 基于深度學習的推薦算法大部分都存在不同程度的數據集缺失和源碼缺失
基于深度學習的推薦算法大部分都存在不同程度的數據集缺失和源碼缺失
【導讀】來自意大利米蘭理工大學的 Maurizio 團隊近日發表了一篇極具批判性的文章,劍指推薦系統領域的其他數十篇論文,指出這些論文中基于深度學習的推薦算法大部分都存在不同程度的數據集缺失和源碼缺失,導致它們無法復現,而那些可復現的算法,其性能也難以達到預期,甚至難以超越基于傳統的、簡單的機器學習推薦算法。
推薦系統領域研究的潛在問題
近年來,基于深度學習的算法是非常熱門的研究方向,其在許多領域,如計算機視覺,自然語言處理等領域都取得了巨大的成功,因此許多研究人員也期待能借助深度學習方法在推薦系統領域取得突出的進展,例如基于長期依賴配置和基于場景的 top-n 推薦算法。近年來也有許多基于深度學習的推薦算法發表在知名會議和期刊上,然而過去有工作指出這些深度學習推薦算法并不是完全可信的,主要存在以下三個問題:
許多聲稱有提升的方法事實上并不能超越經過合理調參的基準對比工作,甚至不能超越很簡單的傳統方法。具體來說,這些方法在實驗上存在一定的缺陷。
基準對比工作的選擇問題:許多方法選擇的對比工作本身就有問題,不是廣義上的基準工作。并且該領域的基準工作很混亂,不太統一。
不同工作采用的數據集,驗證方法,性能指標,數據預處理步驟都不同,這使得性能對比很困難,無法確定哪個工作在相同的應用環境中表現最好。而且很多工作不開源數據和代碼,這不符合現在的代碼開源趨勢,甚至即使開源了,也不把完整代碼放出來。
系統的算法評估標準
