") 關(guān)于英特爾發(fā)力FPGA的相關(guān)事件分析
關(guān)于英特爾發(fā)力FPGA的相關(guān)事件分析
芯片巨頭英特爾已經(jīng)談?wù)?CPU-FPGA 復(fù)合計算很長時間了,以至于我們有時候不記得其 Xeon-Arria 混合計算單元并不是一款量產(chǎn)產(chǎn)品——這種計算單元是將一個 Xeon 服務(wù)器芯片和一個中端 FPGA 放入單個 Xeon 處理器插槽中。但英特爾正在努力攻堅這一領(lǐng)域,并且最近也向 The Next Platform 透露了當(dāng)前的規(guī)劃。
這種 CPU-FPGA 混合器件類似于 AMD 的加速計算單元(APU/Accelerated Computing Units),只是 APU 是將計算和 GPU 加速放入單個處理器封裝中。CPU-FPGA 混合器件有望得到廣泛的采用,尤其是想要將特定類型的負載從 CPU 遷移到加速器上的超大規(guī)模計算用戶和云計算開發(fā)商。
盡管英特爾有自家的 GPU 并且也已經(jīng)為特定的市場將其放入到了 CPU 封裝中或 CPU die 上(比如基于 Xeon E3 芯片的用于加速媒體處理的低端工作站和低端服務(wù)器),但英特爾在將 Xeon 處理器上的負載遷移到其它器件上的熱情并不高。它首先打造了并行 X86 處理器的 Knights 系列來作為輔助引擎,之后又將其做成了一款完整的處理器 “Knights Landing” Xeon Phi 7200,這款處理器在 2015 年底開始初步出貨,并在 2016 年夏季正式發(fā)布。英特爾已經(jīng)終結(jié)了 Knights Landing 芯片的協(xié)處理器版本,它們從未真正出貨,因為客戶只是需要使用可以運行他們自己的操作系統(tǒng)的 Xeon Phi 的托管版本。
也就是說,F(xiàn)PGA 和 GPU 一樣,只是一種遷移計算負載的模式;英特爾正在努力將各種各樣的 FPGA 配置帶進這一領(lǐng)域,以確保計算負載確實能以某種形式從 Xeon CPU 遷移到 Xeon Phi(可用于傳統(tǒng)的 HPC 和新興的人工智能負載,主要是用于神經(jīng)網(wǎng)絡(luò)訓(xùn)練)或 Altera FPGA 或之前提到的那些低端的 CPU-GPU 混合器件。英特爾肯定不希望英偉達的 Tesla GPU 加速器或 AMD 的 Epyc CPU 和 Radeon Instinct GPU 組合占領(lǐng)這些市場。
英特爾在與 FPGA 制造商 Altera 達成了代工合作協(xié)議之后就開始談?wù)?Xeon-FPGA 混合計算器件了,Altera 也是英特爾的第一個這樣的客戶。之后兩家合作一路深化,直到 2015 年 6 月,英特爾用 167 億美元收購了整個 Altera。在今年休假離開之前負責(zé)管理英特爾的數(shù)據(jù)中心組的 Diane Bryant 曾在 2014 年 6 月即興宣布了第一款 CPU-FPGA 器件,那是在英特爾收購 Altera 的一年之前。那時候,Bryant 說向這種計算復(fù)合體中加入 FPGA 可以提供多達 10 倍的加速,這可以通過使用 QuickPath Interconnect(QPI)鏈路直接將 FPGA 連接到 Xeon 處理器上實現(xiàn)。該鏈路通常用于多處理器系統(tǒng)中的 NUMA 擴展,相比于使用 PCI-Express 外設(shè)總線,它的性能可高出 20 倍。
