 一篇文章搞定CNN轉置卷積
一篇文章搞定CNN轉置卷積
在CNN中,轉置卷積是一種上采樣(up-sampling)的方法。如果你對轉置卷積感到困惑,那么就來讀讀這篇文章吧。
上采樣的需要
在我們使用神經網絡的過程中,我們經常需要上采樣(up-sampling)來提高低分辨率圖片的分辨率。
上采樣有諸多方法,舉例如下。
最近鄰插值(Nearest neighbor interpolation)
雙線性插值(Bi-linear interpolation)
雙立方插值(Bi-cubic interpolation)
但是,上述的方法都需要插值操作,而這些插值的操作都充滿了人為設計和特征工程的氣息,而且也沒有網絡進行學習的余地。
為何需要轉置卷積
如果我們想要網絡去學出一種最優的上采樣方法,我們可以使用轉置卷積。它與基于插值的方法不同,它有可以學習的參數。
若是想理解轉置卷積這個概念,可以看看它是如何運用于在一些有名的論文和項目中的。
DCGAN的生成器(generator)接受一些隨機采樣的值作為輸入來生成出完整的圖片。它的語義分割(semantic segmentation)就使用了卷積層來提取編碼器(encoder)中的特征,接著,它把原圖存儲在解碼器(decoder)中以確定原圖中的每個像素的類別歸屬。
轉置卷積也被稱作: “分數步長卷積(Fractionally-strided convolution)”和”反卷積(Deconvolution)”.
我們在這篇文章里面只使用轉置卷積這個名字,其他文章可能會用到其他名字. 這些名字指的都是同樣的東西.
卷積操作
我們先通過一個簡單的例子來看看卷積是怎么工作的.
假設我們有一個4x4的input矩陣, 并對它使用核(kernel)為3x3,沒有填充(padding),步長(stride)為1的卷積操作. 結果是一個2x2的矩陣,如下圖所示.
(譯者注: stride,kernel,padding等詞以下記為英文)
卷積操作的本質其實就是在input矩陣和kernel矩陣之間做逐元素(element-wise)的乘法然后求和. 因為我們的stride為1,不使用padding,所以我們只能在4個位置上進行操作.
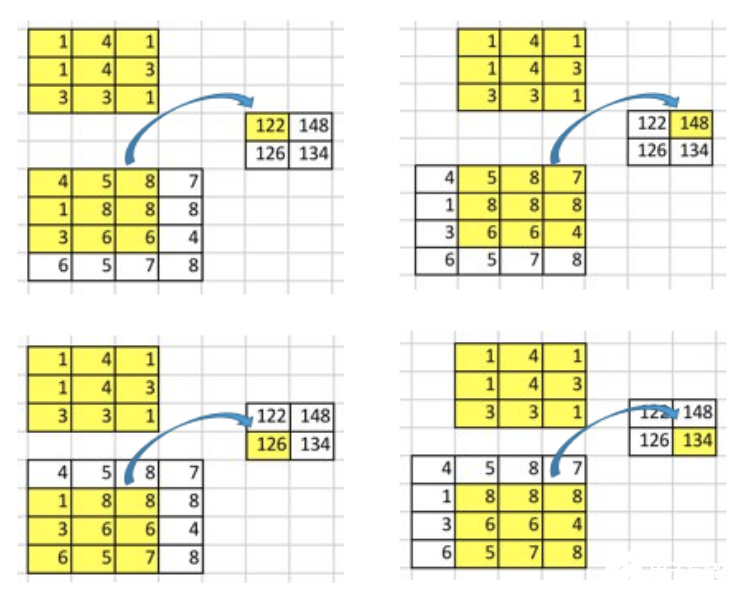
要點:卷積操作其實就是input值和output值的位置性關系(positional connectivity).
例如,在input矩陣的左上角的值會影響output矩陣的左上角的值.
更進一步,3x3的核建立了input矩陣中的9個值和output矩陣中的1個值的關系.
“卷積操作建立了多對一的關系”. 在閱讀下文時,請讀者務必時刻牢記這個概念.
卷積的逆向操作
現在,考慮一下我們如何換一個計算方向. 也就是說,我們想要建立在一個矩陣中的1個值和另外一個矩陣中的9個值的關系.這就是像在進行卷積的逆向操作,這就是轉置卷積的核心思想.
