 記錄啟發式對話中的知識管理
記錄啟發式對話中的知識管理
【導讀】自然語言對話系統正在覆蓋越來越多的生活和服務場景,同時,自然語言對話的理解能力和對精細知識的對話召回率在技術上仍有很大挑戰。
啟發式對話通過建立知識點之間的話題關聯,使對話系統能夠主動發現相關知識,充分發揮知識的協同作用,引導對話過程,把知識在合適的時間主動送達用戶。知識不只是以知識圖譜或問答庫等形式被動被搜索,啟發式對話中的知識結合了先驗經驗和用戶對話習慣,從而擁有知識角色,讓對話理解和對話流程更加自然,也更有用戶價值。
在本期公開課課程中,AI 科技大本營邀請到了思必馳 北京研發院NLP 部門負責人葛付江針對“啟發式對話中的知識管理”做系統的講解和梳理。
以下內容為大本營公開課整理。
今天給大家分享一下,關于啟發式對話中的知識管理系統,分享的內容包括以下五個方面:
▌對話系統的架構
首先是對話系統的架構,我們來看一下對話系統流程。
在一般的對話系統應用場景,比如在智能音箱、智能電視,包括現在車載的設備等,當用戶說了一個問句,智能客服自動的問答和對話,這樣的系統的基本流程是它接收到用戶的一個問句或者用戶說的一句話,然后系統里做一些處理,給用戶一個答復。
我們今天說的對話系統和傳統的問答系統有一個重要的區別,對話系統它是維護上下文的,在做一個對話的時候是有上下文場景,在這個上下文的過程中需要控制一些對話的狀態,來完整地理解用戶的意圖。
例如,用戶問一句明天會下雨嗎?系統會做一些預處理,即一些自然語言處理上的特征處理,比如分詞、詞性標注、命名實體識別這樣的模塊,在這里可以識別到一些實體,比如里邊的時間是明天,關于天氣現象是下雨,這是命名實體可以做到的。
經過特征的預處理以及命名實體的識別,然后進入正式的對于這句話的理解。首先是對于用戶的每一個問句需要做一個領域的判斷,一般做這個領域判斷是因為在對話系統里會支持各種場景,首先把用戶的這句話限定在一個固定的場景下,然后才能做相應的后續處理。
領域的判斷一般情況下有各種方式,不管是寫模板,還是一些分類的算法,比如這句話我們送到一個分類器里,它可能能判斷出它是一個天氣領域相關的。在這里邊,通過 Slot Filling,它就可以得到天氣領域的一個意圖,這個意圖領域是天氣領域,有它的地點和時間。當然這句話沒有提到地點,因為一般這樣的系統會通過傳感器或者是定位的信息,或者是 IP,或者各種設備相關的場景的信息獲取到他一個默認的地點或者默認的城市,根據這些信息,然后我們得到一個結構化的意圖。
這個結構化的意圖,然后送給一個對話管理或者對話狀態追蹤的模塊,這個對話狀態的管理去做一個判斷,說以當前這個領域,比如天氣這個領域它的 Slot 是否是滿足的。對于天氣這個領域比較簡單,發現這句話實際上它的領域意圖、時間、地點都已經滿足了,然后把這些槽位都補充上。
根據這些補充好的信息,實際上它就是一個結構化的信息,根據它的時間、地點、天氣現象,然后去后臺的數據服務里做一個查找,把真正的天氣,比如明天需要下雨或者是晴天這樣一個信息取出來,然后經過一個答案生成,Response Generation 這樣一個模塊,然后生成一句比較自然的話,比如說明天可能是一個晴天,然后就說明天是一個晴天,如果再說得更自然一點,可能說是一個出游的好時間,類似這樣的,整個流程大概是這樣,實際上是一個比較簡單的過程。
