 Tesseract的安裝測試使用
Tesseract的安裝測試使用
OCR開源項目很多,給大家一個鏈接,這個鏈接列出了現有的比較出名的OCR開源項目,鏈接如下:
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
從上面的排名可以看到,Tesseract是排在第一名的!所以下面就認真學習一下Tesseract。首先介紹一下Tesseract,然后安裝,測試,了解其不足等等。
Tesseract的OCR引擎目前已作為開源項目發布在Google Project,
其項目主頁在這里查看https://github.com/tesseract-ocr,
它支持中文OCR,并提供了一個命令行工具。python中對應的包是
pytesseract. 通過這個工具我們可以識別圖片上的文字。
一 Tesseract的安裝測試使用
首先下載Tesseract在Windows下的安裝版。(因為在國外訪問不了谷歌,所以別人***下載了下來,這里給大家百度網盤鏈接)
http://pan.baidu.com/s/1i56Uxlr
根據https://github.com/tesseract-ocr/tesseract/wiki,找到非官方的安裝包,好像只看到64位的安裝包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下載后直接安裝即可,但是要記得你的安裝目錄,我們等會配置環境變量要用。
如果不是做英文的圖文識別,還需要下載其他語言的識別包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
簡體字識別包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁體字識別包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
1.3 安裝Tesseract
下載Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安裝就行。(此處附上windows 4.0的安裝過程)
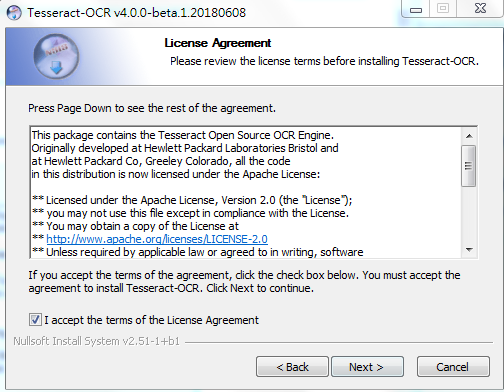
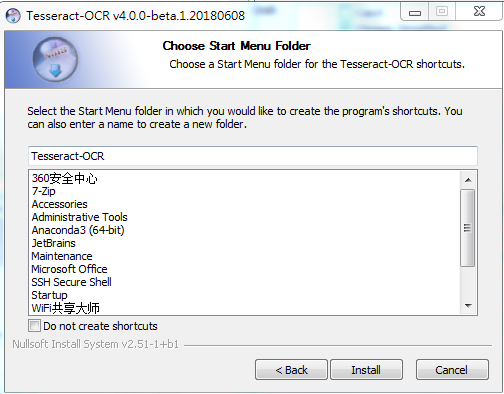
既然是要訓練中文,記得勾選 additional language data
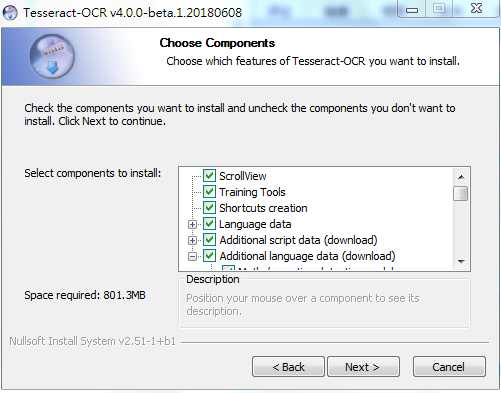
找到中文簡體和中文繁體,按需勾選,然后點下一步
