 研究人員們提出了PBA的方法來獲取更為有效的數據增強策略
研究人員們提出了PBA的方法來獲取更為有效的數據增強策略
近年來深度學習模型的飛速發展離不開龐大的數據體量和多樣化的數據收集。收集大量的、豐富的數據是十分耗時耗力的工作,而數據增強則為研究人員們提供了另一種增加數據多樣性的可能,無需真正收集數據即可得到較為豐富多樣的訓練數據。來自伯克利的研究人員們提出了PBA(Population Based Augmentation)的方法來獲取更為有效的數據增強策略,并在實現同樣效果下實現了1000x的加速。
數據增強
數據增強策略通常包括剪切、填充、翻轉和旋轉等,但這些基本策略對于深度網絡的訓練還是太簡單,在對于數據增強策略和種類的研究相較于神經網絡的研究還是太少了。
一些常見的數據增強方法
最近谷歌針對這方面進行了深入的探索性的研究,提出了AutoAugment方法并在CIFAR-10數據集上取得了很好的成果。
這篇論文利用了強化學習等方法來搜索更好的數據增強策略,基于RNN的控制器從搜索空間中預測增強策略,而一個固定架構的子網絡則用于在增強的數據上進行訓練收斂到精度R,最后利用精度R來作為獎勵使得控制器尋求更好的數據增強策略。
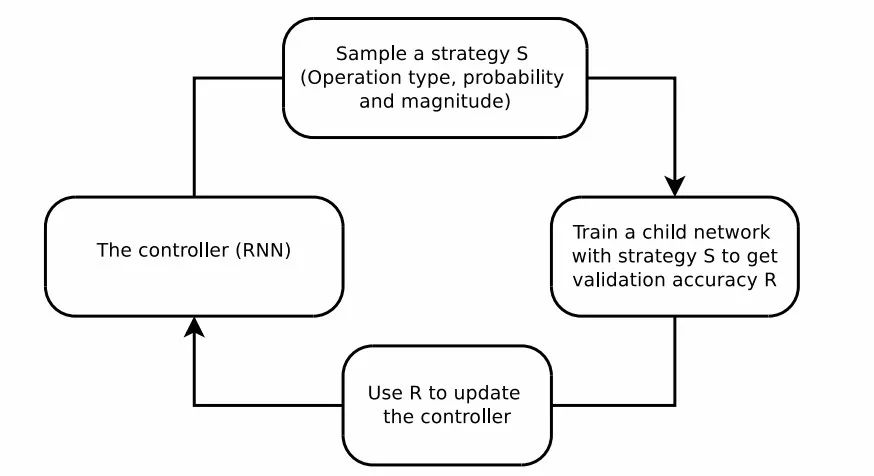
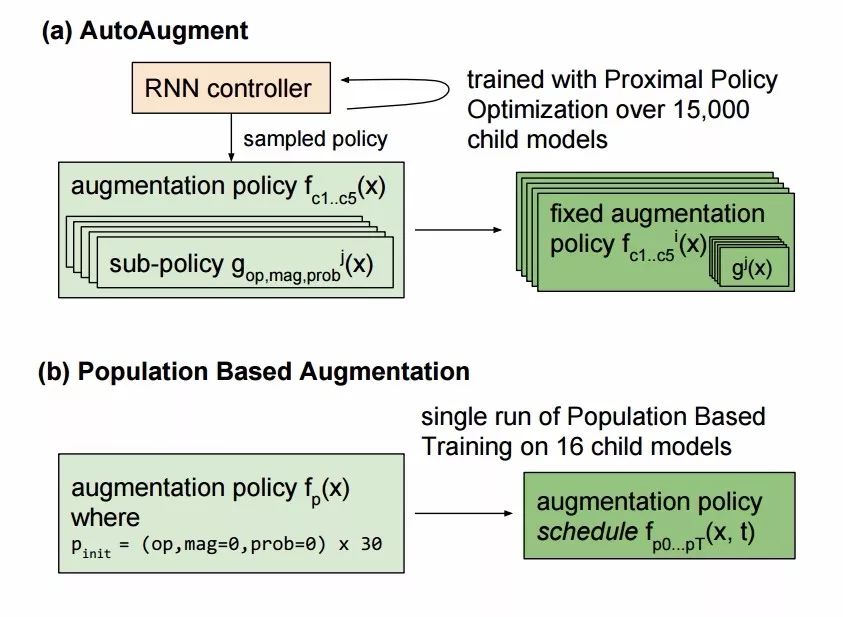
AutoAugment引入了16種幾何、色彩變換并從中選擇兩種以固定的幅度來對每一批數據進行增強,所以高性能的增強方法可以通過強化學習直接由模型從數據中學習到。但這種方法的弊端在于它需要訓練一萬五千個模型到收斂,以便為強化學習模型收集足夠的樣本來學習數據增強策略。在樣本間的計算不能共享,使得它要耗費15000個P100計算時來在ImageNet上實現較好的效果,即使在較小的CIFAR-10上也要消耗5000個GPU時(這意味著需要7500-37500美元的訓練費用才能得到較好的數據增強策略)。如果可以將先前訓練的策略遷移或共享到新的訓練中去,就能更高效地實現數據增強策略的搜索與獲取。
