") 計算機視覺的損失函數(shù)是什么?
計算機視覺的損失函數(shù)是什么?
導(dǎo)讀
損失函數(shù)在模型的性能中起著關(guān)鍵作用。選擇正確的損失函數(shù)可以幫助你的模型學(xué)習(xí)如何將注意力集中在數(shù)據(jù)中的正確特征集合上,從而獲得最優(yōu)和更快的收斂。
計算機視覺是計算機科學(xué)的一個領(lǐng)域,主要研究從數(shù)字圖像中自動提取信息。
在過去的十年中,在深度學(xué)習(xí)方面的創(chuàng)新,大量數(shù)據(jù)的方便獲取以及GPU的使用已經(jīng)將計算機視覺領(lǐng)域推到了聚光燈下。它甚至開始在一些任務(wù)中實現(xiàn)“超人”的性能,比如人臉識別和手寫文本識別。(事實上,如今登機的自動人臉驗證已經(jīng)變得越來越普遍了。)
近年來,我們在網(wǎng)絡(luò)架構(gòu)、激活函數(shù)、損失函數(shù)等計算機視覺領(lǐng)域看到了許多創(chuàng)新。
損失函數(shù)在模型的性能中起著關(guān)鍵作用。選擇正確的損失函數(shù)可以幫助你的模型學(xué)習(xí)如何將注意力集中在數(shù)據(jù)中的正確特征集合上,從而獲得最優(yōu)和更快的收斂。
這篇文章的主要目的是總結(jié)一些重要的損失函數(shù)在計算機視覺中的使用。
你可以在這里:https://github.com/sowmyay/medium/blob/master/CV-LossFunctions.ipynb找到這里討論的所有損失函數(shù)的PyTorch實現(xiàn)。
Pixel-wise損失函數(shù)
顧名思義,這種損失函數(shù)計算預(yù)測圖像和目標(biāo)圖像的像素間損失。損失函數(shù),如MSE或L2損失、MAE或L1損失、交叉熵損失等,大部分都可以應(yīng)用于在目標(biāo)變量的每一對像素之間進行預(yù)測。
由于這些損失函數(shù)分別對每個像素向量的類預(yù)測進行評估,然后對所有像素進行平均,因此它們斷言圖像中的每個像素都具有相同的學(xué)習(xí)能力。這在圖像的語義分割中特別有用,因為模型需要學(xué)習(xí)像素級的密集預(yù)測。
