 關于C程序源代碼是如何在硬件上運行的?
關于C程序源代碼是如何在硬件上運行的?
要把我們編寫的一個C程序源代碼轉換成可以在硬件上運行的程序(可執行代碼:hex/bin等),需要進行編譯和鏈接。
編譯:把文本形式源代碼翻譯為機器語言形式的目標文件的過程。
鏈接:把目標文件、操作系統的啟動代碼和用到的庫文件進行組織形成最終生成可執行代碼的過程。
從下圖可以看到,整個代碼的編譯過程分為編譯和鏈接兩個過程,編譯對應圖中的大括號括起的部分,其余則為鏈接過程。
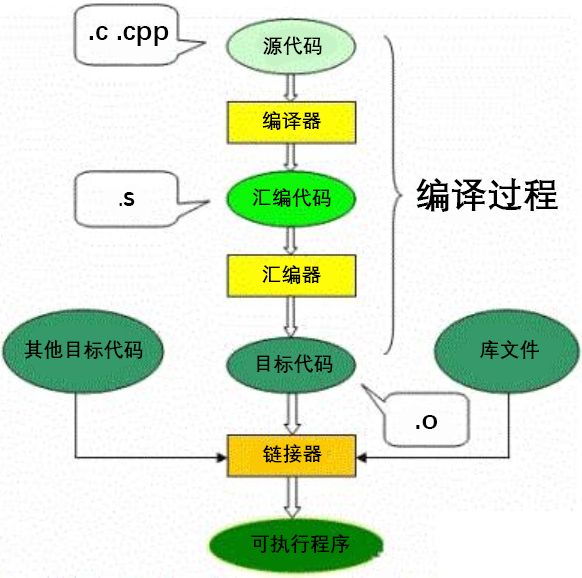
編譯過程又可以分成兩個階段:編譯和匯編。
一、編譯
編譯是讀取源程序(字符流),對之進行詞法和語法的分析,將高級語言指令轉換為功能等效的匯編代碼,源文件的編譯過程包含兩個主要階段:
1.預處理階段
第一個階段是預處理階段,在正式的編譯階段之前進行。預處理階段將根據已放置在文件中的預處理指令來修改源文件的內容。如#include指令就是一個預處理指令,它把頭文件的內容添加到.cpp文件中。這個在編譯之前修改源文件的方式提供了很大的靈活性,以適應不同的計算機和操作系統環境的限制。
一個環境需要的代碼跟另一個環境所需的代碼可能有所不同,因為可用的硬件或操作系統是不同的。在許多情況下,可以把用于不同環境的代碼放在同一個文件中,再在預處理階段修改代碼,使之適應當前的環境。
主要是以下幾方面的處理:
a.宏定義指令
如 #define a b
對于這種偽指令,預編譯所要做的是將程序中的所有a用b替換,但作為字符串常量的 a則不被替換。還有 #undef,則將取消對某個宏的定義,使以后該串的出現不再被替換。
b.條件編譯指令
如#ifdef,#ifndef,#else,#elif,#endif等
這些偽指令的引入使得程序員可以通過定義不同的宏來決定編譯程序對哪些代碼進行處理。預編譯程序將根據有關的文件,將那些不必要的代碼過濾掉。
c.頭文件包含指令
如#include "FileName"或者#include等
在頭文件中一般用偽指令#define定義了大量的宏(最常見的是字符常量),同時包含有各種外部符號的聲明。采用頭文件的目的主要是為了使某些定義可以供多個不同的C源程序使用。因為在需要用到這些定義的C源程序中,只需加上一條#include語句即可,而不必再在此文件中將這些定義重復一遍。
預編譯程序將把頭文件中的定義統統都加入到它所產生的輸出文件中,以供編譯程序對之進行處理。包含到c源程序中的頭文件可以是系統提供的,這些頭文件一般被放在 /usr/include目錄下。
在程序中#include它們要使用尖括號(< >)。另外開發人員也可以定義自己的頭文件,這些文件一般與c源程序放在同一目錄下,此時在#include中要用雙引號("")。
d.特殊符號
預編譯程序可以識別一些特殊的符號
