") 機器學(xué)習(xí)全靠調(diào)參?谷歌大腦新研究:神經(jīng)網(wǎng)絡(luò)構(gòu)建超強網(wǎng)絡(luò)
機器學(xué)習(xí)全靠調(diào)參?谷歌大腦新研究:神經(jīng)網(wǎng)絡(luò)構(gòu)建超強網(wǎng)絡(luò)
機器學(xué)習(xí)全靠調(diào)參?這個思路已經(jīng)過時了。
谷歌大腦團隊發(fā)布了一項新研究:只靠神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索出的網(wǎng)絡(luò),不訓(xùn)練,不調(diào)參,就能直接執(zhí)行任務(wù)。這樣的網(wǎng)絡(luò)叫做WANN,權(quán)重不可知神經(jīng)網(wǎng)絡(luò)。它在MNIST數(shù)字分類任務(wù)上,未經(jīng)訓(xùn)練和權(quán)重調(diào)整,就達(dá)到了92%的準(zhǔn)確率,和訓(xùn)練后的線性分類器表現(xiàn)相當(dāng)。除了監(jiān)督學(xué)習(xí),WANN還能勝任許多強化學(xué)習(xí)任務(wù)。
團隊成員之一的大佬David Ha,把成果發(fā)上了推特,已經(jīng)獲得了1300多贊:
那么,先來看看效果吧。
谷歌大腦用WANN處理了3種強化學(xué)習(xí)任務(wù)。(給每一組神經(jīng)元,共享同一個權(quán)重。)
第一項任務(wù),Cart-Pole Swing-Up。
這是經(jīng)典的控制任務(wù),一條滑軌,一臺小車,車上一根桿子。小車在滑軌的范圍里跑,要把桿子從自然下垂的狀態(tài)搖上來,保持在直立的位置不掉下來。(這個任務(wù)比單純的Cart-Pole要難一些:Cart-Pole桿子的初始位置就是向上直立,不需要小車把它搖上來,只要保持就可以。)
難度體現(xiàn)在,沒有辦法用線性控制器 (Linear Controller) 來解決。每一個時間步的獎勵,都是基于小車到滑軌一頭的距離,以及桿子擺動的角度。
WANN的最佳網(wǎng)絡(luò) (Champion Network) 長這樣:
它在沒有訓(xùn)練的狀態(tài)下,已經(jīng)表現(xiàn)優(yōu)異:
表現(xiàn)最好的共享權(quán)重,給了團隊十分滿意的結(jié)果:只用幾次擺動便達(dá)到了平衡狀態(tài)。
第二項任務(wù),Bipedal Waker-v2。
一只兩足“生物”,要在隨機生成的道路上往前走,越過凸起,跨過陷坑。獎勵多少,就看它從出發(fā)到掛掉走了多長的路,以及電機扭矩的成本(為了鼓勵高效運動) 。每條腿的運動,都是由一個髖關(guān)節(jié)、和一個膝關(guān)節(jié)來控制的。有24個輸入,會指導(dǎo)它的運動:包括“激光雷達(dá)”探測的前方地形數(shù)據(jù),本體感受到的關(guān)節(jié)運動速度等等。比起第一項任務(wù)中的低維輸入,這里可能的網(wǎng)絡(luò)連接就更多樣了。所以,需要WANN對從輸入到輸出的布線方式,有所選擇。這個高維任務(wù),WANN也優(yōu)質(zhì)完成了。
你看,這是搜索出的最佳架構(gòu),比剛才的低維任務(wù)復(fù)雜了許多:
它在-1.5的權(quán)重下奔跑,長這樣:
第三項任務(wù),CarRacing-v0。