在U-Net等模型中也使用了這些損失函數(shù)的變體,在用于圖像分割時采用加權(quán)的像素級交叉熵損失來處理類間不平衡問題。
類不平衡是像素級分類任務(wù)中常見的問題。當(dāng)圖像數(shù)據(jù)中的各種類不平衡時,就會出現(xiàn)這種情況。由于像素方面的損失是所有像素損失的平均值,因此訓(xùn)練會被分布最多的類來主導(dǎo)。
Perceptual損失函數(shù)
Johnson et al (2016),Perceptual損失函數(shù)用于比較看起來相似的兩個不同的圖像,就像相同的照片,但移動了一個像素或相同的圖像使用了不同的分辨率。在這種情況下,雖然圖像非常相似,pixel-wise損失函數(shù)將輸出一個大的誤差值。而Perceptual損失函數(shù)比較圖像之間的高級感知和語義差異。
考慮一個圖像分類網(wǎng)絡(luò)如VGG,已經(jīng)在ImageNet的數(shù)以百萬計的圖像數(shù)據(jù)集上訓(xùn)練過,第一層的網(wǎng)絡(luò)往往提取底層的特征(如線,邊緣或顏色漸變)而最后的卷積層應(yīng)對更復(fù)雜的概念(如特定的形狀和模式)。根據(jù)Johnson等人的觀點,這些在前幾層捕獲的低層次特征對于比較非常相似的圖像非常有用。
例如,假設(shè)你構(gòu)建了一個網(wǎng)絡(luò)來從輸入圖像重構(gòu)一個超分辨圖像。在訓(xùn)練期間,你的目標(biāo)圖像將是輸入圖像的超分辨率版本。你的目標(biāo)是比較網(wǎng)絡(luò)的輸出圖像和目標(biāo)圖像。為此,我們將這些圖像通過一個預(yù)先訓(xùn)練好的VGG網(wǎng)絡(luò)傳遞,并提取VGG中前幾個塊的輸出值,從而提取圖像的底層特征信息。這些低級的特征張量可以通過簡單的像素級損失來進行比較。
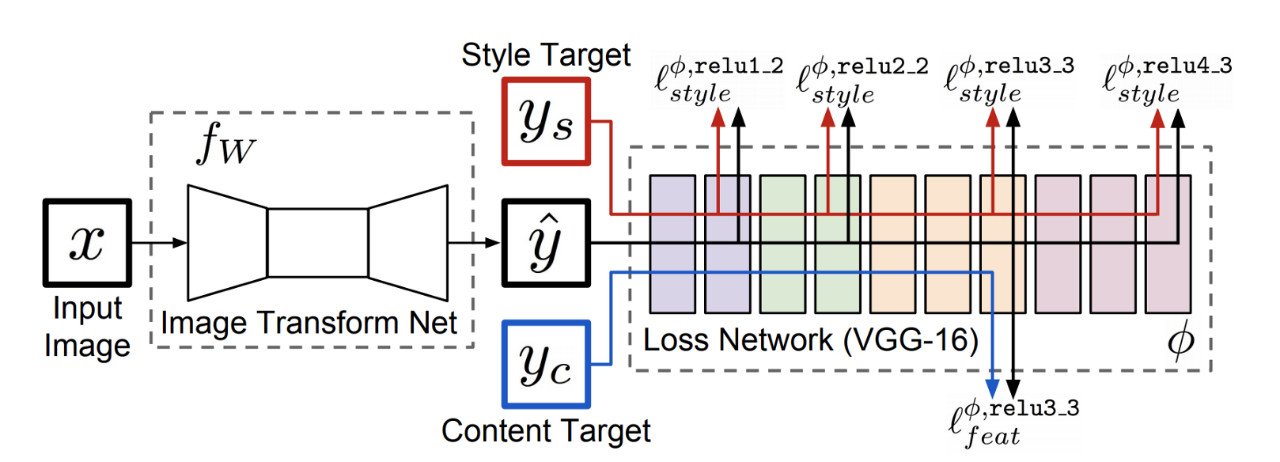
用于圖像分類的預(yù)訓(xùn)練的損失網(wǎng)絡(luò)
Perceptual損失的數(shù)學(xué)表示
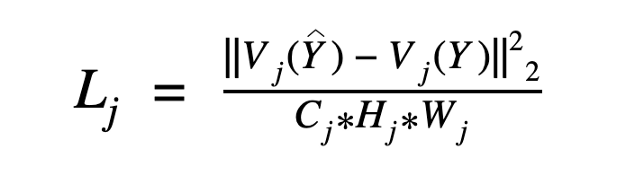
