") 您應該知道的9種深度學習算法
您應該知道的9種深度學習算法
本文的主要目標是讓您對深度學習領域有一個整體了解,并幫助您了解每種特定情況下應使用的算法。來吧。
神經網絡:基礎
神經網絡是一個具有相互連接的節(jié)點的計算系統(tǒng),其節(jié)點的工作方式更像是人腦中的神經元。這些神經元在它們之間進行處理并傳遞信息。每個神經網絡都是一系列的算法,這些算法試圖通過一個模擬人類大腦運作的過程來識別一組數(shù)據(jù)中的潛在關系。
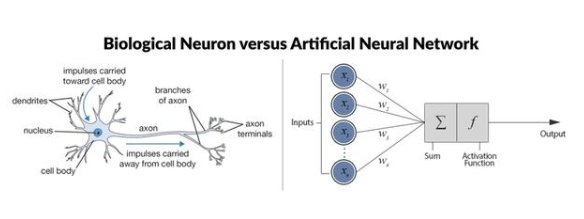
深度學習算法和經典神經網絡之間有什么區(qū)別呢?最明顯的區(qū)別是:深度學習中使用的神經網絡具有更多隱藏層。這些層位于神經元的第一層(即輸入層)和最后一層(即輸出層)之間。另外,沒有必要將不同層的所有神經元連接起來。
您應該知道的9種深度學習算法
#1反向傳播
反向傳播算法是一種非常流行的用于訓練前饋神經網絡的監(jiān)督學習算法。本質上,反向傳播計算成本函數(shù)的導數(shù)的表達式,它是每一層之間從左到右的導數(shù)乘積,而每一層之間的權重梯度是對部分乘積的簡單修改(“反向傳播誤差”)。
我們向網絡提供數(shù)據(jù),它產生一個輸出,我們將輸出與期望的輸出進行比較(使用損失函數(shù)),然后根據(jù)差異重新調整權重。然后重復此過程。權重的調整是通過一種稱為隨機梯度下降的非線性優(yōu)化技術來實現(xiàn)的。
假設由于某種原因,我們想識別圖像中的樹。我們向網絡提供任何種類的圖像,并產生輸出。由于我們知道圖像是否實際上有一棵樹,因此我們可以將輸出與真實情況進行比較并調整網絡。隨著我們傳遞越來越多的圖像,網絡的錯誤就會越來越少。現(xiàn)在我們可以給它提供一個未知的圖像,它將告訴我們該圖像是否包含樹。
#2前饋神經網絡(FNN)
前饋神經網絡通常是全連接,這意味著層中的每個神經元都與下一層中的所有其他神經元相連。所描述的結構稱為“多層感知器”,起源于1958年。單層感知器只能學習線性可分離的模式,而多層感知器則可以學習數(shù)據(jù)之間的非線性的關系。
前饋網絡的目標是近似某個函數(shù)f。例如對于分類,=(x)將輸入x映射到類別y。前饋網絡定義了一個映射y = f(x;θ),并學習了導致最佳函數(shù)逼近的參數(shù)θ的值。
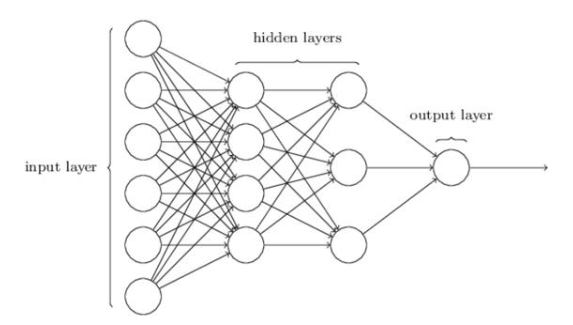
這些模型之所以稱為前饋,是因為從x到定義f的中間計算,最后到輸出y,沒有反饋連接。沒有將模型的輸出反饋到自身的反饋連接。當前饋神經網絡擴展為包括反饋連接時,它們稱為循環(huán)神經網絡。
#3卷積神經網絡(CNN)
卷積神經網絡除了為機器人和自動駕駛汽車的視覺提供幫助外,還成功的應用于人臉識別,對象監(jiān)測和交通標志識別等領域。
