 基于可編程總線帶寬控制系統的分配方案研究
基于可編程總線帶寬控制系統的分配方案研究
傳統SoC總線架構已不能滿足新的聯網嵌入式設計對高帶寬數據流進行實時控制的需求,NetSilicon開發的可編程總線帶寬控制系統可以使多個資源同時訪問總線,使其既滿足應用要求又不會影響其他重要操作的性能。本文將對該系統的可編程總線帶寬分配方案進行探討。
32位嵌入式設計越來越要求對網絡上高帶寬數據流進行實時控制,特別是在系統級芯片(SoC)層面,以確定性和無爭議的方式傳輸數據和控制信息變得非常重要。各種操作直接處于系統開發者既定的控制之下也很重要,而這在基于總線的SoC設計中并不總是能夠實現。
設計者和芯片供應商常常借鑒板級及系統級架構技術,以便在最短的設計時間內以最低的開發成本進行SoC設計。由于手機和PDA等設備對確定性的實時響應需求很少,所以傳統解決方案在此類應用中表現還不錯。
但在許多新的聯網嵌入式設計中,傳統總線架構不能滿足共享總線對高帶寬及高密度數據流的需求,在下列應用中尤其如此,如工業用人機界面(HMI)網絡顯示、POS終端設備,具有不同數據帶寬需求的彩色打印機、網絡投影儀和監視攝像機,以及網絡打印機、數字復印機、多功能一體機、傳真機和掃描儀等。
許多基于片上串行互連的替代方案正在研發中,這些替代方案類似于串行結構、交叉交換(crossbar switch)和基于數據包的總線。在這些新方案得以完善之前,鑒于時間和成本壓力,必須找到能修改從板級設計借鑒過來的共享總線架構的方法,以滿足新的32位嵌入式聯網設計對確定性和實時性的要求。
傳統SoC總線的優缺點
SoC開發者不愿意放棄這種通用共享總線,因為它可以減少設計周期中的規范制定及驗證工作,能使SoC的高層次集成如同將擴展卡插到背板上一樣簡單。通過采用通用總線,開發者可以集中精力投入到更高層次的決策中。
圖1:NS9xxx的帶寬控制系統。
ARM公司在高級微控制器總線架構(AMBA)中采用通用總線,允許獲得許可的使用者專注于自己的應用開發,從而快速將產品推向市場。
微處理器、DMA控制器、存儲器控制器及其它更高性能的模塊通過AHB連接。性能較低的模塊,比如UART、通用輸入/輸出(GPIO)及定時器等,則通過APB連接。
但是,基于ARM的SoC所瞄準的許多高端嵌入式應用,要求它們在處理這些應用的確定性與實時性需求的同時,還可以訪問高帶寬網絡環境。
這些應用要求SoC能夠發出控制信號、采集數據并在網絡上實時傳輸數據。基于不同的網絡特性及其帶寬要求,現有SoC總線架構的性能將會得到盡可能的提升,例如,高端聯網嵌入式應用可能要處理通過以太網連接從照相機傳輸到打印機的視頻數據位流,或從服務器傳輸到打印機的圖像,與此同時還可能根據與掃描、刷新和更新周期有關的確切要求對本地LCD顯示進行更新。使用外部LCD時,LCD控制器必須知道通過該總線傳輸的具體字節數量、數據發送順序以及數據在顯示器上顯示的特定時隙和順序,同時也很必要將信息不斷地饋送給LCD用于更新。
圖2: NS9750原理框圖。
共享總線的概念并不能滿足SoC中的這些要求。在典型的AHB設計中,總線主控是總線上全部的主要資源,也就是說,當總線空閑時,它們可向總線請求完成一個任務所需要的時間。但在基于ARM的SoC中,程序設計者不能直接控制當它們掌管總線時可得到多少總線資源。
共享總線架構用多種方式來區分這些操作的優先次序,包括:菊花鏈仲裁、集中式并行仲裁、基于自選或沖突監測的分布式仲裁以及帶多個總線請求的總線仲裁。但當指定的主控接管總線后,其他操作就會擱置在一邊。目前還沒有一種機制能夠讓多個資源同時訪問總線,使其既滿足應用要求,又不會影響其他重要操作提供確定性及實時性響應的能力。