其中,V_j(Y)表示VGG網(wǎng)絡(luò)第j層在處理圖像Y時的激活情況,其形狀為(C_j, H_j, W_j)。我們使用L2損失的平方,根據(jù)圖像的形狀歸一化,比較了ground truth圖像Y和預(yù)測圖像Y^的激活情況。
如果你想使用VGG網(wǎng)絡(luò)的多個特征映射作為你的損失計算的一部分,只需為多個j添加L_j值。
內(nèi)容-風(fēng)格損失函數(shù)—神經(jīng)網(wǎng)絡(luò)風(fēng)格轉(zhuǎn)換
風(fēng)格轉(zhuǎn)換是將圖像的語義內(nèi)容轉(zhuǎn)換成不同風(fēng)格的過程。風(fēng)格轉(zhuǎn)換模型的目標(biāo)是,給定一個內(nèi)容圖像(C)和一個風(fēng)格圖像(S),生成包含C的內(nèi)容和S的風(fēng)格的輸出圖像。
在這里,我們將討論content-style損失函數(shù)的最簡單實現(xiàn)之一,該函數(shù)用于訓(xùn)練這種風(fēng)格的轉(zhuǎn)換模型。后來的研究中使用了許多內(nèi)容-風(fēng)格損失函數(shù)的變體。下一節(jié)將討論一個這樣的損失函數(shù),稱為“紋理損失”。
內(nèi)容/風(fēng)格損失的數(shù)學(xué)表示
已經(jīng)發(fā)現(xiàn),CNNs在較高的層次上捕獲內(nèi)容的信息,而較低的層次更關(guān)注單個像素值。
因此,我們使用一個或多個CNN頂層,計算原始內(nèi)容圖像(C)和預(yù)測輸出(P) 的激活圖。
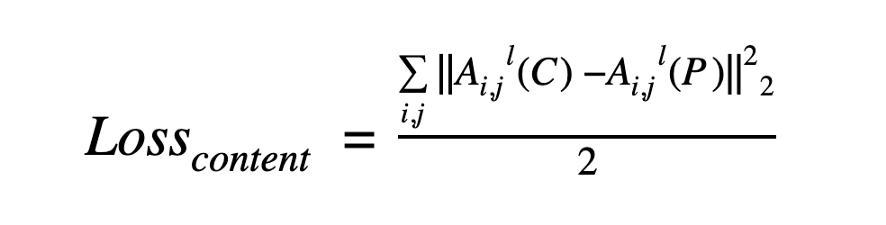
同樣,通過計算預(yù)測圖像(P)和風(fēng)格圖像(S)的下一級特征圖的L2距離,可以計算出風(fēng)格損失,得到的損失函數(shù)定義為:

alpha和beta是超參數(shù)。
注意:只有減少樣式和內(nèi)容損失的優(yōu)化會導(dǎo)致高像素化和噪聲輸出。為了解決這個問題,我們引入了total variation loss來保證生成的圖像的空間連續(xù)性和平滑性。
紋理損失
Gatys et al (2016)首次引入的用于圖像風(fēng)格轉(zhuǎn)換的風(fēng)格損失組件。紋理損失是一種引入的損失函數(shù),是對感知損失的改進,特別適用于捕獲圖像的風(fēng)格。Gatys et al發(fā)現(xiàn),我們可以通過查看激活或特征圖(來自VGG網(wǎng)絡(luò))內(nèi)的值的空間相關(guān)性來提取圖像的風(fēng)格表示。這是通過計算Gram矩陣來實現(xiàn)的:
