") 詳細了解卡爾曼濾波器
詳細了解卡爾曼濾波器
深入研究Kalman濾波器,這是有史以來最廣泛且最有用的算法之一。
與我的朋友交談時,我經(jīng)常聽到:"哦,卡爾曼過濾器……我通常學(xué)習(xí)它們,理解它們,然后我忘記了一切"。 好吧,考慮到卡爾曼濾波器(KF)是世界上應(yīng)用最廣泛的算法之一(如果環(huán)顧四周,您80%的技術(shù)可能已經(jīng)在內(nèi)部運行某種KF),讓我們嘗試將其弄清楚 一勞永逸。
在這篇文章的結(jié)尾,您將對KF的工作原理,其背后的想法,為什么需要多個變體以及最常見的變體有一個直觀而詳細的了解。
狀態(tài)估計
KF是所謂的狀態(tài)估計算法的一部分。 什么是狀態(tài)估計? 假設(shè)您有一個系統(tǒng)(讓我們將其視為黑匣子)。 黑匣子可以是任何東西:您的風(fēng)扇,化學(xué)系統(tǒng),移動機器人。 對于這些系統(tǒng)中的每一個,我們都可以定義一個狀態(tài)。 狀態(tài)是變量的向量,我們很想知道它們,它們可以描述系統(tǒng)在特定時間點的"狀態(tài)"(這就是為什么將其稱為狀態(tài))。 "可以描述"是什么意思? 這意味著,如果您知道在時間k處的狀態(tài)向量和提供給系統(tǒng)的輸入,則可以(同時使用系統(tǒng)工作原理的一些知識)知道在時間k + 1處的系統(tǒng)狀態(tài)。
例如,假設(shè)我們有一個移動的機器人,并且我們關(guān)心知道它在空間中的位置(而不關(guān)心它的方向)。 如果我們將狀態(tài)定義為機器人的位置(x,y)及其速度(v_x,v_y),并且我們有一個關(guān)于機器人如何運動的模型,那么就足以確定機器人的位置和位置。 下一次瞬間。
因此,狀態(tài)估計算法估計系統(tǒng)的狀態(tài)。 為什么要估算呢? 因為在現(xiàn)實生活中,外部觀察者永遠無法訪問系統(tǒng)的真實狀態(tài)。 通常有兩種情況:您可以測量狀態(tài),但是測量結(jié)果會受到噪聲的影響(每個傳感器只能產(chǎn)生一定精度的讀數(shù),可能對您來說還不夠),或者您無法直接測量狀態(tài)。 一個示例可能是使用GPS計算上述移動機器人的位置(我們將位置確定為狀態(tài)的一部分),這可能會給您帶來多達10米的測量誤差,對于您可能想到的任何應(yīng)用程序來說,這可能都不足夠 。
通常,在進行狀態(tài)估計時,您可以放心地假設(shè)您知道系統(tǒng)的輸入(因為是您提供的)和輸出。 由于測量了輸出,因此它也會受到一定的測量噪聲的影響。 據(jù)此,我們將狀態(tài)估計器定義為一個系統(tǒng),該系統(tǒng)接收要估計其狀態(tài)的系統(tǒng)的輸入和輸出,并輸出系統(tǒng)狀態(tài)的估計值。傳統(tǒng)上,狀態(tài)用x表示,輸出用 y或z,u是輸入,而tilde_x是估計狀態(tài)。
System and State Estimator block diagram.
