 深度學習或者人工神經網絡模擬了生物神經元?
深度學習或者人工神經網絡模擬了生物神經元?
深度學習(DL)或者人工神經網絡(ANN)模擬了生物神經元?
這是個很大的誤解。
ANN充其量模仿了一個1957年面世的低配版神經元。
任何宣稱深度學習的靈感來源于生物的人都是出于種種營銷目的,或者他壓根就沒讀過生物學文獻。
不過,仿生系統研究怕是要遇到阻礙了。
兩篇最近發表于Cell上的神經元基因Arc的新發現,揭示了生物神經元更大的復雜性,其遠比我們想象得復雜得多。
大數據文摘微信公眾號后臺對話框回復“生物”獲取論文
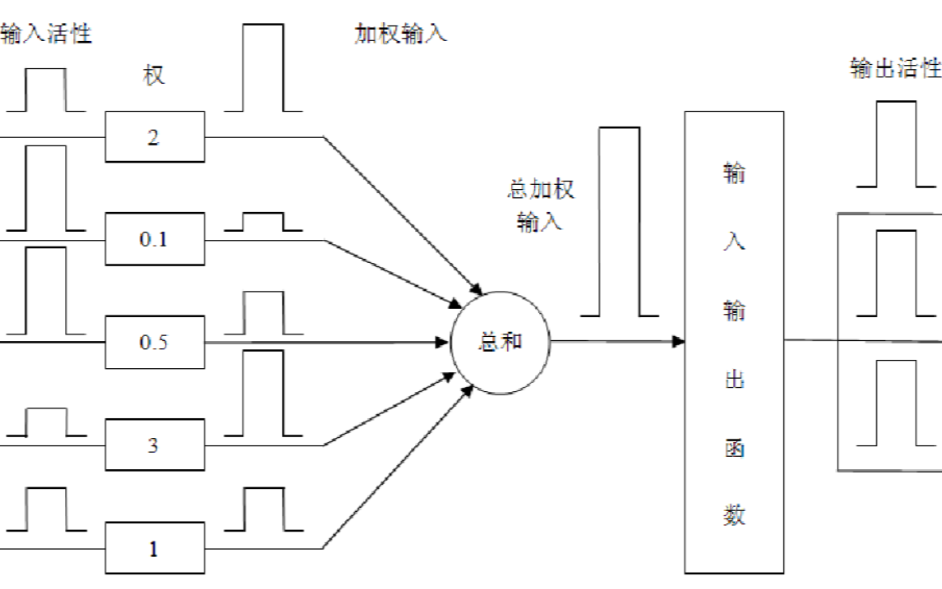
深度學習里的神經元實質上是數學函數,即相似度函數。在每個人工神經元內,帶權重的輸入信號和神經元的閾值進行比較,匹配度越高,激活函數值為1并執行某種動作的可能性就越大,不執行(對應函數值為0)的可能性越小。
雖然有個別例外情況(比如自回歸神經網絡Autoregressive networks),但多數深度學習算法都是這樣工作的,比如感知器(perceptron)、卷積神經網絡(Convolutional Neural Network,CNN)以及循環神經網絡(Recurrent Neural Network, RNN)。
生物神經元和深度學習的概念大不相同。
生物神經元并不會保持連續信號,而是產生動作電位,或者依據事件做出相應行為。
因此,所謂“神經形態”(neuromorphic)的硬件,也就是受到“整合信息,然后發送信號”(integrate and spike)的神經元的啟發。
如果你對構建一個仿生認知系統感興趣,可以看看今年2月這篇普度大學的論文。你必須知道的是,這類系統并不像深度學習框架那樣具有連續作用性。
大數據文摘微信公眾號后臺對話框回復“生物”獲取論文
從本質上來講,生物系統利用最少的能量來維持生存,但深度學習系統需要消耗非常多的能量,對比十分鮮明。深度學習采用蠻力手段(不斷嘗試和犯錯)來實現認知,我們知道它的運作原理,但是還不知道怎么減少深度學習的能耗。
一直以來,學術界一直以來希望用仿生手段創造出比深度學習更加強大的體系,雖然在這個方面努力了很久,但是進展尚不明顯。已經取得的進展有HTM神經元,它更貼近新大腦皮層(neo-cortex)結構。從下圖中可以看出,這種神經元模型要比深度學習中的神經元復雜得多。
左:深度學習ANN,中:生物神經元,右:HTM神經元
相比之下,深度學習方法雖然用的是和卡通一樣簡單的神經元模型,近一段時間以來卻意外大顯身手,在認知方面取得了讓人難以置信的成效。深度學習所做的事情非常正確,只是我們還不了解它做的究竟是什么。
不過,仿生系統研究怕是要遇到阻礙了。以色列的一個關于神經元性質的新實驗表明,生物中的神經元比我們想象得復雜得多:
大數據文摘微信公眾號后臺對話框回復“生物”獲取論文
總結一下,生物神經元的這些特性我們才剛剛知道:
單個神經元的峰電位波形通常隨著刺激部位的不同而改變,兩者的關系可以用函數表達;
在細胞外,從不同方向施加的刺激并不能引起空間性加成(Spatial summation);
當細胞內外刺激交疊時,不會產生空間性加成或者空間性相減(Spatial subtraction)。如果這些刺激的精確時值互不相關,那么非局部時間的干擾也不能奏效。
簡而言之,一個神經元里所發生的事情遠不止“計算-輸出”這么簡單。
生物神經元很可能不是隨著單一參數(也就是權重)而改變的純函數能夠描述的。它們更像是能顯示各種狀態的機器。換句話說,權重或許不是單值,而是多重值的,甚至是更高維度的。這些神經元的性質仍有待探索,我們對此幾乎一無所知。