英特爾最后真的收購了 Altera,這沒什么驚奇的。Altera 是 FPGA 領(lǐng)域的兩大主要玩家之一,另一家是賽靈思(Xilinx)。如果非要說有讓人驚訝的地方,那就是英特爾出的錢太多了,畢竟 Altera 的年收入還不到 20 億美元。英特爾和 Altera 的這筆交易也讓我們看到了英特爾的擔(dān)憂。這家公司將會使用 FPGA 來對抗 GPU,之后該公司還表示預(yù)計在 2020 年之前,三分之一的云開發(fā)商(也包括超大規(guī)模計算用戶)的系統(tǒng)中都會使用 FPGA。由于 FPGA 在一些負載上有 10 到 20 倍的性能優(yōu)勢,加上數(shù)量巨大,所以可能會給 Xeon 的銷量帶來巨大影響。(目前我們尚未看到這種效果,但想象一下如果用 CPU 來實現(xiàn)深度學(xué)習(xí)奇跡,得需要多少 CPU 和多高的成本。這方面的創(chuàng)新可能根本就沒有發(fā)生過。)
到目前為止,英特爾 Xeon 還在熱銷,即使 FPGA 和 GPU 等加速器正在侵蝕 Xeon 的業(yè)務(wù)。除了 SmartNIC 網(wǎng)絡(luò)接口和其它網(wǎng)絡(luò)功能虛擬化工作,F(xiàn)PGA 也已被用于執(zhí)行服務(wù)器加密以及加速關(guān)系數(shù)據(jù)庫,正如 Swarm64 做的那樣。在一些案例中,F(xiàn)PGA 卡有自己的內(nèi)存和計算,只將一些核心的串行任務(wù)交給 CPU 做,比如來自 Nallatech 的雙 FPGA 協(xié)處理器就是這樣。
順便一提,讓 FPGA 與處理器協(xié)同工作并不是什么新花樣。賽靈思和 Altera 都在同一個片上系統(tǒng)封裝中集成 FPGA 和 ARM 處理器很多年了,而且英特爾本來也可以在用于超大規(guī)模計算的 Xeon D X86 芯片設(shè)計上做同樣的事。事實上,這個本可以做到的事情后來造就了第二代測試臺 CPU-FPGA 混合器件,英特爾在 2016 年 3 月展示了這種器件。
英特爾可編程解決方案組的 FPGA 軟件解決方案高級總監(jiān)告訴 Bernhard Friebe 說,這種器件在同一個封裝中放入一個 15 核的 Broadwell Xeon 處理器和一個 Arria 10 FPGA,這不是 Stratix 10 一樣的頂級部件。該器件使用了英特爾的 14nm 工藝生產(chǎn),目前正在實驗性生產(chǎn),有望在今年年底前開始出貨。
英特爾采用的是雙管齊下的 FPGA 戰(zhàn)略:一是 CPU-FPGA 混合器件,比如共享同一個插槽的 Broadwell-Arria 封裝;二是分立的 Xeon CPU 與 Arria 或 Stratix FPGA 通過 PCI-Express 總線彼此相連。
據(jù) Friebe 說,英特爾的當(dāng)前計劃是基于 Arria 10-GX FPGA 打造自己的 PCI-Express 卡,英特爾將其稱為可編程加速卡(PAC/programmable acceleration card),并計劃在 2018 年上半年開始銷售。后面也會有基于 Stratix 10 FPGA 的 PAC,但英特爾沒說什么時候會有。我們估計大概在 2018 年年底。
