") 華為語音處理方法的專利揭秘
華為語音處理方法的專利揭秘
華為的該項技術(shù)當中,語音系統(tǒng)為多個NLP引擎的每一個識別結(jié)果進行打分,最后確定一個或多個識別結(jié)果以及輸出次序,并按次序向用戶輸出該一個或多個識別結(jié)果,可以實現(xiàn)對引擎的篩選,做到優(yōu)中選優(yōu)。
華為在2013年1月提出了一種語音處理方法,并提供了系統(tǒng)和終端。該發(fā)明可以利用到多個廠商的技術(shù),從而可以根據(jù)實際需求得到各種側(cè)重點不同的搜索結(jié)果。
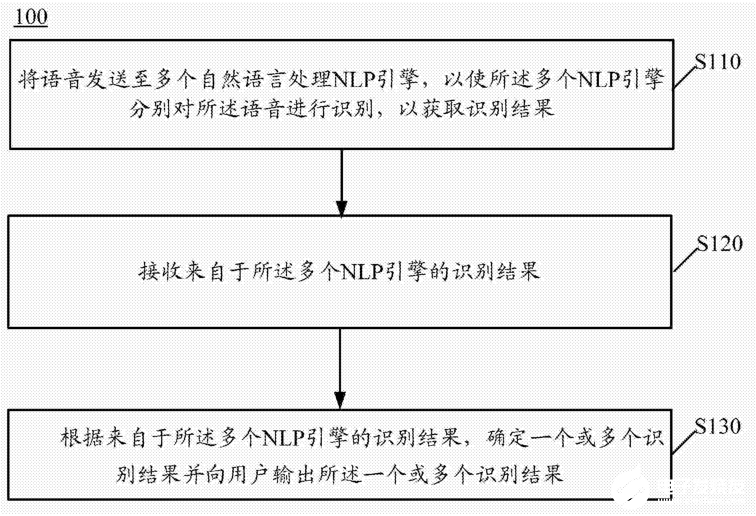
圖1
圖1所示為語音處理方法的系統(tǒng)框圖。S110在獲取一個錄音片段流之后,可以將該錄音片段流發(fā)送至多個自然語言處理NLP引擎,其中,NLP引擎處理的錄音片段流可以由終端直接發(fā)送,也可以通過代理服務器獲取。
每個NLP引擎收到錄音片段流之后即可進行識別,進而獲取一個或多個識別結(jié)果,并對每一個識別結(jié)果進行打分,最后將獲取到的識別結(jié)果以及每一個識別結(jié)果的分數(shù)發(fā)送給終端。
具體地,在接收到來自于多個NLP引擎中的識別結(jié)果之后,打分系統(tǒng)可以對NLP引擎的本次識別結(jié)果進行打分。一方面,打分系統(tǒng)可以根據(jù)每一個NLP引擎的響應時間、給出識別結(jié)果的多少或識別結(jié)果的離散程度,對每一次識別結(jié)果進行打分,并根據(jù)總分對識別結(jié)果進行排序。另一方面,用戶可以根據(jù)實際需求,設(shè)定不同的得分權(quán)重來控制總得分中各項得分的比例。
S130根據(jù)來自于多個NLP引擎的識別結(jié)果,確定一個或多個識別結(jié)果以及輸出次序向用戶輸出(例如,通過顯示器或揚聲器向用戶輸出),供用戶選擇。
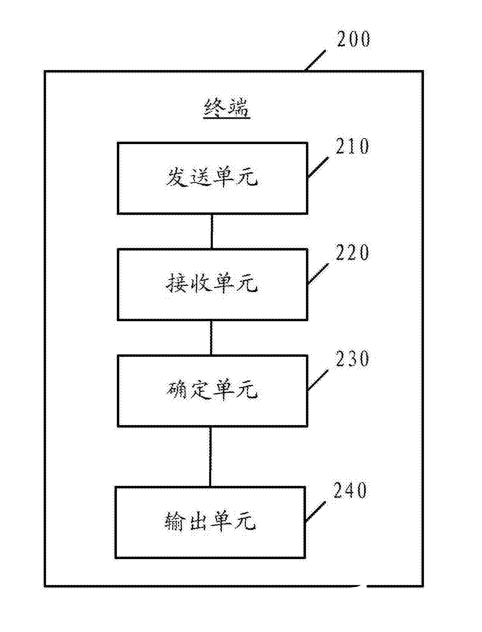
圖2
圖2所示為終端200的示意性框圖,發(fā)送單元210將語音發(fā)送至多個NLP引擎進行識別,以獲取識別結(jié)果。
接收單元220接收多個NLP引擎的識別結(jié)果之后,由確定單元230對NLP引擎的每一個識別結(jié)果進行打分,并確定一個或多個識別結(jié)果以及輸出次序。
輸出單元240根據(jù)輸出次序向用戶輸出一個或多個識別結(jié)果。