如果你覺得這樣的解釋讓理解神經元性質變得更難了,那還有兩篇最近發表于Cell上的神經元基因Arc的新發現,揭示了更大的復雜性。
神經元釋放的細胞外囊泡中,很多都含有一種叫做Arc的基因,可以幫助神經元之間相互建立連接。那些被基因改造后缺乏Arc基因的小鼠難以形成長期記憶,而人類的一些神經功能障礙也與這個基因有關。
這項研究表明,神經元之間的交流是通過發送成套RNA編碼實現的。更準確地說,是成套的指令而非數據。發送編碼和發送數據完全是兩碼事。這也就意味著,一個神經元的行為可以改變另一個神經元的行為;不是通過觀察,而是通過彼此修正。
這種編碼交換機制隱隱證實了一些早期的猜想:“生物大腦僅僅是由離散的邏輯構成的嗎?”
實驗結果揭示了一個新的事實。即使在我們認知的最小單位,也就是單個神經元之間,也存在著一種對話式的認知(conversational cognition)。這種認知不斷修正神經元彼此的行為。
因此,神經元不僅是有不同狀態的機器,也是預先設定了指令的、能相互發送編碼的通路。
這些實驗對我們有兩點明確的啟示。
第一,我們對人類大腦計算能力的估計可能偏差了至少一個數量級。
如果粗略地設定一個神經元只執行一次運算,那么整體上看人類大腦可以完成每秒38拍字節(Peta)的運算(1拍字節=10^15字節)。
如果假定深度學習模型里的運算都等價于浮點數的運算,那么大腦的性能可以匹敵一個每秒3.8億億次浮點運算的電腦系統。當前最頂尖的超級計算機——中國的神威·太湖之光(Sunway Taihulight)的峰值性能是每秒12.5億億次/秒。
然而,大腦的實際運算能力很有可能是我們認為的10倍之多,也就是38億億次/秒。不過顯而易見的是,生物大腦實際上只用了較少的計算就實現了非常多的認知。
第二,未來在探究深度學習架構時,人們會很熱心地采用內部結構更復雜的神經元或者節點。
現在到了重新開始,并探究更復雜的神經元的時候了。迄今為止,我們遇到的比較復雜的神經元類型來自于長短期記憶(Long Short Term Memory, LSTM)。以下展示的是針對LSTM神經元的蠻力架構搜索:
目前尚不清楚為什么這些更復雜的LSTM更為有效,只有架構搜索算法才明白其中緣由,不過算法可不會解釋自己是怎么回事的。
最近發布的一篇來自CMU和蒙特利爾大學的論文探究了設計更為復雜的LSTMs。
大數據文摘微信公眾號后臺對話框回復“生物”獲取論文
Nested LSTMs相對于標準的LSTMs實現了重大改進。
綜上所述,致力于探究更加復雜的神經元類型的研究計劃可能會帶來豐碩的成果,甚至可以和把復數值應用于神經網絡上帶來的碩果相提并論。
在復數神經網絡中,只有應用于RNN才能體現出性能的改善。這也表明,要想超越簡單的感知,內部神經元復雜度可能是必需的。
這些復雜性對于更高級的認知是必要的,這是現有深度學習認知系統所不具備的。無論是對抗特征的強健性,還是讓機器學會忘記、學會忽略什么、學習抽象和識別上下文語境的切換,都是相當復雜的事。
預計在不久的將來,這一領域會出現更多積極大膽的研究。畢竟,大自然已經明確地告訴我們,神經元個體是更復雜的,因而我們創造的神經元模型也可能需要更復雜。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
神經元
+關注
關注
1文章
363瀏覽量
18441 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論