這是一個自上而下的 (Top-Down) 、像素環(huán)境里的賽車游戲。一輛車,由三個連續(xù)命令來控制:油門、轉(zhuǎn)向、制動。目標(biāo)是在規(guī)定的時間里,經(jīng)過盡可能多的磚塊。賽道是隨機生成的。研究人員把解釋每個像素 (Pixel Interpretation) 的工作交給了一個預(yù)訓(xùn)練的變分自編碼器 (VAE) ,它可以把像素表征壓縮到16個潛在維度。這16維就是網(wǎng)絡(luò)輸入的維度。學(xué)到的特征是用來檢測WANN學(xué)習(xí)抽象關(guān)聯(lián) (Abstract Associations) 的能力,而不是編碼不同輸入之間顯式的幾何關(guān)系。
這是WANN最佳網(wǎng)絡(luò),在-1.4共享權(quán)重下、未經(jīng)訓(xùn)練的賽車成果:
雖然路走得有些蜿蜒,但很少偏離跑到。而把最佳網(wǎng)絡(luò)微調(diào)一下,不用訓(xùn)練,便更加順滑了:
總結(jié)一下,在簡單程度和模塊化程度上,第二、三項任務(wù)都表現(xiàn)得優(yōu)秀,兩足控制器只用了25個可能輸入中的17個,忽略了許多LIDAR傳感器和膝關(guān)節(jié)的速度。
WANN架構(gòu)不止能在不訓(xùn)練單個權(quán)重的情況下完成任務(wù),而且只用了210個網(wǎng)絡(luò)連接(Connections) ,比當(dāng)前State-of-the-Art模型用到的2804個連接,少了一個數(shù)量級。做完強化學(xué)習(xí),團隊又瞄準(zhǔn)了MNIST,把WANN拓展到了監(jiān)督學(xué)習(xí)的分類任務(wù)上。一個普通的網(wǎng)絡(luò),在參數(shù)隨機初始化的情況下,MNIST上面的準(zhǔn)確率可能只有10%左右。
而新方法搜索到的網(wǎng)絡(luò)架構(gòu)WANN,用隨機權(quán)重去跑,準(zhǔn)確率已經(jīng)超過了80%;如果像剛剛提到的那樣,喂給它多個權(quán)值的合集,準(zhǔn)確率就達(dá)到了91.6%。
對比一下,經(jīng)過微調(diào)的權(quán)重,帶來的準(zhǔn)確率是91.9%,訓(xùn)練過的權(quán)重,可以帶來94.2%的準(zhǔn)確率。再對比一下,擁有幾千個權(quán)重的線性分類器:
也只是和WANN完全沒訓(xùn)練、沒微調(diào)、僅僅喂食了一些隨機權(quán)重時的準(zhǔn)確率相當(dāng)。論文里強調(diào),MINST手寫數(shù)字分類是高維分類任務(wù)。WANN表現(xiàn)得非常出色。并且沒有哪個權(quán)值,顯得比其他值更優(yōu)秀,大家表現(xiàn)得十分均衡:所以隨機權(quán)重是可行的。
不過,每個不同的權(quán)重形成的不同網(wǎng)絡(luò),有各自擅長分辨的數(shù)字,所以可以把一個擁有多個權(quán)值的WANN,用作一個自給自足的合集 (Self-Contained Ensemble) 。
實現(xiàn)原理
不訓(xùn)練權(quán)重參數(shù)獲得極高準(zhǔn)確度,WANN是如何做到的呢?神經(jīng)網(wǎng)絡(luò)不僅有權(quán)重偏置這些參數(shù),網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)、激活函數(shù)的選擇都會影響最終結(jié)果。

谷歌大腦的研究人員在論文開頭就提出質(zhì)疑:神經(jīng)網(wǎng)絡(luò)的權(quán)重參數(shù)與其架構(gòu)相比有多重要?在沒有學(xué)習(xí)任何權(quán)重參數(shù)的情況下,神經(jīng)網(wǎng)絡(luò)架構(gòu)可以在多大程度上影響給定任務(wù)的解決方案。