PBA算法
為了提高算法的效率,來自伯克利的研究人員提出了PBA算法,可以在比原算法少三個數量級的計算上獲得相同的測試精度。
與AutoAugment不同,這種方法在多個小模型的副本上訓練CIFAR-10數據集,只需要在Titan XP上訓練5小時即可得到較好的數據增強策略,這一策略應用到CIFAR-100,并重新訓練一個較大的網絡可以獲得十分有效的效果。與先前需要很多天的訓練相比,這種方法耗時更短且得到的效果更好。
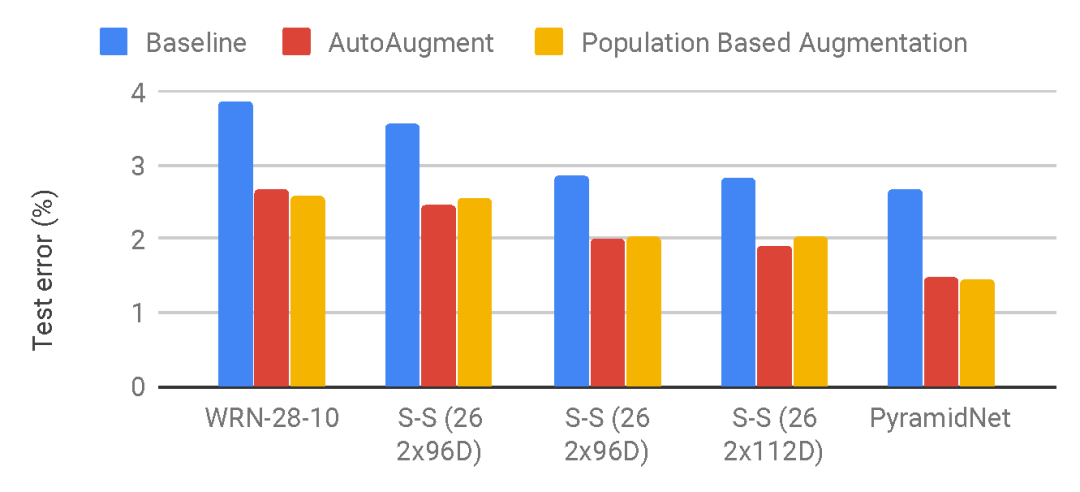
與AutoAugment相比,新方法給出的數據增強策略在不同模型上的表現。
研究人員從DeepMind的Population Based Training算法中借鑒了一些思想,并將其應用在了數據增強策略的生成上,將訓練中當前的結果作為生成策略的基礎,使得訓練的結果可以在不同子模型中共享,避免耗時的重復訓練。
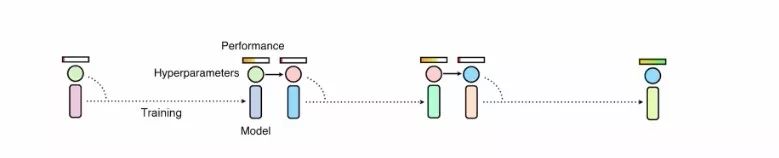
這一改進使得通常的工作站也可以訓練大型的數據增強策略算法。與AutoAugment不同,這一方法生成了一個策略調度方法而不是一個固定的策略。這意味著,在某個訓練周期,PBA生成的數據增強策略是法f(x,t),其中x是輸入圖像,t為當前的訓練周期。而AutoAugment則會在不同的子模型上生成固定的策略fi(x)。
研究人員利用了16個小的WideResNet,每一個會學習出不同的超參數計劃,而其中表現最好的調度將會被用于訓練大型的模型,并從中得出最后的測試錯誤率。
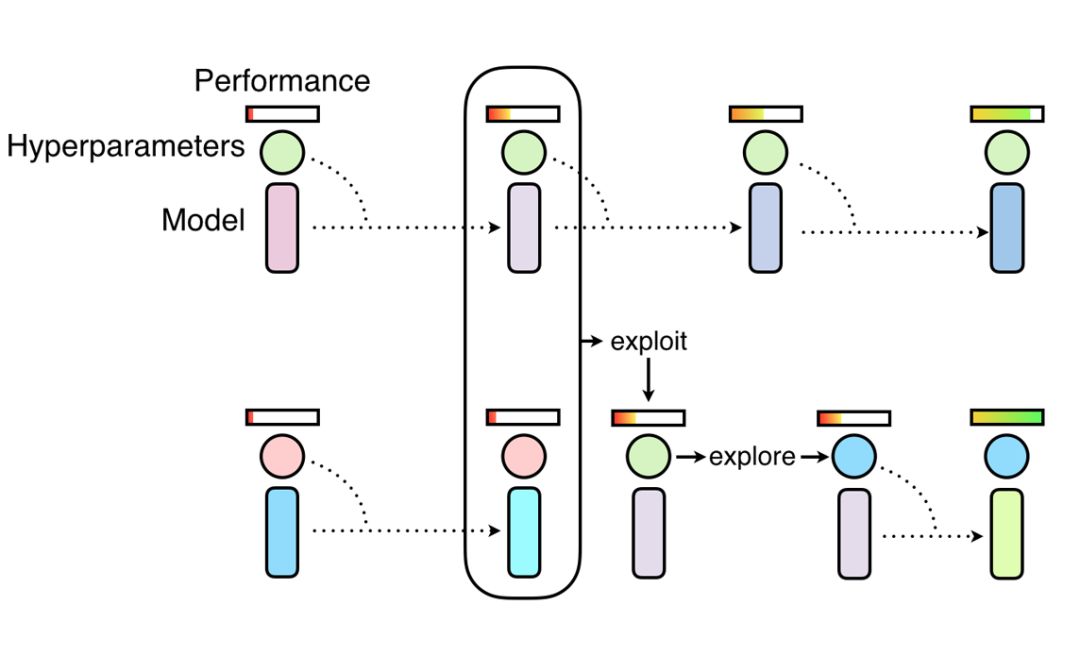
Population Based Training方法,首先將一系列小模型用于發現超參數,而后將表現最好的模型權重(exploit)與隨機搜索結合起來(explore)。這些小模型首先在目標數據集上從零開始訓練,隨后通過將高性能的超參數復制到表現欠佳的模型上實現訓練過程的復用,而后利用超參數的擾動來實現隨機探索,以獲取更好的表現。