卡爾曼濾波器
您可能已經(jīng)注意到,我們已經(jīng)討論了一些有關(guān)錯誤的內(nèi)容:
· 您可以測量系統(tǒng)的輸出,但是傳感器會給出測量誤差
· 您可以估計狀態(tài),但是作為狀態(tài)估計它具有一定的置信度。
除此之外,我說過,您需要某種系統(tǒng)知識,您需要了解系統(tǒng)"行為"的模型(稍后會詳細介紹),您的模型當然并不完美,因此您將擁有 另一個錯誤。
在KF中,您可以使用高斯分布來處理所有這些不確定性。 高斯分布是表示您不確定的事物的一種好方法。 您當前的信念可以用分布的均值表示,而標準差可以說明您對信念的信心。
在KF中:
· 您的估計狀態(tài)將是具有一定均值和協(xié)方差的高斯隨機變量(它將告訴我們該算法"信任"當前估計的程度)
· 您對原始系統(tǒng)的輸出測量的不確定性將用均值為0和一定協(xié)方差的隨機變量表示(這將告訴我們我們對測量本身的信任程度)
· 系統(tǒng)模型的不確定性將由均值為0和一定協(xié)方差的隨機變量表示(這將告訴我們我們對所使用模型的信任程度)。
讓我們舉一些例子來了解其背后的想法。
· 不良的模型,好的傳感器讓我們再次假設(shè)您想跟蹤機器人的位置,并且您在傳感器上花費了很多錢,它們?yōu)槟峁├迕准壍木取?另一方面,您根本不喜歡機器人技術(shù),您在Google上搜索了一下,然后發(fā)現(xiàn)了一個非常基本的運動模型:隨機游動(基本上是一個僅由噪聲給出運動的粒子)。 很明顯,您的模型不是很好,不能真正被信任,而您的測量結(jié)果卻很好。 在這種情況下,您可能將使用非常窄的高斯分布(小方差)來建模測量噪聲,而使用非常寬的高斯分布(大方差)來建模不確定性。
· 傳感器質(zhì)量差,模型好如果傳感器質(zhì)量不佳(例如GPS),但您花費大量時間對系統(tǒng)進行建模,則情況恰好相反。 在這種情況下,您可能將使用非常窄的高斯分布(小方差)來建模模型不確定性,而使用非常寬的高斯分布(大方差)來建模噪聲。
Wide variance vs. small variance Gaussian distributions.
估計狀態(tài)不確定性如何?KF將根據(jù)估計過程中發(fā)生的事情進行更新,您唯一要做的就是將其初始化為足夠好的值。 "足夠好"取決于您的應(yīng)用程序,您的傳感器,您的模型等。通常,KF需要一點時間才能收斂到正確的估計值。
KF如何運作?
如前所述,要讓KF正常工作,您需要對系統(tǒng)有"一定的了解"("不確定",即不完美的模型)。 特別是對于KF,您需要兩個模型:
· 狀態(tài)轉(zhuǎn)換模型:某些函數(shù),在時間k給出狀態(tài)和輸入,可以在時間k + 1給出狀態(tài)。
· 測量模型:給定時間為k的某個函數(shù),可以為您提供同一時間的測量結(jié)果
稍后,我們將了解為什么需要這些功能,讓我們首先看一些示例以了解它們的含義。
狀態(tài)轉(zhuǎn)換模型,此模型告訴您系統(tǒng)如何隨時間演變(如果您還記得的話,我們之前曾談到狀態(tài)如何具有足夠的描述性以及時推斷系統(tǒng)行為)。這在很大程度上取決于系統(tǒng)本身以及您對系統(tǒng)的關(guān)心。如果您不知道如何對系統(tǒng)建模,則可以使用一些Google搜索來提供幫助。對于運動的物體(如果以適當?shù)牟蓸勇蕼y量),可以使用恒速模型(假定物體以恒定的速度運動),對于車輛,可以使用單輪腳踏車模型,等等……讓我們假設(shè)一種或另一種,我們建立了一個模型。我們在這里做出一個重要的假設(shè),這對于KF的工作是必要的:您的當前狀態(tài)僅取決于先例。換句話說,系統(tǒng)狀態(tài)的"歷史"濃縮為先前的狀態(tài),也就是說,給定先前的狀態(tài),每個狀態(tài)都獨立于過去。這也稱為馬爾可夫假設(shè)。如果這不成立,就不能僅憑先例來表達當前狀態(tài)。
度量模型度量模型告訴您如何將輸出(可以度量)和狀態(tài)聯(lián)系在一起。 直觀上,您需要這樣做,因為您知道測量的輸出,并且想要在估計期間從中推斷出狀態(tài)。 同樣,此模型因情況而異。 例如,在移動機器人示例中,如果您關(guān)心位置并且擁有GPS,則您的模型就是身份功能,因為您已經(jīng)在測量狀態(tài)的嘈雜版本。
