 圖卷積神經網絡入門詳解
圖卷積神經網絡入門詳解
【導讀】GCN問世已經有幾年了(2016年就誕生了),但是這兩年尤為火爆。本人愚鈍,一直沒能搞懂這個GCN為何物,最開始是看清華寫的一篇三四十頁的綜述,讀了幾頁就沒讀了;后來直接拜讀GCN的開山之作,也是讀到中間的數學部分就跪了;再后來在知乎上看大神們的講解,直接被排山倒海般的公式——什么傅里葉變換、什么拉普拉斯算子等等,給搞蒙了,越讀越覺得:“哇這些大佬好厲害,哎我怎么這么菜!”。就這么反反復復,嘗試一次放棄一次,終于慢慢有點理解了,慢慢從那些公式的里跳了出來,看到了全局,也就慢慢明白了GCN的原理。今天,我就記錄一下我對GCN“階段性”的理解。
GCN的概念首次提出于ICLR2017(成文于2016年):
一、GCN是做什么的
在扎進GCN的汪洋大海前,我們先搞清楚這個玩意兒是做什么的,有什么用。
深度學習一直都是被幾大經典模型給統治著,如CNN、RNN等等,它們無論再CV還是NLP領域都取得了優異的效果,那這個GCN是怎么跑出來的?是因為我們發現了很多CNN、RNN無法解決或者效果不好的問題——圖結構的數據。
回憶一下,我們做圖像識別,對象是圖片,是一個二維的結構,于是人們發明了CNN這種神奇的模型來提取圖片的特征。CNN的核心在于它的kernel,kernel是一個個小窗口,在圖片上平移,通過卷積的方式來提取特征。這里的關鍵在于圖片結構上的平移不變性:一個小窗口無論移動到圖片的哪一個位置,其內部的結構都是一模一樣的,因此CNN可以實現參數共享。這就是CNN的精髓所在。
再回憶一下RNN系列,它的對象是自然語言這樣的序列信息,是一個一維的結構,RNN就是專門針對這些序列的結構而設計的,通過各種門的操作,使得序列前后的信息互相影響,從而很好地捕捉序列的特征。
上面講的圖片或者語言,都屬于歐式空間的數據,因此才有維度的概念,歐式空間的數據的特點就是結構很規則。但是現實生活中,其實有很多很多不規則的數據結構,典型的就是圖結構,或稱拓撲結構,如社交網絡、化學分子結構、知識圖譜等等;即使是語言,實際上其內部也是復雜的樹形結構,也是一種圖結構;而像圖片,在做目標識別的時候,我們關注的實際上只是二維圖片上的部分關鍵點,這些點組成的也是一個圖的結構。
圖的結構一般來說是十分不規則的,可以認為是無限維的一種數據,所以它沒有平移不變性。每一個節點的周圍結構可能都是獨一無二的,這種結構的數據,就讓傳統的CNN、RNN瞬間失效。所以很多學者從上個世紀就開始研究怎么處理這類數據了。這里涌現出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其中一種,這里只講GCN,其他的后面有空再討論。
GCN,圖卷積神經網絡,實際上跟CNN的作用一樣,就是一個特征提取器,只不過它的對象是圖數據。GCN精妙地設計了一種從圖數據中提取特征的方法,從而讓我們可以使用這些特征去對圖數據進行節點分類(node classification)、圖分類(graph classification)、邊預測(link prediction),還可以順便得到圖的嵌入表示(graph embedding),可見用途廣泛。因此現在人們腦洞大開,讓GCN到各個領域中發光發熱。
二、GCN長啥樣,嚇人嗎
GCN的公式看起來還是有點嚇人的,論文里的公式更是嚇破了我的膽兒。但后來才發現,其實90%的內容根本不必理會,只是為了從數學上嚴謹地把事情給講清楚,但是完全不影響我們的理解,尤其對于我這種“追求直覺,不求甚解”之人。
下面進入正題,我們直接看看GCN的核心部分是什么亞子:
假設我們手頭有一批圖數據,其中有N個節點(node),每個節點都有自己的特征,我們設這些節點的特征組成一個N×D維的矩陣X,然后各個節點之間的關系也會形成一個N×N維的矩陣A,也稱為鄰接矩陣(adjacency matrix)。X和A便是我們模型的輸入。
GCN也是一個神經網絡層,它的層與層之間的傳播方式是:
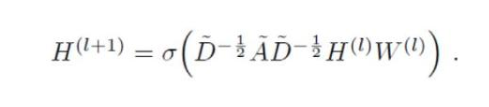
這個公式中:
A波浪=A+I,I是單位矩陣
D波浪是A波浪的度矩陣(degree matrix),公式為
H是每一層的特征,對于輸入層的話,H就是X
σ是非線性激活函數
我們先不用考慮為什么要這樣去設計一個公式。我們現在只用知道: 這個部分,是可以事先算好的,因為D波浪由A計算而來,而A是我們的輸入之一。
所以對于不需要去了解數學原理、只想應用GCN來解決實際問題的人來說,你只用知道:哦,這個GCN設計了一個牛逼的公式,用這個公式就可以很好地提取圖的特征。這就夠了,畢竟不是什么事情都需要知道內部原理,這是根據需求決定的。
為了直觀理解,我們用論文中的一幅圖:

