") Google發(fā)布新API,支持訓練更小更快的AI模型
Google發(fā)布新API,支持訓練更小更快的AI模型
(文章來源:雷鋒網(wǎng))
Google發(fā)布了 Quantification Aware Training(QAT)API,使開發(fā)人員可以利用量化的優(yōu)勢來訓練和部署模型AI模型。通過這個API,可以將輸入值從大集合映射到較小集合的輸出,同時,保持接近原始狀態(tài)的準確性。
新的API的目標是支持開發(fā)更小、更快、更高效的機器學習(ML)模型,這些模型非常適合在現(xiàn)有的設備上運行,例如那些計算資源非常寶貴的中小型企業(yè)環(huán)境中的設備。
通常,從較高精度到較低精度的過程有很多噪聲。因為量化把小范圍的浮點數(shù)壓縮為固定數(shù)量的信息存儲區(qū)中,這導致信息損失,類似于將小數(shù)值表示為整數(shù)時的舍入誤差(例如,在范圍[2.0,2.3]中的所有值都可以在相同的存儲中表示。)。問題在于,當在多個計算中使用有損數(shù)時,精度損失就會累積,這就需要為下一次計算重新標度。
谷歌新發(fā)布的QAT API通過在AI模型訓練過程中模擬低精度計算來解決此問題。在整個訓練過程中,將量化誤差作為噪聲引入,QAT API的算法會嘗試將誤差最小化,以便它學習這個過程中的變量,讓量化有更強的魯棒性。訓練圖是利用了將浮點對象轉(zhuǎn)換為低精度值,然后再將低精度值轉(zhuǎn)換回浮點的操作,從而確保了在計算中引入了量化損失,并確保了進一步的計算也可以模擬低精度。
谷歌在報告中給出的測試結(jié)果顯示,在開源Imagenet數(shù)據(jù)集的圖像分類模型(MobilenetV1 224)上進行測試,結(jié)果顯示未經(jīng)量化的精度為71.03%,量化后的精度達到了71.06%。
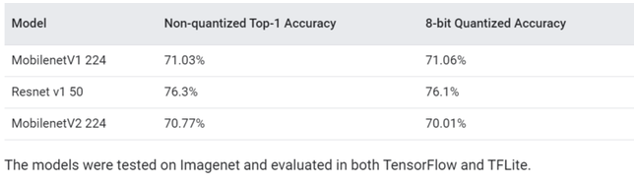
針對相同數(shù)據(jù)集測試的另一種分類模型(Nasnet-Mobile)中測試,在量化后僅有1%的精度損失(74%至73%)。除了模擬精度降低的計算外,QAT API還負責記錄必要的統(tǒng)計信息,以量化訓練整個模型或模型的一部分。比如,這可以使開發(fā)人員能夠通過調(diào)用模型訓練API將模型轉(zhuǎn)換為量化的TensorFlow Lite模型。或者,開發(fā)人員可以在模擬量化如何影響不同硬件后端的準確性的同時嘗試各種量化策略。

Google表示,在默認情況下,作為TensorFlow模型優(yōu)化工具包一部分的QAT API配置為與TensorFlow Lite中提供的量化執(zhí)行支持一起使用,TensorFlow Lite是Google的工具集,旨在將其TensorFlow機器學習框架上構(gòu)建的模型能夠適應于移動設備,嵌入式和物聯(lián)網(wǎng)設備。“我們很高興看到QAT API如何進一步使TensorFlow用戶在其支持TensorFlow Lite的產(chǎn)品中突破有效執(zhí)行的界限,以及它如何為研究新的量化算法和進一步開發(fā)具有不同精度特性的新硬件平臺打開大門”,Google在博客中寫道。
QAT API的正式發(fā)布是在TensorFlow Dev Summit上,也是在發(fā)布了用于訓練量子模型的機器學習框架TensorFlow Quantum之后發(fā)布。谷歌也在會議的會話中預覽了QAT API。
(責任編輯:fqj)
-
谷歌
+關注
關注
27文章
6142瀏覽量
105100 -
API
+關注
關注
2文章
1485瀏覽量
61817
發(fā)布評論請先 登錄
相關推薦
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

Google AI Edge Torch的特性詳解

AI大模型的訓練數(shù)據(jù)來源分析
如何訓練自己的AI大模型
如何訓練ai大模型
ai模型訓練需要什么配置
ai大模型訓練方法有哪些?
ai大模型和ai框架的關系是什么
ai大模型和傳統(tǒng)ai的區(qū)別在哪?
【大語言模型:原理與工程實踐】大語言模型的預訓練
零一萬物正式發(fā)布Yi大模型API開放平臺
谷歌發(fā)布新的AI SDK,簡化Gemini模型與Android應用程序的集成
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”O(jiān)penBuddy-StableLM-3B
Google Cloud 推出 TPU v5p 和 AI Hypercomputer: 支持下一代 AI 工作負載





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論