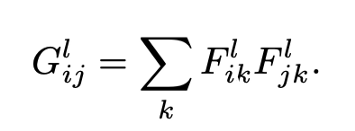
Gram矩陣(對于VGG網(wǎng)絡(luò)的l層)是向量化特征映射F_i和F_j(在l層)的內(nèi)積,它捕捉了特征在圖像不同部分同時出現(xiàn)的趨勢。
紋理損失的數(shù)學(xué)表示
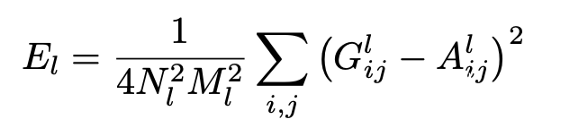
這里,G^l^和A^l^分別是模型輸出的l層和目標(biāo)圖像的l層的風(fēng)格樣式表示。N~l~是層l中不同特征映射的數(shù)量,M~l~是層l(i)中特征映射的容量(也就是通道的寬和高)。最后,E~l~是圖層l的紋理損失。
網(wǎng)絡(luò)的紋理損失是所有紋理損失的加權(quán)和,表示為:
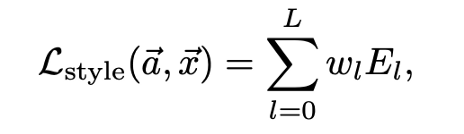
這里a是原始圖像,x是預(yù)測圖像。
注意:雖然這里的數(shù)學(xué)看起來有點復(fù)雜,但請理解紋理損失只是應(yīng)用在特征圖的gram矩陣上的感知損失。
拓撲感知損失函數(shù)
Mosinska等人(2017)介紹了最近文獻中另一個有趣的損失函數(shù),即拓撲感知損耗函數(shù)。這可以被認為是感知損失的延伸,應(yīng)用于分割mask預(yù)測。
Mosinska等人認為,在圖像分割問題中使用的像素級損失,如交叉熵損失,只依賴于局部測度,而不考慮拓撲結(jié)構(gòu)的特征,如連接組件或孔的數(shù)量。因此,傳統(tǒng)的分割模型如U-Net往往會對薄的結(jié)構(gòu)進行錯誤的分類。這是因為對薄層像素的錯誤分類在像素損失方面的代價很低。作為對像素損失的改進,他們建議引入一個懲罰項,該懲罰項基于VGG-19網(wǎng)絡(luò)生成的特征圖(類似于感知損失),以考慮拓撲信息。
(c)使用像素級丟失檢測神經(jīng)元膜后獲得的分割,(d)利用拓撲損耗檢測細胞膜后得到的分割
這種方法在從衛(wèi)星圖像中進行道路分割時也特別有用,例如,樹木的遮擋。