(譯者注:從信息論的角度看,卷積是不可逆的.所以這里說的并不是從output矩陣和kernel矩陣計算出原始的input矩陣.而是計算出一個保持了位置性關系的矩陣.)
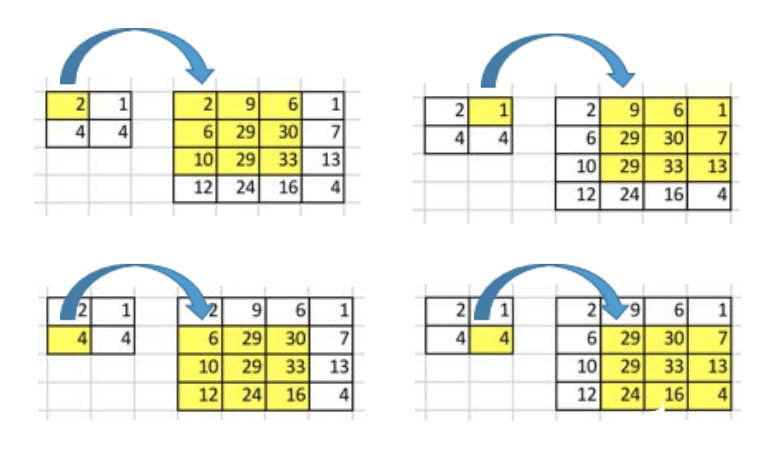
但是,我們如何進行這種逆向操作呢?
為了討論這種操作,我們先要定義一下卷積矩陣和卷積矩陣的轉置.
卷積矩陣
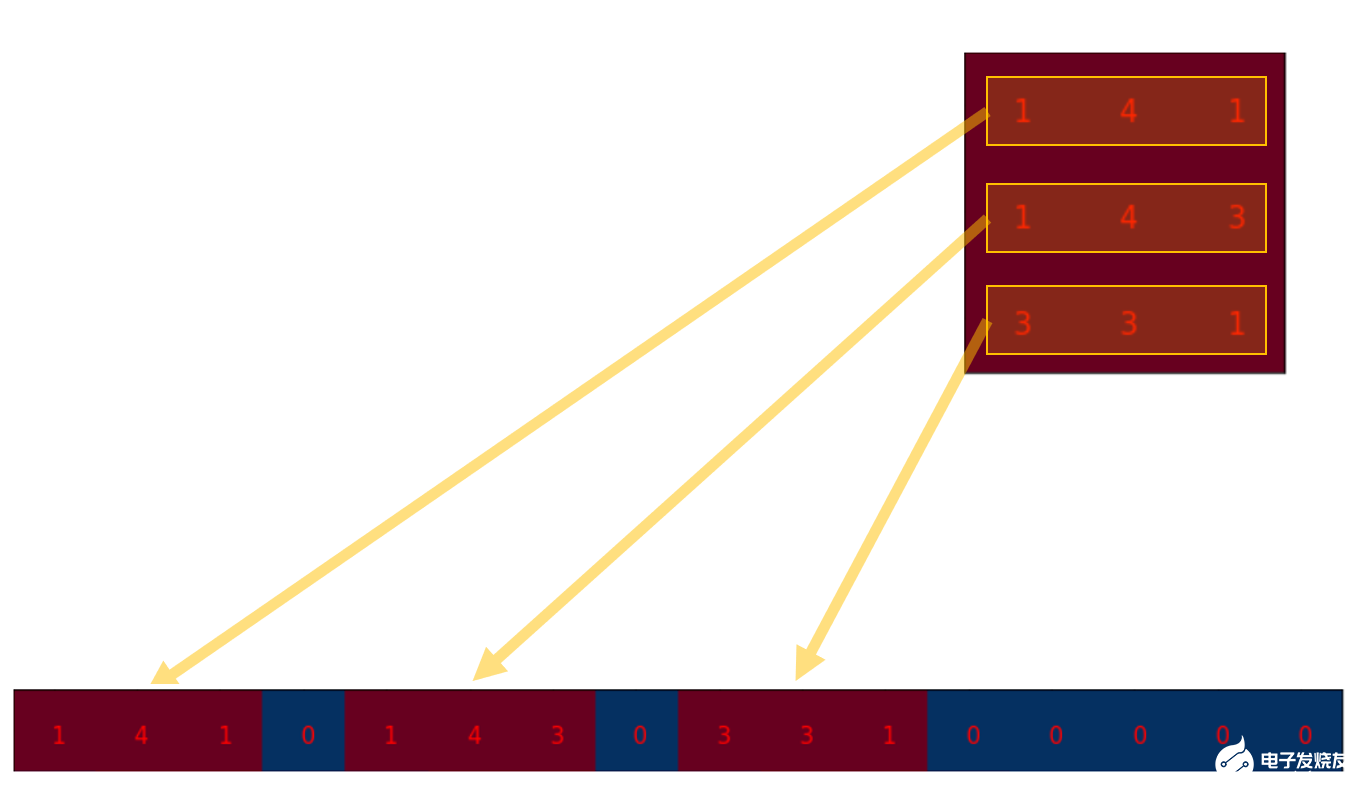
我們可以將卷積操作寫成一個矩陣. 其實這就是重新排列一下kernel矩陣, 使得我們通過一次矩陣乘法就能計算出卷積操作后的矩陣.