例如在源程序中出現的LINE標識將被解釋為當前行號(十進制數),FILE則被解釋為當前被編譯的C源程序的名稱。預編譯程序對于在源程序中出現的這些串將用合適的值進行替換。
預編譯程序所完成的基本上是對源程序的“替代”工作。經過此種替代,生成一個沒有宏定義、沒有條件編譯指令、沒有特殊符號的輸出文件。這個文件的含義同沒有經過預處理的源文件是相同的,但內容有所不同。下一步,此輸出文件將作為編譯程序的輸出而被翻譯成為機器指令。
2.編譯優化階段
第二個階段編譯、優化階段,經過預編譯得到的輸出文件中,只有常量;如數字、字符串、變量的定義,以及c語言的關鍵字,如main,if,else,for,while,{,}, +,-,*,等等。
編譯程序所要作得工作就是通過詞法分析和語法分析,在確認所有的指令都符合語法規則之后,將其翻譯成等價的中間代碼表示或匯編代碼。
優化處理是編譯系統中一項比較艱深的技術。它涉及到的問題不僅同編譯技術本身有關,而且同機器的硬件環境也有很大的關系。優化一部分是對中間代碼的優化。這種優化不依賴于具體的計算機。另一種優化則主要針對目標代碼的生成而進行的。
對于前一種優化,主要的工作是刪除公共表達式、循環優化(代碼外提、強度削弱、變換循環控制條件、已知量的合并等)、復寫傳播,以及無用賦值的刪除,等等。
后一種類型的優化同機器的硬件結構密切相關,最主要的是考慮是如何充分利用機器的各個硬件寄存器存放的有關變量的值,以減少對于內存的訪問次數。另外,如何根據機器硬件執行指令的特點(如流水線、RISC、CISC、VLIW等)而對指令進行一些調整使目標代碼比較短,執行的效率比較高,也是一個重要的研究課題。
二、匯編
匯編實際上指把匯編語言代碼翻譯成目標機器指令的過程。對于被翻譯系統處理的每一個C語言源程序,都將最終經過這一處理而得到相應的目標文件。目標文件中所存放的也就是與源程序等效的目標的機器語言代碼。目標文件由段組成。通常一個目標文件中至少有兩個段:
代碼段:該段中所包含的主要是程序的指令。該段一般是可讀和可執行的,但一般卻不可寫。
數據段:主要存放程序中要用到的各種全局變量或靜態的數據。一般數據段都是可讀,可寫,可執行的。
1.UNIX環境下的三種目標文件
可重定位文件:其中包含有適合于其它目標文件鏈接來創建一個可執行的或者共享的目標文件的代碼和數據。
共享的目標文件:這種文件存放了適合于在兩種上下文里鏈接的代碼和數據。第一種是鏈接程序可把它與其它可重定位文件及共享的目標文件一起處理來創建另一個 目標文件;第二種是動態鏈接程序將它與另一個可執行文件及其它的共享目標文件結合到一起,創建一個進程映象。
可執行文件:它包含了一個可以被操作系統創建一個進程來執行之的文件。匯編程序生成的實際上是第一種類型的目標文件。對于后兩種還需要其他的一些處理方能得到,這個就是鏈接程序的工作了。
2.鏈接過程
由匯編程序生成的目標文件并不能立即就被執行,其中可能還有許多沒有解決的問題。