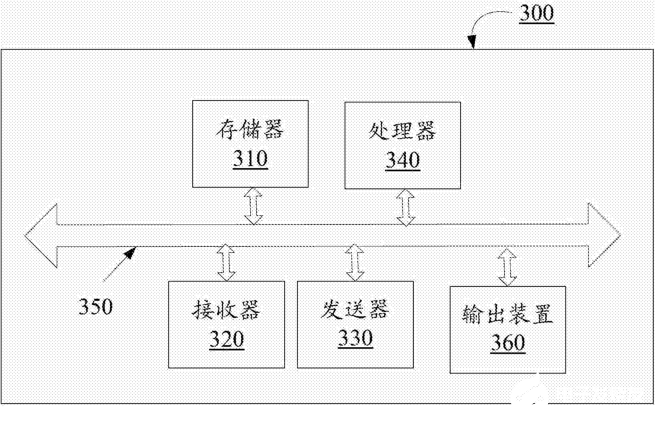
圖3
圖3所示為終端300的示意性框圖,存儲器310存儲一組程序代碼,處理器340調(diào)用存儲器310存儲的程序代碼,執(zhí)行以下操作:
將語音通過發(fā)送器330發(fā)送至多個NLP引擎進行識別,以獲取識別結(jié)果;
接收器320接收來自于多個NLP引擎的識別結(jié)果;
處理器340對每一個識別結(jié)果進行打分,確定一個或多個識別結(jié)果以及輸出次序;
輸出裝置360根據(jù)輸出次序向用戶輸出識別結(jié)果。
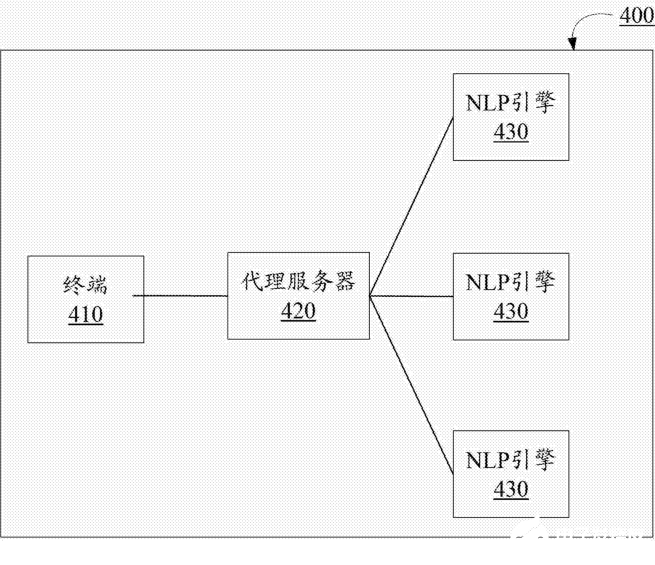
圖4
圖4是語音處理系統(tǒng)400的示意性框圖。終端410即為上文介紹的終端200和終端300。圖中的多個引擎430接收終端發(fā)送的語音后,對語音進行識別,以獲取識別結(jié)果,并將獲取的識別結(jié)果發(fā)送至終端。代理服務器430用于接收終端發(fā)送的語音,并將所述語音轉(zhuǎn)發(fā)至多個NLP引擎。
在該發(fā)明中,通過將語音發(fā)送至多個NLP引擎,使多個NLP引擎分別對語音進行識別,以獲取識別結(jié)果;接收來自多個NLP引擎的識別結(jié)果;根據(jù)來自多個引擎的識別結(jié)果,向用戶輸出可供用戶選擇的識別結(jié)果,可以使多個NLP引擎為用戶的一段語音進行處理。該發(fā)明可以利用到多個廠商的技術(shù),從而得到各種側(cè)重不同的結(jié)果。
在上述系統(tǒng)中,系統(tǒng)可以為多個NLP引擎的每一個識別結(jié)果進行打分,最后確定一個或多個識別結(jié)果以及輸出次序,并按次序向用戶輸出一個或多個識別結(jié)果,可以實現(xiàn)對引擎的篩選,做到優(yōu)中選優(yōu)。
-
華為
+關(guān)注
關(guān)注
215文章
34294瀏覽量
251183 -
語音系統(tǒng)
+關(guān)注
關(guān)注
1文章
27瀏覽量
12992
發(fā)布評論請先 登錄
相關(guān)推薦
華為公司在3GPP中的地位和作用及在3G專利方面的進展
處理語音業(yè)務掉話問題有哪些方法?
華為公開“電池管理系統(tǒng)、健康狀態(tài)估算方法”專利
揭秘華為語音助手的獨家語音喚醒技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論