我們將3x3的kernel重排為4x16的矩陣,如下:

這就是卷積矩陣. 每一行都定義了一次卷積操作. 如果你還看不透這一點, 可以看看下面的圖. 卷積矩陣的每一行都相當于經過了重排的kernel矩陣,只是在不同的位置上有zero padding罷了.
為了實現矩陣乘法,我們需要將尺寸為4x4的input矩陣壓扁(flatten)成一個尺寸為16x1的列向量(column vector).
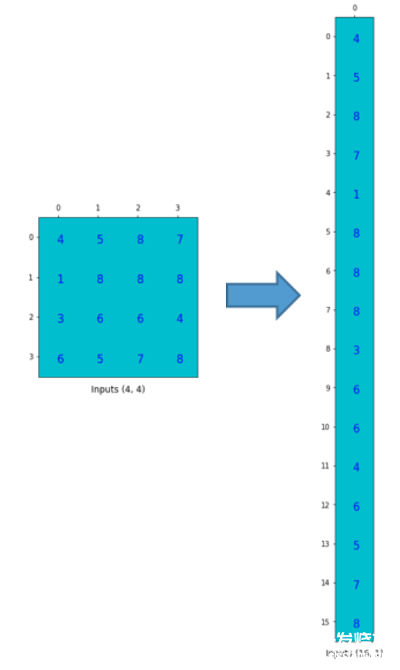
然后,我們對4x16的卷積矩陣和1x16的input矩陣(就是16維的列向量,只是看成一個矩陣)進行矩陣乘法.
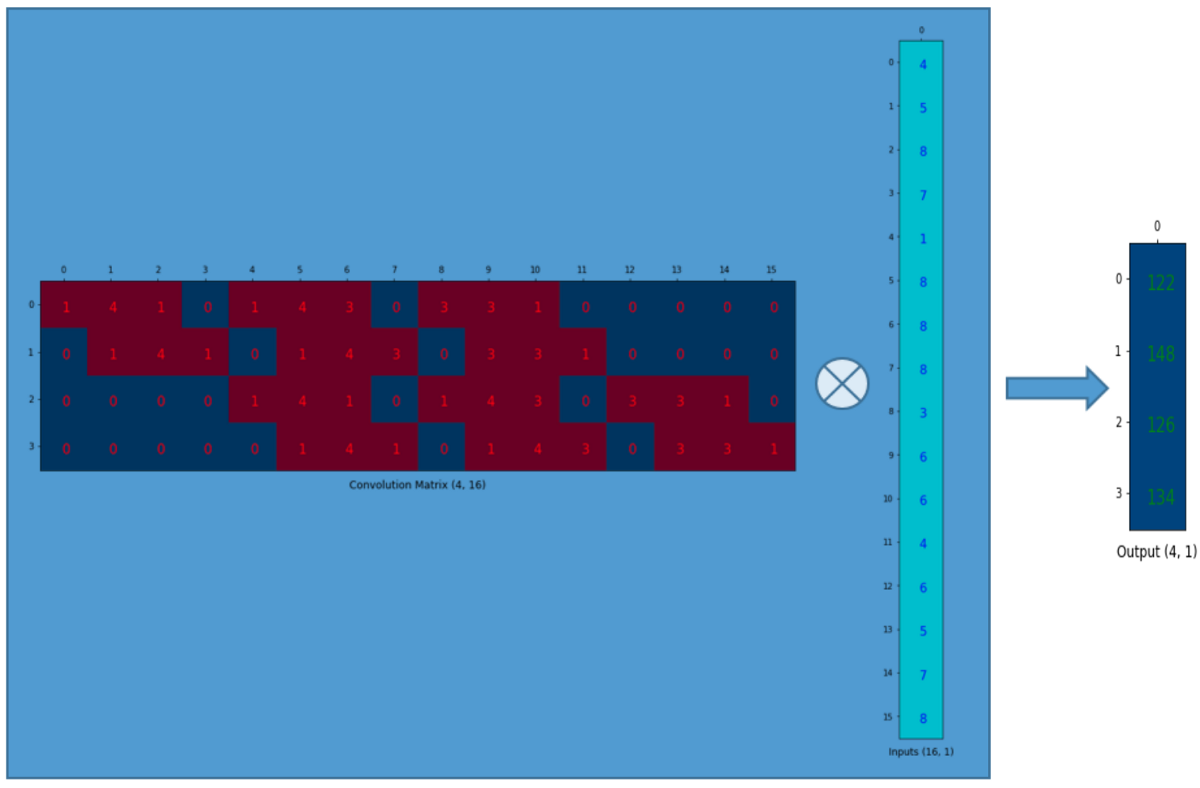
尺寸為4x1的output矩陣可以重排為2x2的矩陣.這正和我們之前得到的結果一致.

一句話,一個卷積矩陣其實就是kernel權重的重排,一個卷積操作可以被寫成一個卷積矩陣.
即便這樣又如何呢?
我想說的是: 使用這個卷積矩陣,你可以把16(4x4的矩陣)個值映射為4(2x2的矩陣)個值. 反過來做這個操作,你就可以把4(2x2的矩陣)個值映射為16(4x4的矩陣)辣.
蒙了?