在AMBA環境中處理這類情況的一種通用方法是使用仲裁通道。如果有六個總線主控,總線便設計成有六個仲裁通道。但是,片上仲裁邏輯根據請求訪問該總線的主控數目來分配這些通道,而不是把每個通道指定給某個特定的主控。如果有四個主控請求訪問總線,則這六個通道會在這四個主控之間進行分配,確保每個主控有平等的機會訪問該總線。
然而,這并不能解決如何分配足夠的總線帶寬以完成某一特定任務這一基本問題。若其中一個操作需要三個通道,而其它操作總共只需要兩個通道,則每一種操作將會分配到相同數量的可用通道空間。其結果是,有的通道沒有充分利用(甚至根本沒用到),而有的則超負荷使用,影響SoC在極低延遲內對事件進行確定性響應的能力。
可編程總線帶寬控制系統
因此,需要一種可編程的總線帶寬分配方案,在某一特定時刻為某一特定的主控分配其所需的總線配置,并將剩余的總線空間分配給其它可能要求訪問該總線的主控。由于這種方案可能隨時間改變,因此需要一種機制以便按照常規原理重新分配總線資源。
NetSilicon公司已開發一種新的帶寬控制系統來取代采用AMBA架構的帶寬控制系統。該系統采用一個16槽位旋轉優先級總線仲裁器(見圖1),這種仲裁器包含一套可編程偽隨機或旋轉優先級緩存替換算法。例如,在NetSilicon的 NS9750(見圖2)中,AHB上的六個通道不是通過競爭進行分配,而是根據16槽位總線分配方案由六個總線主控分享。通過系統控制模塊中的專用寄存器,系統開發者目前可采用三種方法在SoC中分配總線資源。
在最高層次,某特定總線主控每次發出的一個訪問請求,都會按請求順序得到響應,直到這六個主控全被輪詢。根據所需帶寬,每一個總線主控可分配到一定數目的槽位并獨占這些槽位。例如在NS9750中,四個槽位分配給CPU,四個槽位給以太網,四個槽位給BBus橋,三個槽位給LCD,三個槽位給PCI/卡總線,但在系統運行期間系統軟件會根據需要重新評估這一分配方案,這可用來確定AHB總線周期的數目。如果在下一個評估周期中情況沒有發生變化,則沿用以前的設置,如果情況有變,則協定新的總線主控槽位分配方案。
為對總線資源進行更精確的控制,這種循環仲裁方案提供兩個附加層次的可編程性能:分配給ARM CPU的總線帶寬大小以及這16個槽位中每個槽位的帶寬利用率。
NS9750的ARM926EJ-S內核作為總線主控時不能控制所有總線資源,缺省情況下它只能控制50%的總線帶寬或16個槽位中的8個,這樣可確保其它五個總線主控可以一直占有至少50%的總線帶寬。不過,在程序設計者直接控制下,它可以按照指令將其部分帶寬釋放給另一個總線主控,或者,在該總線仲裁周期內或程序設計者認為必要的任何周期中控制另外的槽位。
程序設計者也可為每個槽位選擇帶寬利用系數——100%、75%、50%或25%。這一選擇是通過控制何時以及以怎樣的順序分配每個槽位的訪問來實現的,系數為25%,則這個槽位每四個周期只能被輪詢一次;系數為50%,則每兩個周期輪詢一次;75%,則每四個周期輪詢三次。
對旋轉總線仲裁器進行編程
程序設計者可通過包含在系統控制模塊內的幾個寄存器定義多種選項。第一個寄存器是16入口總線請求配置寄存器,它的每一個入口代表一個主控和一個準許槽位的總線請求。每一個請求/準許槽位每次只能分配給一個總線主控,但根據總線主控的帶寬要求,每個總線主控可同時連接多個請求/準許槽位。當多個通道分配給一個主控時,這些通道應均勻分布在這16個通道當中。
每個請求/準許槽位都有一個兩位的帶寬壓縮字段(BRF),用以確定每個槽位能對系統總線進行仲裁的頻率(100%、75%、50%或25%)。BRC將總線請求信號輸出到第二個16入口總線請求寄存器(BRR),默認情況下,BRC中未被分配的槽位將阻止用任何總線請求信號設置相應的BRR入口。
第四個寄存器用于存儲哪個總線主控有數據在等待向AHB傳輸,而第五個寄存器則是程序設計者用來為每個總線請求和準許槽位(分配給特定總線主控)分配權重值。
