") 關于人臉識別的歷史和發(fā)展
關于人臉識別的歷史和發(fā)展
自動人臉識別的經(jīng)典流程分為三個步驟:人臉檢測、面部特征點定位(又稱FaceAlignment人臉對齊)、特征提取與分類器設計。一般而言,狹義的人臉識別指的是"特征提取+分類器"兩部分的算法研究。
在深度學習出現(xiàn)以前,人臉識別方法一般分為高維人工特征提取(例如:LBP,Gabor等)和降維兩個步驟,代表性的降維方法有PCA,LDA等子空間學習方法和LPP等流行學習方法。在深度學習方法流行之后,代表性方法為從原始的圖像空間直接學習判別性的人臉表示。

一般而言,人臉識別的研究歷史可以分為三個階段。在第一階段(1950s-1980s),人臉識別被當作一個一般性的模式識別問題,主流技術(shù)基于人臉的幾何結(jié)構(gòu)特征。在第二階段(1990s)人臉識別迅速發(fā)展,出現(xiàn)了很多經(jīng)典的方法,例如Eigen Face, Fisher Face和彈性圖匹配,此時主流的技術(shù)路線為人臉表觀建模。在第三階段(1990s末期到現(xiàn)在),人臉識別的研究不斷深入,研究者開始關注面向真實條件的人臉識別問題,主要包括以下四個方面的研究:1)提出不同的人臉空間模型,包括以線性判別分析為代表的線性建模方法,以Kernel方法為代表的非線性建模方法和基于3D信息的3D人臉識別方法。2)深入分析和研究影響人臉識別的因素,包括光照不變?nèi)四樧R別、姿態(tài)不變?nèi)四樧R別和表情不變?nèi)四樧R別等。3)利用新的特征表示,包括局部描述子(Gabor Face, LBP Face等)和深度學習方法。4)利用新的數(shù)據(jù)源,例如基于視頻的人臉識別和基于素描、近紅外圖像的人臉識別。

2007年以來,LFW數(shù)據(jù)庫成為事實上的真實條件下的人臉識別問題的測試基準。LFW數(shù)據(jù)集包括來源于因特網(wǎng)的5,749人的13,233張人臉圖像,其中有1680人有兩張或以上的圖像。LFW的標準測試協(xié)議包括6000對人臉的十折確認任務,每折包括300對正例和300對反例,采用十折平均精度作為性能評價指標。
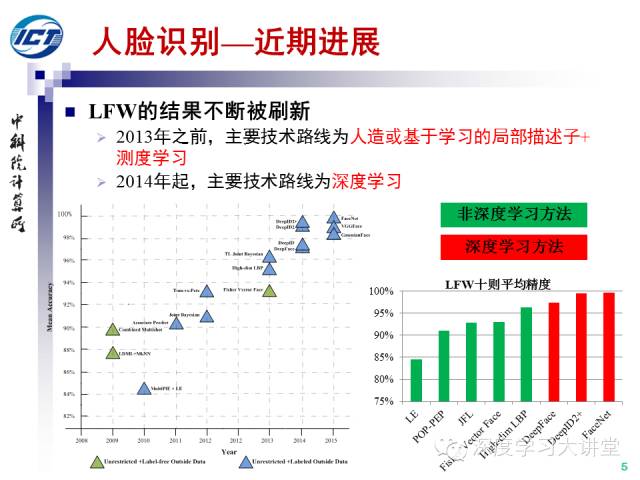
自從LFW發(fā)布以來,性能被不斷刷新。2013年之前,主要技術(shù)路線為人造或基于學習的局部描述子+測度學習。2014年之后,主要技術(shù)路線為深度學習。
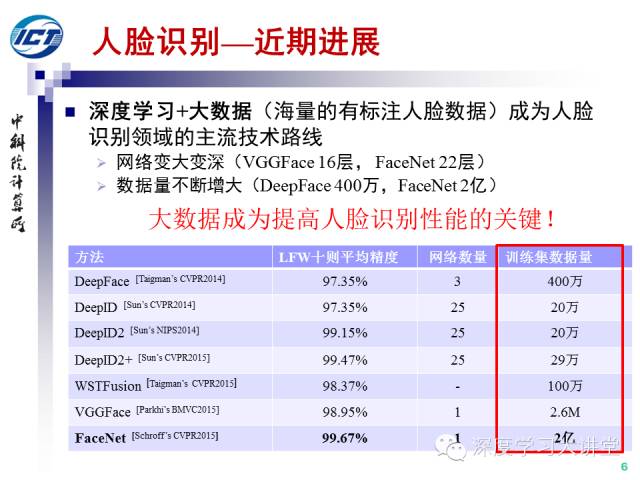
2014年以來,深度學習+大數(shù)據(jù)(海量的有標注人臉數(shù)據(jù))成為人臉識別領域的主流技術(shù)路線,其中兩個重要的趨勢為:1)網(wǎng)絡變大變深(VGGFace16層,F(xiàn)aceNet22層)。2)數(shù)據(jù)量不斷增大(DeepFace400萬,F(xiàn)aceNet2億),大數(shù)據(jù)成為提升人臉識別性能的關鍵。
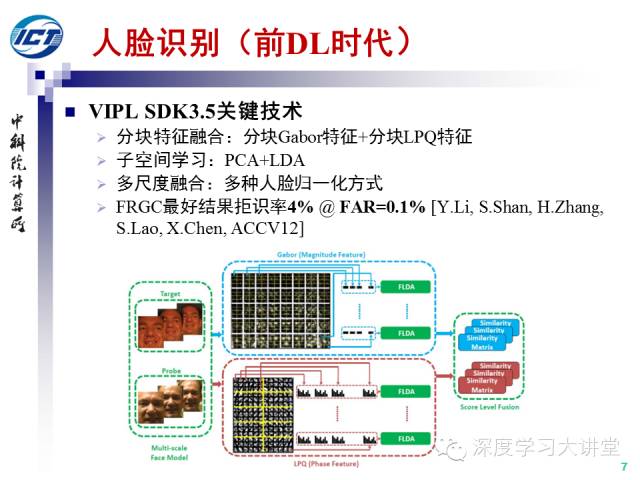
在前DL時代,以VIPL實驗室三代半SDK為例,關鍵技術(shù)點包括1)分塊人臉特征融合:Gabor特征+LPQ特征。 2)子空間學習進行特征降(PCA+LDA)。3)融合多尺度的人臉歸一化模板。SDK3.5的相關技術(shù)在FRGC實驗4上取得了0.1%錯誤接受率條件下96%的確認率,至今依然是FRGC數(shù)據(jù)集上最好結(jié)果。

