 機器學習模型切實可行的優化步驟
機器學習模型切實可行的優化步驟
導讀
這篇文章提供了可以采取的切實可行的步驟來識別和修復機器學習模型的訓練、泛化和優化問題。
眾所周知,調試機器學習代碼非常困難。即使對于簡單的前饋神經網絡也是這樣,你經常會在網絡體系結構做出一些決定,重初始化和網絡優化——所有這些會都導致在你的機器學習代碼中出現bug。
正如Chase Roberts在一篇關于“How to unit test machine learning code”的優秀文章中所寫的,他遇到的麻煩來自于常見的陷阱:
代碼不會崩潰,不會引發異常,甚至不會變慢。
訓練網絡仍在運行,損失仍將下降。
幾個小時后,數值收斂了,但結果很差
那么我們該怎么做呢?
本文將提供一個框架來幫助你調試神經網絡:
從最簡單的開始
確認你的損失
檢查中間輸出和連接
對參數進行診斷
跟蹤你的工作
請隨意跳轉到特定的部分或通讀下面的內容!請注意:我們不包括數據預處理或特定的模型算法選擇。對于這些主題,網上有很多很好的資源。
1. 從最簡單的開始
一個具有復雜結構和正則化以及學習率調度程序的神經網絡將比一個簡單的網絡更難調試。我們在第一點上有點欺騙性,因為它與調試你已經構建的網絡沒有什么關系,但是它仍然是一個重要的建議!
從最簡單的開始:
首先建立一個更簡單的模型
在單個數據點上訓練模型
首先,構建一個更簡單的模型
首先,構建一個只有一個隱藏層的小型網絡,并驗證一切正常。然后逐步增加模型的復雜性,同時檢查模型結構的每個方面(附加層、參數等),然后再繼續。
在單個數據點上訓練模型
作為一個快速的完整性檢查,你可以使用一兩個訓練數據點來確認你的模型是否能夠過擬合。神經網絡應該立即過擬合,訓練精度為100%,驗證精度與你的模型隨機猜測相匹配。如果你的模型不能對這些數據點進行過擬合,那么要么是它太小,要么就是存在bug。
即使你已經驗證了模型是有效的,在繼續之前也可以嘗試訓練一個(或幾個)epochs。
2. 確認你的損失
你的模型的損失是評估你的模型性能的主要方法,也是模型評估的重要參數,所以你要確保:
損失適合于任務(對于多分類問題使用類別交叉熵損失或使用focal loss來解決類不平衡)
你的損失函數在以正確的尺度進行測量。如果你的網絡中使用了不止一種類型的損失,例如MSE、adversarial、L1、feature loss,那么請確保所有損失都按正確的順序進行了縮放
注意,你最初的損失也很重要。如果模型一開始就隨機猜測,檢查初始損失是否接近預期損失。在Stanford CS231n coursework中,Andrej Karpathy提出了以下建議:
在隨機表現上尋找正確的損失。確保在初始化小參數時得到預期的損失。最好先單獨檢查數據的loss(將正則化強度設置為零)。例如,對于使用Softmax分類器的CIFAR-10,我們期望初始損失為2.302,因為我們期望每個類的隨機概率為0.1(因為有10個類),而Softmax損失是正確類的負對數概率,因此:-ln(0.1) = 2.302。
對于二分類的例子,只需對每個類執行類似的計算。假設數據是20%的0和80%的1。預期的初始損失是- 0.2ln(0.5) - 0.8ln(0.5) = 0.693147。如果你的初始損失比1大得多,這可能表明你的神經網絡權重不平衡(即初始化很差)或者你的數據沒有標準化。
3. 檢查內部的輸出和連接
要調試神經網絡,通常了解神經網絡內部的動態以及各個中間層所起的作用以及這些中間層之間如何連接是很有用的。你可能會遇到以下錯誤:
梯度更新的表達式不正確
權重更新沒有應用
梯度消失或爆炸
如果梯度值為零,這可能意味著優化器中的學習率可能太小,或者你遇到了上面的錯誤#1,其中包含梯度更新的不正確的表達式。
除了查看梯度更新的絕對值之外,還要確保監視激活的大小、權重的大小和每個層的更新相匹配。例如,參數更新的大小(權重和偏差)應該是1-e3。
有一種現象叫做“死亡的ReLU”或“梯度消失問題”,ReLU神經元在學習了一個表示權重的大的負偏置項后,會輸出一個零。這些神經元再也不會在任何數據點上被激活。
你可以使用梯度檢查來檢查這些錯誤,通過使用數值方法來近似梯度。如果它接近計算的梯度,則正確地實現了反向傳播。
Faizan Shaikh描述了可視化神經網絡的三種主要方法:
初步方法- 向我們展示訓練模型整體結構的簡單方法。這些方法包括打印出神經網絡各層的形狀或濾波器以及各層的參數。
基于激活的方法- 在這些方法中,我們解碼單個神經元或一組神經元的激活情況,以直觀地了解它們在做什么
基于梯度的方法- 這些方法傾向于在訓練模型時操作由前向和后向傳遞形成的梯度(包括顯著性映射和類激活映射)。
有許多有用的工具可以可視化單個層的激活和連接,比如ConX和Tensorboard。
使用ConX生成的動態呈現可視化示例
4. 參數診斷
神經網絡有大量的參數相互作用,使得優化變得困難。請注意,這是一個活躍的研究領域,所以下面的建議只是簡單的出發點。
Batch size- 你希望batch size足夠大,能夠準確地估計錯誤梯度,但又足夠小,以便小批隨機梯度下降(SGD)能夠使你的網絡歸一化。小的batch size將導致學習過程以訓練過程中的噪聲為代價快速收斂,并可能導致優化困難。論文On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima描述了:
在實踐中已經觀察到,當使用一個較大的batch size時,模型的質量會下降,這可以通過它的泛化能力來衡量。我們研究了在大批量情況下泛化下降的原因,并給出了支持large-batch方法趨向于收斂于訓練和測試函數的sharp的極小值這一觀點的數值證據——眾所周知,sharp的極小值導致較差的泛化。相比之下,小batch size的方法始終收斂于平坦的最小值,我們的實驗支持一個普遍的觀點,即這是由于梯度估計中的固有噪聲造成的。
學習速率- 學習率過低將導致收斂速度慢或陷入局部最小值的風險,而學習速率過大導致優化分歧,因為你有跳過損失函數的更深但是更窄部分的風險。考慮將學習率策略也納入其中,以隨著訓練的進展降低學習率。CS231n課程有一大部分是關于實現退火學習率的不同技術。
梯度裁剪- 在反向傳播期間的通過最大值或最大范數對梯度進行裁剪。對于處理可能在上面的步驟3中遇到的任何梯度爆炸非常有用。
Batch normalization- Batch normalization用于對每一層的輸入進行歸一化,以解決內部協變量移位問題。如果你同時使用Dropout和Batch Norm,請確保在Dropout上閱讀下面的要點。
本文來自Dishank Bansal的”TensorFlow中batch norm的陷阱和訓練網絡的健康檢查“,里面包括了很多使用batch norm的常見錯誤。
隨機梯度下降(SGD)- 有幾種使用動量,自適應學習率的SGD,和Nesterov相比并沒有訓練和泛化性能上的優勝者。一個推薦的起點是Adam或使用Nesterov動量的純SGD。
正則化- 正則化對于構建可泛化模型至關重要,因為它增加了模型復雜度或極端參數值的代價。它顯著降低了模型的方差,而沒有顯著增加其偏差。如CS231n課程所述:
通常情況下,損失函數是數據損失和正則化損失的總和(例如L2對權重的懲罰)。需要注意的一個危險是正則化損失可能會超過數據損失,在這種情況下,梯度將主要來自正則化項(它通常有一個簡單得多的梯度表達式)。這可能會掩蓋數據損失的梯度的不正確實現。
為了檢查這個問題,應該關閉正則化并獨立檢查數據損失的梯度。
Dropout- Dropout是另一種正則化你的網絡,防止過擬合的技術。在訓練過程中,只有保持神經元以一定的概率p(超參數)活動,否則將其設置為零。因此,網絡必須在每個訓練批中使用不同的參數子集,這減少了特定參數的變化成為主導。
這里需要注意的是:如果您同時使用dropout和批處理規范化(batch norm),那么要注意這些操作的順序,甚至要同時使用它們。這仍然是一個活躍的研究領域,但你可以看到最新的討論:
來自Stackoverflow的用戶MiloMinderBinder:Dropout是為了完全阻斷某些神經元的信息,以確保神經元不相互適應。因此,batch norm必須在dropout之后進行,否則你將通過標準化統計之后的數據傳遞信息。”
來自arXiv:Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift — 從理論上講,我們發現,當我們將網絡狀態從訓練狀態轉移到測試狀態時,Dropout會改變特定神經單元的方差。但是BN在測試階段會保持其統計方差,這是在整個學習過程中積累的。當在BN之前的使用Dropout時,該方差的不一致性(我們將此方案命名為“方差漂移”)導致不穩定的推斷數值行為,最終導致更多的錯誤預測。
5. 跟蹤你的網絡
你很容易忽視記錄實驗的重要性,直到你忘記你使用的學習率或分類權重。通過更好的跟蹤,你可以輕松地回顧和重現以前的實驗,以減少重復的工作(也就是說,遇到相同的錯誤)。
然而,手工記錄信息對于多個實驗來說是很困難的。工具如Comet.ml可以幫助自動跟蹤數據集、代碼更改、實驗歷史和生產模型(這包括關于模型的關鍵信息,如超參數、模型性能指標和環境細節)。
你的神經網絡對數據、參數甚至版本中的細微變化都非常敏感,這會導致模型性能的下降。跟蹤你的工作是開始標準化你的環境和建模工作流的第一步。
快速回顧
我們希望這篇文章為調試神經網絡提供了一個堅實的起點。要總結要點,你應該:
從簡單的開始— 先建立一個更簡單的模型,然后通過對幾個數據點的訓練進行測試
確認您的損失— 檢查是否使用正確的損失,并檢查初始損失
檢查中間輸出和連接— 使用梯度檢查和可視化檢查看圖層是否正確連接,以及梯度是否如預期的那樣更新
診斷參數— 從SGD到學習率,確定正確的組合(或找出錯誤的)
跟蹤您的工作— 作為基線,跟蹤你的實驗過程和關鍵的建模組件
-
神經網絡
+關注
關注
42文章
4717瀏覽量
99983 -
機器學習
+關注
關注
66文章
8306瀏覽量
131834
發布評論請先 登錄
相關推薦
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
機器學習中的數據預處理與特征工程
Al大模型機器人
深度學習中的模型權重
深度學習模型訓練過程詳解
深度學習的模型優化與調試方法



全面總結機器學習中的優化算法
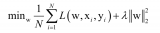
淺析機器學習的基本步驟






 工商網監
工商網監
評論