每個步驟的數(shù)學(xué)公式和解釋如下:
那么,KF實際如何運作? 該算法分兩個步驟工作,稱為預(yù)測和更新。 假設(shè)我們在時間k處,并且那時我們有估計狀態(tài)。 首先,我們使用狀態(tài)轉(zhuǎn)換模型,并使估計狀態(tài)演化到下一個時刻(1)。 這相當于說:鑒于我當前對狀態(tài)的信念,我所擁有的輸入以及對系統(tǒng)的了解,我希望我的下一個狀態(tài)是這樣。 這是預(yù)測步驟。
現(xiàn)在,由于我們還具有輸出和測量模型,因此我們實際上可以使用實際測量"校正"預(yù)測。 在更新步驟中,我們采用預(yù)期狀態(tài),我們計算輸出(使用測量模型)(2),然后將其與實際測量的輸出進行比較。 然后,我們以"智能方式"使用兩者之間的差異來校正狀態(tài)的估計(3)。
通常,我們用頂點-表示校正前來自預(yù)測步驟的狀態(tài)估計。 K稱為卡爾曼增益。 那才是真正的聰明之處:K取決于我們對測量的信任程度,我們對當前估計的信任程度(這取決于我們對模型的信任程度),并根據(jù)此信息K"決定"了預(yù)測的估計量 用測量值校正。 如果我們的測量噪聲"小",而不是我們相信來自預(yù)測步驟的估計,那么我們將使用該測量對估計進行很多校正,如果相反,那么我們將對其進行最小限度的校正。
注意:為簡單起見,我寫方程式時就好像在處理普通變量一樣,但是您必須考慮到在每一步中我們都在處理隨機的高斯變量,因此我們還需要通過函數(shù)傳播 變量的協(xié)方差,而不僅僅是均值。d
Example of real position and estimation at each step of the KF algorithm.
肯德基家族
根據(jù)所使用的模型類型(狀態(tài)轉(zhuǎn)換和測量),可以將KF分為兩個大類:如果模型是線性的,則具有線性卡爾曼濾波器,而如果它們是非線性的,則具有非線性卡爾曼濾波器。
為什么要區(qū)分? 好吧,KF假設(shè)您的變量是高斯變量,當通過線性函數(shù)傳遞時,高斯變量仍然是高斯變量,如果通過非線性函數(shù)傳遞,則不正確。 這打破了卡爾曼假設(shè),因此我們需要找到解決方法。
從歷史上看,人們發(fā)現(xiàn)了兩種主要方法:用模型作弊和用數(shù)據(jù)作弊。如果您對模型作弊,則基本上可以使當前估計值周圍的非線性函數(shù)線性化,從而使您回到可以工作的線性情況。這種方法稱為擴展卡爾曼濾波器(EKF)。該方法的主要缺點是您必須能夠計算f()和h()的雅可比行列式。另外,如果您使用數(shù)據(jù)作弊,則可以使用非線性函數(shù),但隨后嘗試對非高斯分布進行"高斯化"(如果該詞甚至存在)。這是通過稱為"無味轉(zhuǎn)換"的智能采樣技術(shù)完成的。通過此變換,您可以(均值)和均方差來描述一個分布(在前兩個時刻僅完全描述了高斯分布)。這種方法稱為無味卡爾曼濾波器(UKF)。從理論上講,UKF優(yōu)于EKF,因為與模型線性化相比,Unscented Transform對結(jié)果分布的近似更好。在實踐中,必須具有相當大的非線性才能實際看到較大的差異。
肯尼迪行動
由于我談到了很多有關(guān)帶GPS的移動機器人的內(nèi)容,因此我就此情況作了簡短的演示(如果要使用它,可以在這里找到代碼)。 使用獨輪車模型生成機器人運動。 用于KF的狀態(tài)轉(zhuǎn)換模型是等速模型,其狀態(tài)包含x和y位置,轉(zhuǎn)向角及其導(dǎo)數(shù)。
機器人會及時移動(實際位置顯示為黑色),在每一步中,您都會得到非常嘈雜的GPS測量值,該測量值給出x和y(紅色)并估算位置(藍色)。 您可以使用不同的參數(shù),看看它們?nèi)绾斡绊憼顟B(tài)估計。 如您所見,我們可以進行非常嘈雜的測量,并對實際位置進行很好的估算。
KF in action: a robot real path (black) is tracked with a KF (blue) from noisy measurements (red).