拓撲感知損失的數(shù)學(xué)表示
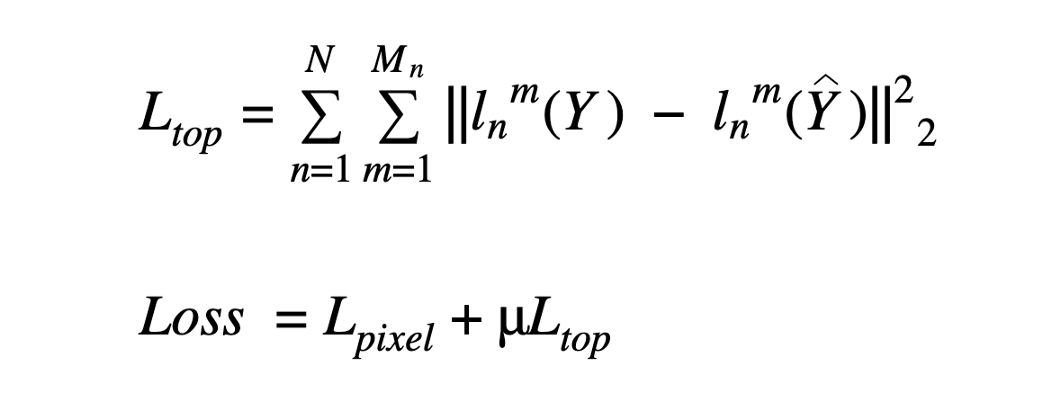
這里,在RHS上,l(m,n)表示VGG19網(wǎng)絡(luò)第n層的第m個feature map。Mu是衡量像素損失和拓撲損失相對重要性的標(biāo)量。
對比損失/三元組損失
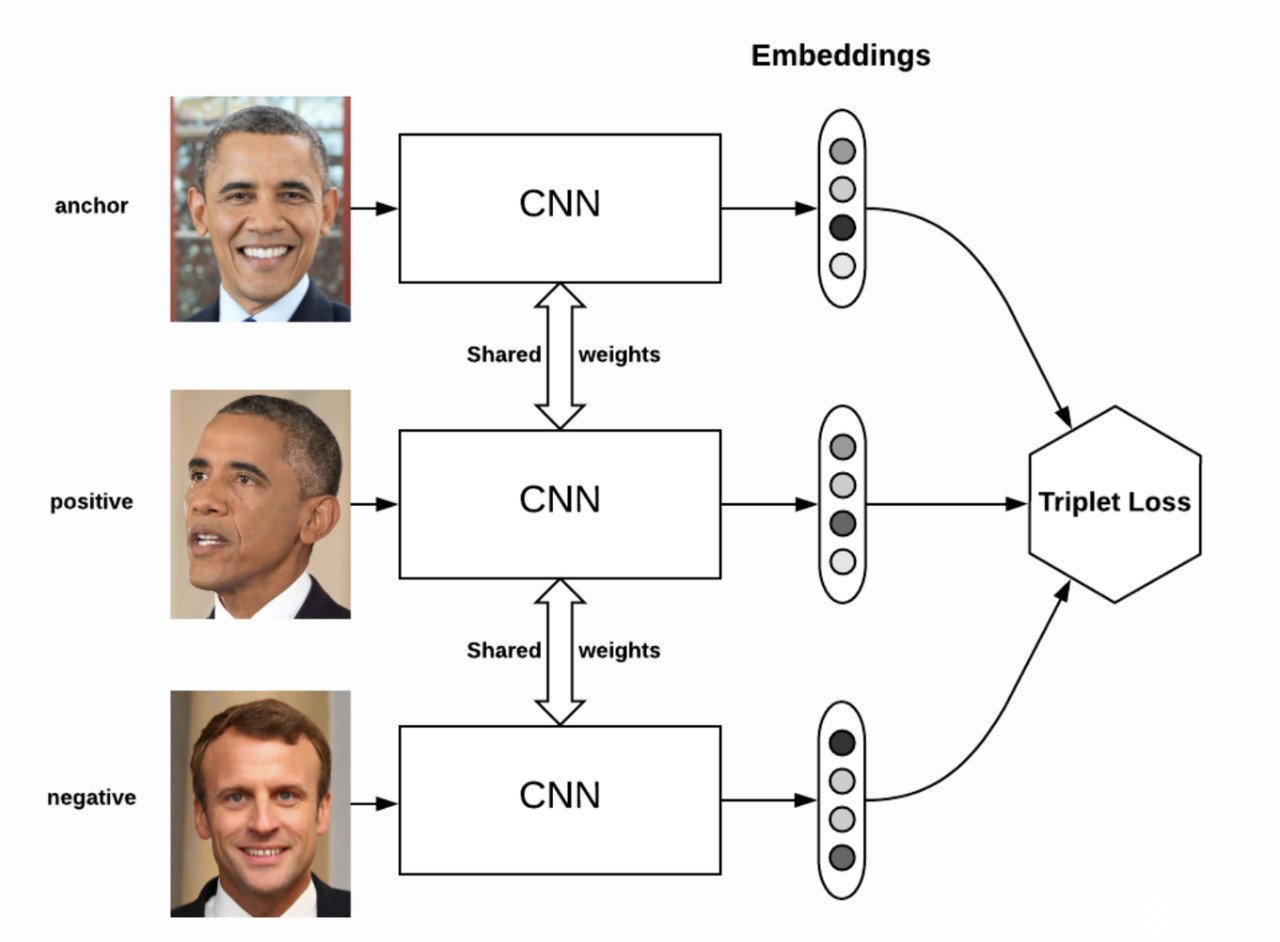
Triplet loss是由Florian Schroff等人在FaceNet(2015)中提出的,其目的是在有限的小數(shù)據(jù)集(如辦公室中的人臉識別系統(tǒng))上構(gòu)建一個人臉識別系統(tǒng)。傳統(tǒng)的CNN人臉識別架構(gòu)在這種情況下總是失敗。
Florian Schroff et al關(guān)注的事實是,在人臉識別的小樣本空間中,我們不僅要正確識別匹配的人臉,還要準(zhǔn)確區(qū)分兩個不同的人臉。為了解決這個問題,F(xiàn)aceNet的論文引入了一個名為“Siamese網(wǎng)絡(luò)”的概念。
在Siamese網(wǎng)絡(luò)中,我們通過網(wǎng)絡(luò)傳遞一個圖像A,并將其轉(zhuǎn)換成一個更小的表示,稱為嵌入。現(xiàn)在,在不更新網(wǎng)絡(luò)的任何權(quán)值或偏差的情況下,我們對不同的圖像B重復(fù)這個過程并提取其嵌入。如果圖像B與圖像A中的人是同一個人,那么它們相應(yīng)的嵌入必須非常相似。如果它們屬于不同的人,那么它們相應(yīng)的嵌入一定是非常不同的。
重申一下,Siamese網(wǎng)絡(luò)的目標(biāo)是確保一個特定的人的圖像(錨點)與同一個人的所有其他圖像(positive)的距離要比與任何其他人的圖像(negative)的距離更近。
為了訓(xùn)練這樣一個網(wǎng)絡(luò),他們引入了三元組損失函數(shù)。考慮一個三元組:[anchor, positive, negative] 。
三元組損失定義為:
1. 定義距離度量d=L2范數(shù)
2. 計算anchor圖像與positive圖像的嵌入距離=d(a, p)
3. 計算anchor圖像嵌入到negative圖像的距離=d(a, n)