可以先不勾選,因為這樣直接下載語言的包實在太慢。可以從網頁上直接下載語言包,然后等程序安裝好后,放入安裝目錄下tessdata目錄下面
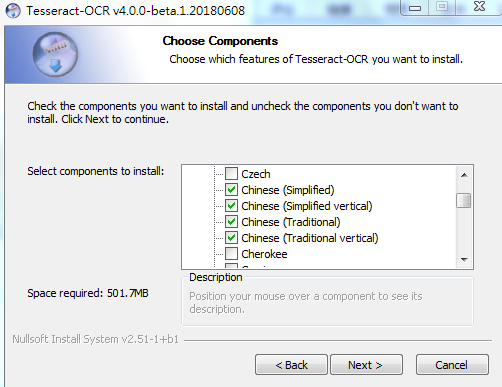
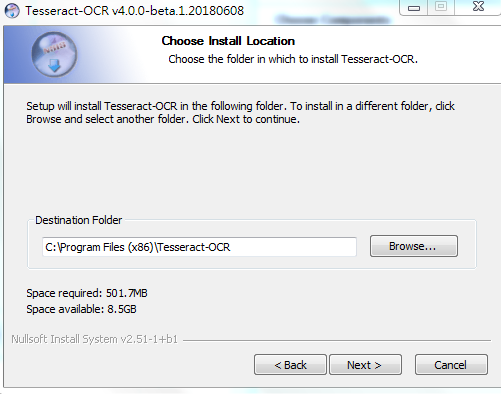
下載下來之后一路Next安裝好,然后在開始菜單找到其控制臺引導程序,如下圖所示
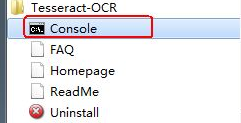
1.4 測試英文字符識別
上面的安裝包里自帶了已經訓練好的英文-拉丁文識別數據~所以我們先來測試一下英文字符的識別吧~識別圖像如下:
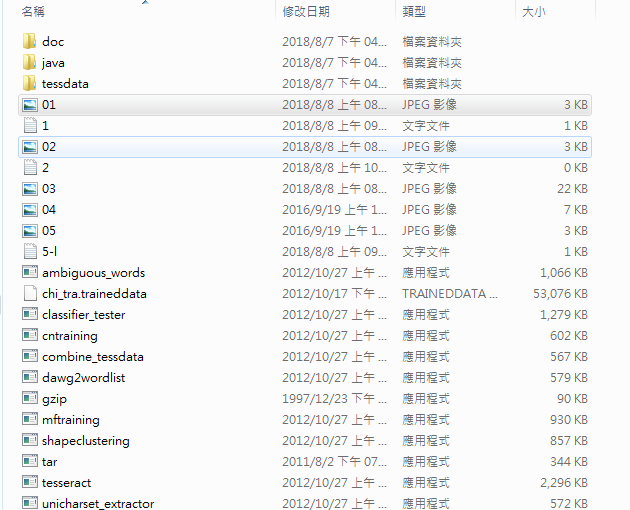
1.4.1把上面的圖片放到Tesseract的安裝目錄下,如下圖所示:
1.4.2打開上面提到的控制臺窗口,如下圖所示:
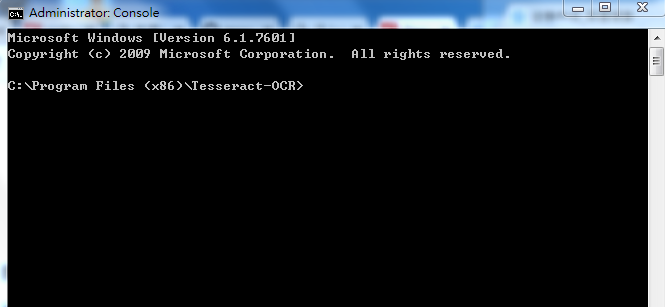
1.4.3在窗口中輸入命令:“tesseract.exe 0.jpg 1”,并回車,如下圖所示:
01.jpg代表待識別的源文件,1代表輸出文件名,默認輸出格式是txt文件格式!
注意,上面的 lang之前是-l 而不是-1!

1.4.4讓我們先查看一下01.jpg照片,如下圖:
1.4.5在安裝目錄下生成了1.txt文件,識別結果如下圖所示:
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
OCR
+關注
關注
0文章
144瀏覽量
16330
原文標題:深入學習使用ocr算法識別圖片中文字的方法
文章出處:【微信號:ddongcloud,微信公眾號:嵌入式DSP】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
壓接式N頭連接器安裝方便嗎

言必信科技 如何正確安裝磁環

Docker運行環境安裝
HarmonyOS高效測試必備HDC命令
全新Fluke 1670 系列多功能安裝測試儀——測試速度提高30%,報告時間減少50%

什么是系統集成測試?DC-DC電源測試系統可以測試哪些參數?
電源ATE自動測試系統的定制化測試柜

家用斷路器的安裝方法
德國GMC-I多功能安裝測試儀METRALINE MF - 高效、便捷的電氣測試解決方案

注射器滑動性測試儀的基本測試原理

蓄電池整組充放電活化儀上位機軟件安裝說明

米爾全志T527開發板安裝測試軟件
探針測試臺工作原理 探針測試臺為嘛測試會偏大?
48V通信電源安裝調試





 工商網監
工商網監
評論