獎勵:卡爾曼增益的直觀含義
讓我們看一下線性O(shè)F情況下卡爾曼增益的公式,并嘗試更深入地了解增益的工作原理。
其中P_k是當前估計狀態(tài)的協(xié)方差(我們對估計的信心程度),C是測量模型的線性變換,使得y(k)= Cx(k),R是測量噪聲的協(xié)方差矩陣 。 請注意,分數(shù)表示法并不是真正正確的,但是可以使發(fā)生的事情更容易可視化。
根據(jù)等式,如果R變?yōu)?,則我們有:
代之以定義的算法步驟(3),可以看到我們將完全忽略預(yù)測步驟的結(jié)果,并且使用測量模型的逆變換來獲得僅來自測量的狀態(tài)估計。
相反,如果我們非常信任模型/估計,則P_k將趨于0,從而得出:
因此,我們得到的最終估計與預(yù)測步長輸出相同。
請注意,我正在交替使用"信任模型"和"信任當前估計"。 它們并不相同,但它們是相關(guān)的,因為我們對預(yù)測步驟的估計的信任程度是我們對模型的信任程度(因為僅使用模型完成預(yù)測步驟)加上我們對模型的信任程度的組合。 估計上一步過濾。
獎勵2:庫
有很多不錯的庫可以在線計算KF,這是我的一些最愛。
作為GO愛好者,我將從這個非常不錯的GO庫開始,其中包含幾個預(yù)先實現(xiàn)的模型:rosshemsley/kalman
對于Python,您可以查看 pykalman.github.io
結(jié)論:我們深入研究了什么是狀態(tài)估計,卡爾曼濾波器的工作原理,其背后的直覺,如何使用它們以及何時使用。 我們介紹了一個玩具(但現(xiàn)實生活中)的問題,并介紹了如何使用卡爾曼濾波器解決該問題。 然后,我們更深入地研究了Kalman濾波器在幕后的實際作用。
-
濾波器
+關(guān)注
關(guān)注
160文章
7729瀏覽量
177689 -
算法
+關(guān)注
關(guān)注
23文章
4600瀏覽量
92646
發(fā)布評論請先 登錄
相關(guān)推薦
卡爾曼濾波器的特性及仿真

卡爾曼濾波的優(yōu)缺點有哪些
聲表面波(SAW)濾波器和體聲波(BAW)濾波器詳細介紹
高通濾波器和低通濾波器的區(qū)別
卡爾曼濾波是什么 卡爾曼濾波與目標追蹤技術(shù)分析

什么是低通濾波器?低通濾波器有什么作用?

高通濾波器、低通濾波器、帶通濾波器怎樣測幅頻特性?
如何通過濾波器類型判斷濾波器的通帶和阻帶?

卡爾曼濾波算法c語言實現(xiàn)方法
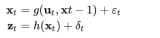
什么是匹配濾波器?如何理解匹配濾波器?
卡爾曼濾波算法的基本原理
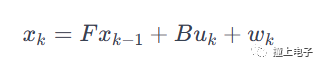
卡爾曼濾波五個公式
卡爾曼濾波的原理和C代碼






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論