繼續讀.
轉置過后的卷積矩陣
我們想把4(2x2的矩陣)個值映射為16(4x4的矩陣)個值。但是,還有一件事!我們需要維護1對9的關系。
假設我們轉置一下卷積矩陣C(4x16),得到C.T(16x4)。我們可以將C.T(16x4)和一個列向量(4x1)以矩陣乘法相乘,得到尺寸為16x1的output矩陣。轉置之后的矩陣建立了1個值對9個值的關系。
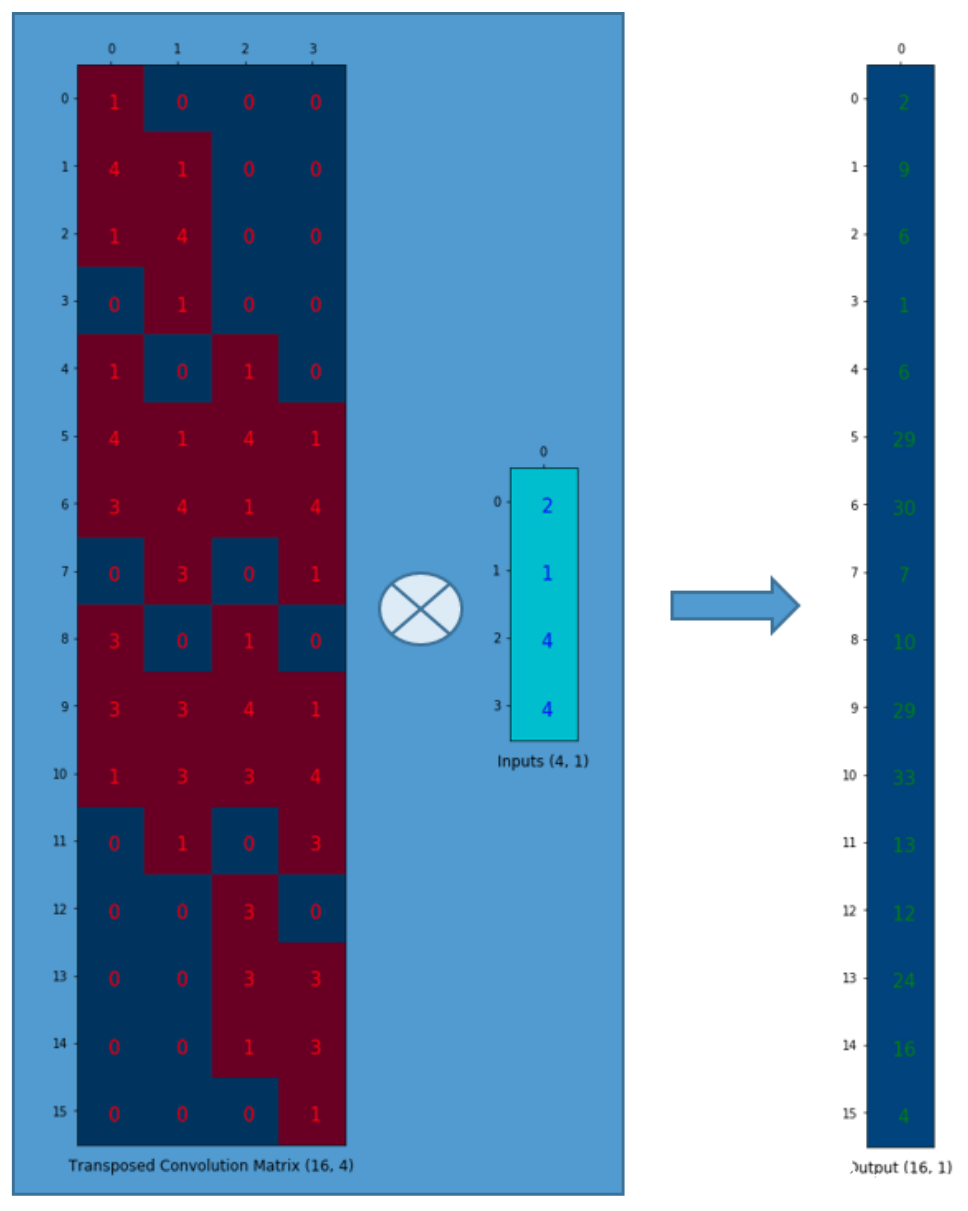
output矩陣可以被重排為4x4的.

我們已經上采樣了一個小矩陣(2x2),得到了一個大矩陣(4x4)。轉置卷積依然維護著1對9的關系:因為權重就是這么排的。
注意:用來進行轉置卷積的權重矩陣不一定來自于(come from)原卷積矩陣。重點是權重矩陣的形狀和轉置后的卷積矩陣相同。
總結
轉置卷積和普通卷積有相同的本質:建立了一些值之間的關系。只不過,轉置卷積所建立的這個關系與普通卷積所建立的關系,方向相反。
我們可以使用轉置卷積來進行上采樣。并且,轉置卷積中的權重是可以被學習的。因此,我們沒有必要搞什么插值方法來做上采樣。