通過這個流程我想跟大家分享一下對話系統的基本架構,首先它要處理一個用戶的 Query,然后它要經過一個對話管理的模塊,這個對話管理實際上就是維護上下文的信息。再下面是一個意圖的理解,這個意圖的理解可能有各種方式,包括知識庫或者叫知識圖譜,包括問答的形式,這種問句相似度匹配,還有一些通用的各種其他的意圖的理解,包括意圖分類的這些東西。
在這個里邊,對話管理在這個里邊,一般情況下對話管理實際上是一個類似于流程圖的東西,比如以剛才天氣的里邊,它實際上是一種叫 Slot Filling,有幾個信息填滿之后就可以了。然后在一些其他的對話過程中,比如說典型的客服,實際上一般在客服的具體場景下,比如金融領域的某一種金融業務或者是用戶查詢一種金融產品,比如保險這種產品,某一種保險產品,它有一些信息,它實際上是一個流程圖的形式。
還有一種是我們后面會提到的啟發式的對話,這幾種形式的結合,其實是一個對話的管理。現在一般的系統可能都是處理某一種對話,要么就是 Slot Filling,要么就是一個設定好的流程,要么是一種啟發式,能把它做到融合的可能還不是特別多。
繼續在這個圖里邊,剛才提到對話管理就是 DM,對話的理解就是知識庫,問答對,還有一些通用的,比如說抱怨,一種通用的狀態,一般情況下可能是一種分類的方式來做的這種 NLU 的理解之后,各個模塊做到這個 NLU 之后,它需要去做一個抉擇,因為在各種系統里邊,用戶的一句話可能都會找到一個答案,我們到底選哪一個答案,所以就做一個排序,排序完之后經過一個答案的生成,最后給用戶一個答復。
當然這里邊,邊上還有一個模塊就是上下文的管理,它在對話管理、NLU 以及排序和答案生成這些模塊里都會用多,它會維護一些上下文的信息。當然這張圖結構是比較簡單的,但是每一個里邊實際上有挺多東西,我們后面看具體的內容,最后我們回過頭再來看這張圖,可能就會有一些不一樣的東西。
看之前我們先總結一下現在一些對話機器人的現狀,一般對話機器人怎么來評價或者它現在的狀態,一般評價的標準,我們對機器人的評價是不太好評價的,我們做一個系統或者做一個學術的研究,一般情況下它怎么來衡量這個機器人的效果,實際上是一個很重要的事,我們要做這個事前需要先定一個標準。

一般的像對話系統主要的幾種評價的東西,一個是準確率,準確率可能就是基于一些問答對還是不對,或者對話答的對還是不對,比如這個對話進行了十輪,這十輪里有幾次對的,幾次錯的,直接給一個零一的判斷,然后算出準確率。
另外一個,人工打分,因為這個對話過程中它可能并不是一個絕對的零一的判斷,有的時候它給的答案可能不那么合理,但是一定程度上能夠接受,所以人一般可以給它打一個分數,比如說 1 到 10 分或者 1 到 5 分,給一個分數,最后給這個機器人一個綜合的打分。
學術上可能借鑒一些其他系統的標準,比如說困惑度或者 BLEU 值這樣的方式來給一些打分,一般這種標準更多是在一個限定的數據集里去衡量這句話,生成的這句答復它的語言流暢程度,可能更多的是從語言流暢程度的角度來衡量,當然這些困惑度或者BLEU值,它的好處是能自動地來判斷,但是壞處是它其實很難嚴格地從語意上來判斷這個系統好或壞。
在一些極窄的領域里,比如說訂餐,甚至更窄一點,比如訂一個披薩或者訂咖啡,或者撥打電話,這種很窄的領域,實際上現在機器學習的方法和模板的方法都能夠做到一個比較好的精度。
機器學習或者深度學習,但是深度學習在這種場景下它也依賴于一個比較大的數據量,相對于這個場景來說,因為一般在這種實驗上,它的場景還是比較小的。如果場景比較多的話,現在在一個比較復雜的場景里,可能現在深度學習的效果還不是很好,就是在多輪對話的場景下,并且有多個場景混合的話。