為了深入探究基于深度學習的推薦算法是否存在以上問題,作者制定了兩個算法評估標準:
可復現性:能否通過代碼和數據集重現文中的實驗結果
性能評估:這些工作和基準工作相比能提高多少
在此標準的基礎上,作者評估了近幾年發表在頂尖會議上,運用深度學習方法來實現 top-n 推薦的 18 篇工作,最后發現:只有七篇工作是可復現的;而這 7 篇工作中,有 6 篇都沒能超越傳統的、經過合理調參的啟發式方法。即使是簡單地將最流行的items推薦給每個用戶(TopPopular),也能在特定的性能指標衡量下超越深度學習方法達到最優。
文章可復現性判斷
(一)調研文章范圍
作者收集了2015年到2018年 KDD、SIGIR、WWW 和 RecSys 會議上的研究工作,這些論文都是采用基于深度學習的方法來解決top-n分類問題的。在此基礎上,只考慮與精度評估有關的工作,因此最終篩選出了18篇文章。
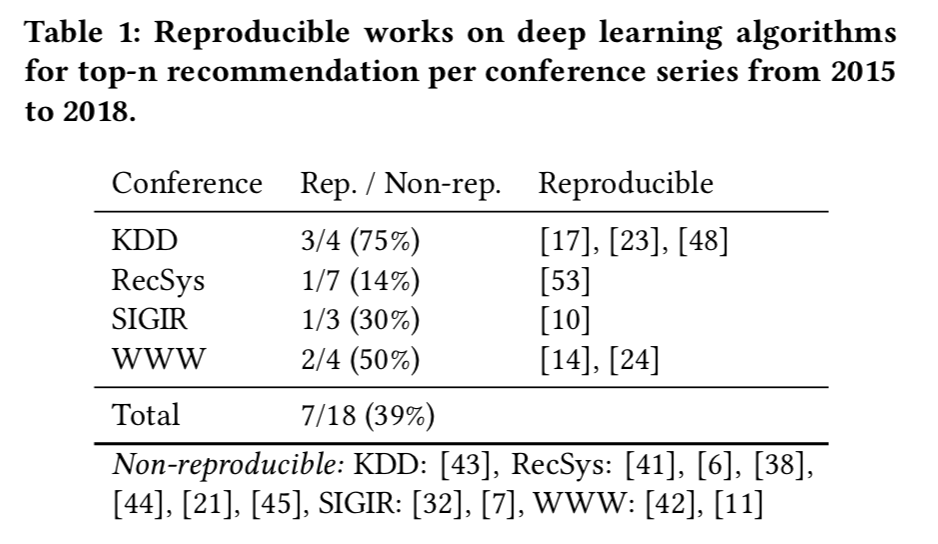
(二)可復現性的數據和代碼標準
首先,盡量通過文章原作者提供的源碼和數據來復現結果。由于有太多的實現細節以及驗證程序需要考慮,想要單純的依靠作者提供的資源來重現文中的結果是很難的。為了解決這個問題,作者擴大了代碼和數據的搜索范圍,只要是和原文章有關的代碼,即便不是官方代碼也考慮在內,如果實在找不到現成的實現代碼和數據,就聯系原文作者并等待30天。在進行了以上步驟后,將同時滿足以下兩個條件的文章定性為可復現文章,具體的:
