這些改變必須在不降低FPGA的易用性的情況下進行。這個新階段給FPGA電路和應用工程師帶來了更大的負擔。
D.設計努力
注意最后一節的重點是設備屬性:成本,容量,速度和功耗。成本,容量和速度正是FPGA在20世紀80年代和90年代處于ASIC劣勢的那些屬性。然而他們興旺起來。對這些屬性的狹隘關注可能會被誤導,就像ASIC公司在20世紀90年代對它們的狹隘關注導致他們低估了FPGA。盡管存在缺點,但可編程性給了FPGA一個優勢。這種優勢轉化為風險更低,設計更簡單。這些屬性仍然有價值,但其他技術也提供可編程性。
設計工作和風險正在成為可編程邏輯中的關鍵要求。非常大的系統難以正確設計,需要設計師團隊。組裝復雜的計算或數據處理系統的問題促使客戶找到更簡單的解決方案。隨著設計成本和時間的增加,它們成為FPGA的一個問題,如ASIC在20世紀90年代的ASIC NRE成本。從本質上講,大的設計成本會破壞FPGA的價值主張。
就像30年前尋求定制集成電路的客戶被ASIC吸引到FPGA一樣,現在很多人都被多核處理器,圖形處理器(GPU)和軟件可編程應用特定標準產品(ASSP)所吸引。這些替代解決方案提供預先設計的系統軟件,以簡化到他們的映射問題。它們犧牲了易用性的可編程邏輯的一些靈活性,性能和功率效率。很明顯,雖然有許多FPGA用戶需要利用FPGA技術的極限,但是還有許多其他技術能力足夠的人,但是由于使用這種技術的復雜性而使他們感到害怕。
設備的復雜性和能力促使設計工具的能力增加。現代的FPGA工具集包括從C,Cuda和OpenCL到邏輯或嵌入式微處理器的高級綜合匯編。供應商提供的邏輯和處理功能庫支持設計成本。工作的操作系統和管理程序控制FPGA SoC操作。 FPGA設計系統內置了團隊設計功能,包括構建控制。一些功能是由供應商自己建立的,另一些則是不斷增長的FPGA生態系統的一部分。
顯然,可用性對于FPGA的下一個階段至關重要。這種可用性是通過更好的工具,更高級的建筑,工藝技術的開發還是固定塊的更多積累來實現的?最有可能的是,就像以前的每一個年齡都需要為每個年齡段做出貢獻一樣,所有的技巧都需要成功。還有更多。與其他階段一樣,FPGA的下一個階段將只是在回顧中才會完全清楚。在整個年齡,期望看到歷史悠久的好工程:從現有的技術生產出最好的產品。隨著現有技術和“最佳”定義的不斷變化,這一良好的工程將會完成。
十四、FPGA的未來
未來是什么?此后是什么階段?我拒絕推測,而是發出一個挑戰:記住Alan Kay的話:“預測未來的最好方法就是發明它。”
-
FPGA
+關注
關注
1620文章
21510瀏覽量
598978 -
摩爾定律
+關注
關注
4文章
630瀏覽量
78770 -
晶體管
+關注
關注
77文章
9502瀏覽量
136947
發布評論請先 登錄
相關推薦
可編程晶振都有什么頻率的呢?分享3個挑選可編程晶振的技巧

可編程電源使用方法
可編程電源如何編程
現場可編程門陣列的原理和應用
具有三個直流/直流降壓轉換器和四個LDO的用戶可編程電源管理IC TPS6521905數據表

具有三個直流/直流降壓轉換器和四個LDO的用戶可編程電源管理IC TPS6522005-EP數據表
現場可編程門陣列是什么
具有三個直流/直流降壓轉換器和四個LDO的用戶可編程電源管理IC TPS6522005-EP數據表
汽車類具有三個直流/直流降壓轉換器和四個LDO的用戶可編程電源管理 IC數據表
基于FPGA的可編程AES加解密IP






 工商網監
工商網監
評論