上圖中的GCN輸入一個圖,通過若干層GCN每個node的特征從X變成了Z,但是,無論中間有多少層,node之間的連接關系,即A,都是共享的。
假設我們構造一個兩層的GCN,激活函數分別采用ReLU和Softmax,則整體的正向傳播的公式為:
最后,我們針對所有帶標簽的節點計算cross entropy損失函數:

就可以訓練一個node classification的模型了。由于即使只有很少的node有標簽也能訓練,作者稱他們的方法為半監督分類。
當然,你也可以用這個方法去做graph classification、link prediction,只是把損失函數給變化一下即可。
三、GCN為什么是這個亞子
我前后翻看了很多人的解讀,但是讀了一圈,最讓我清楚明白為什么GCN的公式是這樣子的居然是作者Kipf自己的博客:tkipf.github.io/graph-c 推薦大家一讀。
作者給出了一個由簡入繁的過程來解釋:
我們的每一層GCN的輸入都是鄰接矩陣A和node的特征H,那么我們直接做一個內積,再乘一個參數矩陣W,然后激活一下,就相當于一個簡單的神經網絡層嘛,是不是也可以呢?
實驗證明,即使就這么簡單的神經網絡層,就已經很強大了。這個簡單模型應該大家都能理解吧,這就是正常的神經網絡操作。
但是這個簡單模型有幾個局限性:
只使用A的話,由于A的對角線上都是0,所以在和特征矩陣H相乘的時候,只會計算一個node的所有鄰居的特征的加權和,該node自己的特征卻被忽略了。因此,我們可以做一個小小的改動,給A加上一個單位矩陣I,這樣就讓對角線元素變成1了。
A是沒有經過歸一化的矩陣,這樣與特征矩陣相乘會改變特征原本的分布,產生一些不可預測的問題。所以我們對A做一個標準化處理。首先讓A的每一行加起來為1,我們可以乘以一個
,D就是度矩陣。我們可以進一步把 拆開與A相乘,得到一個對稱且歸一化的矩陣:
。
通過對上面兩個局限的改進,我們便得到了最終的層特征傳播公式:
其中 ,
為 的degree matrix。
公式中的 與對稱歸一化拉普拉斯矩陣十分類似,而在譜圖卷積的核心就是使用對稱歸一化拉普拉斯矩陣,這也是GCN的卷積叫法的來歷。原論文中給出了完整的從譜卷積到GCN的一步步推導,我是看不下去的,大家有興趣可以自行閱讀。
四、GCN有多牛
在看了上面的公式以及訓練方法之后,我并沒有覺得GCN有多么特別,無非就是一個設計巧妙的公式嘛,也許我不用這么復雜的公式,多加一點訓練數據或者把模型做深,也可能達到媲美的效果呢。
但是一直到我讀到了論文的附錄部分,我才頓時發現:GCN原來這么牛啊!
為啥呢?
因為即使不訓練,完全使用隨機初始化的參數W,GCN提取出來的特征就以及十分優秀了!這跟CNN不訓練是完全不一樣的,后者不訓練是根本得不到什么有效特征的。
我們看論文原文:

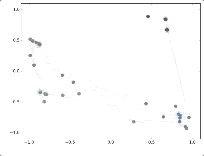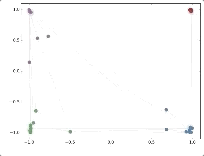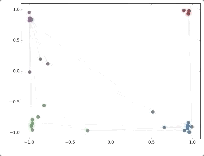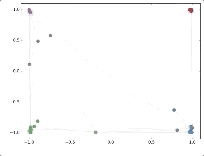
然后作者做了一個實驗,使用一個俱樂部會員的關系網絡,使用隨機初始化的GCN進行特征提取,得到各個node的embedding,然后可視化:

可以發現,在原數據中同類別的node,經過GCN的提取出的embedding,已經在空間上自動聚類了。
而這種聚類結果,可以和DeepWalk、node2vec這種經過復雜訓練得到的node embedding的效果媲美了。
說的夸張一點,比賽還沒開始,GCN就已經在終點了。看到這里我不禁猛拍大腿打呼:“NB!”
還沒訓練就已經效果這么好,那給少量的標注信息,GCN的效果就會更加出色。
作者接著給每一類的node,提供僅僅一個標注樣本,然后去訓練,得到的可視化效果如下:
這是整片論文讓我印象最深刻的地方。
看到這里,我覺得,以后有機會,確實得詳細地吧GCN背后的數學琢磨琢磨,其中的玄妙之處究竟為何,其物理本質為何。這個時候,回憶起在知乎上看到的各路大神從各種角度解讀GCN,例如從熱量傳播的角度,從一個群體中每個人的工資的角度,生動形象地解釋。這一刻,歷來痛恨數學的我,我感受到了一絲數學之美,于是凌晨兩點的我,打開了天貓,下單了一本正版《數學之美》。哦,數學啊,你真如一朵美麗的玫瑰,每次被你的美所吸引,都要深深受到刺痛,我何時才能懂得你、擁有你?
其他關于GCN的點滴:
對于很多網絡,我們可能沒有節點的特征,這個時候可以使用GCN嗎?答案是可以的,如論文中作者對那個俱樂部網絡,采用的方法就是用單位矩陣 I 替換特征矩陣 X。
我沒有任何的節點類別的標注,或者什么其他的標注信息,可以使用GCN嗎?當然,就如前面講的,不訓練的GCN,也可以用來提取graph embedding,而且效果還不錯。
GCN網絡的層數多少比較好?論文的作者做過GCN網絡深度的對比研究,在他們的實驗中發現,GCN層數不宜多,2-3層的效果就很好了。
這么強大的玩意兒,趕緊去試試吧!
-
圖像識別
+關注
關注
9文章
519瀏覽量
38240 -
深度學習
+關注
關注
73文章
5493瀏覽量
120985 -
cnn
+關注
關注
3文章
351瀏覽量
22173
發布評論請先 登錄
相關推薦
卷積神經網絡與傳統神經網絡的比較
BP神經網絡和卷積神經網絡的關系
循環神經網絡和卷積神經網絡的區別
卷積神經網絡的實現原理
bp神經網絡和卷積神經網絡區別是什么
卷積神經網絡分類方法有哪些
cnn卷積神經網絡分類有哪些
卷積神經網絡訓練的是什么
卷積神經網絡的原理與實現
卷積神經網絡的基本結構及其功能
卷積神經網絡的原理是什么
卷積神經網絡和bp神經網絡的區別
卷積神經網絡的優勢和應用領域

詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論