另外在一些較大的領域,比如客服,客服這個場景,它一般情況下對于一個企業的客服,一個企業的客服可能會涉及到幾種產品,既使是一類產品也會涉及到這一類產品不同的產品線以及它各種型號這些東西,客服它相對來說是一個比較寬的領域。
現在不管是深度學習,還是其他傳統的機器學習,如果在整體都用深度學習的方式,它的準確率是比較低的,很少能做到 50% 以上的,就是在一個比較大的領域里。所以現在在客服領域里,很多系統是基于檢索式或者是基于模板的,檢索式就是它準備好了一些標準的問答對,因為企業做自己的客服的時候,一般情況下積累了一些它自己對自己產品的標準問題和答案的,用戶的一個問題就到這里找一個最相似的問題,然后給它一個答案。這種方式目前是用得比較多的。
另外一種就是模板,人工去寫一些規則的模板或者叫語義的模板,然后去解釋用戶的這個問句包含哪些主要的信息,然后把它對到一個意圖上給一個答案,在這些領域里邊,較大的領域實際上機器學習的算法還是有一些挑戰的,即使用模板它也有很多的挑戰,因為模板多了之后它就會有沖突以及不好維護的問題。
▌啟發式對話系統
啟發式對話系統,是我們正在做的一個啟發式對話系統,啟發式對話系統現在有一些相似的概念,比如說主動式對話,思必馳提出來這個啟發式對話可能主要是在這樣,在一些企業的場景下很多時候用戶實際上是面對一個對話機器人,他不太清楚能問什么樣的問題,以及這個機器人的能力是什么樣,它能回答什么樣的問題,或者用戶大概知道他要什么東西,但是他對于問問題這個事,讓他去問很多問題還是要費一點腦筋的。
啟發式對話大概就是這么一個流程。它實際上通過這些問題背后的一些聯系,能讓這個對話一直持續下去。當然你說你不想了解然后它就結束了。這是一個基本的概念。
我們來看一下啟發式對話有哪些基本的特點,首先根據用戶的問題主動引導對話交互,用戶問了一個問題,系統會根據這個問題把一些相關的問題列出來或者問用戶他想不想了解。用戶的問題是以多種形式連接到知識點,當然這個對話后面,我們叫知識點,以一個知識點的方式,連接一個知識點可能就是對于一個具體的問題,這個問題可能有各種不同的問法,我們都認為它是一個知識點。
以多種形式指的是現在常見的形式,它可能是一個問答對的形式,在這個對話系統后面可能是一個問答對的形式,也可能是一個知識圖譜的形式來存在的,但是它們的連接是統一的,都是以一種知識點來管理它們。

知識點如果直觀地理解,我們可以認為它就是問答對或者知識圖譜里面的一個實體相關的屬性這樣的東西,這些知識點之間或者問題之間,它通過話題來融合,話題實際上對用戶是一個不可見的概念,它是為了去做推薦,因為我們把問題通過話題做一個連接之后,后面這個啟發式對話實際上是根據話題來做一些選擇,用戶問了一個問題,我們把這個問題所在的知識點,這個知識點它所在的話題,根據這個話題去找到一些相關的話題,然后在那些話題下面找到一些對應的問題,然后推薦給用戶。
話題之間有一些語義或者邏輯關系的,后面會具體講這些話題之間是怎么組織的。整個對話過程可能就是根據話題來做整體的規劃以及跳轉的。這是現在整個啟發式對話它的一些特點。
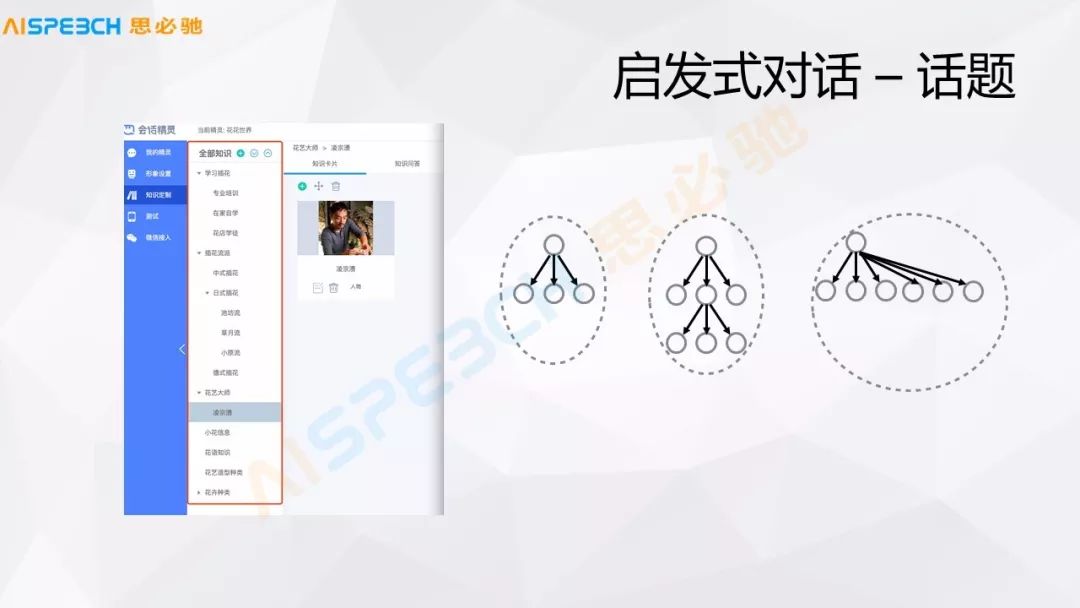