為此,研究人員提出了一種神經(jīng)網(wǎng)絡(luò)架構(gòu)的搜索方法,無需訓(xùn)練權(quán)重找到執(zhí)行強化學(xué)習(xí)任務(wù)的最小神經(jīng)網(wǎng)絡(luò)架構(gòu)。谷歌研究人員還把這種方法用在監(jiān)督學(xué)習(xí)領(lǐng)域,僅使用隨機權(quán)重,就能在MNIST上實現(xiàn)就比隨機猜測高得多的準(zhǔn)確率。
論文從架構(gòu)搜索、貝葉斯神經(jīng)網(wǎng)絡(luò)、算法信息論、網(wǎng)絡(luò)剪枝、神經(jīng)科學(xué)這些理論中獲得啟發(fā)。為了生成WANN,必須將權(quán)重對網(wǎng)絡(luò)的影響最小化,用權(quán)重隨機采樣可以保證最終的網(wǎng)絡(luò)是架構(gòu)優(yōu)化的產(chǎn)物,但是在高維空間進行權(quán)重隨機采樣的難度太大。研究人員采取了“簡單粗暴”的方法,對所有權(quán)重強制進行權(quán)重共享(weight-sharing),讓權(quán)重值的數(shù)量減少到一個。這種高效的近似可以推動對更好架構(gòu)的搜索。
操作步驟
解決了權(quán)重初始化的問題,接下來的問題就是如何收搜索權(quán)重不可知神經(jīng)網(wǎng)絡(luò)。它分為四個步驟:
1、創(chuàng)建初始的最小神經(jīng)網(wǎng)絡(luò)拓?fù)淙骸?/p>
2、通過多個rollout評估每個網(wǎng)絡(luò),并對每個rollout分配不同的共享權(quán)重值。
3、根據(jù)性能和復(fù)雜程度對網(wǎng)絡(luò)進行排序。
4、根據(jù)排名最高的網(wǎng)絡(luò)拓?fù)鋪韯?chuàng)建新的群,通過競爭結(jié)果進行概率性的選擇。
然后,算法從第2步開始重復(fù),在連續(xù)迭代中,產(chǎn)生復(fù)雜度逐漸增加的權(quán)重不可知拓?fù)洌╳eight agnostic topologies )。
拓?fù)渌阉?/strong>
用于搜索神經(jīng)網(wǎng)絡(luò)拓?fù)涞牟僮魇艿缴窠?jīng)進化算法(NEAT)的啟發(fā)。在NEAT中,拓?fù)浜蜋?quán)重值同時優(yōu)化,研究人員忽略權(quán)重,只進行拓?fù)渌阉鞑僮鳌?/p>
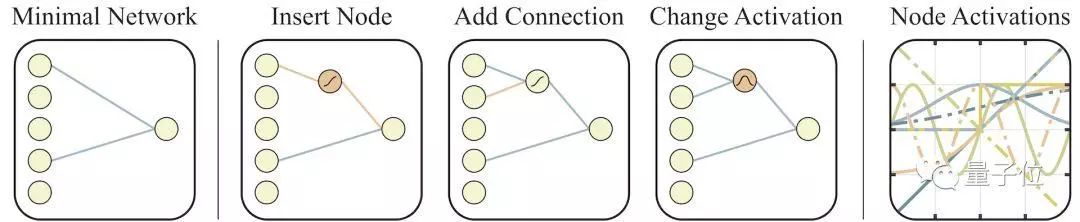
上圖展示了網(wǎng)絡(luò)拓?fù)淇臻g搜索的具體操作:
一開始網(wǎng)絡(luò)上是最左側(cè)的最小拓?fù)浣Y(jié)構(gòu),僅有部分輸入和輸出是相連的。
然后,網(wǎng)絡(luò)按以下三種方式進行更改:
1、插入節(jié)點:拆分現(xiàn)有連接插入新節(jié)點。
2、添加連接:連接兩個之前未連接的節(jié)點,添加新連接。
3、更改激活函數(shù):重新分配隱藏節(jié)點的激活函數(shù)。
圖的最右側(cè)展示了權(quán)重在[2,2]取值范圍內(nèi)可能的激活函數(shù),如線性函數(shù)、階躍函數(shù)、正弦余弦函數(shù)、ReLU等等。
權(quán)重依然重要
WANN與傳統(tǒng)的固定拓?fù)渚W(wǎng)絡(luò)相比,可以使用單個的隨機共享權(quán)重也能獲得更好的結(jié)果。