1、有源代碼,并且源代碼只需要微小的細節改動(例如調整路徑,調整工作環境)就能正確運行。如果只是有一個代碼框架,而缺少許多細節,是不滿足這個要求的。
2、至少有一個文中用到的數據集是可以獲得并使用的(某些文章用的數據集是自建數據集或者不是公開數據集,對于作者而言很難獲取)。而且訓練集和驗證集的劃分方法也是在文中或者源碼中進行明確闡述的。
最終,18篇文章中只有 7 篇滿足以上條件,具備可復現性。作者還表示:“這是一個驚人的結果,如果深入追究可能會涉及到學術造假問題,就不貼那些結果不能復現的文章編號了”。
可復現工作的性能評估
在挑選出 7 篇可復現的工作后,作者進一步的評估了它們的性能。為了保證不同方法之間的可對比性,本文介紹了兩種評估策略。第一種評估策略是將所用的方法和基準方法在同樣的測試流程和測試集上進行評估,這有助于橫向對比不同的方法在同一數據集上的性能差異,雖然這種策略在之前的類似文章中已經用過,但會導致驗證方法和每個方法的原始文章中采用的方法有一定的差距,因此不能完全反應原始方法的性能(不完全復現)。
為了解決這個問題,作者提出將超參調優過程和測試過程分開進行,保證所有的方法(包括基準)方法都使用相同的測試代碼,但是允許它們有不同的調參過程,這樣每種方法都可以按照原文中提出的調參策略在自己的數據集上,即保證完全復現了原文方法,又保證不同方法之間具有可對比性。
基準方法的選擇
所有的基準方法都是簡單的非神經網絡,啟發式算法,或者說基于傳統機器學習和統計學的方法。選擇簡單的非深度學習方法作為基準方法,通過和基于深度學習的方法進行對比,以驗證模型復雜度的提升能否帶來性能上的顯著提升,作者得到的結論是不能。