這是一個具體的例子,這是一個產品的形態,就是說這個話題的組織。對于一個企業的客戶,它如果想做一個它的對話系統,它可以人為地去設定一些話題,這個話題是以樹型的組織,比如在這個里邊就是一個關于花相關的話題,比如怎么學習花藝,各種花藝相關的信息,每一個話題,橙色的這部分是這個話題的組織,話題樹,用戶可以設定這樣一個話題的組織。在這個話題下面,每一個話題下面用戶都可以去定一些,比如花藝大師,花藝大師下面用戶可以定義它在這下面一些人相關的信息,然后具體把這些人相關的信息列出來。
一個終端的用戶就可以去問這些關于人的信息,所以話題大概有這么幾種形式,首先以右邊這個圖的形式,某一個話題下面可能有兩三個這樣的話題,當然這個話題還可以有層次,它可以有子話題、孫子話題,這個層次結構可以來組織擴展,當然一個話題下面可以有很多話題,這個話題的一個組織形式,這些基本的概念。
▌對話系統中的知識管理
再我們來看一下,在對話系統里邊這些知識它在對話的理解以及對話管理中是怎么來發生作用的,后面我會結合現有的技術,現有的大家常見的做對話里邊的相關技術,然后和啟發式對話一起來介紹對話系統中的知識管理。
首先來看幾個例子,在機器人理解語言中可能遇到的一些問題,這個給大家一個直觀的感覺,可能遇到哪些問題。比如說在理解上,機器人理解語言的過程中,比如說“今天天津適合洗車嗎”這樣一個輸入,如果是語音或者拼音輸入都可能會有這樣的問題,“今天天津適合洗車嗎”可能和“今天天津市河西”,天津市有一個河西區,可能就會理解錯,從拼音到文字可能就會出錯,實際上這個非常相似的。
這是我們在語言上可能會有一些問題,機器來做這個事的時候,它實際上很難來判斷,人是有一些背景的知識和上下文知識的。

我們來看一下,剛才列了那么多問題,一般情況下來做這個對話里邊核心的,剛才我們在最開始的架構圖里已經看到對話系統里邊核心的三大塊,一個是自然語言理解,一個是對話意圖理解,對話管理和對話答案的生成三個部分。
大家比較關注的是前兩個方面,對話的理解和管理,理解這部分可能最常見的是基于規則的系統,比如我們就寫一個 pattern,科研人員、時間、發表過的文章,類似這樣的,這個規則系統里有一些詞典和規則的組織,當然這有一系列規則組織的問題,實際上它也是一個比較浩大的工程,但是我們從算法或者是我們理解的角度,可能覺得它還是一個比較簡單的方式,當然規則多了之后是挺難維護的。

另外一種可能就是通過意圖的分類的方式,比如通過一些機器學習的方式給它做一個分類。比如我們做一點簡單的,比如天氣,對話系統只要理解出來它是天氣,然后我們就給它播一個天氣預報,很多場景下用戶也可以接受,系統不理解它里邊具體的東西,只理解是某一種意圖,然后就給它做一個播報。這里面常見的這種分類的算法都可以用得到。

另外一種是問句檢索的方式,比如在閑聊或者客服中實際上都大量地用到。我們說閑聊,實際上從學術上來說可能很多研究是在做深度學習的閑聊,但實際場景的閑聊里邊,有很多也是通過問答檢索的方式檢索出來的,當然它需要有大量的問答對,這些問答對都是人手工事先整理出來的,這是一個比較耗費人力的東西,并且它覆蓋的范圍有限。
一般做這個事的方式是說先通過一個倒排索引,這個用戶問題來了之后檢索出一組問題,然后對它進行一個侯選,然后再做一些排序,這個排序的算法可能有各種加權,有傳統的 learning to rank,還有深度學習下來這種深度的語意匹配的算法,這些算法我們后面可以具體地看幾個例子。

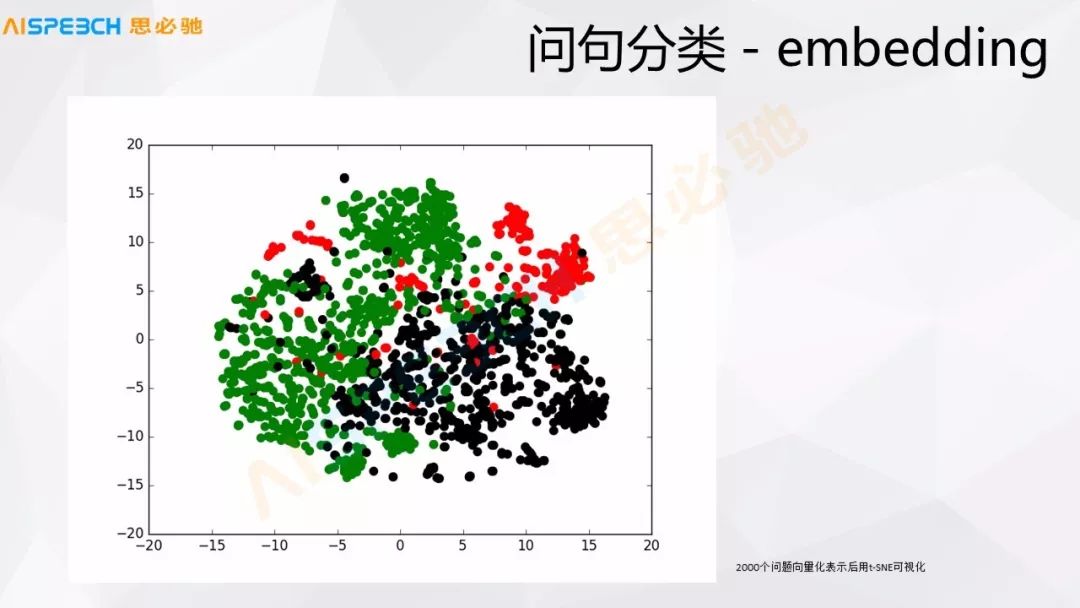
