 PowerVR GPU架構的性能優化建議
PowerVR GPU架構的性能優化建議
最近在看移動GPU優化的時候對TiledBased GPU有一些疑惑,特別是常說的Alpha-Blend比Alpha-Test在移動GPU上快的奇特性質,于是找了powerVR相關的文檔來閱讀,也做個記錄。
Imagination的powerVR架構的GPU之前主要是iOS手機系列的GPU供應商,而蘋果自從17年宣布要逐步放棄使用imagination的GPU技術轉而自主研發GPU開始,powerVR架構就似乎前途未卜。Apple A11處理器開始到最新的iphone XS 使用的A12處理器,都是蘋果自研的GPU,相比起之前的powerVR的GPU有巨大的性能提升。雖然蘋果轉向了自研GPU,但似乎其架構還是繼承于PVR,相應的TBDR也是保留的,所以powerVR架構相關的知識對于iOS的GPU開發依舊還是有用的。同時Metal2提供了一些新的feature如Imageblocks,Raster Order Groups等新feature,這部分是Apple對TBDR架構的加強與優化。
主流圖形架構
Immediate Mode Renderer(IMR)
Tile Based Renderer(TBR)
Tile Based Deferred Renderer(TBDR)
Unified and Non-unified shader architecture
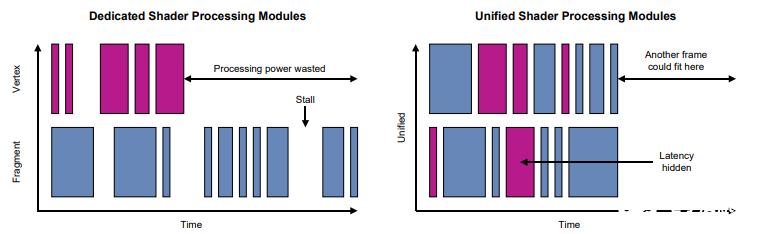
非統一的著色器架構上Vertex Shader要等待Fragment Shader執行完后才能push處理完的頂點數據丟給FS單元。
而統一的著色器架構,處理會減少等待時間,提升性能。PowerVR全部采用的都是Unified Shader Architecture.
Overdraw
由于geometry提交順序的不同,會有一些fragment會被重復繪制。
為了減少overdraw的情形,圖形計算核心會進行Early-Z testing的操作以減少Overdraw。
IMR
每一個渲染對象/drawcall完成了整個渲染管線流程寫入frameBuffer才會開始渲染下一個對象/drawcall。在IMR模式下,Early-Z test可以直接將深度測試的幾何圖元跳過以提升性能,但是Early-Z test依賴渲染繪制對象的提交順序是從前往后的。
同時每一次渲染完的color與depth數據讀取寫回到colorbuffer與depth/stencil buffer是都會產生很大的帶寬消耗。普通的Read-Modify-Write都是在system memory與GPU之間傳輸數據,如ZWrite/Write,Blend這些。所以IMR的架構會有一個很大顯存cache來優化這部分大量的內存帶寬消耗。
TBR
整個光柵化和fragment處理會被分為一個個Tile進行處理,通常為16×16大小的Tile。
TBR的結構添加了on-chip buffers用來儲存tiling后的Depth Buffer和Color buffer。原先IMR架構中對主存中color/depth buffer進行Read-Modify-Write的操作變成直接在GPU中的高速內存操作,減少了最影響性能的系統內存傳輸的開銷。
雖然TBR減少了IMR的帶寬開銷,但是依然沒有解決overdraw的問題。
TBDR
PowerVR的渲染架構 Tile Based Deferred Rendering(TBDR)
數據從內存到GPU之間的傳輸是最大的性能消耗,powerVR架構的TBDR,on-chip buffer都為了該目標而優化。
TBDR 架構關注于在渲染管線中盡可能移除冗余的操作與計算,最小化內存帶寬和能耗同時提升管線處理的吞吐量。
TBDR將每個Tiler的渲染過程拆分為兩個步驟,一個是Hidden Surface Removal(HSR)和 deferred pixel shading。
TBDR會盡可能地延遲pixel shading的時間,直到所有光柵化后的fragment完成了DepthTest和HSR。對于一個場景中全是不透明幾何圖元的渲染畫面來說。每一個光柵化完的fragment patch會經過HSR和Depth test,在所有triangle完成了raster之后,最后留下來的fragment會留下來執行pixel shading。也就是在這種情況下tile中的每一個像素只執行一次pixel shader。
如果渲染流程中有alpha test/blend/pixel depth write,就會阻斷deferred shading,因為這個時候需要執行shading,才能正確進行后續fragment的計算。
Alpha Test需要執行shading 算出當前fragment的alpha,判斷該fragment是否被丟棄。
Alpha Blend 需要讀取framebuffer中當前像素之前的顏色。
Pixel Depth write會影響到后續fragment的HSR與Depth test。
這三種情況下Pixel Depth Write,因為會影響到后續fragment HSR/Depth,所以這個時候一定要執行該像素的shading,打亂了原先deferred的流程。具體要看GPU實現時時把整個HSR步驟積累的fragment都shading掉還是只把當前fragment shading掉。
而對于AlphaBlend來說,它并不一定要打斷deferred shading。
遇到blending的fragment,可以把該fragment像素位置的所有fragment按順序保留在列表中,等到shading時按順序計算blend。
但這樣就會增加pixel shading的次數。具體的實現還是要參照GPU的實現方式,由于使用TBR,Blend的開銷相對比IMR還是降低了很多。