例如,某個源文件中的函數可能引用了另一個源文件中定義的某個符號(如變量或者函數調用等);在程序中可能調用了某個庫文件中的函數,等等。所有的這些問題,都需要經鏈接程序的處理方能得以解決。
鏈接程序的主要工作就是將有關的目標文件彼此相連接,也即將在一個文件中引用的符號同該符號在另外一個文件中的定義連接起來,使得所有的這些目標文件成為一個能夠誒操作系統裝入執行的統一整體。
根據開發人員指定的同庫函數的鏈接方式的不同,鏈接處理可分為兩種:
靜態鏈接:在這種鏈接方式下,函數的代碼將從其所在地靜態鏈接庫中被拷貝到最終的可執行程序中。這樣該程序在被執行時這些代碼將被裝入到該進程的虛擬地址空間中。靜態鏈接庫實際上是一個目標文件的集合,其中的每個文件含有庫中的一個或者一組相關函數的代碼。
動態鏈接:在此種方式下,函數的代碼被放到稱作是動態鏈接庫或共享對象的某個目標文件中。鏈接程序此時所作的只是在最終的可執行程序中記錄下共享對象的名字以及其它少量的登記信息。在此可執行文件被執行時,動態鏈接庫的全部內容將被映射到運行時相應進程的虛地址空間。動態鏈接程序將根據可執行程序中記錄的信息找到相應的函數代碼。
對于可執行文件中的函數調用,可分別采用動態鏈接或靜態鏈接的方法。使用動態鏈接能夠使最終的可執行文件比較短小,并且當共享對象被多個進程使用時能節約一些內存,因為在內存中只需要保存一份此共享對象的代碼。但并不是使用動態鏈接就一定比使用靜態鏈接要優越。在某些情況下動態鏈接可能帶來一些性能上損害。
我們在Linux使用的gcc編譯器便是把以上的幾個過程進行捆綁,使用戶只使用一次命令就把編譯工作完成,這的確方便了編譯工作,但對于初學者了解編譯過程就很不利了,下圖便是gcc代理的編譯過程:
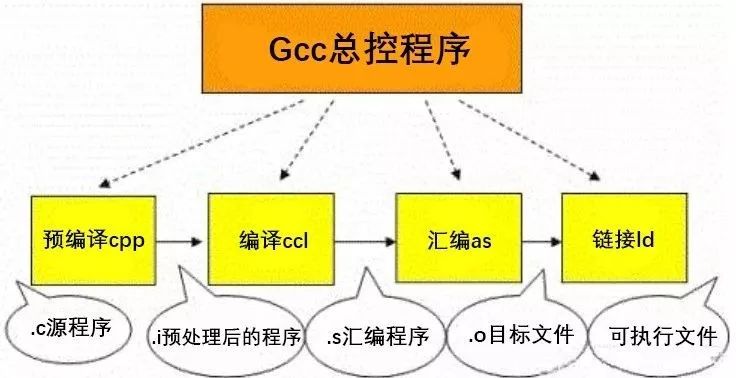
從上圖可以看到:
預編譯:
將.c 文件轉化成 .i文件
使用的gcc命令是:gcc –E
對應于預處理命令:cpp
編譯:
將.c/.h文件轉換成.s文件
使用的gcc命令是:gcc –S
對應于編譯命令是:cc –S
匯編:
將.s 文件轉化成 .o文件
使用的gcc 命令是:gcc –c
對應于匯編命令是:as
鏈接:
將.o文件轉化成可執行程序
使用的gcc 命令是:gcc
對應于鏈接命令是:ld
三、結語總結起來編譯過程就上面的四個過程:預編譯、編譯、匯編、鏈接。 了解這四個過程中所做的工作,對我們理解頭文件、庫等的工作過程是有幫助的,而且清楚的了解編譯鏈接過程還對我們在編程時定位錯誤,以及編程時盡量調動編譯器的檢測錯誤會有很大的幫助的。
-
編程
+關注
關注
88文章
3592瀏覽量
93596 -
源代碼
+關注
關注
96文章
2944瀏覽量
66670 -
C程序
+關注
關注
4文章
254瀏覽量
35996
發布評論請先 登錄
相關推薦
源代碼解析工具與自動化流程圖生成解決方案
hex可以轉成源代碼么
為什么安秉信息的源代碼防泄密軟件這么穩定?






 工商網監
工商網監
評論