在數(shù)學中,卷積是一個函數(shù)越過另一個函數(shù)時兩個函數(shù)重疊多少的積分度量。
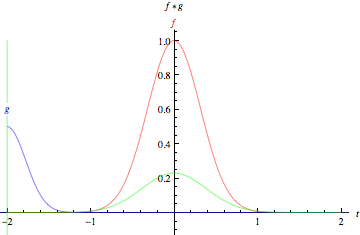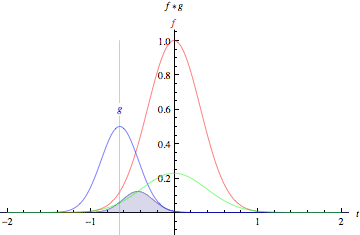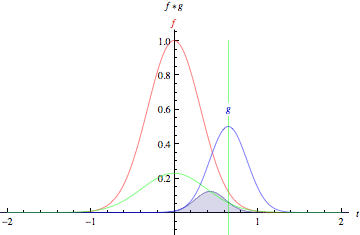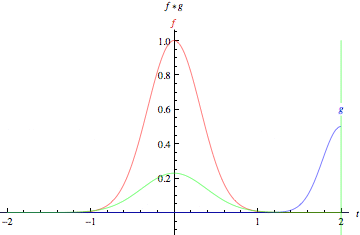
綠色曲線表示藍色和紅色曲線的卷積,它是t的函數(shù),位置由垂直的綠色線表示。灰色區(qū)域表示乘積g(tau)f(t-tau)作為t的函數(shù),所以它的面積作為t的函數(shù)就是卷積。
這兩個函數(shù)在x軸上每一點的重疊的乘積就是它們的卷積。
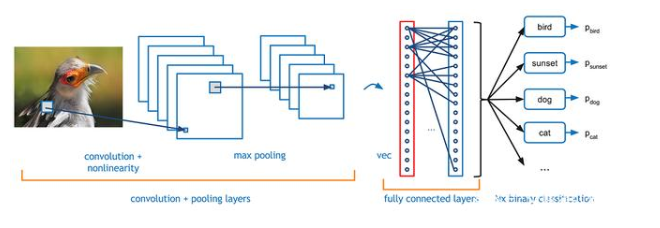
在某種程度上,他們嘗試對前饋網絡進行正則化,以避免過度擬合(當模型只學習預先看到的數(shù)據(jù)而不能泛化時),這使得他們能夠很好地識別數(shù)據(jù)之間的空間關系。
#4循環(huán)神經網絡(RNN)
循環(huán)神經網絡在許多NLP任務中都非常成功。在傳統(tǒng)的神經網絡中,可以理解所有輸入和輸出都是獨立的。但是,對于許多任務,這是不合適的。如果要預測句子中的下一個單詞,最好考慮一下它前面的單詞。
RNN之所以稱為循環(huán),是因為它們對序列的每個元素執(zhí)行相同的任務,并且輸出取決于先前的計算。RNN的另一種解釋:這些網絡具有“記憶”,考慮了先前的信息。
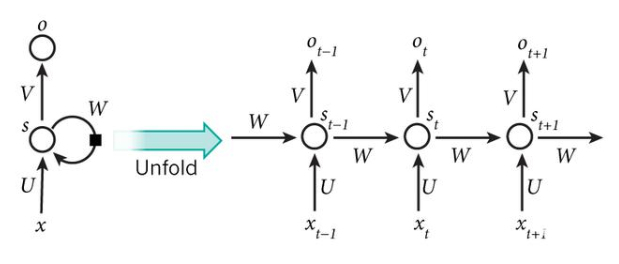
例如,如果序列是5個單詞的句子,則由5層組成,每個單詞一層。
在RNN中定義計算的公式如下:
x_t-在時間步t輸入。例如,x_1可以是與句子的第二個單詞相對應的one-hot向量。
s_t是步驟t中的隱藏狀態(tài)。這是網絡的“內存”。s_t作為函數(shù)取決于先前的狀態(tài)和當前輸入x_t:s_t = f(Ux_t + Ws_ {t-1})。函數(shù)f通常是非線性的,例如tanh或ReLU。計算第一個隱藏狀態(tài)所需的s _ {-1}通常初始化為零(零向量)。
o_t-在步驟t退出。例如,如果我們要預測句子中的單詞,則輸出可能是字典中的概率向量。o_t = softmax(Vs_t)
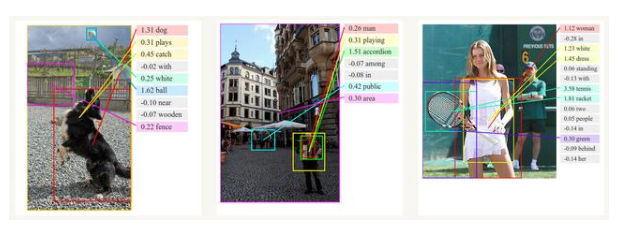
圖像描述的生成
與卷積神經網絡一起,RNN被用作模型的一部分,以生成未標記圖像的描述。組合模型將生成的單詞與圖像中的特征相結合:
最常用的RNN類型是LSTM,它比RNN更好地捕獲(存儲)長期依賴關系。LSTM與RNN本質上相同,只是它們具有不同的計算隱藏狀態(tài)的方式。