4. 三元組損失= d(a, p) - d(a, n) + offset
三元組的數(shù)學(xué)表示
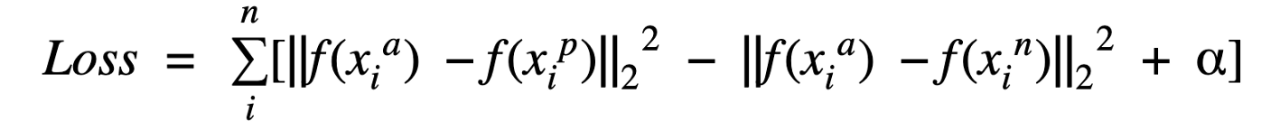
這里, x^a^ -> anchor, x^p^ -> positive,x^n^ -> negative
注:為了快速收斂,必須選取正確的三元組進行損失計算。FaceNet的論文討論了實現(xiàn)這一目標(biāo)的兩種方法——離線三元組生成和在線三元組生成。關(guān)于這個話題的詳細討論我們將留到以后討論。
GAN損失
由Ian Goodfellow等人(https://arxiv.org/abs/1406.2661)(2014)首先提出的生成式對抗網(wǎng)絡(luò)是目前最流行的圖像生成任務(wù)解決方案。GANs的靈感來自博弈論,并使用一個對抗的方案,使它可以用無監(jiān)督的方式訓(xùn)練。
GANs可以被看作是一個兩個人的游戲,我們讓生成器(比如產(chǎn)生一個超分辨率的圖像)與另一個網(wǎng)絡(luò) —— 判別器進行較量。判別器的任務(wù)是評估一個圖像是來自原始數(shù)據(jù)集(真實圖像)還是來自另一個網(wǎng)絡(luò)(假圖像)。判別器模型像任何其他深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)一樣k可以被更新,生成器使用判別器作為損失函數(shù),這意味著生成器的損失函數(shù)是隱式的,是在訓(xùn)練過程中學(xué)習(xí)的。對于典型的機器學(xué)習(xí)模型,收斂可以看作是在訓(xùn)練數(shù)據(jù)集上讓所選損失函數(shù)最小化。在GAN中,收斂標(biāo)志著雙人博弈的結(jié)束,是尋求生成器和判別器損失之間的平衡。
對于GAN來說,生成器和判別器是兩個參與者,它們輪流更新各自的模型權(quán)值。在這里,我們將總結(jié)一些用于GAN網(wǎng)絡(luò)的損失函數(shù)
1. Min-Max損失函數(shù)
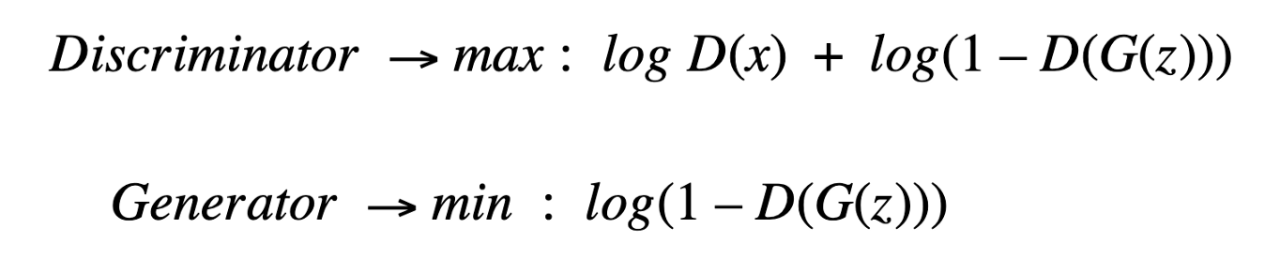
然而,在實踐中發(fā)現(xiàn),這種生成器的損失函數(shù)會飽和。也就是說,如果它不能像判別器學(xué)習(xí)得那么快,判別器贏了,游戲就結(jié)束了,模型就不能得到有效的訓(xùn)練。