Alpha-Test的情況是和Pixel Depth Write類似,由于Alpha Test失敗fragment會被丟棄,如果其開啟了DepthWrite,那么就一定要執行shading。因為alpha-test會影響后續fragment的HSR/Z-Test的流程。如果沒有開啟depth Write,也可以和Blend一樣保留后續所有fragment的方式來延遲shading。但是這個時候后續該位置的fragment patch都是不能被移出shading列表的,延遲shading也沒有意義了。
關于PowerVR 架構
Vector處理單元
高效計算單元,同時計算3到4個元素。如果一個計算的值小于4個,那么其他的計算會被浪費。只對一個元素進行計算時,效率會降低到25%,造成計算和電能的浪費,可以通過合并vector來優化。
Scalar處理單元
標量計算單元更加靈活,不需要填充其他的位寬數據。每一個硬件tick比起非向量化優化的代碼能處理更多有效的數據值。
Verte Processing (Tiler)
Tile Accelerator(TA)計算每個transform后的圖元屬于哪個tile。
計算完后,per-tile隊列會更新。變換后的幾何體和tile list會被儲存在Parameter Buffer(PB)中。PB被儲存在系統內存中。
Per-Tile Rasterization (Render)
Image Sythesis Processor(ISP)獲取當前tile的primitive數據,進行HSR,同時進行Z-Test和Stencil Test。ISP只處理ScreenSpace Position,和vertex data。
接下來是Texture and Shading Processor (TSP),處理fragment shaders和visible pixels。當Tile的渲染結束之后,color data會被寫回到主存中的framebuffer中。直到所有的tile都完成渲染后,整個frameBuffer就完成了。
PowerVR Shader Engine
massive multi-threaded and multi-tasking approah.
HSR Efficiency
Early-Z testing 需要按從前往后順序提交opaque對象的draw call,需要進行排序會有額外的overhead。當物體有intersection時,Eearly-Z testing并不能移除所有的overdraw,同時對draw call進行排序可能會造成pipeline 狀態改變產生的overhead。
PowerVR 的HSR盡可能減少了fragment shading的數量。
性能優化建議
對drawcall進行排序
對于TBDR架構來說,所有的drawcall 按照 opaque - alpha-tested - blended進行排序會最大程度利用HSR減少overdraw。對于有blend的pixel來說,后續所有相同位置的pixel都需要進行pixel shading,而alpha-test在完成后的像素還是可以繼續進行HSR的優化。所以比先blend提交alpha-test可以盡可能減少overdraw。
始終進行Clear操作
在IMR架構中,進行Clear操作需要對fragment buffer每個像素設置一遍值。如果確認畫面會被完全重繪覆蓋的情況下,不進行Clear操作會有減少這部分的性能開銷。而在移動平臺的GPU上并不是這樣,由于移動平臺為了減少內存與GPU間的帶寬消耗,frameBuffer是分塊存在on-chip memory中的。在整個渲染過程結束后將所有的tiled framebuffer 拷貝到主存中的framebuffer中。如果不進行clear,而在上一幀的buffer上重新繪制,需要在每個tiled frameBuffer開始繪制之前從主存再同步到on-chip的內存中。這一部分會有很大的overhead。
不要在每一幀開始繪制之后更新Buffer
由于GPU繪制采用的是雙緩沖繪制,當前幀提交的draw call會在下一幀進行繪制,而當前幀繪制上一幀提交的draw call。如果在幀中間更新buffer,而這個buffer在上一幀提交的drawcall中被使用,有可能當前幀更新的buffer正在GPU中渲染,而此時驅動層將復制一份buffer來進行數據的更新或者等待當前繪制命令完成再進行更新。這兩種情況一種會造成驅動層的overhead,而另一種會造成CPU的阻塞。
使用壓縮貼圖和Mipmapping
使用壓縮的貼圖格式會減少傳輸的帶寬,從而提升性能。同時由于在TileBased架構下,部分按塊壓縮的貼圖壓縮格式可以和FrameBuffer的Tile進行匹配,其結構對于貼圖緩存來說更加友好。
盡可能使用Mipmapping,首先使用mipmap,對于較遠以及較小的貼圖物體會有更好的抗鋸齒效果,減少畫面的閃爍以提升畫面效果。其次使用在采樣貼圖時,對于不同大小的物體選用其大小相對應層級的貼圖到對應的TextureCache能有效減少貼圖緩存missing的幾率以提升貼圖采樣的效率。同時由于有不同層級的貼圖,會大量減少每次將貼圖從內存復制到GPU的帶寬消耗,同時使用Mipmap只會增加33%的內存消耗。
-
gpu
+關注
關注
28文章
4703瀏覽量
128723 -
powervr
+關注
關注
0文章
98瀏覽量
31053
發布評論請先 登錄
相關推薦
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
NPU與GPU的性能對比
GPU服務器AI網絡架構設計

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
如何優化emc存儲性能
如何優化SOC芯片性能
如何提高GPU性能
智能駕駛用戶體驗優化建議
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
GPU云服務器架構解析及應用優勢
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
深入解讀AMD最新GPU架構
揭秘GPU: 高端GPU架構設計的挑戰






 工商網監
工商網監
評論