英特爾的 CPU-FPGA 混合器件包含一款尚未命名的 “Skylake” Xeon SP 處理器加 Arria 10 FPGA 組合器件。這些 CPU-FPGA 混合器件將會在實驗性的 Broadwell-Arria 器件基礎(chǔ)上繼續(xù)前進,并會使用更快的 UltraPath Interconnect(UPI)鏈路在一個 Socket P 插槽中將 FPGA 直接連接到 Skylake 芯片。我們也知道這是一種單插槽機器,所以這可能意味著會有一個 bin 相對低的 Skylake 部件(也許是 Silver 或 Bronze),也可能只有一個 UPI 鏈路。(更多不一定更好。)
目前還不清楚這兩個計算元件之間的鏈路數(shù)量是 1 還是 2 還是 3,但是鑒于 Skylake 可以有 1、2 或 3 個 UPI 端口,根據(jù)模型的不同,這三者皆有可能。我們也不清楚英特爾打算在這兩個器件之間使用什么一致性模型,但很顯然這能讓 CPU 和 FPGA 可以讀寫同一個內(nèi)存并且無需在兩個器件傳遞數(shù)據(jù)——不管是直接傳遞還是使用虛擬尋址移動指針。如果英特爾選擇 CCIX、Gen-Z 或 OpenCAPI 這三種新興的協(xié)議,情況就會相當(dāng)有趣,因為這些協(xié)議在器件之間提供的一致性能使得內(nèi)存尋址對編程者而言不可見。我們應(yīng)該會看到。
我們可以確定地說英特爾正在專注研發(fā)編程環(huán)境,這樣不管 CPU 和 FPGA 是分立的還是混合在同一個插槽中,都能使用同樣的工具。英特爾將其稱為 Acceleration Stack,這是一個基于 OpenCL 的完備的編程環(huán)境。OpenCL 是一種常用的高級編程語言,可以與 Verilog 和 VHDL 配合用于 FPGA 開發(fā)。
這種用于 FPGA 的 Acceleration Stack 是專門為英特爾器件設(shè)計的。據(jù) Friebe 說,Acceleration Stack 組合了英特爾的系統(tǒng)與 FPGA 的固件與 Open Programmable Acceleration Engine(OPAE)開源框架。其中包含用于運行在裸機上的操作系統(tǒng)的實體 FPGA 驅(qū)動和一個虛擬 FPGA 驅(qū)動——這個虛擬 FPGA 驅(qū)動可以運行在服務(wù)器虛擬化管理程序之下,從而可在虛擬機上實現(xiàn)功能。
英特爾的想法是構(gòu)建一個一致的 API 集合,可通過 C 語言訪問,可以用于混合或分立的設(shè)置,并且像 OPAE 代碼一樣開源,在 GitHub 上放養(yǎng)。這個 FPGA API 使用了 BSD 許可,這個 FPGA 驅(qū)動使用了 GNU GPLv2 許可。有很多公司必須獲得許可的 OpenCL 工具,英特爾也有自己的,稱為 Intel FPGA for OpenCL,它可以進行各種優(yōu)化以便在 FPGA 上運行。
如果這些工具能吸收 C 語言代碼并將其轉(zhuǎn)換成 OpenCL 代碼,然后轉(zhuǎn)換成 VHDL,那么這可能會非常有用。我們預(yù)計,有了這個 OPAE 軟件層,這個堆棧中更高層的應(yīng)用框架就會與 OPAE 通信以便將負載遷移到 FPGA 上,這樣可以極大簡化編程任務(wù)。當(dāng)然,OpenCL 代碼也會被自動編譯成 FPGA 可用的 VHDL。