2. 不飽和的GAN損失
不飽和GAN損失是一種改進的生成器損失,以克服飽和的問題,使用了一個微妙的變化。該生成器不是最小化所生成圖像的負判別器概率的對數(shù),而是最大化所生成圖像的判別器概率的對數(shù)。
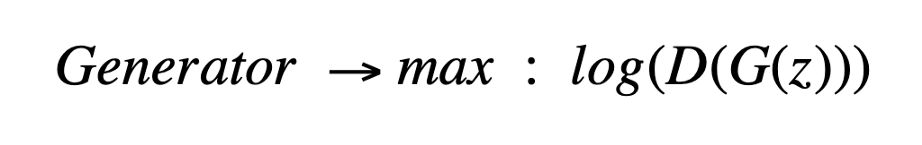
3. 最小均方GAN損失
由Xudong Mao, et al (2016)提出,當(dāng)生成的圖像與真實圖像非常不同時,這種損失函數(shù)特別有用,因為此時會導(dǎo)致梯度非常小或梯度消失,進而導(dǎo)致模型很少或沒有更新。
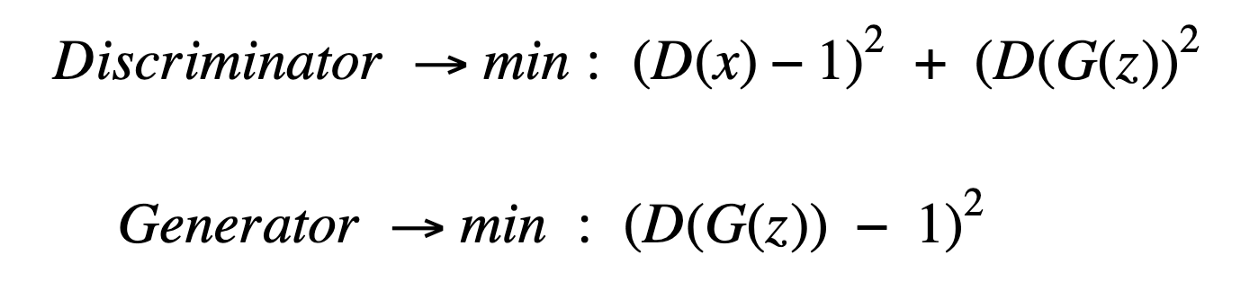
4. Wasserstein GAN損失
Martin Arjovsky等人(2017)。他們觀察到,傳統(tǒng)GAN的目的是最小化真實圖像和生成圖像的實際概率分布和預(yù)測概率分布之間的距離,即所謂的Kullback-Leibler (KL)散度。相反,他們建議在Earth-Mover’s distance上對問題進行建模,該模型根據(jù)將一個分布轉(zhuǎn)換成另一個分布的成本來計算兩個概率分布之間的距離。
使用Wasserstein損失的GAN涉及到將判別器的概念改變?yōu)橐粋€更改評估器,比生成器模型更新得更頻繁(例如,更新頻率是生成器模型的五倍)。評估器用實際的數(shù)字而不是預(yù)測概率來給圖像打分。它還要求模型的權(quán)重保持較小。該得分的計算使得真假圖像的得分之間的距離最大程度地分離。Wasserstein的損失的好處是,它提供了一個有用幾乎無處不在的梯度,允許模型的繼續(xù)訓(xùn)練。
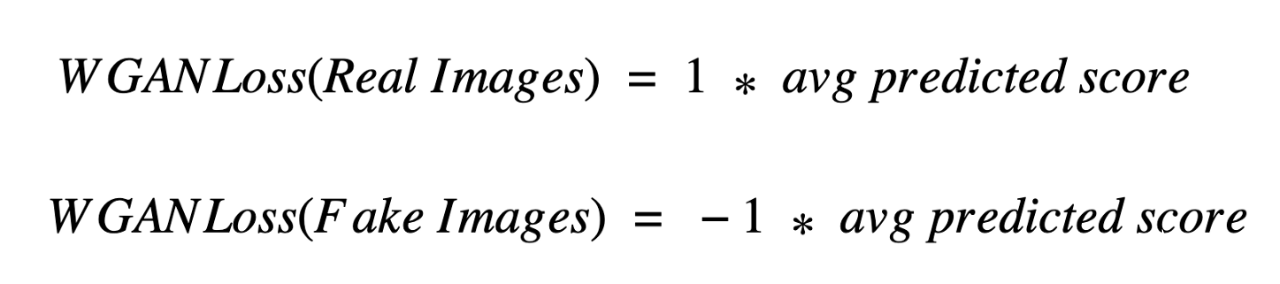
5. 循環(huán)一致性損失
圖像到圖像的轉(zhuǎn)換是一個圖像合成的任務(wù),需要對給定的圖像進行有控制的修改,生成一個新的圖像。例如,把馬轉(zhuǎn)換成斑馬(或反過來),把繪畫轉(zhuǎn)換成照片(或反過來),等等。
