 Facebook AI發布了一個包含編碼問題和代碼片段答案的數據集
Facebook AI發布了一個包含編碼問題和代碼片段答案的數據集
Facebook AI發布了一個包含編碼問題和代碼片段答案的數據集,旨在評估基于AI的自然語言代碼搜索系統。該版本還包括Facebook自己的幾種代碼搜索模型的基準測試結果,以及來自24,000個GitHub存儲庫的超過400萬種Java方法的訓練語料庫。
在arXiv上發表的一篇論文中,研究人員描述了他們收集數據的技術。訓練數據語料庫是從最受歡迎的GitHub Android代碼存儲庫中收集的,按星數排序。解析存儲庫中的每個Java文件,以標識各個方法。Facebook在培訓代碼搜索系統的研究中使用了所得的語料庫。為了創建評估數據集,他們從Stack Overflow 的問答數據轉儲開始,僅選擇同時具有“ Java”和“ Android”的問題研究人員說:“其中,他們只保留答案被投票的問題,這些問題也與訓練數據語料庫中確定的一種方法相匹配。結果將518個問題手動過濾為最終的287個問題。研究人員表示:
我們的數據集不僅是當前可用于Java的最大數據集,而且還是唯一以自動化(一致)方式針對Stack Overflow的真實答案進行驗證的數據集。
Facebook最近發表了幾篇關于神經代碼搜索的論文,這是一種用于訓練神經網絡回答“如何”編碼問題的機器學習技術。軟件開發人員通常會使用Stack Overflow來學習如何解決特定的編碼問題,例如,如何解決 Android應用程序中的錯誤。但是,在處理使用專有API或較不常見的編程語言的代碼時,這不是一個選擇。在這種情況下,程序員自己的組織之外的專家很少(或沒有)。相反,Facebook和其他公司探索了使用源代碼本身作為培訓數據來產生可以回答編碼問題的自然語言處理(NLP)系統的想法。
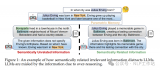
去年,Facebook發表了一篇關于無監督學習方法的論文,稱為神經代碼搜索(NCS),該方法接受了從GitHub收集的數據的培訓。該技術從源代碼中提取單詞,并學習將每個單詞映射到高維空間中的向量的嵌入。嵌入通常具有向量的性質,向量在向量空間中彼此“接近”,表示具有相似含義的詞,并且詞之間的關系可用向量算術表示。一個例子是在Wikipedia上訓練的word2vec模型,當給定向量表達式“ Paris-France + Spain”時,該模型將返回“ Madrid”。
學習了嵌入之后,使用“ 詞袋 ”模型將語料庫中的每個Java方法轉換為嵌入空間中的向量;通過嵌入將代碼中的每個單詞轉換為向量,并將向量的加權總和分配給該方法作為其索引。這會將每個Java方法映射到嵌入空間中的一個點。為了回答編碼問題,通過將查詢中的每個單詞都通過嵌入轉換并產生加權和,可以將該問題類似地映射到嵌入空間中的某個點。問題的“答案”是Java方法,其索引最接近該點。關鍵思想是查詢和代碼都使用相同的嵌入,并且訓練不需要在輸入數據中出現任何問題;它僅從源代碼中學習。
這種技術的一個缺點是它不會學習源代碼中沒有的單詞的嵌入。Facebook研究人員發現,在Stack Overflow上,有問題的單詞中也只有不到一半的單詞包含在源代碼中。這促使研究人員通過監督學習擴展了NCS,“以彌合自然語言單詞和源代碼單詞之間的鴻溝”。產生的系統稱為嵌入統一(UNIF),學習查詢詞的單獨嵌入。在此培訓過程中,團隊使用類似于收集基準數據集的過程從Stack Overflow中提取了一組問題標題和代碼段。該訓練數據集包含451k個問題-答案對,但都不在基準測試中。在基準上進行評估時,對這一數據進行培訓的聯合國系統的性能略優于NCS。兩種系統都以大約三分之一的時間作為最高結果返回“正確”答案,并以一半的時間以“前五項”結果返回“正確”答案。
-
Facebook
+關注
關注
3文章
1429瀏覽量
54658 -
代碼
+關注
關注
30文章
4753瀏覽量
68365 -
數據集
+關注
關注
4文章
1205瀏覽量
24648
發布評論請先 登錄
相關推薦
學習RV32GC對比X86-32指令集的優勢思考
AI大模型的訓練數據來源分析

一個哪夠?是時候讓一群AI替你打工了






 工商網監
工商網監
評論