LSTM中的memory稱為cells,您可以將其視為接受先前狀態(tài)h_ {t-1}和當前輸入參數(shù)x_t作為輸入的黑盒。在內部,這些cells決定保存和刪除哪些memory。然后,它們將先前的狀態(tài),當前memory和輸入參數(shù)組合在一起。
這些類型的單元在捕獲(存儲)長期依賴關系方面非常有效。
#5遞歸神經網絡
遞歸神經網絡是循環(huán)網絡的另一種形式,不同之處在于它們是樹形結構。因此,它們可以在訓練數(shù)據(jù)集中建模層次結構。
由于其與二叉樹、上下文和基于自然語言的解析器的關系,它們通常用于音頻到文本轉錄和情緒分析等NLP應用程序中。然而,它們往往比遞歸網絡慢得多
#6自編碼器
自編碼器可在輸出處恢復輸入信號。它們內部有一個隱藏層。自編碼器設計為無法將輸入準確復制到輸出,但是為了使誤差最小化,網絡被迫學習選擇最重要的特征。
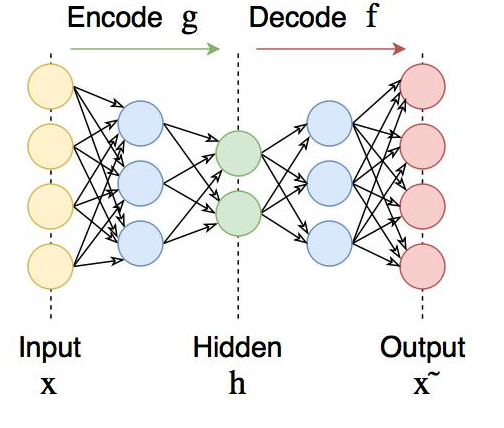
自編碼器可用于預訓練,例如,當有分類任務且標記對太少時。或降低數(shù)據(jù)中的維度以供以后可視化。或者,當您只需要學習區(qū)分輸入信號的有用屬性時。
#7深度信念網絡和受限玻爾茲曼機器
受限玻爾茲曼機是一個隨機神經網絡(神經網絡,意味著我們有類似神經元的單元,其binary激活取決于它們所連接的相鄰單元;隨機意味著這些激活具有概率性元素),它包括:
可見單位層
隱藏單元層
偏差單元
此外,每個可見單元連接到所有的隱藏單元(這種連接是無向的,所以每個隱藏單元也連接到所有的可見單元),而偏差單元連接到所有的可見單元和所有的隱藏單元。
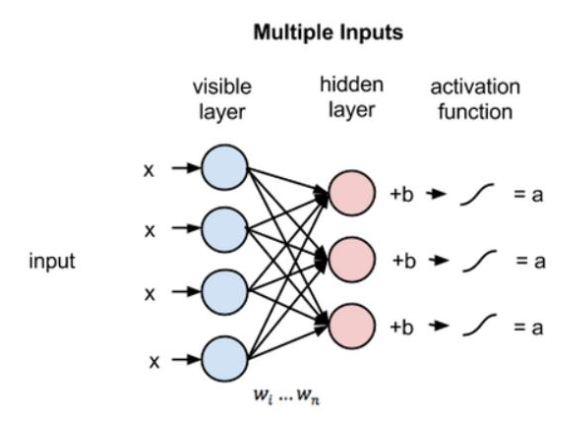
為了使學習更容易,我們對網絡進行了限制,使任何可見單元都不連接到任何其他可見單元,任何隱藏單元都不連接到任何其他隱藏單元。
多個RBM可以疊加形成一個深度信念網絡。它們看起來完全像全連接層,但但是它們的訓練方式不同。
#8生成對抗網絡(GAN)
GAN正在成為一種流行的在線零售機器學習模型,因為它們能夠以越來越高的準確度理解和重建視覺內容。用例包括:
從輪廓填充圖像。
從文本生成逼真的圖像。
制作產品原型的真實感描述。
將黑白圖像轉換為彩色圖像。
在視頻制作中,GAN可用于:
在框架內模擬人類行為和運動的模式。
預測后續(xù)的視頻幀。
創(chuàng)建deepfake
生成對抗網絡(GAN)有兩個部分:
生成器學習生成可信的數(shù)據(jù)。生成的實例成為判別器的負面訓練實例。
判別器學會從數(shù)據(jù)中分辨出生成器的假數(shù)據(jù)。判別器對產生不可信結果的發(fā)生器進行懲罰。
建立GAN的第一步是識別所需的最終輸出,并根據(jù)這些參數(shù)收集初始訓練數(shù)據(jù)集。然后將這些數(shù)據(jù)隨機化并輸入到生成器中,直到獲得生成輸出的基本精度為止。