juno - yan Zhu et al (2018)介紹。訓(xùn)練用于圖像到圖像轉(zhuǎn)換的模型通常需要大量成對的樣本數(shù)據(jù)集,這些樣本很難找到。CycleGAN是一種不需要配對實例的自動訓(xùn)練技術(shù)。這些模型以一種無監(jiān)督的方式進行訓(xùn)練,使用來自源和目標(biāo)域的圖像集合,這些圖像不需要以任何方式關(guān)聯(lián)。
CycleGAN是GAN體系結(jié)構(gòu)的擴展,它同時訓(xùn)練兩個生成器模型和兩個判別器模型。一個生成器從第一個域獲取圖像作為第二個域的輸入和輸出圖像,另一個生成器從第二個域獲取圖像作為輸入并生成第一個域的圖像。然后使用判別器模型來確定生成的圖像是否可信,并相應(yīng)地更新生成器模型。
循環(huán)一致性是指第一個生成器輸出的圖像可以用作第二個生成器的輸入,而第二個生成器的輸出應(yīng)該與原始圖像匹配。反之亦然。
CycleGAN通過增加額外的損失來測量第二個生成器生成的輸出與原始圖像之間的差異,從而趨向于循環(huán)一致性。該損失作為正則化項用于生成模型,指導(dǎo)新領(lǐng)域的圖像生成過程向圖像轉(zhuǎn)換方向發(fā)展。
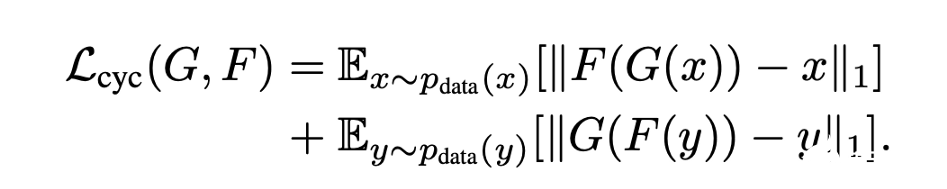
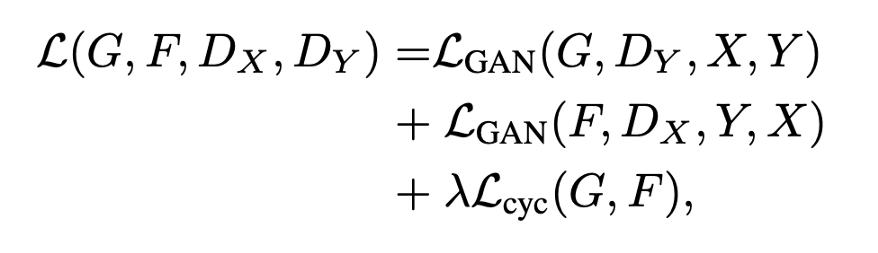
-
gpu
+關(guān)注
關(guān)注
28文章
4701瀏覽量
128708 -
計算機視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45928
發(fā)布評論請先 登錄
相關(guān)推薦
計算機視覺有哪些優(yōu)缺點
機器視覺和計算機視覺有什么區(qū)別
計算機視覺的五大技術(shù)
計算機視覺的工作原理和應(yīng)用
計算機視覺與人工智能的關(guān)系是什么
計算機視覺與智能感知是干嘛的
計算機視覺和機器視覺區(qū)別在哪
計算機視覺和圖像處理的區(qū)別和聯(lián)系
深度學(xué)習(xí)在計算機視覺領(lǐng)域的應(yīng)用
機器視覺與計算機視覺的區(qū)別
計算機視覺的主要研究方向
計算機視覺的十大算法


工業(yè)視覺與計算機視覺的區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論