問句分類也有一些直接拿現在深度學習的,比如embedding,實際現在深度學習,比如前面提到的 Sequence to sequence 模型可以直接把用戶的問題 embedding 成一個向量,我們直接拿這個向量實際上就可以做一些問句的分類或者相似度計算,這張圖是大概 2000 多個用戶的問題,然后做了一個 embedding,就是用 Sequence to sequence 做了一個 embedding。
這個時候拿這種可視化的工具把它可視化出來,我們可以看出來它大概是能分出來的,這是三類問題,實上它確實也就是三類問題,雖然它們之間有一些交叉,現在這種深度學習的方法對于這種東西的建模能力還是挺強的,基本的問題類別還是能區分出來的。
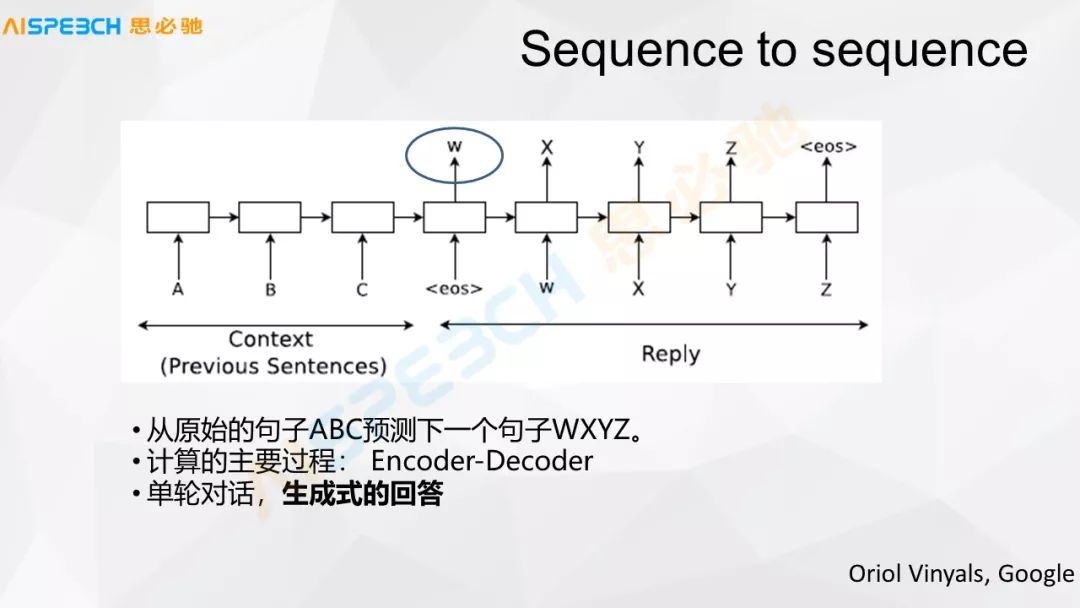
下面這張圖,現在這種基本的深度學習里邊的這些算法有一個很基礎的模型,就是 Sequence to sequence 的模型,它是基于把用戶說的里邊的每一個詞,比如 ABC 是一個輸入的詞,ABC 是輸入的這個問句,A 是一個詞,B 是一個詞,C 是一個詞,然后它的輸出有可能就是 XYZ,它把它送到 Sequence to sequence 這個神經網絡里邊,A 是一個詞,進去之后是一個 RN 的模型,它就做這樣一個 embedding,實際上到了 ABC,然后 eos,就是這個句子結束了。
結束之后這個神經網絡中間層就是一個 W,這個 W 可以表示這個句子的語意的表示,用這個 W 再去解碼出來一個答案,經過大量的數據訓練實際上就可以生成一個答案,生成式的閑聊可能主要就是這么來做的,這個模型,包括中間的這個表示 W,實際上也可以用來做問句的分類或者問句相似度的計算。
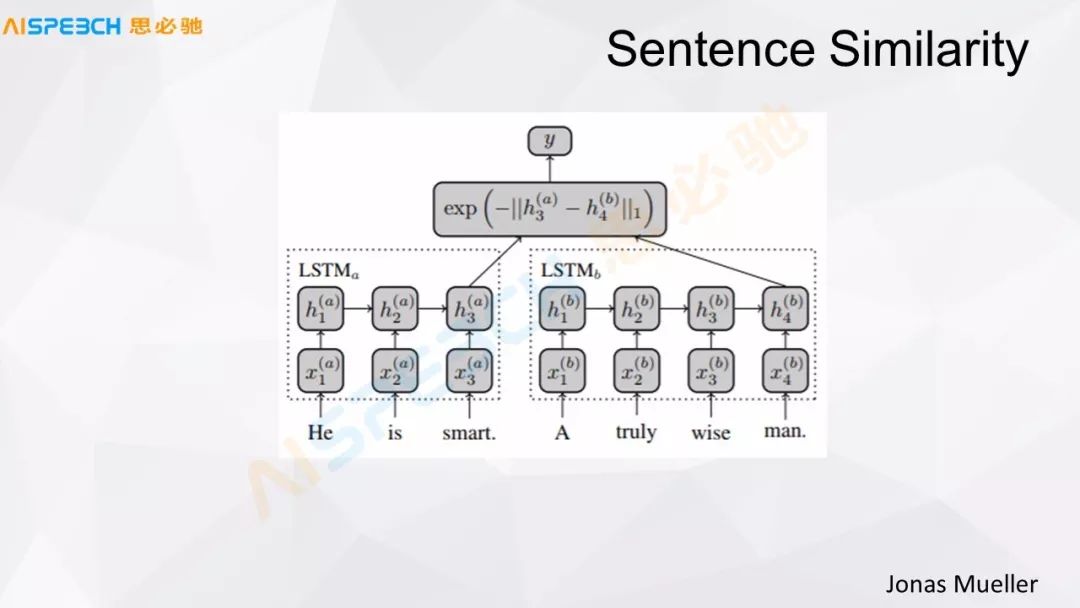
這是一個基本的模型,現在做問句,我們剛才提到現在大量的實際使用中做問句的相似度匹配,可能一種方法就是做句子相似度的計算,這張圖是一個做句子相似度計算的基礎模型,這里面這些都是現有的方法。
比如說用 LSTM 來對句子做一個編碼,這個 LSTM 這個基本的模型和剛才的 Sequence to sequence 的編碼階段類似,用戶的一個問題和一個系統中的問題,兩個都經過一個 LSTM,這個 X 代表了輸入,H 代表的是模型中間的隱藏層,用戶的這句話經過 LSTM 把它編碼成一個 h3(a) 這么一個狀態,還有一個標準問題(被檢索的問題),經過一個編碼,編碼成了 h4(b) 這么一個狀態,兩個經過一個距離的計算,就可以送到一個分類器里,給它做一個相似或者不相似的判斷。
這個方法是把用戶轉換成一個分類的問題,二分類的問題,這個用戶的問題和我們標準庫里的問題相似或者不相似,然后做一個判斷。這樣也可以做這個事,這是一種比較經典的方式,其實它的效果也還挺好,很多場景下都是挺適合的。
我們看一下下面這篇文章,這篇文章我覺得是在做相似度計算方面比較經典的一篇文章,它還做得比較好。它左邊是輸入,比如有 u_1、u_n-1、u_n是用戶的輸入,u_1 到 u_n 是用戶輸入的整個上下文,他可能說了多句。r是response響應。
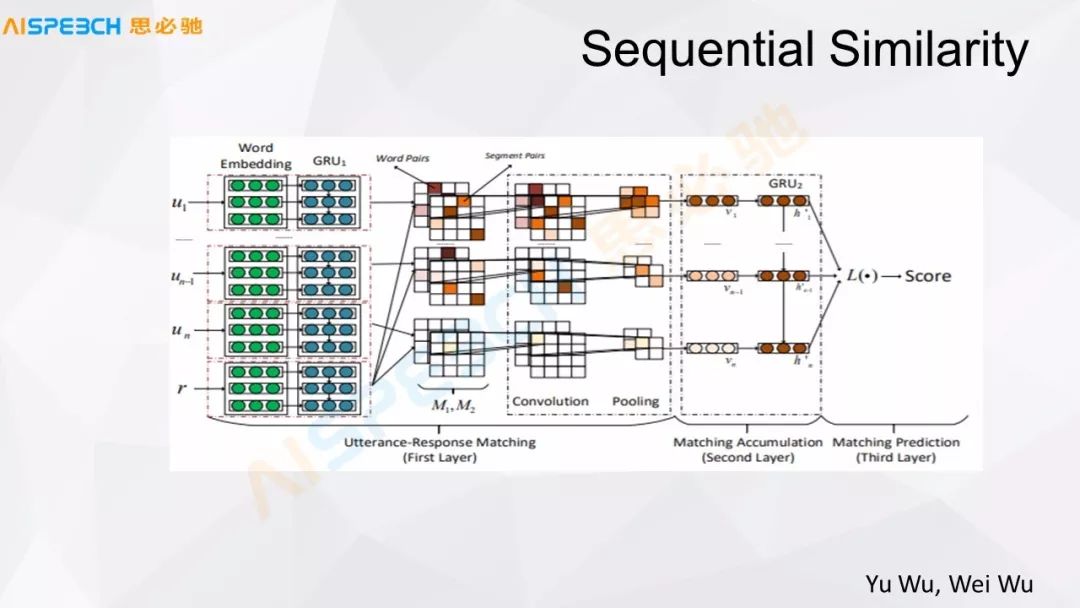