通過這樣的方法,研究人員得以共享不同模型間的計算,并共享不同訓練階段得到的不同的目標超參數。PBA算法通過這一手段避免了需要訓練上千個模型才能獲得高性能數據增強策略的冗長過程。下圖顯示了研究人員獲取的數據增強策略:
研究人員還提供了源碼和使用實例,如果想要給自己的數據集學習出合適的數據增強策略,可以在TUNE框架下進行,只需要簡單的定義新的數據加載器即可使用。詳情請參考代碼:
https://github.com/arcelien/pba
-
控制器
+關注
關注
112文章
16214瀏覽量
177481 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
原文標題:1000倍提速!伯克利提出新的數據增強策略訓練方法,更好更快擴充數據
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
安全研究人員用短信遙控開車門
研究人員提出了“Skim-RNN”的概念,用很少的時間進行快速閱讀
Google研究人員開發增強現實顯微鏡檢測癌細胞
斯坦福提出基于目標的策略強化學習方法——SOORL

一種新方法來檢測這些被操縱的換臉視頻的“跡象”
一種新型獲取太陽能以及如氫氣類的清潔燃料的方法
研究人員們提出了一系列新的點云處理模塊

JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
研究人員提出了一種多尺度高效率的新模型FAMED-Net

Facebook的研究人員提出了Mesh R-CNN模型

研究人員推出了一種新的基于深度學習的策略
馬來西亞研究人員提出一種評估光伏模塊不同冷卻系統有效性的新方法
研究人員找到了一種更好的方法來冷卻 GaN 器件





 工商網監
工商網監
評論