一方面是因為該領域的研究過于跟風使用深度學習方法,沒有細致嚴謹地去研究問題的本質,另一方面也是因為神經網絡本身沒有那么強大(現在有許多工作都是對神經網絡的真實能力提出了質疑),當然,學術上的不嚴謹也是一個重要原因(可能存在的造假行為)。
本文主要采用了如下幾種基準方法:
TopPopular:直接統計“最流行”的items(物品,項目)并推薦給每個用戶,這里的“最流行”可以用不同的指標來衡量。
ItemKNN:基于K最近鄰算法的一種推薦算法,衡量指標是物品之間的距離,因此是基于相似物品的推薦算法。首先通過TF-IDF或BM25算法獲取每個物品對每個用戶的隱式評分(評價向量,rating vector,可以簡單理解為該用戶對該物品的需求程度),然后按照以下公式計算兩個物品之間的距離:
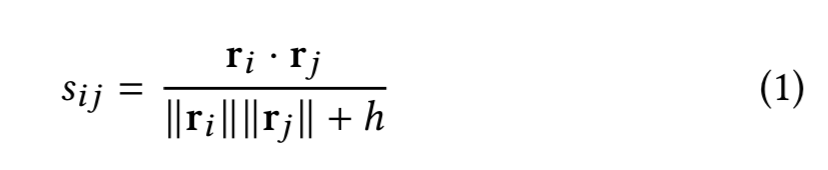
UserKNN:基于相似用戶的推薦算法,類似于ItemKNN,只不過計算樣本點變成了每個用戶自身的評級。
ItemKNN-CBF:基于內容過濾的相似物品推薦算法,CBF表示content-based-filtering,在標準ItemKNN的基礎上,將物品自己的特征向量作為距離衡量向量。
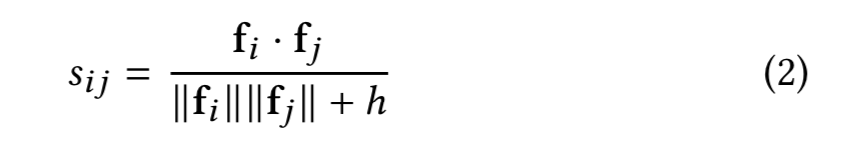
ItemKNN-CFCBF:將每個物品的排名向量和特征向量結合,這樣每個物品就由兩個向量表示,通過計算兩個物品的向量之間的余弦夾角來衡量相似度。
 ??:基于隨機游走的方法,從用戶 u 游走到物品 i 的概率為:
??:基于隨機游走的方法,從用戶 u 游走到物品 i 的概率為:
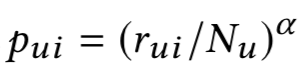
是物品 i 對用戶 u 的評級向量,是用戶 u 的評級,α 是阻尼因子。同理,從商品 i 游走到用戶 u 的概率為:
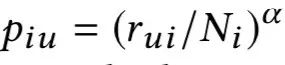
其中是商品 i 的評級。最后,兩個商品 i,j 的相似度計算公式為:

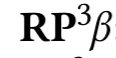 ? 是?
? 是?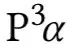 另一個版本,將?
另一個版本,將? 輸出的相似度進一步地按系數 β 擴張,所有基準方法都采用貝葉斯搜索來獲取最優參數。
輸出的相似度進一步地按系數 β 擴張,所有基準方法都采用貝葉斯搜索來獲取最優參數。
算法性能測試與對比結果
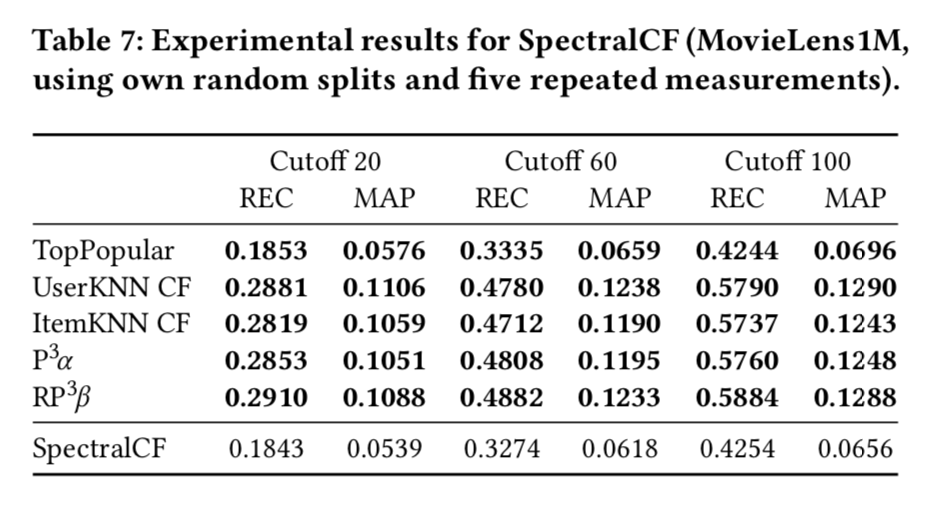
通過將可復現的 7 個方法與基準方法在相同數據集上進行測試,可以評估這些可復現方法的真實性能。這里主要評估之前挑選的7中可復現方法,其中只有Collaborative Variational Autoencoder(CVAE)能在同等訓練條件下超越傳統方法,其他算法都不如同等測試條件下的傳統方法。
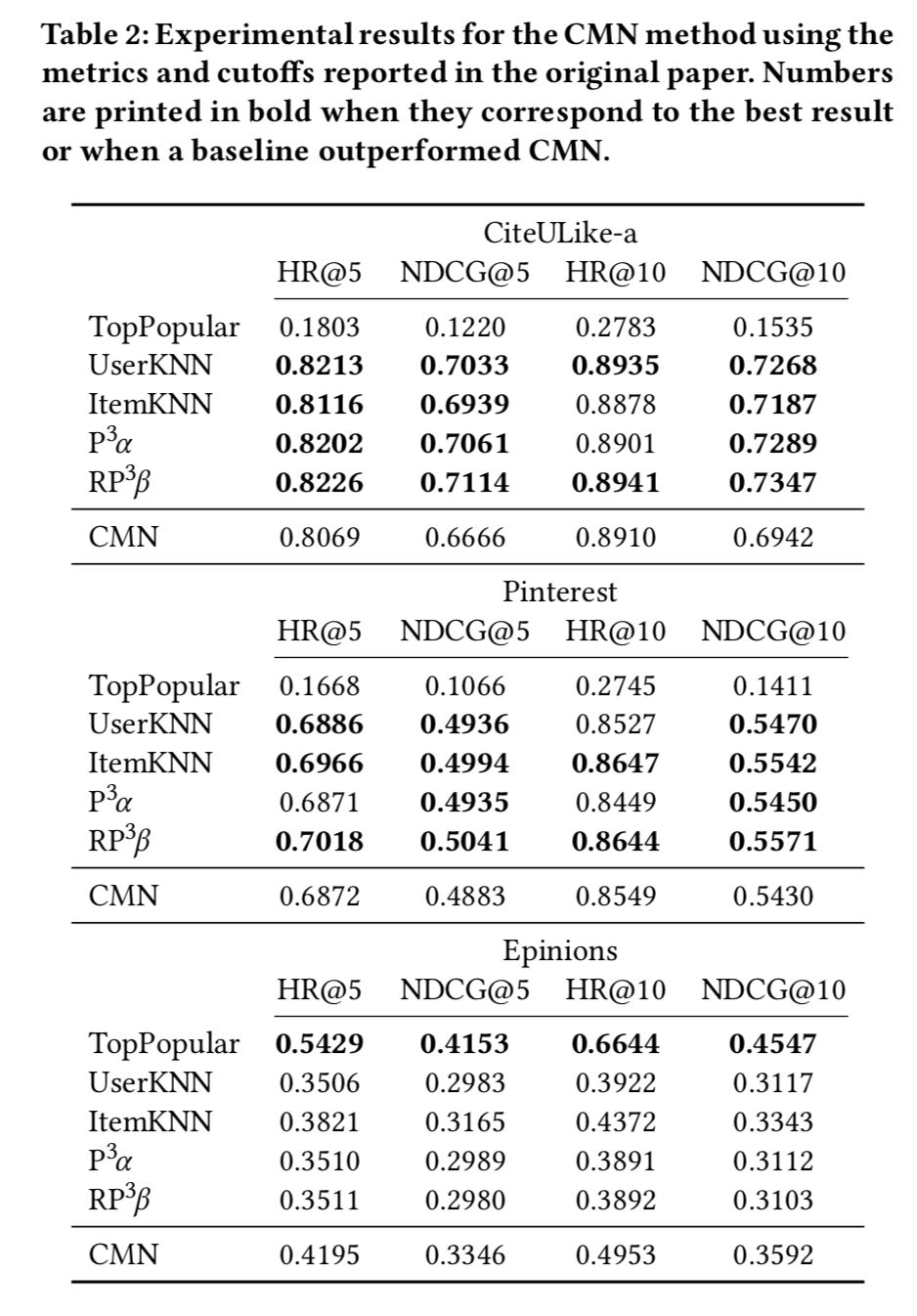
CMN方法的實驗結果
MCRec方法的實驗結果

CVAE實驗結果