使用循環仲裁
圖3:NS9xxx的總線架構。
在前面例子中,當基于特定仲裁再分配調度方案的LCD請求額外的總線訪問時,程序設計者可根據LCD必須處理的數據流的性質來指定分配給LCD的優先級。如果程序設計者認為需要分配10個槽位給LCD控制器,剩余的6個槽位會按最初仲裁方案分配給其它總線主控。這樣LCD控制器可獲得十倍于正常情況下可得到的帶寬,以及十倍于其它主控的帶寬來處理這種特定情形下的負載。
當通過以太網連接傳送數據、同時LCD屏幕進行刷新的時候,這種特性十分重要。LCD需要實時、準確地進行刷新,且不會被以太網請求中斷。
在典型的AMBA總線架構中,如果LCD對總線提出請求,不論有怎樣的刷新需求,它都不得不等待直到以太網主控將總線釋放出來。采用新的循環可編程仲裁方案,程序設計者可降低以太網傳輸的優先級,使數據以更低但可接受的速率傳輸,確保LCD得以適當地刷新而不至于使屏幕出現空白。
如果為保證活動畫面顯示對LCD延時和帶寬要求極高,則以太網協議需求還可進一步降低傳輸速率。但停止數據流傳輸是不可以的。實際上,如果LCD主控控制了該總線并且只有當刷新工作完成后才將總線釋放,則有可能停止數據流的傳輸。
在外圍總線中增加突發模式DMA
在基于AMBA的設計中,外圍總線的傳統設計方法是假定基于ARM內核的嵌入式器件用于低端性能應用。但現在的器件經常需要在不切斷低帶寬外圍電路訪問總線資源的情況下,運行一種或多種高帶寬應用。在具有較多外圍電路的設計中,這種情況特別容易出問題。例如NS9750或NS9360,它們支持USB、I2C,具有四個多功能串行模塊(可選用UART或SPI,同步模式下的速率可達11Mbps)、50個單獨的可編程GPIO引腳、一個IEEE1284外圍端口以及16個通用定時器或計數器(每個都有自己的I/O引腳)。
在傳統的APB實現方案中,采用FIFO就足以應付通信外設(如UART)的低速率傳輸,FIFO可以在處理器必須介入并訪問APB之前將數個字節傳送到接口。但在本文所描述的許多高端嵌入式應用中,一個或多個這樣的外圍電路可能需要高帶寬傳輸,要求能通過APB/AHB橋快速訪問主要的高性能總線。
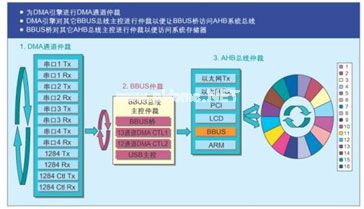
一種讓外圍總線工作于這種突發模式的方法,是僅用一條突發模式外圍總線(如NetSilicon的 BBUS)替代APB總線。這種突發模式外圍總線帶有四個支持突發模式的總線主控(見圖3):第一個總線主控是具有13個通道的DMA引擎,支持13個USB端點;第二個總線主控是具有12個通道的DMA引擎,支持4個串行模塊(每個串行模塊有8個通道)和1284端口;第三個總線主控為BBUS-AHB橋,它包含一個DMA引擎,該引擎具有可訪問AHB系統總線的通道;第四個總線主控是一個USB宿主模塊。另外,這種DMA引擎有兩個獨立的專用DMA通道,可支持連接到外部存儲總線的外部設備。為簡化突發模式狀態,每一個內部DMA通道以“飛越模式”(fly-by mode)在系統存儲器及BBUS外圍電路之間傳輸數據,而兩個外部DMA通道則選擇存儲器到存儲器的傳輸模式。
責任編輯:gt
-
控制系統
+關注
關注
41文章
6543瀏覽量
110472 -
帶寬
+關注
關注
3文章
907瀏覽量
40845 -
可編程
+關注
關注
2文章
844瀏覽量
39781 -
總線
+關注
關注
10文章
2866瀏覽量
87981
發布評論請先 登錄
相關推薦
可編程控制器的使用實驗
可編程序控制器(plc)有哪些應用
邏輯及可編程序控制系統
設計可編程控制系統時的故障防范
對可編程序控制器控制系統的可靠性探討
設計可編程控制系統時的故障防范
高帶寬嵌入式應用中SoC微控制器的新型總線開發






 工商網監
工商網監
評論