盡管它被稱作轉置卷積,但是這并不意味著我們是拿一個已有的卷積矩陣的轉置來作為權重矩陣的來進行轉置卷積操作的. 和普通卷積相比,intput和output的關系被反向處理(轉置卷積是1對多,而不是普通的多對1),才是轉置卷積的本質。
正因如此,嚴格來說轉置卷積其實并不算卷積。但是我們可以把input矩陣中的某些位置填上0并進行普通卷積來獲得和轉置卷積相同的output矩陣。你可以發現有一大把文章說明如何使用這種方法實現轉置卷積。然而,因為需要在卷積操作之前,往input中填上許多的0,這種方法其實有點效率問題.
警告:轉置卷積會在生成的圖像中造成棋盤效應(checkerboard artifacts)。本文推薦在使用轉置卷積進行上采樣操作之后再過一個普通的卷積來減輕此類問題。如果你主要關心如何生成沒有棋盤效應的圖像,需要讀一讀paper。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100565 -
cnn
+關注
關注
3文章
351瀏覽量
22178
發布評論請先 登錄
相關推薦
卷積神經網絡CNN圖解

卷積神經網絡CNN架構分析-LeNet

卷積神經網絡CNN架構分析 - LeNet
深入理解深度學習中的反(轉置)卷積






 工商網監
工商網監
評論