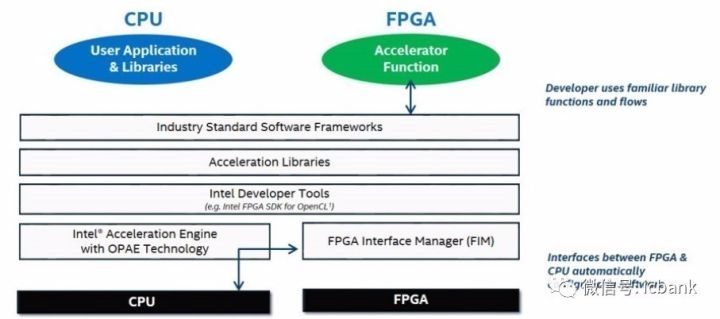
英特爾關(guān)注的核心是讓 FPGA 編程更簡單,同時也保持其兩大分支的一致性。FPGA 本質(zhì)上編程就更難一些。你怎么看待介于硬件和軟件中間的東西?
也許最有意思的地方在于英特爾非常堅定地要使用 FPGA 來加速機器學(xué)習(xí)負載,尤其是用于推理階段,而且它還將為此推出自己的預(yù)配置 FPGA 算法,其客戶可以像獲取軟件一樣獲得這些算法的許可。這也是大概兩年半之前出現(xiàn)關(guān)于英特爾收購 Altera 的傳言時我們所做過的預(yù)測。
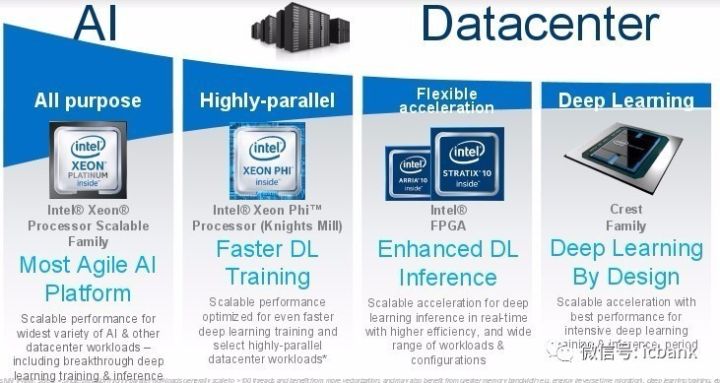
但英特爾在人工智能方面有很多不同的計劃齊頭并進,不知道他們的客戶會做何選擇。
我們一直疑惑的是該在什么時候使用混合設(shè)置,又該在什么時候使用分立的 CPU 和 FPGA 設(shè)置。混合器件的計算能力中規(guī)中矩,但卻有更高的內(nèi)存帶寬和更低的延遲;分立方法則可以組合更多 CPU 計算(使用 Xeon SP 的 2、4 或 8 插槽)和更多 FPGA 計算(可以加入多達 16 個 PCI-Express 卡,在服務(wù)器中有 8 個。FPGA 本身有大量不同的連接和 I/O 選擇,因為這也可以使用 VHDL 編程。
“根據(jù)你想做的事情的不同,有很多不同的使用模式。”Friebe 說,“集成解決方案主要用作旁路加速器。數(shù)據(jù)進入 CPU,然后它將任務(wù)分配給 FPGA,結(jié)果又返回 CPU,你就得到了加速。使用分立的卡時,你可以擴展到其它使用模式。比如,你可以在在線的或流傳輸?shù)哪J街惺褂眠@樣的 FPGA,其中數(shù)據(jù)可以經(jīng)由高帶寬接口直接輸入 FPGA;然后經(jīng)過 PCI-Express 鏈路,這些經(jīng)過 FPGA 加工過的數(shù)據(jù)可以被發(fā)送到 CPU 做進一步處理。”
也可能有一些場景需要在同一個系統(tǒng)中同時使用這兩種方法,畢竟過去發(fā)生過更奇怪的事情。
-
FPGA
+關(guān)注
關(guān)注
1626文章
21667瀏覽量
601838 -
英特爾
+關(guān)注
關(guān)注
60文章
9886瀏覽量
171502 -
人工智能
+關(guān)注
關(guān)注
1791文章
46858瀏覽量
237552
發(fā)布評論請先 登錄
相關(guān)推薦
英特爾股價分析,財報超出預(yù)期,英特爾股票該買入還是賣出?
剛剛!英特爾最新回應(yīng)
英特爾股票分析:英特爾的困境能否結(jié)束?
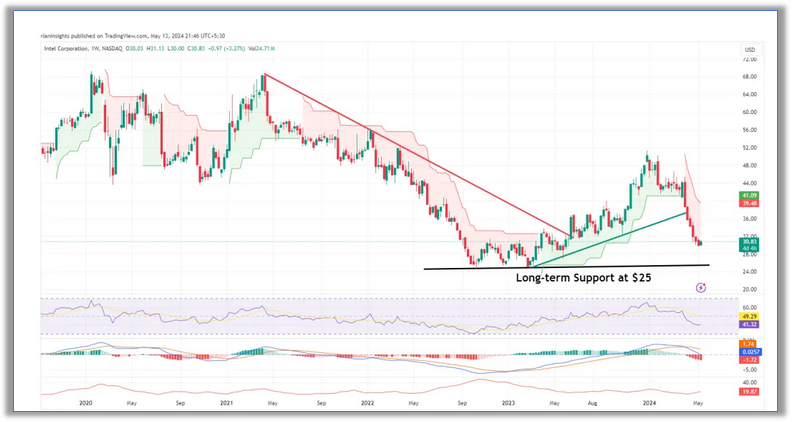
面對高通收購,Apollo 50億美元投資,你該買入英特爾股票嗎?
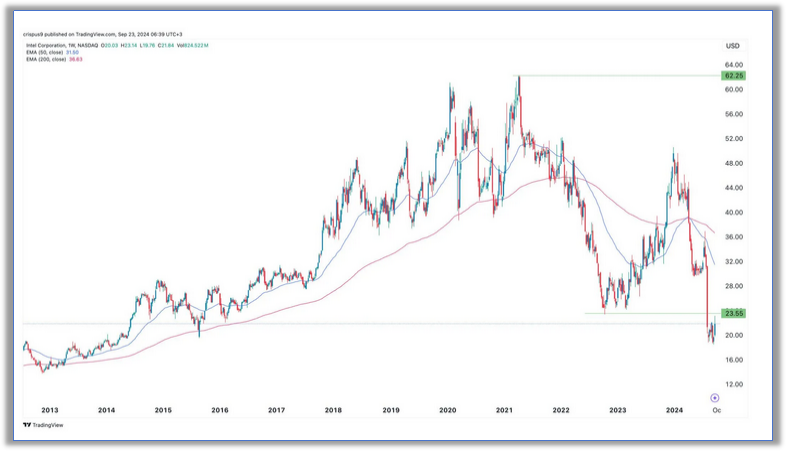
英特爾是如何實現(xiàn)玻璃基板的?
英特爾CEO:AI時代英特爾動力不減
BittWare提供基于英特爾Agilex? 7 FPGA最新加速板
英特爾旗下FPGA公司Altera正式亮相
英特爾成立全新獨立運營的FPGA公司Altera
英特爾旗下Altera正式獨立運作,FPGA市場將迎來怎樣的巨變?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論