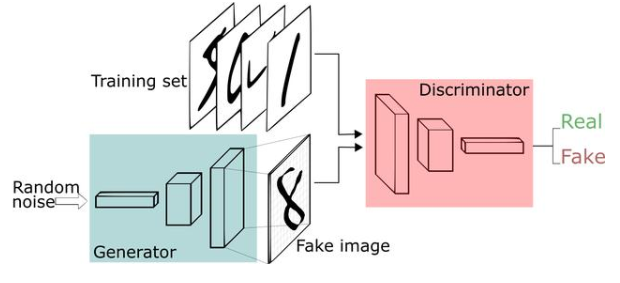
然后,將生成的圖像與原始概念的實際數(shù)據(jù)點一起饋入判別器。判別器對信息進行過濾,并返回0到1之間的概率來表示每個圖像的真實性(1與真相關,0與假相關)。然后檢查這些值是否成功,并不斷重復,直到達到預期的結果。
#9Transformers
Transformers也很新,它們主要用于語言應用。它它們基于一個叫做注意力的概念,這個概念被用來迫使網絡將注意力集中在特定的數(shù)據(jù)點上。
由于LSTM單元過于復雜,因此可以使用注意力機制根據(jù)其重要性對輸入的不同部分進行權衡。注意力機制只不過是另一個具有權重的層,它的唯一目的是調整權重,使輸入的部分優(yōu)先化,同時排除其他部分。
實際上,Transformers由多個堆疊的編碼器(形成編碼器層),多個堆疊的解碼器(解碼器層)和一堆attention層(self- attentions和encoder-decoder attentions)組成
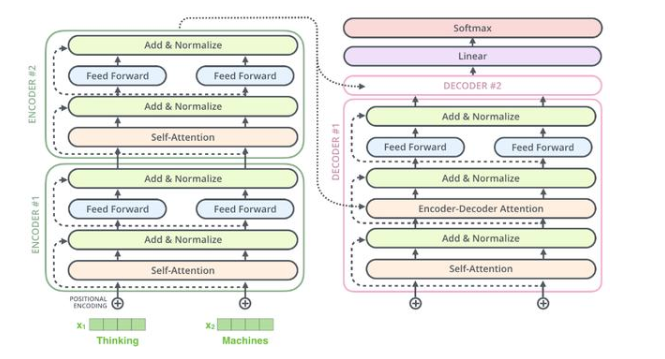
Transformers設計用于處理諸如機器翻譯和文本摘要之類的各種任務的有序數(shù)據(jù)序列,例如自然語言。如今,BERT和GPT-2是兩個最著名的經過預先訓練的自然語言系統(tǒng),用于各種NLP任務中,它們都基于Transformers。
#10圖神經網絡
一般來說,非結構化數(shù)據(jù)并不適合深度學習。在許多實際應用中,數(shù)據(jù)是非結構化的,例如社交網絡,化合物,知識圖,空間數(shù)據(jù)等。
圖神經網絡的目的是對圖數(shù)據(jù)進行建模,這意味著它們識別圖中節(jié)點之間的關系,并對其進行數(shù)值表示。它們以后可以在任何其他機器學習模型中用于各種任務,例如聚類,分類等。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100537 -
算法
+關注
關注
23文章
4599瀏覽量
92642 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發(fā)布評論請先 登錄
相關推薦
NPU與機器學習算法的關系
一種基于深度學習的二維拉曼光譜算法

AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度識別算法包括哪些內容
深度學習算法在集成電路測試中的應用
利用Matlab函數(shù)實現(xiàn)深度學習算法
深度學習的基本原理與核心算法
深度學習模型訓練過程詳解
深度解析深度學習下的語義SLAM

為什么深度學習的效果更好?

目前主流的深度學習算法模型和應用案例

深度學習在人工智能中的 8 種常見應用





 工商網監(jiān)
工商網監(jiān)
評論