這個上下文經過一個 Word Embedding,每一個都可以 Embedding 成一個詞向量的表示,然后經過一個 GRU 或者 LSTM 都可以,然后把它編碼成一個向量。這里邊做了一個比較復雜的操作,中間這部分,M1M2 這部分,它是把用戶的輸入和答案分別交叉去做了一個內積的計算,都是向量,實際上表示出來都是矩陣,它們之間做一個內積混合的運算,充分的交叉之后再經過 CNN,CNN 然后經過一個Pooling,Pooling 之后再經過一個類似于這里邊又過了一個 GRU,最后輸出一個分值。
這個和剛才 LSTM 那個方式最大的區別是,首先它層數增多了,因為它最前面是 GRU,最后邊這兒也是一個 GRU,中間多了一個 CNN 的層,這個 CNN 層的作用實際上是把問題和答案的信息充分地混合,去找到它里邊匹配的相似或者結合的點,然后來給出一個答復。這個模型在很多場景下的效果是比較好的,我們在一些實驗中它的實際確實也是比較好的,但是它的問題是,因為它經過了一個很充分的混合,我們看到它對輸入的要求是有一定要求的,這個輸入相對比較長一點,它的信息比較充分,這樣做是比較好的。但是在有一些對話場景下,當這個對話比較短的時候,它的效果實際上是有限的。這是一種方式。
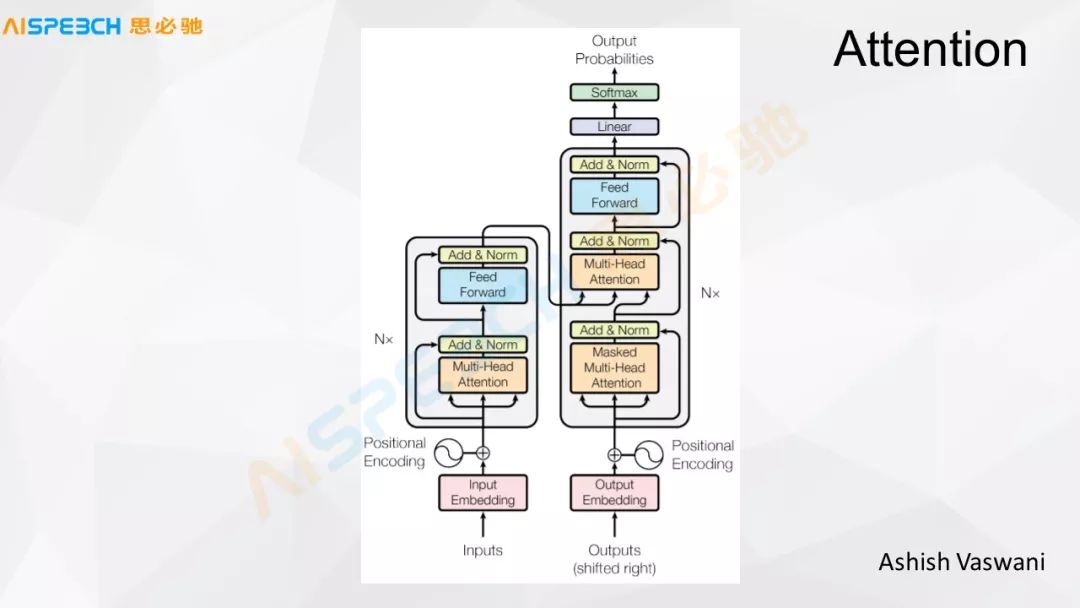
這張圖是谷歌的一篇文章里,它只用 Attention來解決,比如 Input 和 Output 這兩個地方,經過一系列的 Attention 最后輸出出來,我們做一個分類決策。我們借助于 Attention 的這個模型,多層 Attention 的模型去做這個分類任務的時候,這個在一些比較短文本的場景下,問題都比較短的情況下,它的效果實際上是比較好的。實際上這些模型可能都不是萬能的,每一種模型都有它適用的場景,根據數據我們才能看到它在哪些場景下更好或者是有它的長處。每一種模型都有它的長處和缺點。
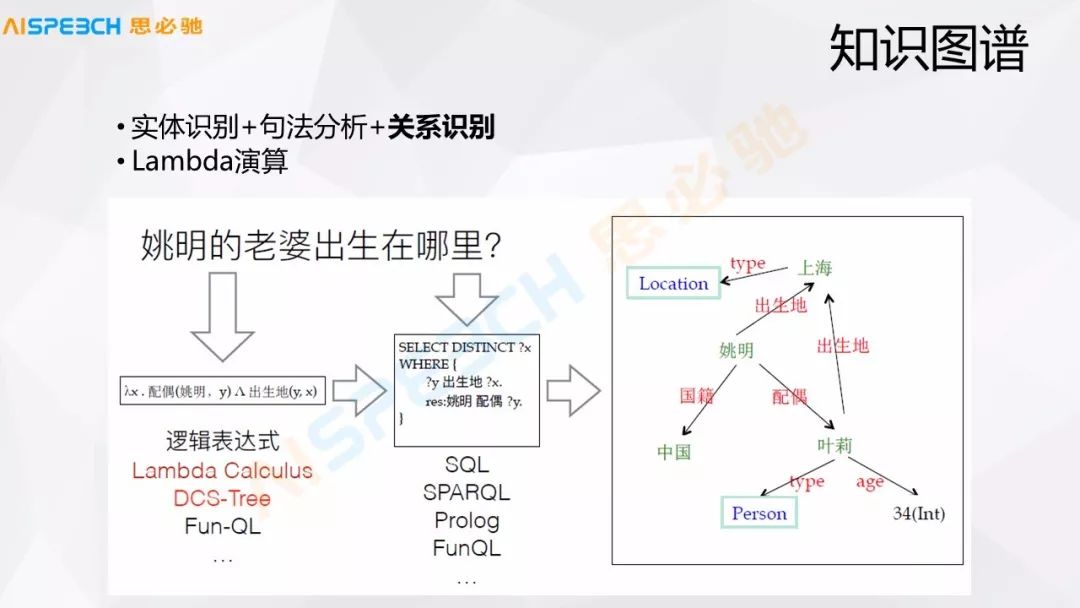
還有一些知識圖譜的方式,最直觀的可能知識圖譜是通過一些邏輯表達式來做的,比如說一個簡單的問題,就是姚明的老婆出生在哪里這種,知識圖譜里邊存儲了姚明以及他的配偶葉麗,這個方式我們理解起來也比較簡單,就是做了這么一個查找,但是當知識圖譜比較大的時候,實際上知識圖譜上的問答還是比較難做的。主要是用戶的表達很難去和知識圖譜里的東西嚴格地匹配上,一般情況下這種方式,把用戶的一個問句嚴格地解析出來問句里各個實體及其關系,然后把這些轉換成一個邏輯表達式,通過這個邏輯表達式到這個知識圖譜里去查找。這種方式其實也很常用。
剛才介紹了現在理解方面主要的方法,但是現在也有很多方式是說集成,我集成上面各種方法,然后做一個集成學習,比如問句理解的方法,問答的方式,就是檢索、知識圖譜、 embedding 的,都可以用來做問答,任務型的問答可能有規則的,也可以做embedding,也可以做分類,復雜問題可能就是客服里邊有很多問題其實挺復雜,長度也比較長,可以用這種分類或者檢索的,也可以用更嚴格的語意解析的方式來做。這些不同的方式、算法做一個集成,實際上現在有挺多是這樣做的,效果也還是挺好。

就是我們在做一個模型去做選擇,上面比如做了三個或者五個模型來去理解,用戶來一句話對這幾個模型都去理解,理解出來之后然后做一個集成,集成之后再做最后的輸出,集成實際上是為了做選擇,到底用哪個模型的答案,當然集成方式主要是兩種,一種是流水線,這些模型我排成一個順序,哪個模型解決了我就出了,我就把答案出出來,然后就不再往后走了,另外一個是模型集成,每個模型都走,然后做一個決策判斷,選哪個模型的結果。