需要指出的是,雖然深度學習強調(diào)特征學習,但學習特征并不是DL的專利。在前DL時代,利用淺層模型從圖像中直接學習表示和基于人造描述子學習語義表示(例如學習中層屬性表示的Attributes and Simile Classifier和學習高層語義表示的Tom-vs-Pete)的工作都見于相關文獻。

2014年,F(xiàn)acebook發(fā)表于CVPR14的工作DeepFace將大數(shù)據(jù)(400萬人臉數(shù)據(jù))與深度卷積網(wǎng)絡相結(jié)合,在LFW數(shù)據(jù)集上逼近了人類的識別精度。其中DeepFace還引入了一個Local Connected卷積結(jié)構(gòu),在每個空間位置學習單獨的卷積核,缺點是會導致參數(shù)膨脹,這個結(jié)構(gòu)后來并沒有流行起來。
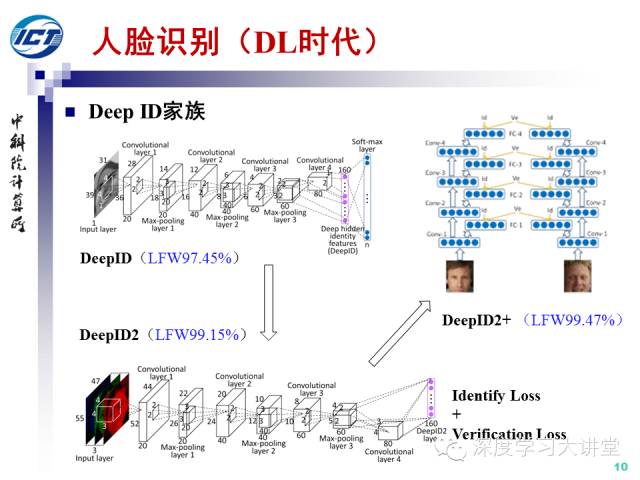
DeepID家族可以看作是DL時代人臉識別領域的一組代表性工作。最早的DeepID網(wǎng)絡包括四個卷積層,采用softmax損失函數(shù)。DeepID2在DeepID網(wǎng)絡的基礎上,同時考慮了分類損失(identityloss) 和確認損失(verification loss),這兩種損失在Caffe深度學習框架中分別可以采用softmaxwithloss層和contrastiveloss層來實現(xiàn)。DeepID2+網(wǎng)絡則是在DeepID2的基礎上,增加了每一層的輔助損失函數(shù)(類似Deep Supervised Network)。
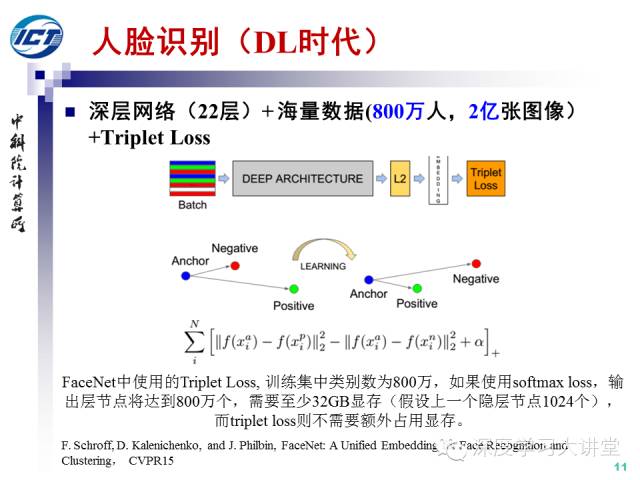
Google發(fā)表于CVPR2015的工作FaceNet采用了22層的深層卷積網(wǎng)絡和海量的人臉數(shù)據(jù)(800萬人的2億張圖像)以及常用于圖像檢索任務的Triplet Loss損失函數(shù)。值得一提的是,由于人臉類別數(shù)達到800萬類,如果使用softmax loss,輸出層節(jié)點將達到800萬個,需要至少32GB顯存(假設上一個隱層節(jié)點1024個,采用單精度浮點數(shù)),而Triplet Loss則不需要額外占用顯存。FaceNet在LFW數(shù)據(jù)集上十折平均精度達到99.63%,這也是迄今為止正式發(fā)表的論文中的最好結(jié)果,幾乎宣告了LFW上從2008年到2015年長達8年之久的性能競賽的結(jié)束。
-
數(shù)據(jù)庫
+關注
關注
7文章
3767瀏覽量
64279 -
人臉識別
+關注
關注
76文章
4007瀏覽量
81783 -
人臉檢測
+關注
關注
0文章
80瀏覽量
16443
發(fā)布評論請先 登錄
相關推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論