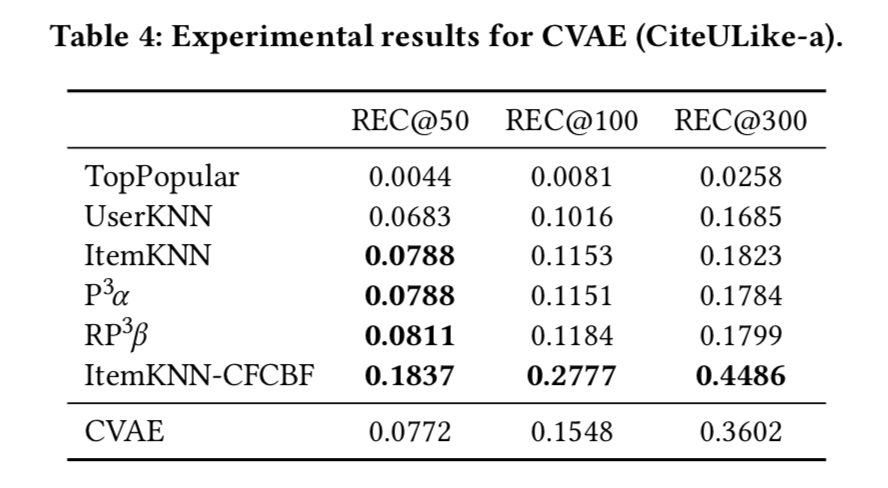
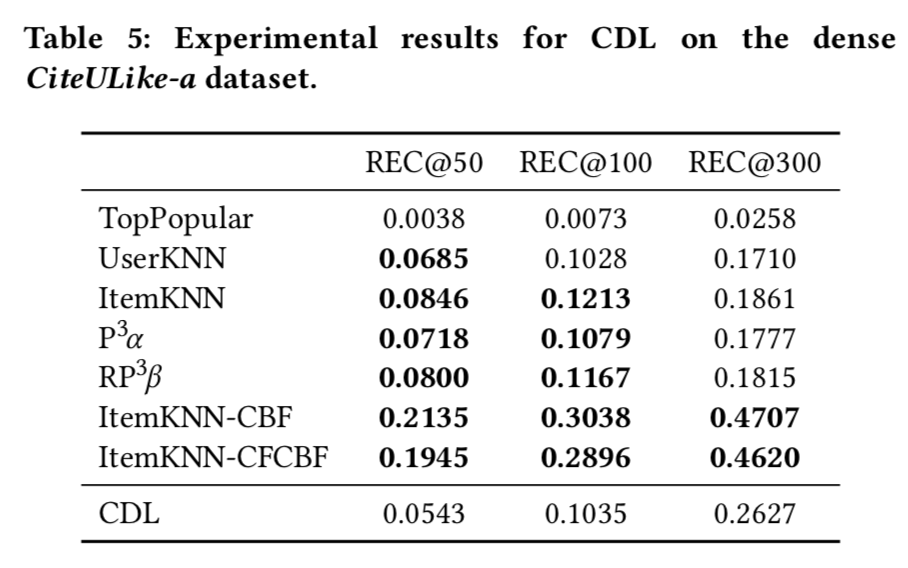
CDL實驗結果
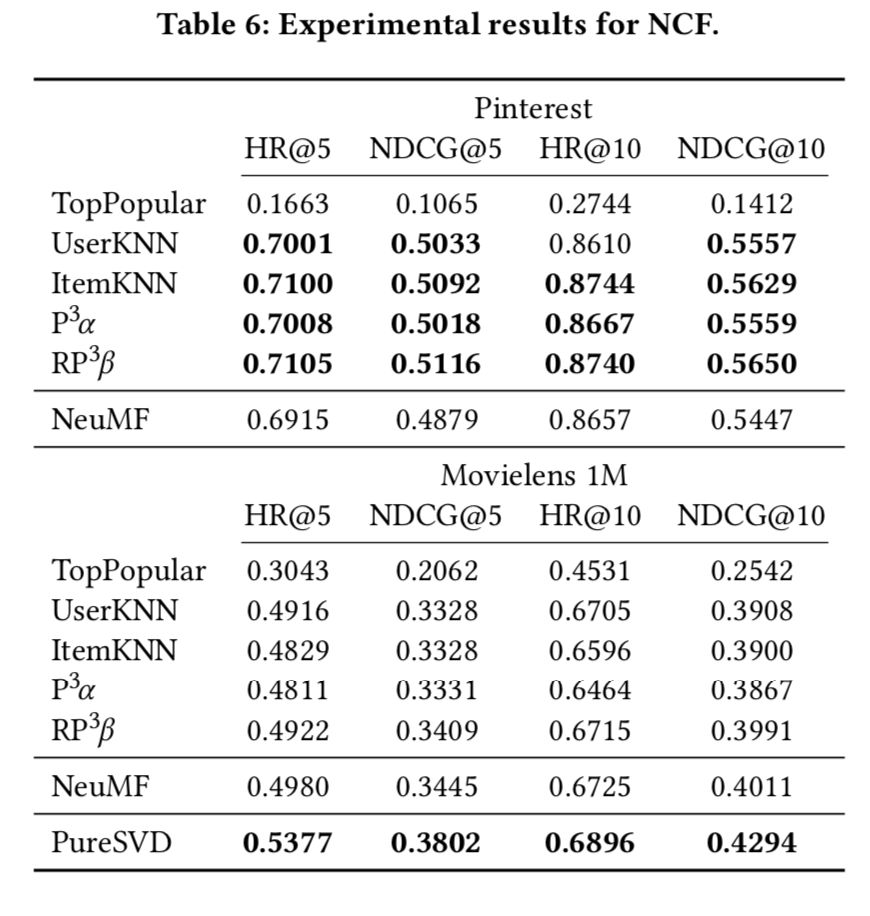
NCF 實驗結果
SpectralCF 實驗結果
結論
本文主要關注近年來發表在熱門會議上的基于深度學習的 top-n 推薦算法,聚焦于它們的可復現性和真實性能。結果表明大部分算法都無法重現理想結果,甚至無法超越傳統的啟發式算法,這說明推薦算法領域的研究和審核需要更加嚴謹和仔細,算法的性能評估需要更加標準,正確的方法。文中提到的那些無法復現和效果低于預期的工作肯定會被重新審核,甚至退回。
-
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977 -
自然語言處理
+關注
關注
1文章
612瀏覽量
13504
原文標題:數十篇推薦系統論文被批無法復現:源碼、數據集均缺失,性能難達預期
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電壓缺失
處理數據缺失的結構化解決辦法
能見度與缺失分析的改進PageRank算法

無線傳感網絡缺失值估計方法
基于距離最大化和缺失數據聚類的填充算法
基于加性噪聲的缺失數據因果推斷
外媒:iOS14.3仍存在SMS短信和消息通知缺失問題

基于張量的車輛交通數據缺失估計方法
缺失值處理你確定你真的會了嗎






 工商網監
工商網監
評論