上面是關于對話中 NLU 的部分,另外一部分是關于對話中的知識管理,或者對話管理里的知識管理,對話管理這部分。
對話管理一般是這樣,我們在有上下文的情況下,對話管理就是用戶當前我們可能能分析出來一個意圖,有的時候甚至當前我們都分析不出來一個意圖。比如說用戶說了一個上海,我們實際上不知道用戶說上海是什么意思,如果前面是在說天氣,那上海就是跟天氣有關,如果前面在說訂票,那上海就是和訂票有關。有當前的一個用戶的意圖,甚至這個都不是一個意圖,然后有上文,有一些上文是在哪個領域里邊,有用戶的信息,這個有時候可能還有一些用戶長時間的信息,根據這些信息做出一些行為,到底是要答復,還是拒絕,還是去問用戶的補充,用戶需要補充一些信息。
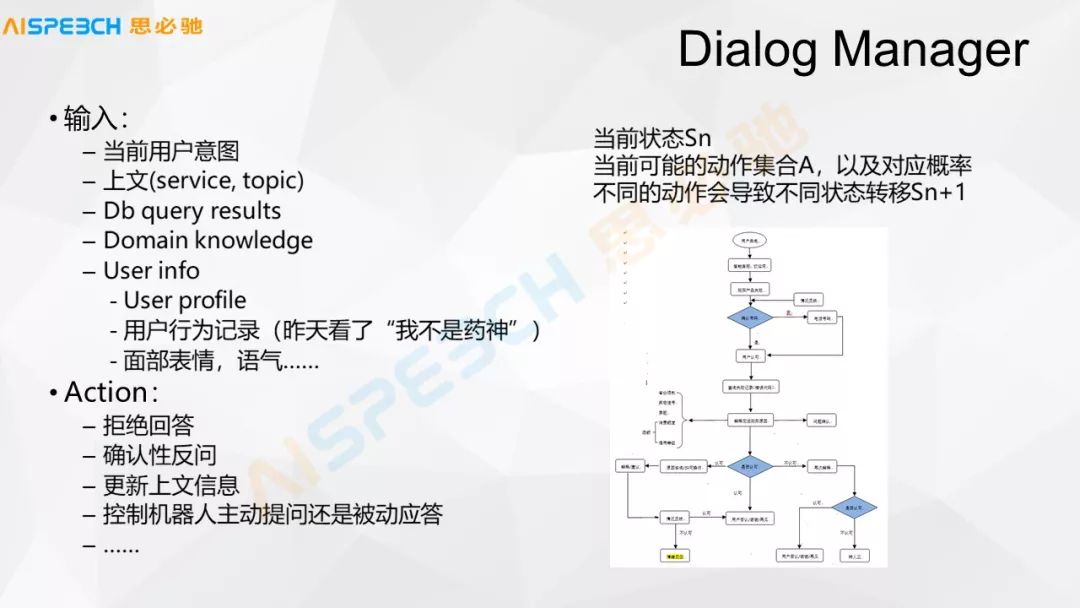
對話管理里面有幾種主要的形式,一種是基于 slot 的,slot 可能就是一個填槽,如果有三個槽位,時間、地點、天氣現象,我就把它填完就行了,缺哪個我就問用戶有哪個。另外一種用 slot 不是特別好解決的就是有些流程很復雜的,特別是在客服,比如這張圖里的場景,這是一個客服的場景,它的流程就很復雜,用戶到了某一個地方,他需要去判斷關于這個地方的信息,然后再做下一步的操作,這是這個對話管理主要的東西。
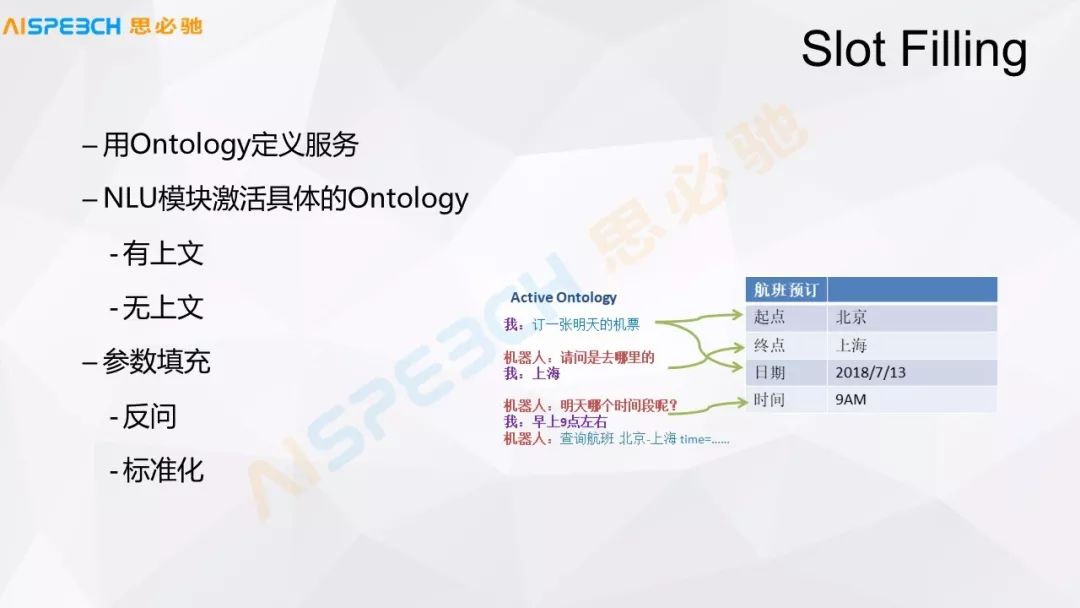
這張圖介紹一下關于最基礎的對話管理,比如 SlotFilling,它是在有沒有上下文,事先定義好了這張訂票的場景,然后它有一些上下文的信息怎么來控制,這個場景是剛才已經提到的,就不詳細說了。
在啟發式對話里邊還有一種基于話題的對話管理,首先話題本身,因為它引入了一個新的概念就是話題,在問用戶的問題之外引入了話題,話題可以是人工建的,也可以是系統自動計算出來的,也可以是系統引導用戶來創建,這個話題就是我剛才在最開始講啟發式對話的時候,我們看到的,比如說關于花的一些相關話題的組織,也可以通過一些學習的方式去挖掘問題之間有哪些話題,特別在一些企業服務的場景中,因為企業本身有它明確的應用場景,所以它是有一些話題,它本身已經組織好的關于這些話題的組織。

當然話題的組織實際上是有很多問題的,我們比如拿樹型來組織這些話題,這個系統的后面怎么來組織這個話題。比如按產品、人物來組織話題,所有的產品是一個話題,所有的人物是一個話題,但是當我真正要去問這個系統的時候,你會發現產品和人物它們之間是有交叉的,因為人物,比如說科技領域的人物和娛樂領域的人物,他們可能就沒有什么交叉領域,我們把它放在一個話題下面也不合適。所以說話題的劃分實際上是有一定交叉的,當然我們顯示出來一般情況下是一種樹型的方式來組織,這樣對用戶也比較容易理解。但是它真正的管理后面實際上有很多的交叉。
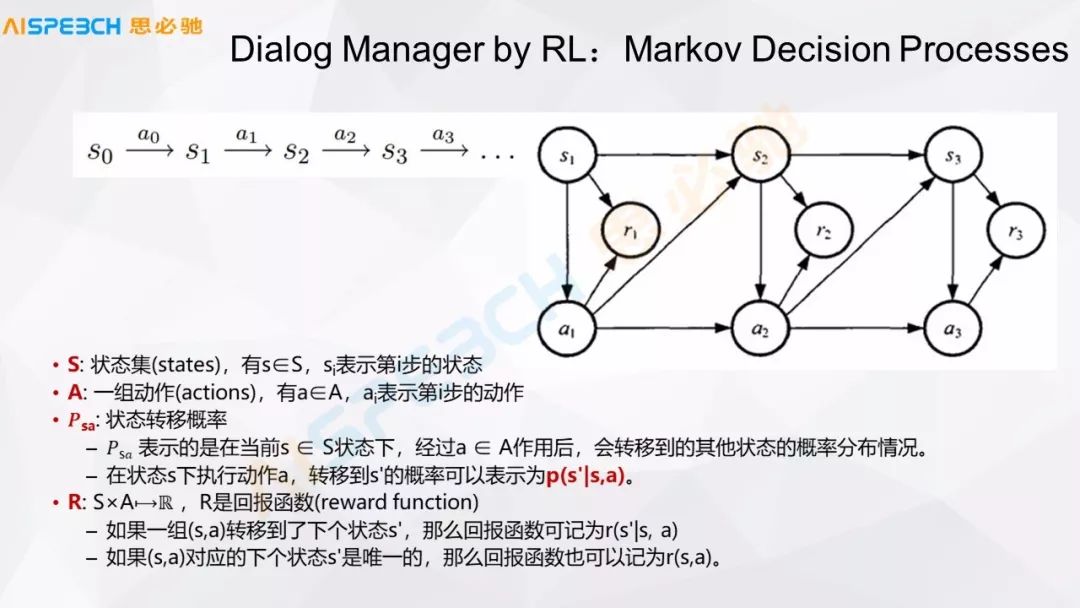
對話的管理,實際上一般情況下我們可以認為它是這種狀態,這種狀態轉換的過程,比較典型的可能就是一個 Markov 決策過程,這里邊 S 是一組狀態集,A 是一組動作,在某一個狀態下它遇到一個什么東西,然后要做一個什么樣的響應或者什么樣的動作,機器學習的方式可能就需要把這個對話組織成這樣一個狀態,在這里邊一個重要的地方是需要有一些回報的函數。
比如說在強化學習做這種對話的時候,不一定是做對話管理,做對話生成的時候也有這種場景,就是說它去定義一個在對話里邊,它模擬多輪,根據一個定好的回報函數,然后來做一個判斷,這是對話管理,對話管理用強化學習可以來做。實際上強化學習就是模擬多輪的對話,然后再回過來判斷當前的狀態到底走哪一步合適。