雖然WANN在多項任務(wù)中取得了最佳結(jié)果,但WANN并不完全獨立于權(quán)重值,當(dāng)隨機分配單個權(quán)重值時,有時也會失敗。WANN通過編碼輸入和輸出之間的關(guān)系起作用,雖然權(quán)重的大小的重要性并不高,但它們的一致性,尤其是符號的一致性才是關(guān)鍵。
隨機共享權(quán)重的另一個好處是,調(diào)整單個參數(shù)的影響變得不重要,無需使用基于梯度的方法。強化學(xué)習(xí)任務(wù)中的結(jié)果讓作者考慮推廣WANN方法的應(yīng)用范圍。他們又測試了WANN在圖像分類基礎(chǔ)任務(wù)MNIST上的表現(xiàn),結(jié)果在權(quán)重接近0時效果不佳。

有Reddit網(wǎng)友質(zhì)疑WANN的結(jié)果,對于隨機權(quán)重接近于0的情況,該網(wǎng)絡(luò)的性能并不好,先強化學(xué)習(xí)實驗中的具體表現(xiàn)就是,小車會跑出限定范圍。
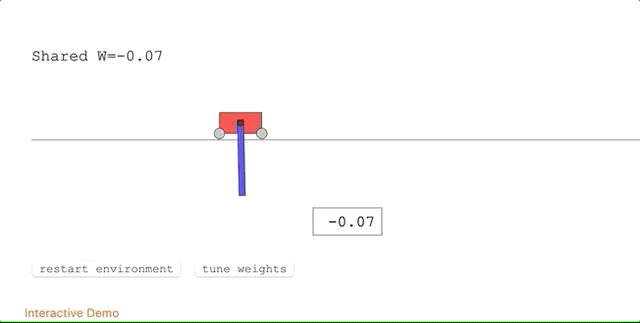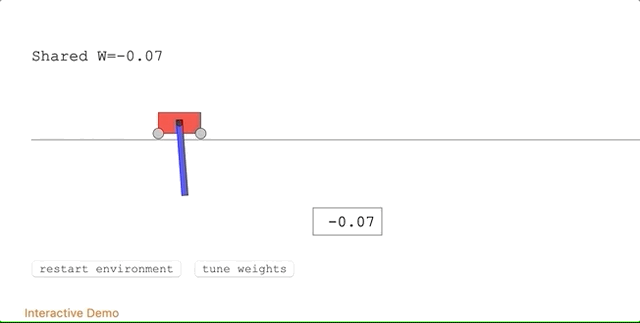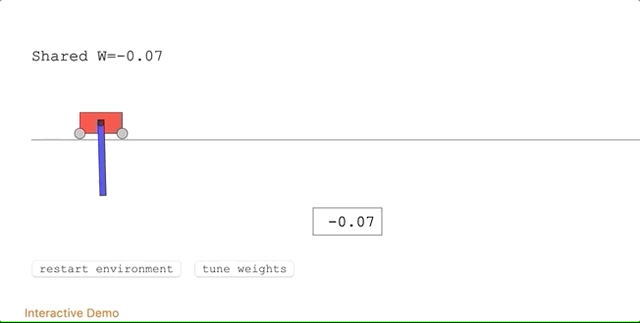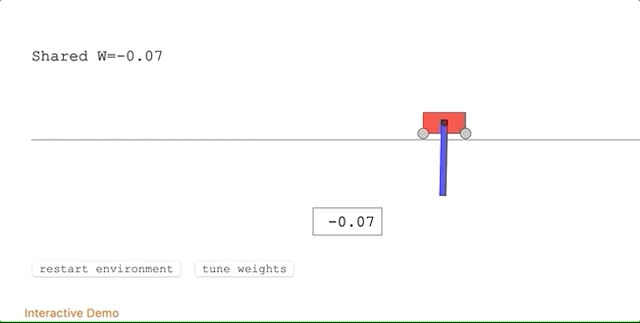
對此,作者給出解釋,在權(quán)重趨于0的情況下,網(wǎng)絡(luò)的輸出也會趨于0,所以后期的優(yōu)化很難達(dá)到較好的性能。
-
谷歌
+關(guān)注
關(guān)注
27文章
6142瀏覽量
105109 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100541 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8378瀏覽量
132412
原文標(biāo)題:谷歌發(fā)布顛覆性研究:不訓(xùn)練不調(diào)參,AI自動構(gòu)建超強網(wǎng)絡(luò)!
文章出處:【微信號:mcuworld,微信公眾號:嵌入式資訊精選】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
卷積神經(jīng)網(wǎng)絡(luò)的實現(xiàn)工具與框架
循環(huán)神經(jīng)網(wǎng)絡(luò)的常見調(diào)參技巧
LSTM神經(jīng)網(wǎng)絡(luò)的調(diào)參技巧
如何構(gòu)建多層神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)機制
BP神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)的關(guān)系
PyTorch神經(jīng)網(wǎng)絡(luò)模型構(gòu)建過程
機器人神經(jīng)網(wǎng)絡(luò)系統(tǒng)的特點包括
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
如何使用神經(jīng)網(wǎng)絡(luò)進行建模和預(yù)測
使用PyTorch構(gòu)建神經(jīng)網(wǎng)絡(luò)
基于神經(jīng)網(wǎng)絡(luò)算法的模型構(gòu)建方法
構(gòu)建神經(jīng)網(wǎng)絡(luò)模型方法有幾種
神經(jīng)網(wǎng)絡(luò)架構(gòu)有哪些
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論