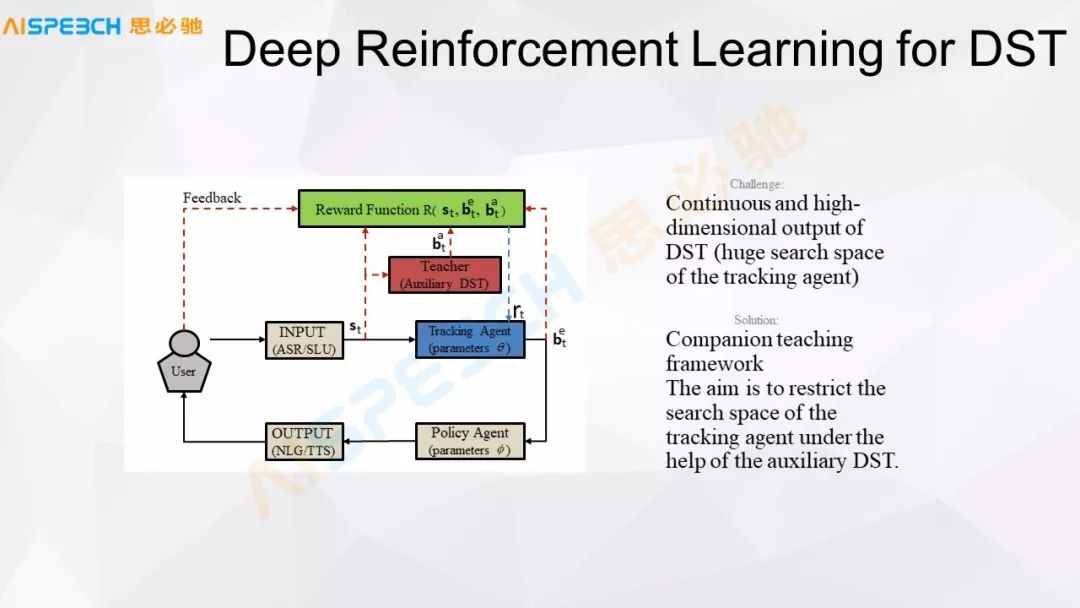
這是一個用深度強化學習來做對話狀態跟蹤的簡單狀態,比如用戶輸入了一句話,通過語音識別,它可以有一個狀態的管理,然后去管理這個狀態,通過一個策略來控制它的輸出。當然它中間核心的一個部分是有這個 Reward 函數,在對話里,這個 Reward 函數就非常重要,一般情況下它也不太好定義,因為我們對話,它到底什么算合適,什么算不合適,這個還不是特別好控制的。
我們來看一下用強化學習來做對話,簡單總結一下,在一個狀態 S 下它可能有 m 種操作,我們不知道這個 m 種操作哪一種能帶來什么樣的回報,所以我們做一個探索,去探索每一種可能操作的回報,利用這種回報做一個響應,做一個決策或者對這個回報做一個打分。
另外也有用對抗網絡做的,但對抗網絡有一個問題,實際上也不太好控制,并且有些情況下可能會強制這些對話的走向,并且對抗網絡它的穩定性也是一個問題,這個訓練過程中的穩定性也是一個問題。

不管是深度學習,還是傳統機器學習,在對話的 NLU 以及對話管理中的一些方法或者作用,前面講的都是一些現有的方法,怎么來做的,但是它里邊都會有一些問題,機器學習的方法很多時候,如果生成式的那就不好控制它到底生成的和這個相關還是不相關,很難判斷。如果是檢索式的,用戶說的這句話,不管怎么著都會給它一個檢索答案,到底這個答案是給用戶還是不給用戶,用戶說了一個不相關的問題,我可能也會給它檢索出來一個答案,答案是給還是不給?這也是一個問題。實際上這里邊就用到知識,這個過程中就非常重要了。
知識在這里邊分為兩種,一種是知識圖譜,嚴格的知識圖譜,這里邊 KG 的這部分。另外一些是語言的知識,比如說語言的搭配、語言語法的轉換、拼寫的問題、領域的問題,實際上還包括一些領域詞的問題,相似詞、同義詞,這些東西在自然語言發展,這么多年實際上已經積累了很多這方面的知識,但是這些東西在現在深度學習里邊實際上很難結合進去。
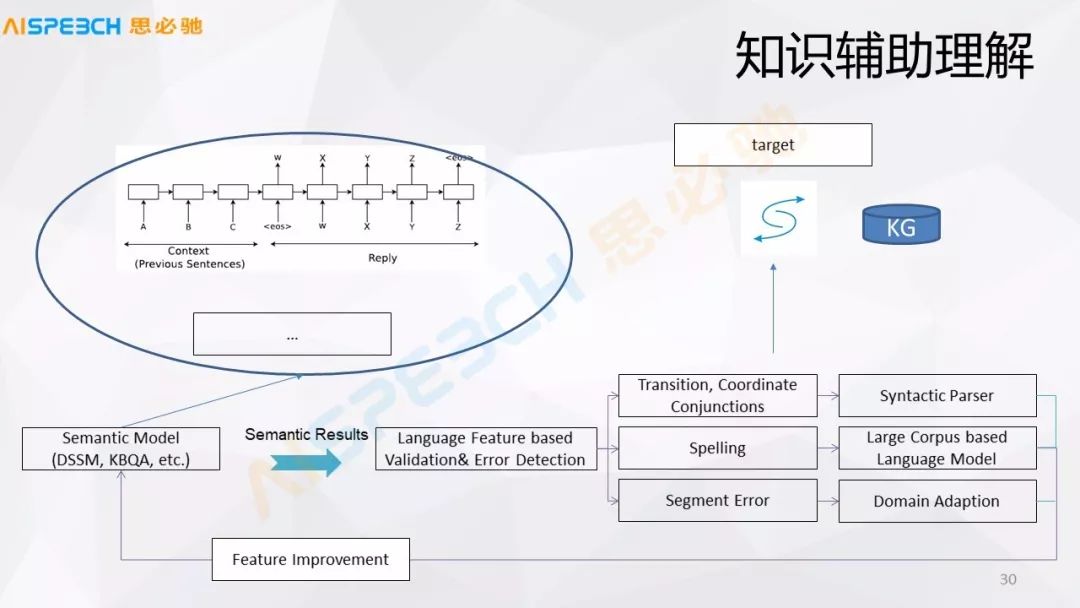
通過上面提到的相似度計算模型我們可以完成前面說的自然語言的相似度計算的問題,但是我們給了這個答案很有可能是不對的,所以說經過這些語言的特征以及 KG 的知識,把知識作為驗證候選的證據,深度語義模型給出多個候選答案,我們對于這種可能的各種侯選,通過知識圖譜或者語言現象對它做一個分析,然后去找到一些證據,這些證據再來驗證去選哪一個答案。因為一般情況下對于直接用嚴格的知識圖譜來解析一個問題的時候有一個問題,很多時候我們無法嚴格地去解析出來這個問題,只能解析出來一部分。
-
啟發式
+關注
關注
0文章
3瀏覽量
6253 -
對話系統
+關注
關注
0文章
7瀏覽量
2180
發布評論請先 登錄
相關推薦
混合啟發式算法在汽車調度中的應用
基于粗糙集的啟發式約簡算法
單片機課程任務式啟發式教學改革
基于時序行為分析的自適應混合啟發式協同優化算法
基于網頁排名算法面向論文索引排名的啟發式方法
基于區分對象集的啟發式屬性約簡算法
啟發式木馬檢測系統
關于啟發式對話中的知識管理系統

AI語音技術升級了 會話精靈開啟對話、語音交互、知識管理等技術
《AI移動智能終端藍皮書》介紹
量子啟發式提升投資收益:指數復制與指數優化






 工商網監
工商網監
評論